CUDA ---- GPU架构(Fermi、Kepler)
GPU架构
SM(Streaming Multiprocessors)是GPU架构中非常重要的部分,GPU硬件的并行性就是由SM决定的。
以Fermi架构为例,其包含以下主要组成部分:
- CUDA cores
- Shared Memory/L1Cache
- Register File
- Load/Store Units
- Special Function Units
- Warp Scheduler
GPU中每个SM都设计成支持数以百计的线程并行执行,并且每个GPU都包含了很多的SM,所以GPU支持成百上千的线程并行执行,当一个kernel启动后,thread会被分配到这些SM中执行。大量的thread可能会被分配到不同的SM,但是同一个block中的thread必然在同一个SM中并行执行。
CUDA采用Single Instruction Multiple Thread(SIMT)的架构来管理和执行thread,这些thread以32个为单位组成一个单元,称作warps。warp中所有线程并行的执行相同的指令。每个thread拥有它自己的instruction address counter和状态寄存器,并且用该线程自己的数据执行指令。
SIMT和SIMD(Single Instruction, Multiple Data)类似,SIMT应该算是SIMD的升级版,更灵活,但效率略低,SIMT是NVIDIA提出的GPU新概念。二者都通过将同样的指令广播给多个执行官单元来实现并行。一个主要的不同就是,SIMD要求所有的vector element在一个统一的同步组里同步的执行,而SIMT允许线程们在一个warp中独立的执行。SIMT有三个SIMD没有的主要特征:
- 每个thread拥有自己的instruction address counter
- 每个thread拥有自己的状态寄存器
- 每个thread可以有自己独立的执行路径
一个block只会由一个SM调度,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。一个SM可以同时拥有多个block。下图显示了软件硬件方面的术语:

需要注意的是,大部分thread只是逻辑上并行,并不是所有的thread可以在物理上同时执行。这就导致,同一个block中的线程可能会有不同步调。
并行thread之间的共享数据回导致竞态:多个线程请求同一个数据会导致未定义行为。CUDA提供了API来同步同一个block的thread以保证在进行下一步处理之前,所有thread都到达某个时间点。不过,我们是没有什么原子操作来保证block之间的同步的。
同一个warp中的thread可以以任意顺序执行,active warps被SM资源限制。当一个warp空闲时,SM就可以调度驻留在该SM中另一个可用warp。在并发的warp之间切换是没什么消耗的,因为硬件资源早就被分配到所有thread和block,所以该新调度的warp的状态已经存储在SM中了。
SM可以看做GPU的心脏,寄存器和共享内存是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的thread。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。所以,掌握部分硬件知识,有助于CUDA性能提升。
Fermi架构
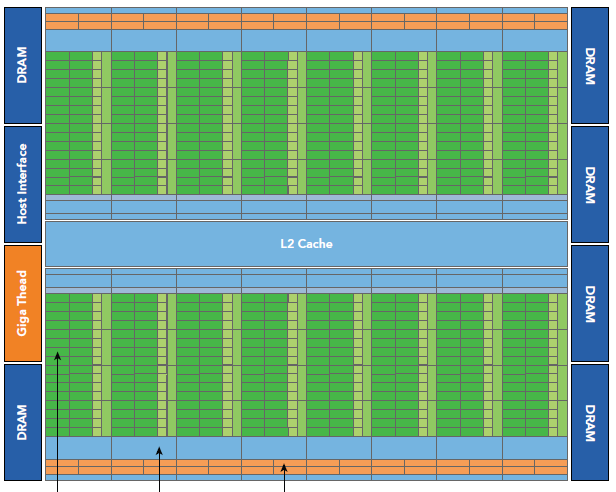
Fermi是第一个完整的GPU计算架构。
- 512个accelerator cores即所谓CUDA cores(包含ALU和FPU)
- 16个SM,每个SM包含32个CUDA core
- 六个384位 GDDR5 DRAM,支持6GB global on-board memory
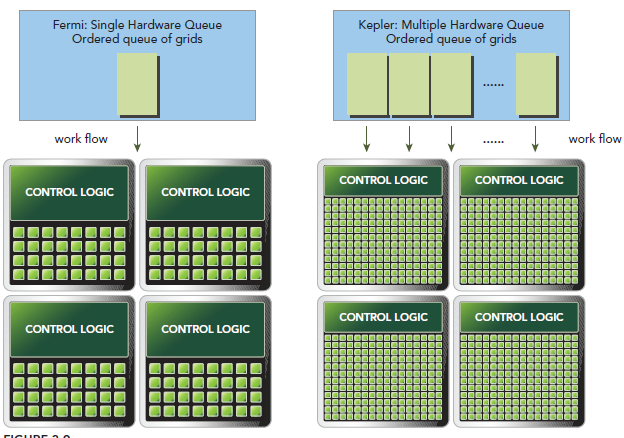
- GigaThread engine(图左侧)将thread blocks分配给SM调度
- 768KB L2 cache
- 每个SM有16个load/store单元,允许每个clock cycle为16个thread(即所谓half-warp,不过现在不提这个东西了)计算源地址和目的地址
- Special function units(SFU)用来执行sin cosine 等
- 每个SM两个warp scheduler两个instruction dispatch unit,当一个block被分配到一个SM中后,所有该block中的thread会被分到不同的warp中。
- Fermi(compute capability 2.x)每个SM同时可处理48个warp共计1536个thread。
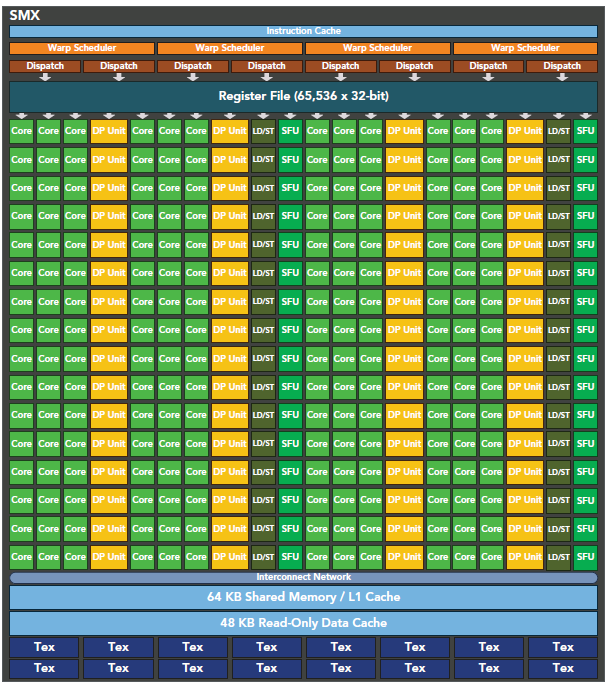
每个SM由一下几部分组成:
- 执行单元(CUDA cores)
- 调度分配warp的单元
- shared memory,register file,L1 cache
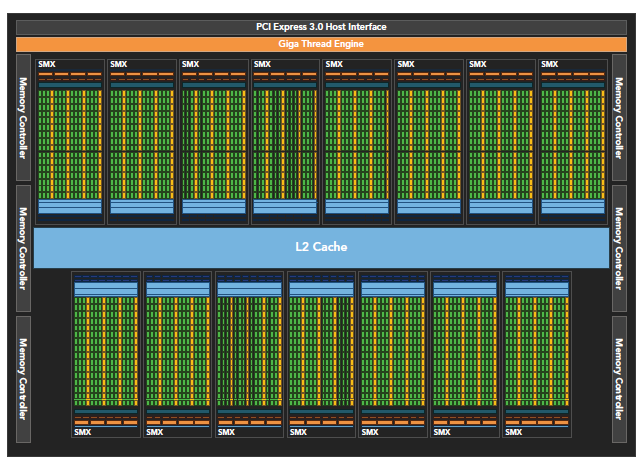
Kepler 架构
Kepler相较于Fermi更快,效率更高,性能更好。
- 15个SM
- 6个64位memory controller
- 192个单精度CUDA cores,64个双精度单元,32个SFU,32个load/store单元(LD/ST)
- 增加register file到64K
- 每个Kepler的SM包含四个warp scheduler、八个instruction dispatchers,使得每个SM可以同时issue和执行四个warp。
- Kepler K20X(compute capability 3.5)每个SM可以同时调度64个warp共计2048个thread。
Dynamic Parallelism
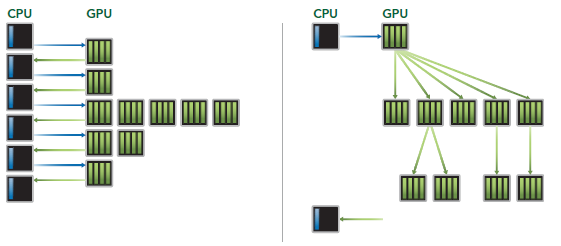
Dynamic Parallelism是Kepler的新特性,允许GPU动态的启动新的Grid。有了这个特性,任何kernel内都可以启动其它的kernel了。这样直接实现了kernel的递归以及解决了kernel之间数据的依赖问题。也许D3D中光的散射可以用这个实现。
Hyper-Q
Hyper-Q是Kepler的另一个新特性,增加了CPU和GPU之间硬件上的联系,使CPU可以在GPU上同时运行更多的任务。这样就可以增加GPU的利用率减少CPU的闲置时间。Fermi依赖一个单独的硬件上的工作队列来从CPU传递任务给GPU,这样在某个任务阻塞时,会导致之后的任务无法得到处理,Hyper-Q解决了这个问题。相应的,Kepler为GPU和CPU提供了32个工作队列。
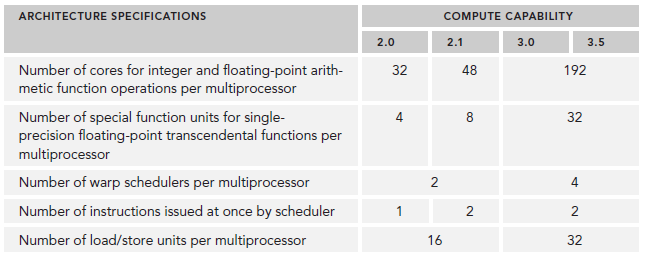
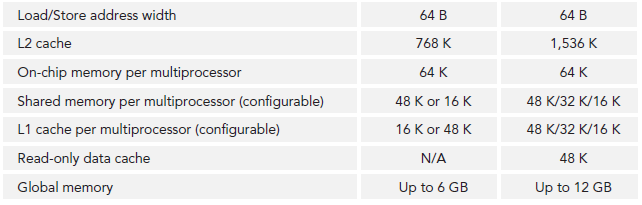
不同arch的主要参数对比
CUDA ---- GPU架构(Fermi、Kepler)的更多相关文章
- NVIDIA GPU架构与原理分析(一)——GPU简介与主流Fermi、Kepler架构GPU概述
1 GPU简介 图形处理单元GPU英文全称Graphic Processing Unit,GPU是相对于CPU的一个概念,NVIDIA公司在1999年发布GeForce256图形处理芯片时首先提出GP ...
- 【并行计算-CUDA开发】CUDA编程——GPU架构,由sp,sm,thread,block,grid,warp说起
掌握部分硬件知识,有助于程序员编写更好的CUDA程序,提升CUDA程序性能,本文目的是理清sp,sm,thread,block,grid,warp之间的关系.由于作者能力有限,难免有疏漏,恳请读者批评 ...
- 适用于CUDA GPU的Numba 随机数生成
适用于CUDA GPU的Numba 随机数生成 随机数生成 Numba提供了可以在GPU上执行的随机数生成算法.由于NVIDIA如何实现cuRAND的技术问题,Numba的GPU随机数生成器并非基于c ...
- 适用于CUDA GPU的Numba例子
适用于CUDA GPU的Numba例子 矩阵乘法 这是使用CUDA内核的矩阵乘法的简单实现: @cuda.jit def matmul(A, B, C): """Perf ...
- 剖析虚幻渲染体系(12)- 移动端专题Part 2(GPU架构和机制)
目录 12.4 移动渲染技术要点 12.4.1 Tile-based (Deferred) Rendering 12.4.2 Hierarchical Tiling 12.4.3 Early-Z 12 ...
- 并行计算基础(1)(GPU架构介绍)
一.常用术语 Task:任务.可以完整得到结果的一个程序,一个程序段或若干个程序段.例如搬砖. Parallel Task:并行任务.可以并行计算的任务.多个人搬砖. Serial Execution ...
- Gradient Boosting, Decision Trees and XGBoost with CUDA ——GPU加速5-6倍
xgboost的可以参考:https://xgboost.readthedocs.io/en/latest/gpu/index.html 整体看加速5-6倍的样子. Gradient Boosting ...
- 奉献pytorch 搭建 CNN 卷积神经网络训练图像识别的模型,配合numpy 和matplotlib 一起使用调用 cuda GPU进行加速训练
1.Torch构建简单的模型 # coding:utf-8 import torch class Net(torch.nn.Module): def __init__(self,img_rgb=3,i ...
- CUDA && GPU中dim3介绍
随机推荐
- HDU3853:LOOPS
题意:迷宫是一个R*C的布局,每个格子中给出停留在原地,往右走一个,往下走一格的概率,起点在(1,1),终点在(R,C),每走一格消耗两点能量,求出最后所需要的能量期望 #include<i ...
- 用python2.7.9 写个小程序搜索某个目录下行有某关键字
# -*- coding: utf-8 -*-import sysreload(sys)sys.setdefaultencoding("utf-8")import os def p ...
- 关于mydumper的.metadata文件丢失
今天要进行MySQL的数据迁移,所以把数据库通过mydumper工具备份的文件解压后.通过myloader进行导入 可是导入的时间出现这个报错: ** (myloader:766): CRITICAL ...
- 秋风下的萧瑟 NOIP2018 游记
“北方的秋天还真的是美丽冻人呢!” 是么?我有些疑惑,任凭雨滴落在脸上. 这天,可真不好,秋雨可让这天气一天比一天的寒冷了. 大概,故事从这里开始吧? 上一次的故事说道了哪里?那么,我们从今天的新故事 ...
- 常用数据库驱动名称以及URL
oracle: 驱动类的名字:oracle.jdbc.driver.OracleDriver URL:jdbc:oracle:thin:@dbip:port:databasename Mysql: 驱 ...
- Android SDK版本号与API Level 的对应关系-转
Android SDK版本号 与 API Level 对应关系 http://developer.android.com/guide/appendix/api-levels.html Android ...
- 20155306 白皎 0day漏洞——基础知识
20155306 白皎 0day漏洞--(第一篇)基础知识 写在前面: 本次免考实践方向是0day漏洞,以博客的形式记录了我的学习实践过程.第一篇博客主要围绕什么是0day漏洞以及一些以后学习中需要的 ...
- C++ STL 学习笔记__(8)map和multimap容器
10.2.9 Map和multimap容器 map/multimap的简介 ² map是标准的关联式容器,一个map是一个键值对序列,即(key,value)对.它提供基于key的快速检索能力. ² ...
- CF434D Nanami's Power Plant
就是切糕那道题,首先对每个函数连一串,然后\(x_u\leq x_v+d\)这个条件就是\(u\)函数\(i\)取值连向\(v\)函数\(i-d\)取值边权为inf,然后答案就是最小割了. #incl ...
- Linux每天一个命令:iperf
iperf命令 Iperf 是一个网络性能测试工具.Iperf可以测试最大TCP和UDP带宽性能,具有多种参数和UDP特性,可以根据需要调整,可以报告带宽.延迟抖动和数据包丢失.下载地址:https: ...