Hive笔记之Fetch Task
在使用Hive的时候,有时候只是想取表中某个分区的前几条的记录看下数据格式,比如一个很常用的查询:
select * from foo where partition_column=bar limit 10;
这种对数据基本没什么要求,随便来点就行,既然如此为什么不直接读取本地存储的数据作为结果集呢。
Hive命令都要转换为MapReduce任务去执行,但是因为启动MapReduce需要消耗资源,然后速度还很慢(相比较于直接从本地文件中读取而言),所以Hive对于查询做了优化,对于某些查询可以不启动MapReduce任务的就尽量不去启动MapReduce任务,而是直接从本地文件读取。
个人理解: fetch task = 不启动MapReduce,直接读取本地文件输出结果。
在hive-site.xml中有三个fetch task相关的值:
hive.fetch.task.conversion
hive.fetch.task.conversion.threshold
hive.fetch.task.aggr
hive.fetch.task.conversion
这个属性有三个可选的值:
none:关闭fetch task优化
minimal:只在select *、使用分区列过滤、带有limit的语句上进行优化
more:在minimal的基础上更加强大了,select不仅仅可以是*,还可以单独选择几列,并且filter也不再局限于分区字段,同时支持虚拟列(别名)
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>
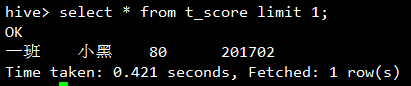
对于查询所有列的情况,会使用fetch task:
如果是查询部分列呢?
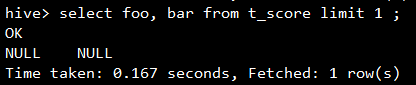
为什么查询部分列也使用了Fetch Task?查看一下当前的set hive.fetch.task.conversion的值:

尝试将hive.fetch.task.conversion设置为none,再查询:
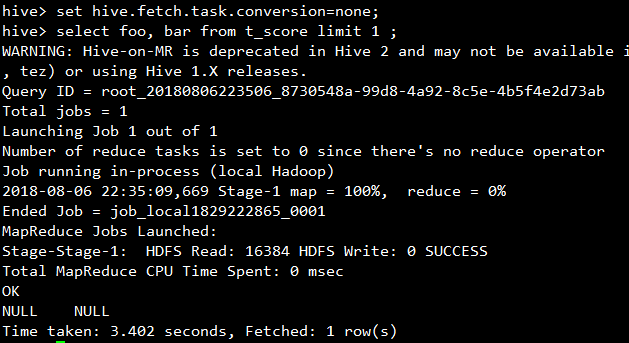
启动了MapReduce任务。
hive.fetch.task.conversion.threshold
在输入大小为多少以内的时候fetch task生效,默认1073741824 byte = 1G。
<property>
<name>hive.fetch.task.conversion.threshold</name>
<value>1073741824</value>
<description>
Input threshold for applying hive.fetch.task.conversion. If target table is native, input length
is calculated by summation of file lengths. If it's not native, storage handler for the table
can optionally implement org.apache.hadoop.hive.ql.metadata.InputEstimator interface.
</description>
</property>
hive.fetch.task.aggr
对于没有group by的聚合查询,比如select count(*) from src,这种最终都会在一个reduce中执行,像这种查询,可以把这个置为true将将其转换为fetch task,这可能会节约一些时间。
<property>
<name>hive.fetch.task.aggr</name>
<value>false</value>
<description>
Aggregation queries with no group-by clause (for example, select count(*) from src) execute
final aggregations in single reduce task. If this is set true, Hive delegates final aggregation
stage to fetch task, possibly decreasing the query time.
</description>
</property>
.
Hive笔记之Fetch Task的更多相关文章
- [转]Hive:简单查询不启用Mapreduce job而启用Fetch task
转自:http://www.iteblog.com/archives/831 如果你想查询某个表的某一列,Hive默认是会启用MapReduce Job来完成这个任务,如下: hive> SEL ...
- Hive基础(3)---Fetch Task(转)
我们在执行hive代码的时候,一条简单的命令大部分都会转换成为mr代码在后台执行,但是有时候我们仅仅只是想获取一部分数据而已,仅仅是获取数据,还需要转化成为mr去执行吗?那个也太浪费时间和内存啦,所以 ...
- Hive快捷查询:不启用Mapreduce job启用Fetch task三种方式介绍
如果查询表的某一列,Hive中默认会启用MapReduce job来完成这个任务,如下: hive>select id,name from m limit 10;--执行时hive会启用MapR ...
- Hive快捷查询:不启用Mapreduce job启用Fetch task
启用MapReduce Job是会消耗系统开销的.对于这个问题,从Hive0.10.0版本开始,对于简单的不需要聚合的类似SELECT <col> from <table> L ...
- 011-HQL中级1-Hive快捷查询:不启用Mapreduce job启用Fetch task三种方式介绍
如果你想查询某个表的某一列,Hive默认是会启用MapReduce Job来完成这个任务,如下: hive; Total MapReduce jobs Launching Job out since ...
- Hive笔记——技术点汇总
目录 · 概况 · 手工安装 · 引言 · 创建HDFS目录 · 创建元数据库 · 配置文件 · 测试 · 原理 · 架构 · 与关系型数据库对比 · API · WordCount · 命令 · 数 ...
- Hive笔记--sql语法详解及JavaAPI
Hive SQL 语法详解:http://blog.csdn.net/hguisu/article/details/7256833Hive SQL 学习笔记(常用):http://blog.sina. ...
- 【Hive】Hive笔记:Hive调优总结——数据倾斜,join表连接优化
数据倾斜即为数据在节点上分布不均,是常见的优化过程中常见的需要解决的问题.常见的Hive调优的方法:列剪裁.Map Join操作. Group By操作.合并小文件. 一.表现 1.任务进度长度为99 ...
- Hive 笔记
DESCRIBE EXTENDED mydb.employees DESCRIBE EXTENDED mydb.employees DESCRIBE EXTENDED mydb.employees ...
随机推荐
- hadoop-lzo 安装配置
在hive中要想使用lzo的格式,需要配置安装好lzo工具并且在hadoop的core-site.xml与mapred-site.xml中配置相应的配置 一.编译安装lzo与lzop 在 ...
- js中判断是否包含某个字符串
1,字符串中是否包含 str.indexOf("3")indexOf() 方法可返回某个指定的字符串值在字符串中首次出现的位置.如果要检索的字符串值没有出现,则该方法返回 -1. ...
- 运用fancybox弹出div的方式弹出视频界面
fancybox可以弹出很多窗体,甚至一个swf格式的小视频.但这样的swf视频播放的时候并没有任何的控件.只能重头看到尾,或者关闭.我们可以利用fancybox弹出div盒子的方式配合html5很快 ...
- Daily Scrum NO.6
会议概况 这两日又是由于编译deadline和数据库课程设计使得我们的进度进行缓慢.但是项目的进程仍然在可掌控的范围之内,时间虽然紧,但是应该最终能够实现Beta版本. 这次会议我们总结了之前5个正常 ...
- LINUX内核分析第四周学习总结——扒开系统调用的“三层皮”
LINUX内核分析第四周学习总结--扒开系统调用的"三层皮" 标签(空格分隔): 20135321余佳源 余佳源 原创作品转载请注明出处 <Linux内核分析>MOOC ...
- C++:继承访问属性(public/protected/private)
• 公有继承(public) 公有继承在C++中是最常用的一种继承方式,我们先来看一个示例: #include<iostream> using namespace std; class F ...
- A-Softmax的总结及与L-Softmax的对比——SphereFace
A-Softmax的总结及与L-Softmax的对比--SphereFace \(\quad\)[引言]SphereFace在MegaFace数据集上识别率在2017年排名第一,用的A-Softmax ...
- 『编程题全队』Beta 阶段冲刺博客集合
『编程题全队』Beta 阶段冲刺博客集合 »敏捷冲刺 日期:2018.5.23 博客连接:『编程题全队』Scrum 冲刺博客 »Day1 日期:2018.5.23 博客连接:『编程题全队』Beta 阶 ...
- PAT 甲级 1096 Consecutive Factors
https://pintia.cn/problem-sets/994805342720868352/problems/994805370650738688 Among all the factors ...
- java自定义注解学习(一)_demo小练习
自定义注解 现在大家开发过程中,经常会用到注解. 比如@Controller 等等,但是有时候也会碰到自定义注解,在开发中公司的记录日志就用到了自定义注解.身为渣渣猿还是有必要学习下自定义注解的. 这 ...