oracle 内连接(inner join)、外连接(outer join)、全连接(full join)
转自:https://premier9527.iteye.com/blog/1659689
建表语句:
create table EMPLOYEE
(
EID NUMBER,
DEPTID NUMBER,
ENAME VARCHAR2(200)
)
create table DEPT
(
DEPTID NUMBER,
DEPTNAME VARCHAR2(200)
)
oracle中的连接可分为,内连接(inner join)、外连接(outer join)、全连接(full join),不光是Oracle,其他很多的数据库也都有这3种连接查询方式
一、内连接inner join,这是我们经常用的查询方式,比如select * from A inner join B on A.field1=B.field2,个人认为,这样的内连接查询与下面的查询等效,select * from A,B where A.field1=B.field2,内连接查询只能查询出匹配的记录,匹配不上的记录时无法查询出来的 。
select * from dept inner join employee on dept.deptid=employee.deptid

select * from dept , employee where dept.deptid=employee.deptid

二、外连接outer join,可进一步分为左外连接left outer join和右外连接right outer join,具体说一下左外连接和右外连接查询的特点,有2个表,部门表和职工表,一个部门下可以有多个职工,一个职工只能对应一个部门,所以部门和职工时1对多的关系,设计表如下

比如现在有需求1,要进行部门表和职工表的关联查询,并要查询出所有的部门信息,这时候,下面的左连接查询就能够查询出想要的结果,左连接就是以left join前面的表为主表,即使有些记录关联不上,主表的信息能够查询出来的
select * from dept left outer join employee on dept.deptid=employee.deptid
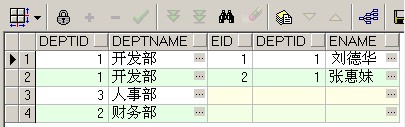
比如现在有需求2,要进行部门表和职工表的关联查询,并要查询出所有的职工信息,这时候,下面的右连接查询就能够查询出想要的结果,右连接就是以right join后面的表为主表,即使有些记录关联不上,主表的信息能够查询出来
select * from dept right outer join employee on dept.deptid=employee.deptid
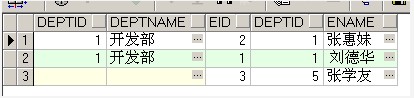
在介绍另外的一种写法,同样达到外连接的效果,大家可以尝试使用。比如在需求1中,下面的查询语句与需求1中给出的左连接语句等效!
select * from dept ,employee where dept.deptid=employee.deptid(+)
总之,外连接就是在关联不上的时候,把其中的部分信息查询出来
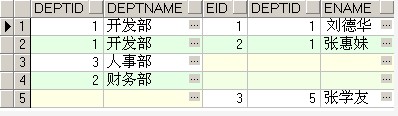
三、全连接full join,语法为full join ... on ...,全连接的查询结果是左外连接和右外连接查询结果的并集,即使一些记录关联不上,也能够把部分信息查询出来
select * from dept full join employee on dept.deptid=employee.deptid
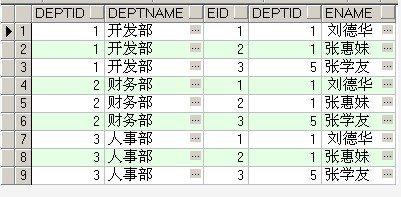
select * from dept full join employee on 1=1
oracle 内连接(inner join)、外连接(outer join)、全连接(full join)的更多相关文章
- R7—左右内全连接详解
在SQL查询中,经常会用到左连接.右连接.内连接.全连接,那么在R中如何实现这些功能,今天来讲一讲! SQL回顾 原理 # 连接可分为以下几类: 内连接.(典型的连接运算,使用像 = 或 ...
- mysql 全连接和 oracle 全连接查询、区别
oracle的全连接查询可以直接用full on,但是在mysql中没有full join,mysql使用union实现全连接. oracle的全连接 select * from a full joi ...
- 基于深度学习和迁移学习的识花实践——利用 VGG16 的深度网络结构中的五轮卷积网络层和池化层,对每张图片得到一个 4096 维的特征向量,然后我们直接用这个特征向量替代原来的图片,再加若干层全连接的神经网络,对花朵数据集进行训练(属于模型迁移)
基于深度学习和迁移学习的识花实践(转) 深度学习是人工智能领域近年来最火热的话题之一,但是对于个人来说,以往想要玩转深度学习除了要具备高超的编程技巧,还需要有海量的数据和强劲的硬件.不过 Tens ...
- Tensorflow 多层全连接神经网络
本节涉及: 身份证问题 单层网络的模型 多层全连接神经网络 激活函数 tanh 身份证问题新模型的代码实现 模型的优化 一.身份证问题 身份证号码是18位的数字[此处暂不考虑字母的情况],身份证倒数第 ...
- 五分钟带你读懂 TCP全连接队列(图文并茂)
爱生活,爱编码,微信搜一搜[架构技术专栏]关注这个喜欢分享的地方. 本文 架构技术专栏 已收录,有各种视频.资料以及技术文章. 一.问题 今天有个小伙伴跑过来告诉我有个奇怪的问题需要协助下,问题确实也 ...
- TCP全连接队列和半连接队列已满之后的连接建立过程抓包分析[转]
最近项目需要做单机100万长连接与高并发的服务器,我们开发完服务器以后,通过自己搭的高速压测框架压测服务端的时候,发生了奇怪的现象,就是服务端莫名其妙的少接收了连接,造成了数据包的丢失,通过网上查资料 ...
- Caffe源码阅读(1) 全连接层
Caffe源码阅读(1) 全连接层 发表于 2014-09-15 | 今天看全连接层的实现.主要看的是https://github.com/BVLC/caffe/blob/master/src ...
- 【转】关于TCP 半连接队列和全连接队列
摘要: # 关于TCP 半连接队列和全连接队列 > 最近碰到一个client端连接异常问题,然后定位分析并查阅各种资料文章,对TCP连接队列有个深入的理解 > > 查资料过程中发现没 ...
- 关于TCP 半连接队列和全连接队列
关于TCP 半连接队列和全连接队列 http://jm.taobao.org/2017/05/25/525-1/ 发表于 2017-05-25 | 作者 蛰剑 | 分类于 网络 ...
- 机器不学习:CNN入门讲解-为什么要有最后一层全连接
哈哈哈,又到了讲段子的时间 准备好了吗? 今天要说的是CNN最后一层了,CNN入门就要讲完啦..... 先来一段官方的语言介绍全连接层(Fully Connected Layer) 全连接层常简称为 ...
随机推荐
- 《Java并发编程实战》笔记-synchronized和ReentrantLock
在一些内置锁无法满足需求的情况下,ReentrantLock可以作为一种高级工具.当震要一些高级功能时才应该使用ReentrantLock,这些功能包括:可定时的.可轮询的与可中断的锁获取操作,公平队 ...
- Dubbo(5)优化:接口抽取以及依赖版本统一
优化点: 1.在上面provider和consumer程序中都存在DemoProviderService接口了,两个项目中存在同样的东西,代码多余以及不方便管理: 正式的项目中存在很多的接口的,将统一 ...
- PAT 乙级 1029 旧键盘(20) C++版
1029. 旧键盘(20) 时间限制 200 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 CHEN, Yue 旧键盘上坏了几个键,于是在敲一段文字的 ...
- Scala集合类型详解
Scala集合 Scala提供了一套很好的集合实现,提供了一些集合类型的抽象. Scala 集合分为可变的和不可变的集合. 可变集合可以在适当的地方被更新或扩展.这意味着你可以修改,添加,移除一个集合 ...
- [前端] html+css+javascript 实现选项卡切换效果
用html+css+js实现选项卡切换效果使用之前学过的综合知识,实现一个新闻门户网站上的常见选项卡效果: 文字素材:房产: 275万购昌平邻铁三居 总价20万买一居 200万内购五环三居 140万安 ...
- [转][html]radio 获取选中状态
方法一: if ($("#checkbox-id").get(0).checked) { // do something } 方法二: if($('#checkbox-id').i ...
- UnicodeString基本操作(Ring0)
#include "Unicode_String_Ring0.h" //bp Unicode_String_Ring0!DriverEntry NTSTATUS DriverEnt ...
- rhel7.0解决:This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
看这篇文章前,先说一下我的实际情况.本来要部署docker服务的,然后yum安装任何软件都不起效果,最后通过老师远程的帮助,最后成功安装上docker,老师的解决办法就是忽略这个问题,直接自己配置网络 ...
- [UE4]UMG和关卡坐标变换、旋转小地图
一.优化上一节的蓝图,新建一个函数addFlagToCanvas(动态添加图标到Canvas) 二. 分析地图坐标系和UMG坐标系 要根据实际情况分析关卡坐标系. UserWidget中的坐标系 三. ...
- [UE4]在UI中获取玩家角色实例