Kaggle大数据竞赛平台入门
Kaggle大数据竞赛平台入门
大数据竞赛平台,国内主要是天池大数据竞赛和DataCastle,国外主要就是Kaggle.Kaggle是一个数据挖掘的竞赛平台,网站为:https://www.kaggle.com/.很多的机构,企业将问题,描述,期望发布在Kaggle上,以竞赛的方式向广大的数据科学家征集解决方案,体现了集体智慧这一思想.每个人在网站上注册后,都可以下载感兴趣项目的数据集,分析数据,构造模型,解决问题提交结果.按照结果的好坏会有一个排名,成绩优异者还可能获得奖金/面试机会等.
图1展示了进入Kaggle官网后显示的正在进行的比赛,这些比赛的类型是不同的,可以进行筛选显示,有All Categories,Faatured,Recruitment,Research,Playground,Getting Started,In Class这7个选项.显示为Featured的比赛(左侧有粉红色条条)一般奖金比较丰厚,竞争也比较大;显示为Research的比赛(左侧有黄色条条),奖金少一些;显示为Recruitment的比赛,虽然没有奖金,但是却可以获得发布项目公司的实习/面试机会,这也给企业招聘人才提供了另外一种方式.显示为Playground的为练习赛,主要用于初学者练手,对于初学者,建议从这里开始.Getting Started里面手把手教你一步一步地进行数据挖掘,是很好的入门教程.除了这些公开比赛,Kaggle还会想活跃的参与者提供私下的比赛,以及为大学团体提供Kaggle-In-Class项目.Kaggle的博客No Free Hunch也是一个好的学习去处,提供了Data Science News,Kaggle News,Kernels,Tutorials,以及Winner's Interviews这些栏目.
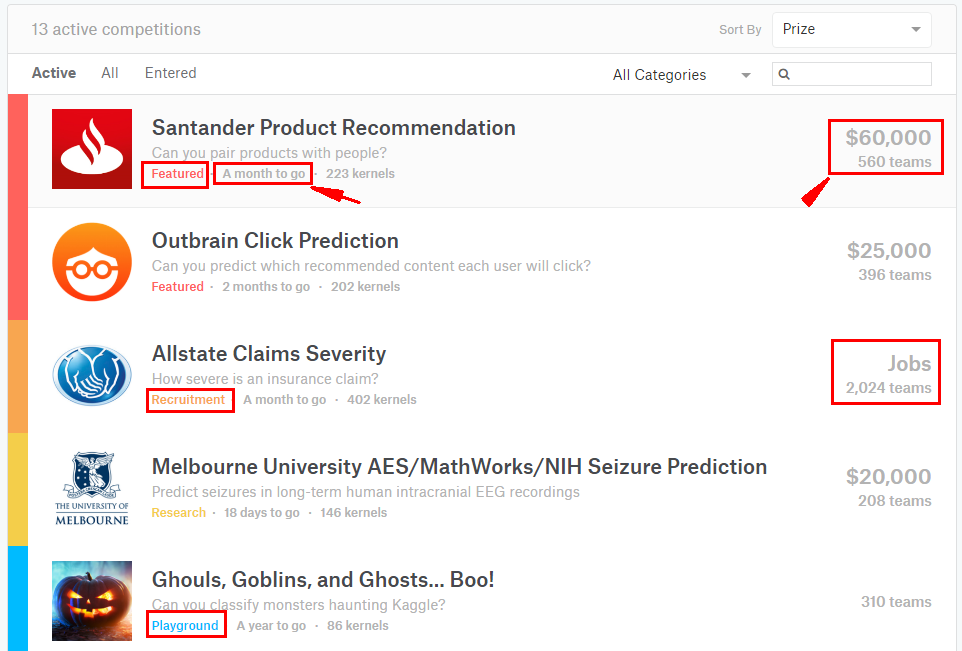
图1 Kaggle首页
比赛流程:
1.进去感兴趣的竞赛项目,下载数据集(csv格式),数据集中一般包括训练数据集和测试数据集,查看数据描述和任务描述,明确需求;
2.用你擅长的任何语言或者算法来构建模型,用训练集来训练,然后用训练好的模型推测测试集的labels,生成一个测试集labels作为最终的提交文件;
3.系统会从所提交文件中选取25%的数据进行初评,根据评测结果得到准确率和排名.在比赛结束时,采用剩下的75%的数据进行终评,作为最后的准确率.
Kernels:
Kernels提供了数据分析的环境,数据集,代码和输出样式,点击进去是下面这样的: 这类似于Jupyper Notebook.在这里面可以直接编译python,可以在code和markdown之间自由切换,可以很方便地复现和分享.还有一点就是你可能不需要将数据集下载下来,也不需要配置本地的python以及各种库(比如pandas,numpy等),直接在网页上进行数据挖掘.Kernel上还可以分享代码(初学者好的学习去处),在Forum(论坛)回答问题还可以积分.

参考文献:
[1] Kaggle机器学习竞赛冠军及优胜者的源代码汇总: http://suanfazu.com/t/kaggle/230
[2] Approaching (Almost) Any Machine Learning Problem | Abhishek Thakur
Kaggle大数据竞赛平台入门的更多相关文章
- 大数据竞赛平台——Kaggle 入门
Reference: http://blog.csdn.net/witnessai1/article/details/52612012 Kaggle是一个数据分析的竞赛平台,网址:https://ww ...
- 大数据竞赛平台——Kaggle 入门篇
这篇文章适合那些刚接触Kaggle.想尽快熟悉Kaggle并且独立完成一个竞赛项目的网友,对于已经在Kaggle上参赛过的网友来说,大可不必耗费时间阅读本文.本文分为两部分介绍Kaggle,第一部分简 ...
- 大数据竞赛平台——Kaggle 入门(转)
先马克一下:http://blog.csdn.net/u012162613/article/details/41929171
- 大数据竞赛平台Kaggle案例实战
Kaggle是由联合创始人.首席执行官安东尼·高德布卢姆(Anthony Goldbloom)2010年在墨尔本创立的,主要为开发商和数据科学家提供举办机器学习竞赛.托管数据库.编写和分享代码的平台. ...
- GitHub 干货 | 各大数据竞赛 Top 解决方案开源汇总
AI 科技评论编者按:现在,越来越多的企业.高校以及学术组织机构通过举办各种类型的数据竞赛来「物色」数据科学领域的优秀人才,并借此激励他们为某一数据领域或应用场景找到具有突破性意义的方案,也为之后的数 ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- 大数据:Hadoop入门
大数据:Hadoop入门 一:什么是大数据 什么是大数据: (1.)大数据是指在一定时间内无法用常规软件对其内容进行抓取,管理和处理的数据集合,简而言之就是数据量非常大,大到无法用常规工具进行处理,如 ...
- 大数据计算平台Spark内核全面解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着Spark在大数据计算领域的暂露头角,越来越多的 ...
- 阿里大数据竞赛season1 总结
关于样本测试集和训练集数量上,一般是选择训练集数量不小于测试集,也就是说训练集选取6k可能还不够,大家可以多尝试得到更好的效果: 2. 有人提出归一化方面可能有问题,大家可以查查其他的归一化方法,但是 ...
随机推荐
- 顺序表的C、C++实现
一个线性表表实现,函数声明放在 line_list.h 头文件汇总,函数定义放在line_list.c 中,main.c 用来测试各个函数. 1.文件 line_list.h // line_list ...
- mongoDB学习--建库、删库、插入、更新
在讲之前我们说一下mongoDB的一些基本概念,我们对比关系型数据库能更直观的理解 SQL术语/概念 MongoDB术语/概念 说明 database database 数据库 table colle ...
- String类的一些细节
先看一段代码: public static void main(String[] args) { String a = "a"+"b"+1; ...
- Luogu4768 NOI2018归程(最短路径+kruskal重构树)
按海拔从大到小合并建出kruskal重构树,这样就能知道开车能到达哪些点,对这些点到1的最短路取min即可.最难的部分在于多组数据的初始化和数组大小的设置. #include<iostream& ...
- Teams UVA - 11609(快速幂板题)
写的话就是排列组合...但能化简...ΣC(n,i)*C(i,1) 化简为n*2^(n-1) ; #include <iostream> #include <cstdio> # ...
- 【刷题】BZOJ 2287 【POJ Challenge】消失之物
Description ftiasch 有 N 个物品, 体积分别是 W1, W2, ..., WN. 由于她的疏忽, 第 i 个物品丢失了. "要使用剩下的 N - 1 物品装满容积为 x ...
- 【题解】 bzoj1503: [NOI2004]郁闷的出纳员 (Splay)
bzoj1503,懒得复制,戳我戳我 Solution: 我知不知道我是那根筋抽了突然来做splay,调了起码\(3h+\),到第二天才改出来(我好菜啊),当做训练调错吧 一个裸的splay,没啥好说 ...
- 【ARC076D/F】Exhausted?
Description 题目链接 Solution 场上尝试使用优化建图网络流实现,结果T到怀疑人生. 鉴于这是个匹配问题,考虑用贪心做一下. 先退一步,想一下如果每一个人只有\([1 ...
- 14.会场安排问题(L4)
时间限制:3000 ms | 内存限制:65535 KB 难度:4 描述 学校的小礼堂每天都会有许多活动,有时间这些活动的计划时间会发生冲突,需要选择出一些活动进行举办.小刘的工作就是安排学校 ...
- yolo2详解
转自:https://blog.csdn.net/u014380165/article/details/77961414 YOLOV2要是YOLO的升级版(Better faster) Better ...