yolo源码解析(一)
原文:https://www.cnblogs.com/zyly/p/9534063.html
yolo源码来源于网址:https://github.com/hizhangp/yolo_tensorflow
在讲解源码之前,我们需要做一些准备工作:
- 下载源码,本文所使用的yolo源码来源于网址:https://github.com/hizhangp/yolo_tensorflow
- 下载训练所使用的数据集,我们仍然使用以VOC 2012数据集为例,下载地址为:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar。
- yolo源码所在目录下,创建一个目录data,然后在data里面创建一个pascal_voc目录,用来保存与VOC 2012数据集相关的数据,我们把下载好的数据集解压到该目录下,其中VOCdevkit为数据集解压得到的文件,剩余三个文件夹我们先不用理会,后面会详细介绍
- 下载与训练模型,即YOLO_small文件,我们把下载好之后的文件解压放在weights文件夹下面。
根据自己的需求修改配置文件yolo/config.py。
- 运行train.py文件,开始训练。
- 运行test.py文件,开始测试。
二 yolo代码文件结构
我们来粗略的介绍一下每个文件的功能:
- data文件夹,上面已经说过了,存放数据集以及训练时生成的模型,缓存文件。
- test文件夹,用来存放测试时用到的图片。
- utils文件夹,包含两个文件一个是pascal_voc.py,主要用来获取训练集图片文件,以及生成对应的标签文件,为yolo网络训练做准备。另一个文件是timer.py用来计时。
- yolo文件夹,也包含两个文件,config.py包含yolo网络的配置参数,yolo_net.py文件包含yolo网络的结构。
- train.py文件用来训练yolo网络。
- test.py文件用来测试yolo网络。
三 config.py文件讲解
我们先从配置文件说起,代码如下:
# -*- coding: utf-8 -*-
"""
Created on Tue Jun 12 12:08:15 2018 @author: lenovo
""" '''
配置参数
''' import os #
# 数据集路径,和模型检查点文件路径
# DATA_PATH = 'data' #所有数据所在的根目录 PASCAL_PATH = os.path.join(DATA_PATH, 'pascal_voc') #VOC2012数据集所在的目录 CACHE_PATH = os.path.join(PASCAL_PATH, 'cache') #保存生成的数据集标签缓冲文件所在文件夹 OUTPUT_DIR = os.path.join(PASCAL_PATH, 'output') #保存生成的网络模型和日志文件所在的文件夹 WEIGHTS_DIR = os.path.join(PASCAL_PATH, 'weights') #检查点文件所在的目录 #WEIGHTS_FILE = None WEIGHTS_FILE = os.path.join(WEIGHTS_DIR, 'YOLO_small.ckpt') #VOC 2012数据集类别名
CLASSES = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant', 'sheep', 'sofa',
'train', 'tvmonitor']
#使用水平镜像,扩大一倍数据集?
FLIPPED = True '''
网络模型参数
''' #图片大小
IMAGE_SIZE = 448 #单元格大小S 一共有CELL_SIZExCELL_SIZE个单元格
CELL_SIZE = 7 #每个单元格边界框的个数B
BOXES_PER_CELL = 2
#泄露修正线性激活函数 系数
ALPHA = 0.1
#控制台输出信息
DISP_CONSOLE = False #损失函数 的权重设置
OBJECT_SCALE = 1.0 #有目标时,置信度权重
NOOBJECT_SCALE = 1.0 #没有目标时,置信度权重
CLASS_SCALE = 2.0 #类别权重
COORD_SCALE = 5.0 #边界框权重 '''
训练参数设置
''' GPU = ''
#学习率
LEARNING_RATE = 0.0001
#退化学习率衰减步数
DECAY_STEPS = 30000
#衰减率
DECAY_RATE = 0.1
STAIRCASE = True
#批量大小
BATCH_SIZE = 45
#最大迭代次数
MAX_ITER = 15000
#日志文件保存间隔步
SUMMARY_ITER = 10
#模型保存间隔步
SAVE_ITER = 500 '''
测试时的相关参数
'''
#格子有目标的置信度阈值
THRESHOLD = 0.2
#非极大值抑制 IoU阈值
IOU_THRESHOLD = 0.5
各个参数我已经在上面注释了,下面就不在重复了。下面我们来介绍yolo网络的构建。
四 yolo_net.py文件讲解
第一部分:
def __init__(self, is_training=True):
'''
构造函数
利用 cfg 文件对网络参数进行初始化,同时定义网络的输入和输出 size 等信息,
其中 offset 的作用应该是一个定长的偏移
boundery1和boundery2 作用是在输出中确定每种信息的长度(如类别,置信度等)。
其中 boundery1 指的是对于所有的 cell 的类别的预测的张量维度,所以是 self.cell_size * self.cell_size * self.num_class
boundery2 指的是在类别之后每个cell 所对应的 bounding boxes 的数量的总和,所以是self.boundary1 + self.cell_size * self.cell_size * self.boxes_per_cell args:
is_training:训练?
'''
#VOC 2012数据集类别名
self.classes = cfg.CLASSES
#类别个数C 20
self.num_class = len(self.classes)
#网络输入图像大小448, 448 x 448
self.image_size = cfg.IMAGE_SIZE
#单元格大小S=7 将图像分为SxS的格子
self.cell_size = cfg.CELL_SIZE
#每个网格边界框的个数B=2
self.boxes_per_cell = cfg.BOXES_PER_CELL
#网络输出的大小 S*S*(B*5 + C) = 1470
self.output_size = (self.cell_size * self.cell_size) *\
(self.num_class + self.boxes_per_cell * 5)
#图片的缩放比例 64
self.scale = 1.0 * self.image_size / self.cell_size
'''#将网络输出分离为类别和置信度以及边界框的大小,输出维度为7*7*20 + 7*7*2 + 7*7*2*4=1470'''
#7*7*20
self.boundary1 = self.cell_size * self.cell_size * self.num_class
#7*7*20+7*7*2
self.boundary2 = self.boundary1 +\
self.cell_size * self.cell_size * self.boxes_per_cell #代价函数 权重
self.object_scale = cfg.OBJECT_SCALE #1
self.noobject_scale = cfg.NOOBJECT_SCALE #1
self.class_scale = cfg.CLASS_SCALE #2.0
self.coord_scale = cfg.COORD_SCALE #5.0 #学习率0.0001
self.learning_rate = cfg.LEARNING_RATE
#批大小 45
self.batch_size = cfg.BATCH_SIZE
#泄露修正线性激活函数 系数0.1
self.alpha = cfg.ALPHA #偏置 形状[7,7,2]
self.offset = np.transpose(np.reshape(np.array(
[np.arange(self.cell_size)] * self.cell_size * self.boxes_per_cell),
(self.boxes_per_cell, self.cell_size, self.cell_size)), (1, 2, 0)) #输入图片占位符 [NONE,image_size,image_size,3]
self.images = tf.placeholder(
tf.float32, [None, self.image_size, self.image_size, 3],
name='images')
#构建网络 获取YOLO网络的输出(不经过激活函数的输出) 形状[None,1470]
self.logits = self.build_network(
self.images, num_outputs=self.output_size, alpha=self.alpha,
is_training=is_training) if is_training:
#设置标签占位符 [None,S,S,5+C] 即[None,7,7,25]
self.labels = tf.placeholder(
tf.float32,
[None, self.cell_size, self.cell_size, 5 + self.num_class])
#设置损失函数
self.loss_layer(self.logits, self.labels)
#加入权重正则化之后的损失函数
self.total_loss = tf.losses.get_total_loss()
#将损失以标量形式显示,该变量命名为total_loss
tf.summary.scalar('total_loss', self.total_loss)
第二部分:build_network
这部分主要是实现了 yolo 网络模型的构成,可以清楚的看到网络的组成,而且为了使程序更加简洁,构建网络使用的是 TensorFlow 中的 slim 模块,主要的函数有slim.arg_scope slim.conv2d slim.fully_connected 和 slim.dropoout等,具体程序如下所示:
def build_network(self,
images,
num_outputs,
alpha,
keep_prob=0.5,
is_training=True,
scope='yolo'):
'''
构建YOLO网络 args:
images:输入图片占位符 [None,image_size,image_size,3] 这里是[None,448,448,3]
num_outputs:标量,网络输出节点数 1470
alpha:泄露修正线性激活函数 系数0.1
keep_prob:弃权 保留率
is_training:训练?
scope:命名空间名 return:
返回网络最后一层,激活函数处理之前的值 形状[None,1470]
'''
#定义变量命名空间
with tf.variable_scope(scope):
#定义共享参数 使用l2正则化
with slim.arg_scope(
[slim.conv2d, slim.fully_connected],
activation_fn=leaky_relu(alpha),
weights_regularizer=slim.l2_regularizer(0.0005),
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01)
):
logging.info('image shape{0}'.format(images.shape))
#pad_1 填充 454x454x3
net = tf.pad(
images, np.array([[0, 0], [3, 3], [3, 3], [0, 0]]),
name='pad_1')
logging.info('Layer pad_1 {0}'.format(net.shape))
#卷积层conv_2 s=2 (n-f+1)/s向上取整 224x224x64
net = slim.conv2d(
net, 64, 7, 2, padding='VALID', scope='conv_2')
logging.info('Layer conv_2 {0}'.format(net.shape))
#池化层pool_3 112x112x64
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_3')
logging.info('Layer pool_3 {0}'.format(net.shape))
#卷积层conv_4、3x3x192 s=1 n/s向上取整 112x112x192
net = slim.conv2d(net, 192, 3, scope='conv_4')
logging.info('Layer conv_4 {0}'.format(net.shape))
#池化层pool_5 56x56x192
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_5')
logging.info('Layer pool_5 {0}'.format(net.shape))
#卷积层conv_6、1x1x128 s=1 n/s向上取整 56x56x128
net = slim.conv2d(net, 128, 1, scope='conv_6')
logging.info('Layer conv_6 {0}'.format(net.shape))
#卷积层conv_7、3x3x256 s=1 n/s向上取整 56x56x256
net = slim.conv2d(net, 256, 3, scope='conv_7')
logging.info('Layer conv_7 {0}'.format(net.shape))
#卷积层conv_8、1x1x256 s=1 n/s向上取整 56x56x256
net = slim.conv2d(net, 256, 1, scope='conv_8')
logging.info('Layer conv_8 {0}'.format(net.shape))
#卷积层conv_9、3x3x512 s=1 n/s向上取整 56x56x512
net = slim.conv2d(net, 512, 3, scope='conv_9')
logging.info('Layer conv_9 {0}'.format(net.shape))
#池化层pool_10 28x28x512
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_10')
logging.info('Layer pool_10 {0}'.format(net.shape))
#卷积层conv_11、1x1x256 s=1 n/s向上取整 28x28x256
net = slim.conv2d(net, 256, 1, scope='conv_11')
logging.info('Layer conv_11 {0}'.format(net.shape))
#卷积层conv_12、3x3x512 s=1 n/s向上取整 28x28x512
net = slim.conv2d(net, 512, 3, scope='conv_12')
logging.info('Layer conv_12 {0}'.format(net.shape))
#卷积层conv_13、1x1x256 s=1 n/s向上取整 28x28x256
net = slim.conv2d(net, 256, 1, scope='conv_13')
logging.info('Layer conv_13 {0}'.format(net.shape))
#卷积层conv_14、3x3x512 s=1 n/s向上取整 28x28x512
net = slim.conv2d(net, 512, 3, scope='conv_14')
logging.info('Layer conv_14 {0}'.format(net.shape))
#卷积层conv_15、1x1x256 s=1 n/s向上取整 28x28x256
net = slim.conv2d(net, 256, 1, scope='conv_15')
logging.info('Layer conv_15 {0}'.format(net.shape))
#卷积层conv_16、3x3x512 s=1 n/s向上取整 28x28x512
net = slim.conv2d(net, 512, 3, scope='conv_16')
logging.info('Layer conv_16 {0}'.format(net.shape))
#卷积层conv_17、1x1x256 s=1 n/s向上取整 28x28x256
net = slim.conv2d(net, 256, 1, scope='conv_17')
logging.info('Layer conv_17 {0}'.format(net.shape))
#卷积层conv_18、3x3x512 s=1 n/s向上取整 28x28x512
net = slim.conv2d(net, 512, 3, scope='conv_18')
logging.info('Layer conv_18 {0}'.format(net.shape))
#卷积层conv_19、1x1x512 s=1 n/s向上取整 28x28x512
net = slim.conv2d(net, 512, 1, scope='conv_19')
logging.info('Layer conv_19 {0}'.format(net.shape))
#卷积层conv_20、3x3x1024 s=1 n/s向上取整 28x28x1024
net = slim.conv2d(net, 1024, 3, scope='conv_20')
logging.info('Layer conv_20 {0}'.format(net.shape))
#池化层pool_21 14x14x1024
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_21')
logging.info('Layer pool_21 {0}'.format(net.shape))
#卷积层conv_22、1x1x512 s=1 n/s向上取整 14x14x512
net = slim.conv2d(net, 512, 1, scope='conv_22')
logging.info('Layer conv_22 {0}'.format(net.shape))
#卷积层conv_23、3x3x1024 s=1 n/s向上取整 14x14x1024
net = slim.conv2d(net, 1024, 3, scope='conv_23')
logging.info('Layer conv_23 {0}'.format(net.shape))
#卷积层conv_24、1x1x512 s=1 n/s向上取整 14x14x512
net = slim.conv2d(net, 512, 1, scope='conv_24')
logging.info('Layer conv_24 {0}'.format(net.shape))
#卷积层conv_25、3x3x1024 s=1 n/s向上取整 14x14x1024
net = slim.conv2d(net, 1024, 3, scope='conv_25')
logging.info('Layer conv_25 {0}'.format(net.shape))
#卷积层conv_26、3x3x1024 s=1 n/s向上取整 14x14x1024
net = slim.conv2d(net, 1024, 3, scope='conv_26')
logging.info('Layer conv_26 {0}'.format(net.shape))
#pad_27 填充 16x16x2014
net = tf.pad(
net, np.array([[0, 0], [1, 1], [1, 1], [0, 0]]),
name='pad_27')
logging.info('Layer pad_27 {0}'.format(net.shape))
#卷积层conv_28、3x3x1024 s=2 (n-f+1)/s向上取整 7x7x1024
net = slim.conv2d(
net, 1024, 3, 2, padding='VALID', scope='conv_28')
logging.info('Layer conv_28 {0}'.format(net.shape))
#卷积层conv_29、3x3x1024 s=1 n/s向上取整 7x7x1024
net = slim.conv2d(net, 1024, 3, scope='conv_29')
logging.info('Layer conv_29 {0}'.format(net.shape))
#卷积层conv_30、3x3x1024 s=1 n/s向上取整 7x7x1024
net = slim.conv2d(net, 1024, 3, scope='conv_30')
logging.info('Layer conv_30 {0}'.format(net.shape))
#trans_31 转置[None,1024,7,7]
net = tf.transpose(net, [0, 3, 1, 2], name='trans_31')
logging.info('Layer trans_31 {0}'.format(net.shape))
#flat_32 展开 50176
net = slim.flatten(net, scope='flat_32')
logging.info('Layer flat_32 {0}'.format(net.shape))
#全连接层fc_33 512
net = slim.fully_connected(net, 512, scope='fc_33')
logging.info('Layer fc_33 {0}'.format(net.shape))
#全连接层fc_34 4096
net = slim.fully_connected(net, 4096, scope='fc_34')
logging.info('Layer fc_34 {0}'.format(net.shape))
#弃权层dropout_35 4096
net = slim.dropout(
net, keep_prob=keep_prob, is_training=is_training,
scope='dropout_35')
logging.info('Layer dropout_35 {0}'.format(net.shape))
#全连接层fc_36 1470
net = slim.fully_connected(
net, num_outputs, activation_fn=None, scope='fc_36')
logging.info('Layer fc_36 {0}'.format(net.shape))
return net
网络最后输出的是一个1470 维的张量(1470 = 7*7*30)。最后一层全连接层的内部如下图所示:

第三部分: calc_iou
这个函数的主要作用是计算两个 bounding box 之间的 IoU。输入是两个 5 维的bounding box,输出的两个 bounding Box 的IoU 。具体程序如下所示:
def calc_iou(self, boxes1, boxes2, scope='iou'):
"""calculate ious
这个函数的主要作用是计算两个 bounding box 之间的 IoU。输入是两个 5 维的bounding box,输出的两个 bounding Box 的IoU Args:
boxes1: 5-D tensor [BATCH_SIZE, CELL_SIZE, CELL_SIZE, BOXES_PER_CELL, 4] ====> (x_center, y_center, w, h)
boxes2: 5-D tensor [BATCH_SIZE, CELL_SIZE, CELL_SIZE, BOXES_PER_CELL, 4] ===> (x_center, y_center, w, h)
注意这里的参数x_center, y_center, w, h都是归一到[0,1]之间的,分别表示预测边界框的中心相对整张图片的坐标,宽和高
Return:
iou: 4-D tensor [BATCH_SIZE, CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
"""
with tf.variable_scope(scope):
# transform (x_center, y_center, w, h) to (x1, y1, x2, y2)
#把以前的中心点坐标和长和宽转换成了左上角和右下角的两个点的坐标
boxes1_t = tf.stack([boxes1[..., 0] - boxes1[..., 2] / 2.0, #左上角x
boxes1[..., 1] - boxes1[..., 3] / 2.0, #左上角y
boxes1[..., 0] + boxes1[..., 2] / 2.0, #右下角x
boxes1[..., 1] + boxes1[..., 3] / 2.0], #右下角y
axis=-1) boxes2_t = tf.stack([boxes2[..., 0] - boxes2[..., 2] / 2.0,
boxes2[..., 1] - boxes2[..., 3] / 2.0,
boxes2[..., 0] + boxes2[..., 2] / 2.0,
boxes2[..., 1] + boxes2[..., 3] / 2.0],
axis=-1) # calculate the left up point & right down point
#lu和rd就是分别求两个框相交的矩形的左上角的坐标和右下角的坐标,因为对于左上角,
#选择的是x和y较大的,而右下角是选择较小的,可以想想两个矩形框相交是不是这中情况
lu = tf.maximum(boxes1_t[..., :2], boxes2_t[..., :2]) #两个框相交的矩形的左上角(x1,y1)
rd = tf.minimum(boxes1_t[..., 2:], boxes2_t[..., 2:]) #两个框相交的矩形的右下角(x2,y2) # intersection 这个就是求相交矩形的长和宽,所以有rd-ru,相当于x1-x2和y1-y2,
#之所以外面还要加一个tf.maximum是因为删除那些不合理的框,比如两个框没交集,
#就会出现左上角坐标比右下角还大。
intersection = tf.maximum(0.0, rd - lu)
#inter_square这个就是求面积了,就是长乘以宽。
inter_square = intersection[..., 0] * intersection[..., 1] # calculate the boxs1 square and boxs2 square
#square1和square2这个就是求面积了,因为之前是中心点坐标和长和宽,所以这里直接用长和宽
square1 = boxes1[..., 2] * boxes1[..., 3]
square2 = boxes2[..., 2] * boxes2[..., 3] #union_square就是就两个框的交面积,因为如果两个框的面积相加,那就会重复了相交的部分,
#所以减去相交的部分,外面有个tf.maximum这个就是保证相交面积不为0,因为后面要做分母。
union_square = tf.maximum(square1 + square2 - inter_square, 1e-10) #最后有一个tf.clip_by_value,这个是将如果你的交并比大于1,那么就让它等于1,如果小于0,那么就
#让他变为0,因为交并比在0-1之间。
return tf.clip_by_value(inter_square / union_square, 0.0, 1.0)
这个函数中主要用到的函数有tf.stack tf.transpose 以及 tf.maximum,下面分别简单介绍一下这几个函数:
1. tf.stack(),定义为:def stack(values, axis=0, name="stack")。该函数的主要作用是对矩阵进行拼接,我们在 TensorFlow 源码中可以看到这句话***tf.stack([x, y, z]) = np.stack([x, y, z])***,也就是说,它和numpy 中的 stack 函数的作用是相同的。都是在指定轴的方向上对矩阵进行拼接。默认值是0。

tf.transpose,定义为def transpose(a, perm=None, name="transpose") 这个函数的作用是根据 perm 的值对矩阵 a 进行转置操作,返回数组的 dimension(尺寸、维度) i与输入的 perm[i]的维度相一致。如果未给定perm,默认设置为 (n-1…0),这里的 n 值是输入变量的 rank 。因此默认情况下,这个操作执行了一个正规(regular)的2维矩形的转置。

tf.maximum,定义为def maximum(x, y, name=None) 这个函数的作用是返回的是a,b之间的最大值。
第四部分:
loss_layer
这个函数的主要作用是计算 Loss。
代价函数是通过loss_layer()实现的,在代码中,我们优化以下多部分损失函数:
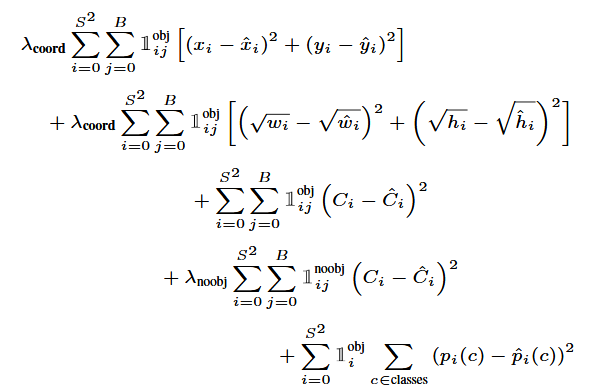
具体程序如下所示:
def loss_layer(self, predicts, labels, scope='loss_layer'):
'''
计算预测和标签之间的损失函数 args:
predicts:Yolo网络的输出 形状[None,1470]
0:7*7*20:表示预测类别
7*7*20:7*7*20 + 7*7*2:表示预测置信度,即预测的边界框与实际边界框之间的IOU
7*7*20 + 7*7*2:1470:预测边界框 目标中心是相对于当前格子的,宽度和高度的开根号是相对当前整张图像的(归一化的)
labels:标签值 形状[None,7,7,25]
0:1:置信度,表示这个地方是否有目标
1:5:目标边界框 目标中心,宽度和高度(没有归一化)
5:25:目标的类别
'''
with tf.variable_scope(scope):
'''#将网络输出分离为类别和置信度以及边界框的大小,输出维度为7*7*20 + 7*7*2 + 7*7*2*4=1470'''
#预测每个格子目标的类别 形状[45,7,7,20]
predict_classes = tf.reshape(
predicts[:, :self.boundary1],
[self.batch_size, self.cell_size, self.cell_size, self.num_class])
#预测每个格子中两个边界框的置信度 形状[45,7,7,2]
predict_scales = tf.reshape(
predicts[:, self.boundary1:self.boundary2],
[self.batch_size, self.cell_size, self.cell_size, self.boxes_per_cell])
#预测每个格子中的两个边界框,(x,y)表示边界框相对于格子边界框的中心 w,h的开根号相对于整个图片 形状[45,7,7,2,4]
predict_boxes = tf.reshape(
predicts[:, self.boundary2:],
[self.batch_size, self.cell_size, self.cell_size, self.boxes_per_cell, 4]) #标签的置信度,表示这个地方是否有框 形状[45,7,7,1]
response = tf.reshape(
labels[..., 0],
[self.batch_size, self.cell_size, self.cell_size, 1])
#标签的边界框 (x,y)表示边界框相对于整个图片的中心 形状[45,7,7,1,4]
boxes = tf.reshape(
labels[..., 1:5],
[self.batch_size, self.cell_size, self.cell_size, 1, 4])
#标签的边界框 归一化后 张量沿着axis=3重复两边,扩充后[45,7,7,2,4]
boxes = tf.tile(
boxes, [1, 1, 1, self.boxes_per_cell, 1]) / self.image_size
classes = labels[..., 5:] '''
predict_boxes_tran:offset变量用于把预测边界框predict_boxes中的坐标中心(x,y)由相对当前格子转换为相对当前整个图片 offset,这个是构造的[7,7,2]矩阵,每一行都是[7,2]的矩阵,值为[[0,0],[1,1],[2,2],[3,3],[4,4],[5,5],[6,6]]
这个变量是为了将每个cell的坐标对齐,后一个框比前一个框要多加1
比如我们预测了cell_size的每个中心点坐标,那么我们这个中心点落在第几个cell_size
就对应坐标要加几,这个用法比较巧妙,构造了这样一个数组,让他们对应位置相加
'''
#offset shape为[1,7,7,2] 如果忽略axis=0,则每一行都是 [[0,0],[1,1],[2,2],[3,3],[4,4],[5,5],[6,6]]
offset = tf.reshape(
tf.constant(self.offset, dtype=tf.float32),
[1, self.cell_size, self.cell_size, self.boxes_per_cell])
#shape为[45,7,7,2]
offset = tf.tile(offset, [self.batch_size, 1, 1, 1])
#shape为[45,7,7,2] 如果忽略axis=0 第i行为[[i,i],[i,i],[i,i],[i,i],[i,i],[i,i],[i,i]]
offset_tran = tf.transpose(offset, (0, 2, 1, 3))
#shape为[45,7,7,2,4] 计算每个格子中的预测边界框坐标(x,y)相对于整个图片的位置 而不是相对当前格子
#假设当前格子为(3,3),当前格子的预测边界框为(x0,y0),则计算坐标(x,y) = ((x0,y0)+(3,3))/7
predict_boxes_tran = tf.stack(
[(predict_boxes[..., 0] + offset) / self.cell_size, #x
(predict_boxes[..., 1] + offset_tran) / self.cell_size, #y
tf.square(predict_boxes[..., 2]), #width
tf.square(predict_boxes[..., 3])], axis=-1) #height #计算每个格子预测边界框与真实边界框之间的IOU [45,7,7,2]
iou_predict_truth = self.calc_iou(predict_boxes_tran, boxes) # calculate I tensor [BATCH_SIZE, CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
#这个是求论文中的1ijobj参数,[45,7,7,2] 1ijobj:表示网格单元i的第j个编辑框预测器’负责‘该预测
#先计算每个框交并比最大的那个,因为我们知道,YOLO每个格子预测两个边界框,一个类别。在训练时,每个目标只需要
#一个预测器来负责,我们指定一个预测器"负责",根据哪个预测器与真实值之间具有当前最高的IOU来预测目标。
#所以object_mask就表示每个格子中的哪个边界框负责该格子中目标预测?哪个边界框取值为1,哪个边界框就负责目标预测
#当格子中的确有目标时,取值为[1,1],[1,0],[0,1]
#比如某一个格子的值为[1,0],表示第一个边界框负责该格子目标的预测 [0,1]:表示第二个边界框负责该格子目标的预测
#当格子没有目标时,取值为[0,0]
object_mask = tf.reduce_max(iou_predict_truth, 3, keep_dims=True)
object_mask = tf.cast(
(iou_predict_truth >= object_mask), tf.float32) * response # calculate no_I tensor [CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
# noobject_mask就表示每个边界框不负责该目标的置信度,
#使用tf.onr_like,使得全部为1,再减去有目标的,也就是有目标的对应坐标为1,这样一减,就变为没有的了。[45,7,7,2]
noobject_mask = tf.ones_like(
object_mask, dtype=tf.float32) - object_mask # boxes_tran 这个就是把之前的坐标换回来(相对整个图像->相对当前格子),长和宽开方(原因在论文中有说明),后面求loss就方便。 shape为(4, 45, 7, 7, 2)
boxes_tran = tf.stack(
[boxes[..., 0] * self.cell_size - offset,
boxes[..., 1] * self.cell_size - offset_tran,
tf.sqrt(boxes[..., 2]),
tf.sqrt(boxes[..., 3])], axis=-1) #class_loss 分类损失,如果目标出现在网格中 response为1,否则response为0 原文代价函数公式第5项
#该项表名当格子中有目标时,预测的类别越接近实际类别,代价值越小 原文代价函数公式第5项
class_delta = response * (predict_classes - classes)
class_loss = tf.reduce_mean(
tf.reduce_sum(tf.square(class_delta), axis=[1, 2, 3]),
name='class_loss') * self.class_scale # object_loss 有目标物体存在的置信度预测损失 原文代价函数公式第3项
#该项表名当格子中有目标时,负责该目标预测的边界框的置信度越越接近预测的边界框与实际边界框之间的IOU时,代价值越小
object_delta = object_mask * (predict_scales - iou_predict_truth)
object_loss = tf.reduce_mean(
tf.reduce_sum(tf.square(object_delta), axis=[1, 2, 3]),
name='object_loss') * self.object_scale #noobject_loss 没有目标物体存在的置信度的损失(此时iou_predict_truth为0) 原文代价函数公式第4项
#该项表名当格子中没有目标时,预测的两个边界框的置信度越接近0,代价值越小
noobject_delta = noobject_mask * predict_scales
noobject_loss = tf.reduce_mean(
tf.reduce_sum(tf.square(noobject_delta), axis=[1, 2, 3]),
name='noobject_loss') * self.noobject_scale # coord_loss 边界框坐标损失 shape 为 [batch_size, 7, 7, 2, 1] 原文代价函数公式1,2项
#该项表名当格子中有目标时,预测的边界框越接近实际边界框,代价值越小
coord_mask = tf.expand_dims(object_mask, 4) #1ij
boxes_delta = coord_mask * (predict_boxes - boxes_tran)
coord_loss = tf.reduce_mean(
tf.reduce_sum(tf.square(boxes_delta), axis=[1, 2, 3, 4]),
name='coord_loss') * self.coord_scale #将所有损失放在一起
tf.losses.add_loss(class_loss)
tf.losses.add_loss(object_loss)
tf.losses.add_loss(noobject_loss)
tf.losses.add_loss(coord_loss) # 将每个损失添加到日志记录
tf.summary.scalar('class_loss', class_loss)
tf.summary.scalar('object_loss', object_loss)
tf.summary.scalar('noobject_loss', noobject_loss)
tf.summary.scalar('coord_loss', coord_loss) tf.summary.histogram('boxes_delta_x', boxes_delta[..., 0])
tf.summary.histogram('boxes_delta_y', boxes_delta[..., 1])
tf.summary.histogram('boxes_delta_w', boxes_delta[..., 2])
tf.summary.histogram('boxes_delta_h', boxes_delta[..., 3])
tf.summary.histogram('iou', iou_predict_truth)
五、train.py讲解
这部分代码主要实现的是对已经构建好的网络和损失函数利用数据进行训练,在训练过程中,对变量采用了指数平均数(exponential moving average (EMA))来提高整体的训练性能。同时,为了获得比较好的学习性能,对学习速率同向进行了指数衰减,使用了 exponential_decay 函数来实现这个功能。这个函数的具体计算公式如下所示:
$decayed_learning_rate=learning_rate∗decay_rate(globalstep/decaysteps) decayed\_learning\_rate = learning\_rate *decay\_rate ^ {(global_step / decay_steps)}$
在训练的同时,对我们的训练模型(网络权重)进行保存,这样以后可以直接进行调用这些权重;同时,每隔一定的迭代次数便写入 TensorBoard,这样在最后可以观察整体的情况。
class Solver(object):
def __init__(self, net, data):
self.net = net
self.data = data
self.weights_file = cfg.WEIGHT_FILE #网络权重
self.max_iter = cfg.MAX_ITER #最大迭代数目
self.initial_learning_rate = cfg.LEARNING_RATE
self.decay_steps = cfg.DECAY_STEPS
self.decay_rate = cfg.DECAY_RATE
self.staircase = cfg.STAIRCASE
self.summary_iter = cfg.SUMMARY_ITER
self.save_iter = cfg.SAVE_ITER
self.output_dir = os.path.join(
cfg.OUTPUT_PATH, datetime.datetime.now().strftime('%Y_%m_%d_%H_%M'))
if not os.path.exists(self.output_dir):
os.makedirs(self.output_dir)
self.save_cfg()
# tf.get_variable 和tf.Variable不同的一点是,前者拥有一个变量检查机制,
# 会检测已经存在的变量是否设置为共享变量,如果已经存在的变量没有设置为共享变量,
# TensorFlow 运行到第二个拥有相同名字的变量的时候,就会报错。
self.variable_to_restore = tf.global_variables()
self.restorer = tf.train.Saver(self.variable_to_restore, max_to_keep = None)
self.saver = tf.train.Saver(self.variable_to_restore, max_to_keep = None)
self.ckpt_file = os.path.join(self.output_dir, 'save.ckpt')
self.summary_op = tf.summary.merge_all()
self.writer = tf.summary.FileWriter(self.output_dir, flush_secs = 60)
self.global_step = tf.get_variable(
'global_step', [], initializer = tf.constant_initializer(0), trainable = False)
# 产生一个指数衰减的学习速率
self.learning_rate = tf.train.exponential_decay(
self.initial_learning_rate, self.global_step, self.decay_steps,
self.decay_rate, self.staircase, name = 'learning_rate')
self.optimizer = tf.train.GradientDescentOptimizer(
learning_rate = self.learning_rate).minimize(
self.net.total_loss, global_step = self.global_step)
self.ema = tf.train.ExponentialMovingAverage(decay = 0.9999)
self.average_op = self.ema.apply(tf.trainable_variables())
with tf.control_dependencies([self.optimizer]):
self.train_op = tf.group(self.average_op)
gpu_options = tf.GPUOptions()
config = tf.ConfigProto(gpu_options=gpu_options)
self.sess = tf.Session(config = config)
self.sess.run(tf.global_variables_initializer())
if self.weights_file is not None:
print('Restoring weights from: '+ self.weights_file)
self.restorer.restore(self.sess, self.weights_file)
self.writer.add_graph(self.sess.graph)
def train(self):
train_timer = Timer()
load_timer = Timer()
for step in range(1, self.max_iter+1):
load_timer.tic()
images, labels = self.data.get()
load_timer.toc()
feec_dict = {self.net.images: images, self.net.labels: labels}
if step % self.summary_iter == 0:
if step % (self.summary_iter * 10) == 0:
train_timer.tic()
summary_str, loss, _ = self.sess.run(
[self.summary_op, self.net.total_loss, self.train_op],
feed_dict = feec_dict)
train_timer.toc()
log_str = ('{} Epoch: {}, Step: {}, Learning rate : {},'
'Loss: {:5.3f}\nSpeed: {:.3f}s/iter,'
' Load: {:.3f}s/iter, Remain: {}').format(
datetime.datetime.now().strftime('%m/%d %H:%M:%S'),
self.data.epoch,
int(step),
round(self.learning_rate.eval(session = self.sess), 6),
loss,
train_timer.average_time,
load_timer.average_time,
train_timer.remain(step, self.max_iter))
print(log_str)
else:
train_timer.tic()
summary_str, _ = self.sess.run(
[self.summary_op, self.train_op],
feed_dict = feec_dict)
train_timer.toc()
self.writer.add_summary(summary_str, step)
else:
train_timer.tic()
self.sess.run(self.train_op, feed_dict = feec_dict)
train_timer.toc()
if step % self.save_iter == 0:
print('{} Saving checkpoint file to: {}'.format(
datetime.datetime.now().strftime('%m/%d %H:%M:%S'),
self.output_dir))
self.saver.save(self.sess, self.ckpt_file,
global_step = self.global_step)
def save_cfg(self):
with open(os.path.join(self.output_dir, 'config.txt'), 'w') as f:
cfg_dict = cfg.__dict__
for key in sorted(cfg_dict.keys()):
if key[0].isupper():
cfg_str = '{}: {}\n'.format(key, cfg_dict[key])
f.write(cfg_str)
六、test.py
最后给出test 部分的源码,这部分需要使用我们下载好的 “YOLO_small.ckpt” 权重文件,当然,也可以使用我们之前训练好的权重文件。
这部分的主要内容就是利用训练好的权重进行预测,得到预测输出后利用 OpenCV 的相关函数进行画框等操作。同时,还可以利用 OpenCV 进行视频处理,使程序能够实时地对视频流进行检测。因此,在阅读本段程序之前,大家应该对 OpenCV 有一个大致的了解。
具体代码如下所示:
class Detector(object):
def __init__(self, net, weight_file):
self.net = net
self.weights_file = weight_file
self.classes = cfg.CLASSES
self.num_class = len(self.classes)
self.image_size = cfg.IMAGE_SIZE
self.cell_size = cfg.CELL_SIZE
self.boxes_per_cell = cfg.BOXES_PER_CELL
self.threshold = cfg.THRESHOLD
self.iou_threshold = cfg.IOU_THRESHOLD
self.boundary1 = self.cell_size * self.cell_size * self.num_class
self.boundary2 = self.boundary1 + self.cell_size * self.cell_size * self.boxes_per_cell
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
print('Restoring weights from: ' + self.weights_file)
self.saver = tf.train.Saver()
self.saver.restore(self.sess, self.weights_file)
def draw_result(self, img, result):
for i in range(len(result)):
x = int(result[i][1])
y = int(result[i][2])
w = int(result[i][3] / 2)
h = int(result[i][4] / 2)
cv2.rectangle(img, (x - w, y - h), (x + w, y + h), (0, 255, 0), 2)
cv2.rectangle(img, (x - w, y - h - 20),
(x + w, y - h), (125, 125, 125), -1)
cv2.putText(img, result[i][0] + ' : %.2f' % result[i][5], (x - w + 5, y - h - 7),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1, cv2.LINE_AA)
def detect(self, img):
img_h, img_w, _ = img.shape
inputs = cv2.resize(img, (self.image_size, self.image_size))
inputs = cv2.cvtColor(inputs, cv2.COLOR_BGR2RGB).astype(np.float32)
inputs = (inputs / 255.0) * 2.0 - 1.0
inputs = np.reshape(inputs, (1, self.image_size, self.image_size, 3))
result = self.detect_from_cvmat(inputs)[0]
for i in range(len(result)):
result[i][1] *= (1.0 * img_w / self.image_size)
result[i][2] *= (1.0 * img_h / self.image_size)
result[i][3] *= (1.0 * img_w / self.image_size)
result[i][4] *= (1.0 * img_h / self.image_size)
return result
def detect_from_cvmat(self, inputs):
net_output = self.sess.run(self.net.logits,
feed_dict={self.net.images: inputs})
results = []
for i in range(net_output.shape[0]):
results.append(self.interpret_output(net_output[i]))
return results
def interpret_output(self, output):
probs = np.zeros((self.cell_size, self.cell_size,
self.boxes_per_cell, self.num_class))
class_probs = np.reshape(output[0:self.boundary1], (self.cell_size, self.cell_size, self.num_class))
scales = np.reshape(output[self.boundary1:self.boundary2],
(self.cell_size, self.cell_size, self.boxes_per_cell))
boxes = np.reshape(output[self.boundary2:], (self.cell_size, self.cell_size,
self.boxes_per_cell, 4))
offset = np.transpose(np.reshape(np.array([np.arange(self.cell_size)] *
self.cell_size * self.boxes_per_cell),
[self.boxes_per_cell, self.cell_size,
self.cell_size]), (1, 2, 0))
boxes[:, :, :, 0] += offset
boxes[:, :, :, 1] += np.transpose(offset, (1, 0, 2))
boxes[:, :, :, :2] = 1.0 * boxes[:, :, :, 0:2] / self.cell_size
boxes[:, :, :, 2:] = np.square(boxes[:, :, :, 2:])
boxes *= self.image_size
for i in range(self.boxes_per_cell):
for j in range(self.num_class):
probs[:, :, i, j] = np.multiply(
class_probs[:, :, j], scales[:, :, i])
filter_mat_probs = np.array(probs >= self.threshold, dtype='bool')
filter_mat_boxes = np.nonzero(filter_mat_probs)
boxes_filtered = boxes[filter_mat_boxes[0],
filter_mat_boxes[1], filter_mat_boxes[2]]
probs_filtered = probs[filter_mat_probs]
classes_num_filtered = np.argmax(filter_mat_probs, axis=3)[filter_mat_boxes[
0], filter_mat_boxes[1], filter_mat_boxes[2]]
argsort = np.array(np.argsort(probs_filtered))[::-1]
boxes_filtered = boxes_filtered[argsort]
probs_filtered = probs_filtered[argsort]
classes_num_filtered = classes_num_filtered[argsort]
for i in range(len(boxes_filtered)):
if probs_filtered[i] == 0:
continue
for j in range(i + 1, len(boxes_filtered)):
if self.iou(boxes_filtered[i], boxes_filtered[j]) > self.iou_threshold:
probs_filtered[j] = 0.0
filter_iou = np.array(probs_filtered > 0.0, dtype='bool')
boxes_filtered = boxes_filtered[filter_iou]
probs_filtered = probs_filtered[filter_iou]
classes_num_filtered = classes_num_filtered[filter_iou]
result = []
for i in range(len(boxes_filtered)):
result.append([self.classes[classes_num_filtered[i]], boxes_filtered[i][0], boxes_filtered[
i][1], boxes_filtered[i][2], boxes_filtered[i][3], probs_filtered[i]])
return result
def iou(self, box1, box2):
tb = min(box1[0] + 0.5 * box1[2], box2[0] + 0.5 * box2[2]) - \
max(box1[0] - 0.5 * box1[2], box2[0] - 0.5 * box2[2])
lr = min(box1[1] + 0.5 * box1[3], box2[1] + 0.5 * box2[3]) - \
max(box1[1] - 0.5 * box1[3], box2[1] - 0.5 * box2[3])
if tb < 0 or lr < 0:
intersection = 0
else:
intersection = tb * lr
return intersection / (box1[2] * box1[3] + box2[2] * box2[3] - intersection)
def camera_detector(self, cap, wait=10):
detect_timer = Timer()
ret, _ = cap.read()
while ret:
ret, frame = cap.read()
detect_timer.tic()
result = self.detect(frame)
detect_timer.toc()
print('Average detecting time: {:.3f}s'.format(detect_timer.average_time))
self.draw_result(frame, result)
cv2.namedWindow('Camera',0)
cv2.imshow('Camera', frame)
cv2.waitKey(wait)
ret, frame = cap.read()
def image_detector(self, imname, wait=0):
detect_timer = Timer()
image = cv2.imread(imname)
detect_timer.tic()
result = self.detect(image)
detect_timer.toc()
print('Average detecting time: {:.3f}s'.format(detect_timer.average_time))
self.draw_result(image, result)
cv2.imshow('Image', image)
cv2.waitKey(wait)
yolo源码解析(一)的更多相关文章
- 第三十六节,目标检测之yolo源码解析
在一个月前,我就已经介绍了yolo目标检测的原理,后来也把tensorflow实现代码仔细看了一遍.但是由于这个暑假事情比较大,就一直搁浅了下来,趁今天有时间,就把源码解析一下.关于yolo目标检测的 ...
- yolo源码解析(3):视频检测流程
代码在自己电脑中!!!!不在服务器 根据前文所说yolo代码逻辑: ├── examples │ ├── darknet.c(主程序) │ │── xxx1.c │ └── xxx2.c │ ├── ...
- yolo源码解析(1):代码逻辑
一. 整体代码逻辑 yolo中源码分为三个部分,\example,\include,以及\src文件夹下都有源代码存在. 结构如下所示 ├── examples │ ├── darknet.c(主程序 ...
- yolo源码解析(三)
七 测试网络 模型测试包含于test.py文件,Detector类的image_detector()函数用于检测目标. import os import cv2 import argparse imp ...
- yolo源码解析(二)
五 读取数据pascal_voc.py文件解析 我们在YOLENet类中定义了两个占位符,一个是输入图片占位符,一个是图片对应的标签占位符,如下: #输入图片占位符 [NONE,image_size, ...
- yolo源码解析(3):进行简单跳帧
视频检测命令 ./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights ../../dataset/ ...
- yolo源码解析(2):处理图片
首先安装ffmpeg, 参考https://blog.csdn.net/lwgkzl/article/details/77836207 然后将视频切分为图片, 参考:https://zhuanlan. ...
- 【原】Android热更新开源项目Tinker源码解析系列之三:so热更新
本系列将从以下三个方面对Tinker进行源码解析: Android热更新开源项目Tinker源码解析系列之一:Dex热更新 Android热更新开源项目Tinker源码解析系列之二:资源文件热更新 A ...
- 【原】Android热更新开源项目Tinker源码解析系列之一:Dex热更新
[原]Android热更新开源项目Tinker源码解析系列之一:Dex热更新 Tinker是微信的第一个开源项目,主要用于安卓应用bug的热修复和功能的迭代. Tinker github地址:http ...
随机推荐
- Storm目录树和任务提交过程
Storm组件本地目录树 Storm zookeeper目录树 Storm任务提交的过程
- laravel5 session的基本使用
配置session配置文件位于config/session.hpp 默认情况下使用session驱动为文件驱动,在生产环境中,建议使用memcache或者redis驱动以便获取更快的session性能 ...
- Laravel 去掉访问后面的 “public”
将laravel/server.PHP 改名为index.php,再将public目录下的.htaccess拷贝到Larvael根目录下,再访问Larvael就会发现不需要加上public,由于访问入 ...
- CF1010D Mars rover [位运算,DP]
题目传送门 Mars Rover 格式难调,题面就不放了. 分析: 今天考试的时候考了这道题目的加强版,所以来做. 其实也并不难,我们建立好树形结构以后先把初始权值全部求出,然后就得到了根节点的初始值 ...
- React Native Android启动白屏的一种解决方案下
实现思路 思路大流程: 1.APP启动的时候控制ReactActivity从而显示启动屏. 2.编写原生模块,提供一个关闭启动屏的公共接口. 3.在js的适当位置(一般是程序初始化工作完成后)调用上述 ...
- BZOJ4255 : Keep Fit!
首先旋转坐标系,把每个点可以接收的范围转化成一个正方形. 然后建立k-d tree,并记录下每个点在k-d tree上的位置. 对询问使用莫队算法,修改$O(\log n)$,查询期望$O(\log ...
- OpenJ_POJ C16D Extracurricular Sports 打表找规律
Extracurricular Sports 题目连接: http://acm.hust.edu.cn/vjudge/contest/122701#problem/D Description As w ...
- Activator 动态构造对象
Activator 意义: 用于动态构造对象 语法1: 根据指定的泛型类型构造对象 Activator.CreateInstance<类型>() 语法2: 根据程序集和类型名构造对象 S ...
- UNICODE 区域对照表
0000-007F Basic Latin 基本拉丁字母 0080-00FF Latin-1 Supplement 拉丁字母補充-1 0100-017F Latin Extended-A 拉丁字母擴充 ...
- STM32 Timer : Base Timer, Input Capture, PWM, Output Compare
http://www.cs.indiana.edu/~geobrown/book.pdf An example of a basic timer is illustrated in Figure 10 ...