Solr6.5配置中文分词IKAnalyzer和拼音分词pinyinAnalyzer (二)
之前在 Solr6.5在Centos6上的安装与配置 (一) 一文中介绍了solr6.5的安装。这篇文章主要介绍创建Solr的Core并配置中文IKAnalyzer分词和拼音检索。
一、创建Core:
1、首先在solrhome(solrhome的路径和配置见Solr6.5在Centos6上的安装与配置 (一)中solr的web.xml)中创建mycore目录;
[root@localhost down]#
[root@localhost down]# mkdir /down/apache-tomcat-8.5.12/solrhome/mycore
[root@localhost down]# cd /down/apache-tomcat-8.5.12/solrhome/mycore
[root@localhost mycore]#
2、复制solr-6.5.0\example\example-DIH\solr\solr下的所有文件到/down/apache-tomcat-8.5.12/solrhome/mycore目录下:
[root@localhost mycore]# cp -R /down/solr-6.5.0/example/example-DIH/solr/solr/* ./
[root@localhost mycore]# ls
conf core.properties
[root@localhost mycore]#
3、重新启动tomcat;
[root@localhost down]# /down/apache-tomcat-8.5.12/bin/shutdown.sh
[root@localhost down]# /down/apache-tomcat-8.5.12/bin/startup.sh
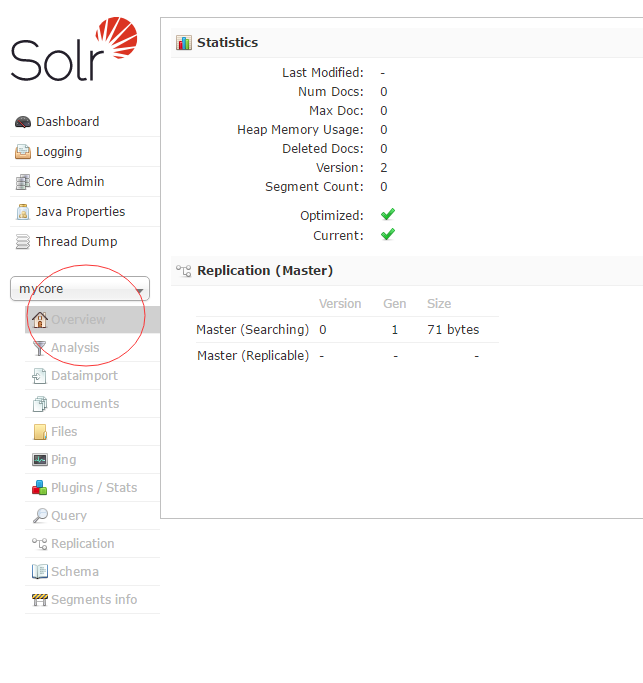
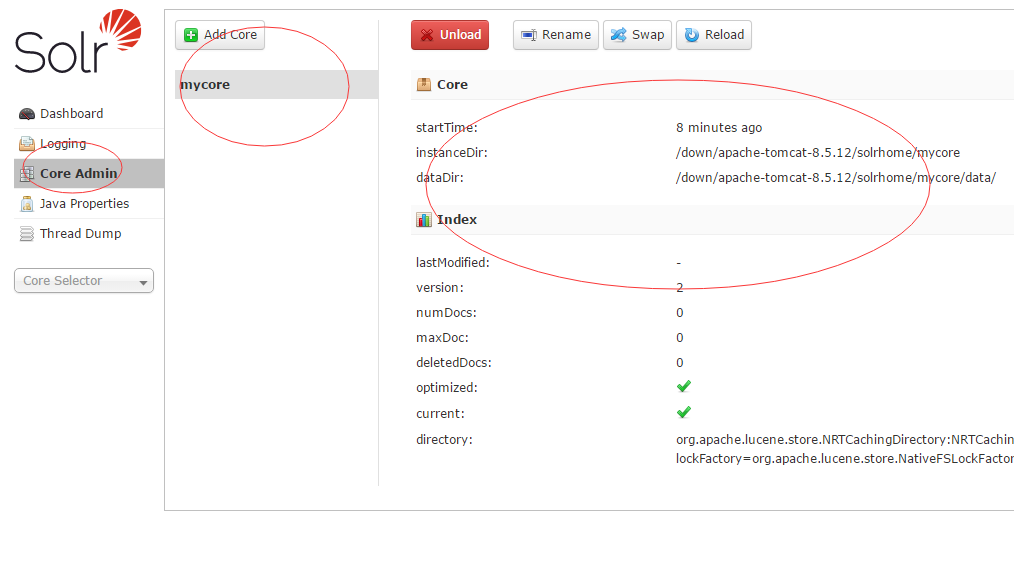
4、此时在浏览器输入http://localhost:8080/solr/index.html即可出现Solr的管理界面,即可看到我们刚才的mycore
二、配置solr自带的中文分词(和IK的区别是不能自己添加词库):
1、配置solr6.5自带中文分词。复制solr-6.5.0/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-6.5.0.jar到apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/目录下。
[root@localhost down]# cp /down/solr-6.5.0/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-6.5.0.jar /down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/
2、为core添加对中文分词的支持。编辑mycore下conf下的managed-schema文件.
[root@localhost conf]# cd /down/apache-tomcat-8.5.12/solrhome/mycore/conf
[root@localhost conf]# vi managed-schema
在文件的</schema>前添加
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
重启tomcat,后在浏览器输入http://localhost:8080/solr/index.html#/mycore/analysis
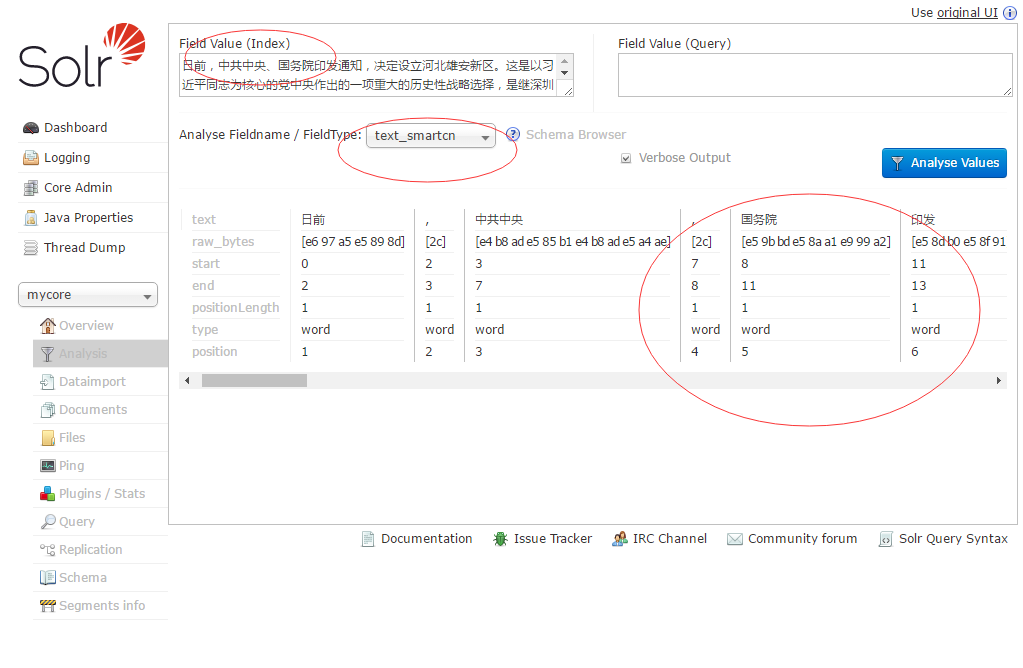
在Field Value (Index)文本框输入一些中文,然后Analyse Fieldname / FieldType:选择text_smartcn查看中文分词的效果。
如图:
三、配置IKAnalyzer的中文分词:
1、首先下载IKAnalyzer 这是最新的支持solr6.5.
解压后会有四个文件。
[root@localhost ikanalyzer-solr5]# ls
ext.dic IKAnalyzer.cfg.xml solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar stopword.dic
ext.dic为扩展字典,stopword.dic为停止词字典,IKAnalyzer.cfg.xml为配置文件,solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar为分词jar包。 2、将文件夹下的IKAnalyzer.cfg.xml , ext.dic和stopword.dic 三个文件 复制到/webapps/solr/WEB-INF/classes 目录下,并修改IKAnalyzer.cfg.xml
[root@localhost ikanalyzer-solr5]# cp ext.dic IKAnalyzer.cfg.xml stopword.dic /down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/classes/
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry> </properties>
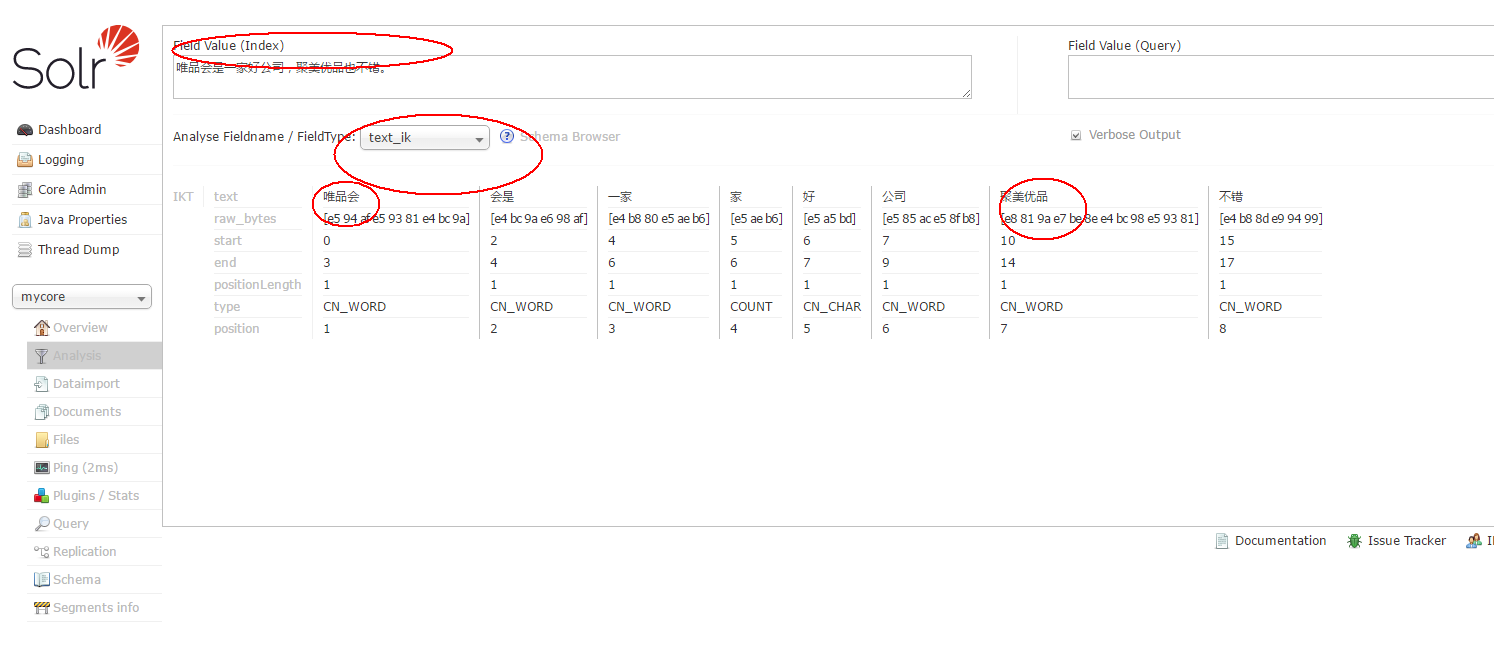
3、在ext.dic 里增加自己的扩展词典,例如,唯品会 聚美优品
4、复制solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar到/down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/目录下。
[root@localhost down]# cp /down/ikanalyzer-solr5/solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar /down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/
5、在 solrhome\mycore\conf\managed-schema 文件</schema>前增加如下配置
<!-- 我添加的IK分词 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/>
</analyzer>
</fieldType>
注意: 记得将stopword.dic,ext.dic的编码方式为UTF-8 无BOM的编码方式。
重启tomcat查看分词效果。
四、配置拼音检索:
1、前期准备,需要用到pinyin4j-2.5.0.jar、pinyinAnalyzer.jar这两个jar包,下载地址。
2、将pinyin4j-2.5.0.jar、pinyinAnalyzer.jar这两个jar包复制到/down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/目录下。
[root@localhost down]# cp pinyin4j-2.5.0.jar pinyinAnalyzer4.3.1.jar /down/apache-tomcat-8.5.12/webapps/solr/WEB-INF/lib/
3、在 solrhome\mycore\conf\managed-schema 文件</schema>前增加如下配置:
<fieldType name="text_pinyin" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
</fieldType>
重启tomcat查看拼音检索效果。
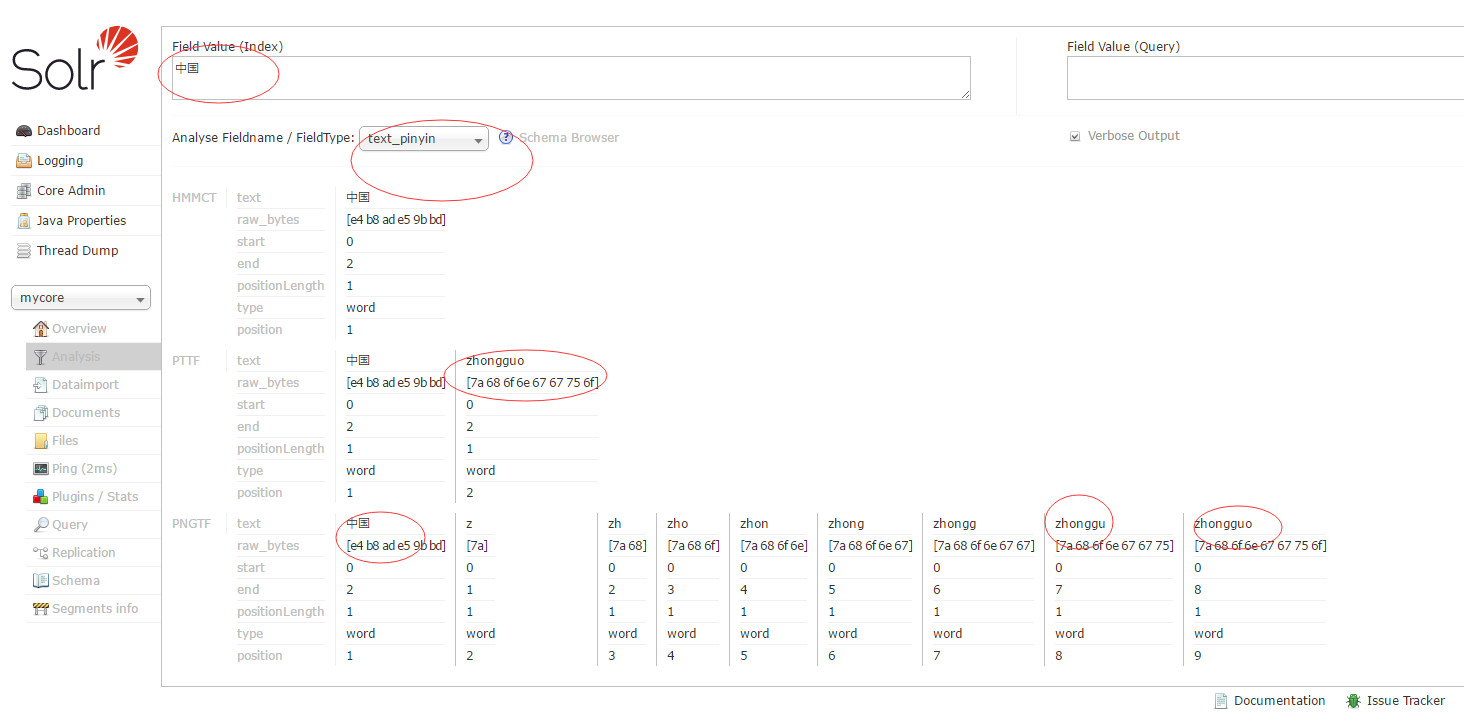
这里用的是solr自带的中文分词加上pinyin4j来实现的。
相关文件的下载地址:
所有要用到的文件:solr6.5ik-pinyin.zip
Solr6.5配置中文分词IKAnalyzer和拼音分词pinyinAnalyzer (二)的更多相关文章
- solr 中文分词器IKAnalyzer和拼音分词器pinyin
solr分词过程: Solr Admin中,选择Analysis,在FieldType中,选择text_en 左边框输入 “冬天到了天气冷了小明不想上学去了”,点击右边的按钮,发现对每个字都进行分词. ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
- 【杂记】docker搭建ELK 集群6.4.0版本 + elasticsearch-head IK分词器与拼音分词器整合
大佬博客地址:https://blog.csdn.net/supermao1013/article/category/8269552 docker elasticsearch 集群启动命令 docke ...
- Solr6.6 配置中文分词库mmseg4j
1.准备 首先安装solr:参照搜索引擎Solr-6.6.0搭建,如果版本高于6,可能会不支持,需要改mmseg4j包 mmseg4j包下载: mmseg4j-solr-2.3.0-with-mmse ...
- elasticsearch 拼音+ik分词,spring data elasticsearch 拼音分词
elasticsearch 自定义分词器 安装拼音分词器.ik分词器 拼音分词器: https://github.com/medcl/elasticsearch-analysis-pinyin/rel ...
- docker环境下solr6.0配置(中文分词+拼音)
前言:这篇文章是基于之前的“linux环境下配置solr5.3详细步骤”(http://www.cnblogs.com/zhangyuan0532/p/4826740.html)进行扩展的.本篇的步骤 ...
- Solr6.5.0配置中文分词器配置
准备工作: solr6.5.0安装成功 1.去官网https://github.com/wks/ik-analyzer下载IK分词器 2.Solr集成IK a)将ik-analyzer-solr6.x ...
随机推荐
- vue 开发系列(一) vue 开发环境搭建
概要 目前前端开发技术越来越像后台开发了,有一站式的解决方案. 1.JS包的依赖管理像MAVEN. 2.JS代码编译打包. 3.组件式的开发. vue 是一个前端的一站式的前端解决方案,从项目的初始化 ...
- hibernate执行createSQLQuery时字段重名的问题
hibernate执行createSQLQuery时字段重名的问题 不同表关联 ,表字段重名 =>之前若 as 别名 会自动区分 但有一次签移到新服务器 mysql 5.5上: 若字段重名:重 ...
- 微信小程序 js结构
// pages/index/index.js Page({ /** * 页面的初始数据 */ data: { }, /** * 生命周期函数--监听页面加载 */ onLoad: function ...
- asp.net 重写URL方法和封装好的DLL
.net 重写URL方法和封装好的DLL URL重写方法DLL(2.0)
- js格式化文件大小, 输出成带单位的字符串工具
/** * 格式化文件大小, 输出成带单位的字符串 * @method formatSize * @grammar formatSize( size ) => String * @grammar ...
- leaflet入门(五)API翻译(下)
L.PointConstructor(函数构造器)Properties(属性)Methods(方法) L.BoundsConstructor(函数构造器)Properties(属性)Methods(方 ...
- (转)Log4Net 全方位跟踪程序运行
转自:http://www.cnblogs.com/qingyuan/archive/2011/05/13/2045616.html 前端日子自己写了一个简单的日志跟踪程序,现在目前正在做的一个项目中 ...
- web-day10
第10章WEB10-requet&response篇 今日任务 登录系统后完成文件下载 商城系统注册功能. 教学导航 教学目标 掌握response设置响应头 掌握response重定向和转发 ...
- JAVA作业之两数的加减乘除
1.设计思路 把输入的字符转化为计算的数字问题,再以对话框的形式输入输出加减乘除的结果问题. 2.程序流程图 3.源代码 4.实验结果
- iscroll 4 下拉 上拉 加载
<!DOCTYPE html> iScroll demo: barebone body, ul, li{ padding:0; margin: 0; border:0; } body{ f ...