爬虫初窥day1:urllib
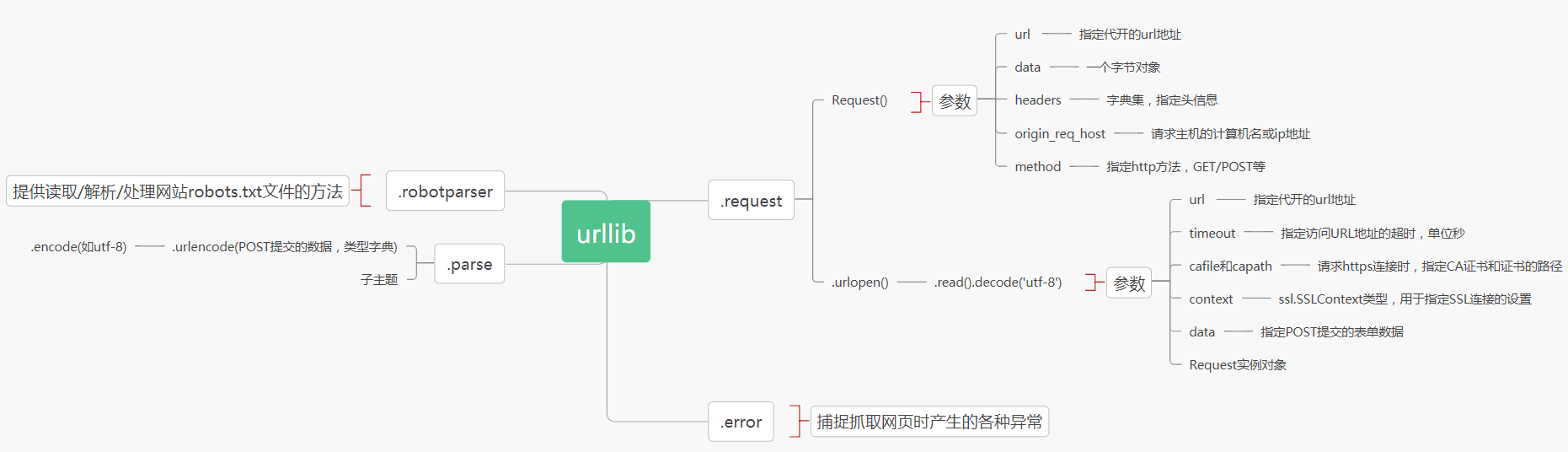
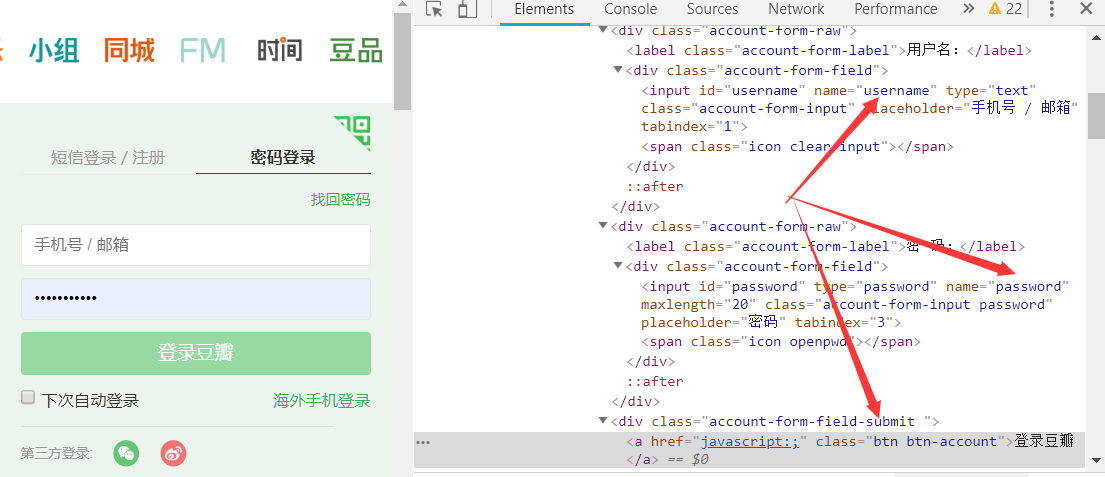
模拟“豆瓣”网站的用户登录
# coding:utf-8
import urllib url = 'https://www.douban.com/'
data = urllib.parse.urlencode({'username':'15x82x54x2x','password':'yxxxxxx65'})
data = data.encode('utf-8')
headers = {}
headers['User-Agent']='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
response = urllib.request.Request(url=url,data=data,headers=headers)
html = urllib.request.urlopen(response).read()
f = open('haha.html','wb')
f.write(html)
f.close()
爬虫初窥day1:urllib的更多相关文章
- 爬虫初窥day3:BeautifulSoup
信息提取 1.通过Tag对象的属性和方法 #!/usr/bin/python # -*- coding: utf- -*- from urllib.request import urlopen fro ...
- 爬虫初窥day4:requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 ...
- 爬虫初窥day2:正则
正则在线测试 http://tool.oschina.net/regex https://www.regexpal.com/ http://tool.chinaz.com/regex exp1:筛选所 ...
- python爬虫 scrapy2_初窥Scrapy
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- Scrapy001-框架初窥
Scrapy001-框架初窥 @(Spider)[POSTS] 1.Scrapy简介 Scrapy是一个应用于抓取.提取.处理.存储等网站数据的框架(类似Django). 应用: 数据挖掘 信息处理 ...
- scrapy2_初窥Scrapy
递归知识:oop,xpath,jsp,items,pipline等专业网络知识,初级水平并不是很scrapy,可以从简单模块自己写. 初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数 ...
- Scrapy 1.4 文档 01 初窥 Scrapy
初窥 Scrapy Scrapy 是用于抓取网站并提取结构化数据的应用程序框架,其应用非常广泛,如数据挖掘,信息处理或历史存档. 尽管 Scrapy 最初设计用于网络数据采集(web scraping ...
- R语言爬虫初尝试-基于RVEST包学习
注意:这文章是2月份写的,拉勾网早改版了,代码已经失效了,大家意思意思就好,主要看代码的使用方法吧.. 最近一直在用且有维护的另一个爬虫是KINDLE 特价书爬虫,blog地址见此: http://w ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
随机推荐
- git查看某个文件修改历史
[git查看某个文件修改历史] 1.使用git命令 git whatchanged charge.lua 显示某个文件的每个版本提交信息:提交日期,提交人员,版本号,提交备注(没有修改细节) git ...
- 百度浏览器 UserAgent
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 BIDUBrowser ...
- 优化-最小化损失函数的三种主要方法:梯度下降(BGD)、随机梯度下降(SGD)、mini-batch SGD
优化函数 损失函数 BGD 我们平时说的梯度现将也叫做最速梯度下降,也叫做批量梯度下降(Batch Gradient Descent). 对目标(损失)函数求导 沿导数相反方向移动参数 在梯度下降中, ...
- Unity时钟定时器插件——Vision Timer源码分析之一
因为项目中,UI的所有模块都没有MonBehaviour类(纯粹的C#类),只有像NGUI的基本组件的类是继承MonoBehaviour.因为没有继承MonoBehaviour,这也不能使用Updat ...
- synchronized细节问题(一)
synchronized锁重入: 关键字synchronized拥有锁重入的功能,也就是在使用synchronized时,当一个线程得到一个对象的锁后,再次请求此对象时是可以再次得到该对象的锁. 下面 ...
- C++旅馆问题。
有总钱数 有每房每天住需要多少钱 问最少可以住几天 最后输入的是钱数.前边输入没个住所每天多少钱 例如: 1001 1002 1003 1004 1000 -1 100 500 600 最少一天,最多 ...
- server2003远程桌面设置一个用户
开始--程序--管理工具--终端服务配置--限制每个用户使用一个会话
- how2j网站前端项目——天猫前端(第一次)学习笔记8
其他页面的学习 这些页面有1.查询结果页 2.支付页面 3.支付成功页面 4.确认收货页面上 5.确认收货页面下 6.收获成功页面 7.评价页面上 8.评价页面下 9.登陆页面 10.注册页面 1.查 ...
- elasticsearch命令
如果安装了x-pack插件,需要验证 curl -u username:passwd 1.查看所有index curl -XGET localhost:/_cat/indices?v 2.清理所有in ...
- 血的教训:Protocol http not supported or disabled in libcurl
报错显示:http not supported or disabled in libcurl 查看配置 curl -V ---------------------------------------- ...