27-hadoop-hbase安装
hbase的安装分为单机模式和完全分布式

单机模式
单机模式的安装很简单, 需要注意hbase自己内置一个zookeeper, 如果使用单机模式, 那么该机器的zookeepr不可以启动
1, 添加java的环境变量 vim {HBASE_HOME}/conf/hbase-env.sh
export JAVA_HOME=/usr/opt/jdk1..0_79
2, 修改配置文件 {HBASE_HOME}/conf/hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>file:////data/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/data/zkData</value>
</property>
3, 启动
./bin/start-hbase.sh
4, 链接
./bin/hbase shell
5, 查看命令
help
6, 查看表
list
ok, 单机模式搭建完成
集群模式
前提: zookeeper集群正常启动, hadoop集群正常启动
1, ./conf/hbase-site.xml
<configuration>
<!-- 指定hdfs的存放目录-->
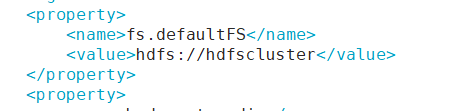
<property>
<name>hbase.rootdir</name>
<value>hdfs://hdfscluster/hbase</value>
</property>
<!--开启集群模式-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zookeeper-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.208.106,192.168.208.107,192.168.208.108</value>
</property>
</configuration>
其中, root.dir是在{HADOOP_HOME}/etc/hadoop/core-site.xml 中
2, ./conf/regionserver中, 配置2台从, 即regionserver
192.168.208.106
192.168.208.107
192.168.208.108
可选配置: 在 backup-mater中配置高可用 ( 我没配置)
192.168.208.107
192.168.208.108
3, hdoop.conf.dir 配置在 hbase-env.sh中 的hbase_classpath下
有3种配置方式, 我们选第一种
Add a pointer to your
HADOOP_CONF_DIRto theHBASE_CLASSPATHenvironment variable in hbase-env.sh.Add a copy of hdfs-site.xml (or hadoop-site.xml) or, better, symlinks, under ${HBASE_HOME}/conf, or
if only a small set of HDFS client configurations, add them to hbase-site.xml.
最终 hbae-env.sh的需要配置:
export JAVA_HOME=/usr/opt/jdk1..0_79
export HBASE_CLASSPATH=/usr/opt/hadoop-2.5./etc/hadoop/
export HBASE_MANAGES_ZK=false # 设置内置zookeeper不可用
4, 分发到从机
scp -r hbase-1.1./ root@192.168.208.107:/opt
scp -r hbase-1.1./ root@192.168.208.108:/opt
5, 需要的话配置环境变量

6, 启动:
./bin/start-hbase.sh
7, 链接
hbase shell
或者访问: 192.168.208.106:16010

8, 杀掉hbase
使用命令 stop-hbase.sh, 然后等待杀死即可, 如果杀不死, 需要到zookeeper下删除 hbase节点下的元素据信息, 如果仍然杀不死, 需要删除数据信息
集群模式需要开放的端口, 粘贴一段官网文档的原话: ( http://hbase.apache.org/book.html#_introduction)
Each HMaster uses three ports (16010, 16020, and 16030 by default). The port offset is added to these ports, so using an offset of 2, the backup HMaster would use ports 16012, 16022, and 16032. The following command starts 3 backup servers using ports 16012/16022/16032, 16013/16023/16033, and 16015/16025/16035.
Each RegionServer requires two ports, and the default ports are 16020 and 16030.
The following command starts four additional RegionServers, running on sequential ports starting at 16202/16302 (base ports 16200/16300 plus 2).
几个简单的shell命令:
创建命名空间: 多个表壳属于一个命名空间
create namespace 'namespce'
创建
create 'table','cf1','cf2', Version=2 # 保存2个版本
create 'namespace:table' # 在命名空间下创建表
查看表结构
desc 'table'
表删除
disable 'table'
drop 'table'
查看表数据
scan 'table' # 全表扫描
系类来自尚学堂极限班视频
27-hadoop-hbase安装的更多相关文章
- 最新hadoop+hbase+spark+zookeeper环境安装(vmmare下)
说明:我这里安装的版本是hadoop2.7.3,hbase1.2.4,spark2.0.2,zookeeper3.4.9 (安装包:链接:http://pan.baidu.com/s/1c25hI4g ...
- hadoop生态圈安装详解(hadoop+zookeeper+hbase+pig+hive)
-------------------------------------------------------------------* 目录 * I hadoop分布式安装 * II zoo ...
- hbase安装配置(整合到hadoop)
hbase安装配置(整合到hadoop) 如果想详细了解hbase的安装:http://abloz.com/hbase/book.html 和官网http://hbase.apache.org/ 1. ...
- 大数据: 完全分布式Hadoop集群-HBase安装
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. 本文基 ...
- 第二章 伪分布式安装hadoop hbase
安装单机模式的hadoop无须配置,在这种方式下,hadoop被认为是一个单独的java进程,这种方式经常用来调试.所以我们讲下伪分布式安装hadoop. 我们继续上一章继续讲解,安装完先试试SSH装 ...
- Apache Hadoop集群离线安装部署(三)——Hbase安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- HADOOP (十一).安装hbase
下载安装包并解压设置hbase环境变量配置hbase-site.xml启动hbase检测hbase启动情况测试hbase shell 下载安装包并解压 https://mirrors.tuna.tsi ...
- [精华]Hadoop,HBase分布式集群和solr环境搭建
1. 机器准备(这里做測试用,目的准备5台CentOS的linux系统) 1.1 准备了2台机器,安装win7系统(64位) 两台windows物理主机: 192.168.131.44 adminis ...
- 项目十八-Hadoop+Hbase分布式集群架构“完全篇”
本文收录在Linux运维企业架构实战系列 前言:本篇博客是博主踩过无数坑,反复查阅资料,一步步搭建,操作完成后整理的个人心得,分享给大家~~~ 1.认识Hadoop和Hbase 1.1 hadoop简 ...
- 【从零开始学习Hadoop】--1.Hadoop的安装
第1章 Hadoop的安装1. 操作系统2. Hadoop的版本3. 下载Hadoop4. 安装Java JDK5. 安装hadoop6. 安装rsync和ssh7. 启动hadoop8. 测试had ...
随机推荐
- (转第二方案)在 ASP.NET 環境下使用 Memcached 快速上手指南
转自:http://blog.miniasp.com/post/2010/01/27/Memcached-for-ASPNET-Quick-Start-Guide.aspx 之前一直想研究 Memca ...
- mysql_变量
set names gbk; 变量 变量分为两种:系统变量,自定义变量 系统变量:系统定义好的,大部分情况用户不需要使用系统变量,如autocommit,auto_increment_incremen ...
- ReLU 和sigmoid 函数对比
详细对比请查看:http://www.zhihu.com/question/29021768/answer/43517930 . 激活函数的作用: 是为了增加神经网络模型的非线性.否则你想想,没有激活 ...
- 搭建一台deeplearning的服务器
在计算机时代的早期,一名极客的满足感很大程度上来源于能DIY一台机器.到了深度学习的时代,前面那句话仍然是对的. 缘起在2013年,MIT科技评论将深度学习列为当年十大科技突破之首.其原因在于,模型有 ...
- Windows远程桌面连接ubuntu 16
一.安装Xrdp Windows远程桌面使用的是RDP协议,所以ubuntu上就要先安装Xrdp,在ubuntu软件中心搜索xrdp安装. 安装xrdp的同时会自动安装vnc4server,xbase ...
- socket粗解
百度定义:网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket. Socket通信流程: 网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一 ...
- 一不小心发现了个Asp.Net Bug
1. Ver是页面定义的变量 2. asp.net 页面定义为 <link href="/company/them/page.css?v=<%=Ver%>" r ...
- nginx windown命令
cmd进入nginx程序文件夹启动nginx:start nginx nginx -s reload|reopen|stop|quit #重新加载配置|重启|停止|退出 nginx nginx -t ...
- Python 基础之class魔术方法
类的常用魔术方法:无需人为调用,基本是在特定的时刻自动触发,方法名被前后两个下划线包裹 魔术方法,总结表: __init__:构造函数.初始化的时候调用. __new__:对象实例化方法,其实这才是类 ...
- 在vue项目中stylus的安装及使用
Stylus是一个CSS预处理器. Stylus安装包安装: dell@DESKTOP-KD0EJ4H MINGW64 /f/gsff-frone $ cnpm install stylus --sa ...