[机器学习] 性能评估指标(精确率、召回率、ROC、AUC)
混淆矩阵
介绍这些概念之前先来介绍一个概念:混淆矩阵(confusion matrix)。对于 k 元分类,其实它就是一个k x k的表格,用来记录分类器的预测结果。对于常见的二元分类,它的混淆矩阵是 2x2 的。
假设要对 15 个人预测是否患病,使用 1 表示患病,使用 0 表示正常。预测结果如下:
| 预测值: | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 真实值: | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
将上面的预测结果转为混淆矩阵,如下:

上图展示了一个二元分类的混淆矩阵,从该混淆矩阵可以得到以下信息:
样本数据总共有 5 + 2 + 4 + 4 = 15 个
真实值为 1 并且预测值也为 1 的样本有 5 个,真实值为 1 预测值为 0 的样本有 2 个,真实值为 0 预测值为 1 的样本有 4 个,真实值为 0 预测值也为 0 的样本有 4 个。
二元分类问题可以获得 True Positive(TP,真阳性)、False Positive(FP,假阳性)、 False Negative(FN,假阴性) 和 True Negative(TN,真阴性)。这四个值分别对应二元分类问题的混淆矩阵的四个位置。
小技巧:上面的这四个概念经常会被搞混淆(难道混淆矩阵的名称就是这么来的?),这里有个小方法帮你记住它。在医学上,一般认为阳性是患病,阴性是正常。所以只要出现“阳性”关键字就表示结果为患病,此外,阳性也分为真阳性和假阳性,从名称就可以看出:真阳性表示确确实实的阳性,也就是说实际为阳性(患病),预测也为阳性(患病);假阳性表示不真实的阳性,也就是说实际为阴性(正常),预测为阳性(患病)。真阴性和假阴性也可以按照上面的方式来简单理解。

很明显,这里的 TP=5,FP=2,FN=4,TN=4。
1.准确率P、召回率R、F1 值
- 准确率(Precision):P=TP/(TP+FP)。 通俗地讲,就是预测正确的正例数据占预测为正例数据的比例。
- 召回率(Recall): R=TP/(TP+FN)。 通俗地讲,就是预测为正例的数据占实际为正例数据的比例
- F1值(F score):
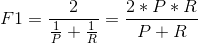
- 正如下图所示,F1的值同时受到P、R的影响,单纯地追求P、R的提升并没有太大作用。在实际业务工程中,结合正负样本比,的确是一件非常有挑战的事。
- 图像展示

True Positive, False Positive, True Negative, False Negative样本中的真实正例类别总数即TP+FN。True Positive Rate,TPR = TP/(TP+FN)。
同理,样本中的真实反例类别总数为FP+TN。False Positive Rate,FPR=FP/(TN+FP)。
|
|
预测 |
合计 |
||
|
1 |
0 |
|||
|
实际
|
1 (P) |
True Positive(TP) |
False Negative(FN) |
Actual Positive(TP+FN) |
|
0 (N) |
False Positive(FP) |
True Negative(TN) |
Actual Negative(FP+TN) |
|
|
合计 |
Predicted Positive(TP+FP) |
Predicted Negative(FN+TN) |
TP+FP+FN+TN |
|
还有一个概念叫”截断点”。机器学习算法对test样本进行预测后,可以输出各test样本对某个类别的相似度概率。
总结一下,对于计算ROC,最重要的三个概念就是TPR, FPR, 截断点。
截断点取不同的值,TPR和FPR的计算结果也不同。将截断点不同取值下对应的TPR和FPR结果画于二维坐标系中得到的曲线
- 纵坐标是true positive rate(TPR) = TP / (TP+FN=P) (分母是横行的合计)直观解释:实际是1中,猜对多少
- 横坐标是false positive rate(FPR) = FP / (FP+TN=N) 直观解释:实际是0中,错猜多少
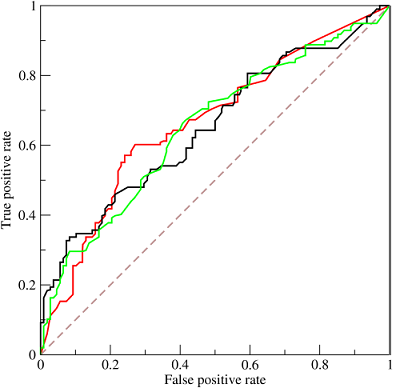

图中的虚线相当于随机预测的结果。不难看出,随着FPR的上升,ROC曲线从原点(0, 0)出发,最终都会落到(1, 1)点。ROC便是其右下方的曲线面积。下图展现了三种AUC的值:
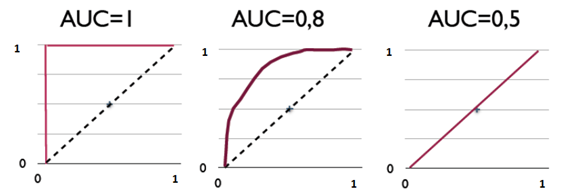
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测,因此不存在AUC < 0.5的情况
ROC 计算例子
from sklearn import metrics
import numpy as np
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
print fpr
print tpr
print thresholds通过计算,得到的结果(FPR,TPR, 截断点)为
[ 0.5 0.5 1. 1. ]
[ 0.8 0.4 0.35 0.1 ]
将结果中的FPR与TPR画到二维坐标中,得到的ROC曲线如下(蓝色线条表示),ROC曲线的面积用AUC表示(淡黄色阴影部分)。
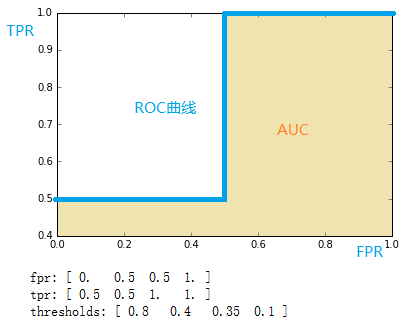
上例给出的数据如下:
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])用这个数据,计算TPR,FPR的过程是怎么样的呢?
1. 分析数据
y是一个一维数组(样本的真实分类)。数组值表示类别(一共有两类,1和2)。我们假设y中的1表示反例,2表示正例。即将y重写为:
y_true = [0, 0, 1, 1]2. 针对score,将数据排序
| 样本 | 预测属于P的概率(score) | 真实类别 |
|---|---|---|
| y[0] | 0.1 | N |
| y[2] | 0.35 | P |
| y[1] | 0.4 | N |
| y[3] | 0.8 | P |
3. 将截断点依次取为score值
将截断点依次取值为0.1,0.35,0.4,0.8时,计算TPR和FPR的结果。
3.1 截断点为0.1
说明只要score>=0.1,它的预测类别就是正例。
此时,因为4个样本的score都大于等于0.1,所以,所有样本的预测类别都为P。
scores = [0.1, 0.4, 0.35, 0.8]
y_true = [0, 0, 1, 1]
y_pred = [1, 1, 1, 1]
TPR = TP/(TP+FN) = 1
FPR = FP/(TN+FP) = 1
3.2 截断点为0.35
说明只要score>=0.35,它的预测类别就是P。
此时,因为4个样本的score有3个大于等于0.35。所以,所有样本的预测类有3个为P(2个预测正确,1一个预测错误);1个样本被预测为N(预测正确)。
scores = [0.1, 0.4, 0.35, 0.8]
y_true = [0, 0, 1, 1]
y_pred = [0, 1, 1, 1]
TPR = TP/(TP+FN) = 1
FPR = FP/(TN+FP) = 0.5
3.3 截断点为0.4
说明只要score>=0.4,它的预测类别就是P。
此时,因为4个样本的score有2个大于等于0.4。所以,所有样本的预测类有2个为P(1个预测正确,1一个预测错误);2个样本被预测为N(1个预测正确,1一个预测错误)。
scores = [0.1, 0.4, 0.35, 0.8]
y_true = [0, 0, 1, 1]
y_pred = [0, 1, 0, 1]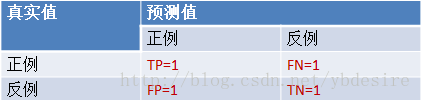
TPR = TP/(TP+FN) = 0.5
FPR = FP/(TN+FP) = 0.5
3.4 截断点为0.8
说明只要score>=0.8,它的预测类别就是P。所以,所有样本的预测类有1个为P(1个预测正确);3个样本被预测为N(2个预测正确,1一个预测错误)。
scores = [0.1, 0.4, 0.35, 0.8]
y_true = [0, 0, 1, 1]
y_pred = [0, 0, 0, 1]
TPR = TP/(TP+FN) = 0.5
FPR = FP/(TN+FP) = 0
用下面描述表示TPR和FPR的计算过程,更容易记住
- TPR:真实的正例中,被预测正确的比例
- FPR:真实的反例中,被预测正确的比例
最理想的分类器,就是对样本分类完全正确,即FP=0,FN=0。所以理想分类器FPR=0,TPR=0。
第一个点,(0,1),即FPR=0, TPR=1,这意味着FN(false negative)=0,并且FP(false positive)=0。Wow,这是一个完美的分类器,它将所有的样本都正确分类。
第二个点,(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。
第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,可以发现该分类器预测所有的样本都为负样本(negative)。
第四个点(1,1),分类器实际上预测所有的样本都为正样本。经过以上的分析,我们可以断言,ROC曲线越接近左上角,该分类器的性能越好。
[机器学习] 性能评估指标(精确率、召回率、ROC、AUC)的更多相关文章
- 【Udacity】机器学习性能评估指标
评估指标 Evaluation metrics 机器学习性能评估指标 选择合适的指标 分类与回归的不同性能指标 分类的指标(准确率.精确率.召回率和 F 分数) 回归的指标(平均绝对误差和均方误差) ...
- 机器学习性能评估指标(精确率、召回率、ROC、AUC)
http://blog.csdn.net/u012089317/article/details/52156514 ,y^)=1nsamples∑i=1nsamples(yi−y^i)2
- 机器学习性能度量指标:AUC
在IJCAI 于2015年举办的竞赛:Repeat Buyers Prediction Competition 中, 很多参赛队伍在最终的Slides展示中都表示使用了 AUC 作为评估指标: ...
- UDA机器学习基础—评估指标
这里举例说明 混淆矩阵 精确率 召回率 F1
- 机器学习笔记--classification_report&精确度/召回率/F1值
https://blog.csdn.net/akadiao/article/details/78788864 准确率=正确数/预测正确数=P 召回率=正确数/真实正确数=R F1 F1值是精确度和召回 ...
- 【机器学习】--模型评估指标之混淆矩阵,ROC曲线和AUC面积
一.前述 怎么样对训练出来的模型进行评估是有一定指标的,本文就相关指标做一个总结. 二.具体 1.混淆矩阵 混淆矩阵如图: 第一个参数true,false是指预测的正确性. 第二个参数true,p ...
- 机器学习性能度量指标:ROC曲线、查准率、查全率、F1
错误率 在常见的具体机器学习算法模型中,一般都使用错误率来优化loss function来保证模型达到最优. \[错误率=\frac{分类错误的样本}{样本总数}\] \[error=\frac{1} ...
- 准确率,召回率,F值,ROC,AUC
度量表 1.准确率 (presion) p=TPTP+FP 理解为你预测对的正例数占你预测正例总量的比率,假设实际有90个正例,10个负例,你预测80(75+,5-)个正例,20(15+,5-)个负例 ...
- Spark ML机器学习库评估指标示例
本文主要对 Spark ML库下模型评估指标的讲解,以下代码均以Jupyter Notebook进行讲解,Spark版本为2.4.5.模型评估指标位于包org.apache.spark.ml.eval ...
随机推荐
- FileZilla_server在Windows和Linnx下的部署安装
1. FileZilla官网下载FileZilla Server服务器,目前最新版本为0.9.53. 2. 安装FileZilla服务器.除以下声明的地方外,其它均采用默认模式,如安装路径等. 2.1 ...
- Codeforces Round #264 (Div. 2) C. Gargari and Bishops 主教攻击
http://codeforces.com/contest/463/problem/C 在一个n∗n的国际象棋的棋盘上放两个主教,要求不能有位置同时被两个主教攻击到,然后被一个主教攻击到的位置上获得得 ...
- 【转】利用线程更新ListView (2014-09-28 08:25:20)
http://blog.sina.com.cn/s/blog_44fa172f0102v2x0.html procedure TForm5.Button3Click(Sender: TObject); ...
- Asp .Net core 2 学习笔记(2) —— 中间件
这个系列的初衷是便于自己总结与回顾,把笔记本上面的东西转移到这里,态度不由得谨慎许多,下面是我参考的资源: ASP.NET Core 中文文档目录 官方文档 记在这里的东西我会不断的完善丰满,对于文章 ...
- .Net桌面程序自动更新NAppUpdate
自动更新介绍 我们做了程序,不免会有版本升级,这就需要程序有自动版本升级的功能.应用程序自动更新是由客户端应用程序自身负责从一个已知服务器下载并安装更新,用户唯一需要进行干预的是决定是否愿意现在或以后 ...
- MQ的demo
public class WorkTest { @Test public void send() throws Exception{ //获取连接 Connection conn = ...
- 表单控件 css的三中引入方式css选择器
1. 表单控件: 单选框 如果两个单选的name值一样,会产生互斥效果 <p> <!--单选框--> 男<input type="radio" nam ...
- 我的AI之路 —— 从裸机搭建GPU版本的深度学习环境
之前一直在CPU上跑深度学习,由于做的是NLP方向所以也能勉强忍受.最近在做图像的时候,实在是扛不住了...还好领导们的支持买个虚拟机先体验下.由于刚买的机器,环境都得自己摸索,瞎搞过很多次,也走过很 ...
- Redis中的批量操作Pipeline
大多数情况下,我们都会通过请求-相应机制去操作redis.只用这种模式的一般的步骤是,先获得jedis实例,然后通过jedis的get/put方法与redis交互.由于redis是单线程的,下一次请求 ...
- underscore.js源码研究(4)
概述 很早就想研究underscore源码了,虽然underscore.js这个库有些过时了,但是我还是想学习一下库的架构,函数式编程以及常用方法的编写这些方面的内容,又恰好没什么其它要研究的了,所以 ...