使用 EXISTS 代替 IN 和 inner join
在使用Exists时,如果能正确使用,有时会提高查询速度:
1,使用Exists代替inner join
2,使用Exists代替 in
1,使用Exists代替inner join例子:
在一般写sql语句时通常会遇到如下语句:
两个表连接时,取一个表的数据,一般的写法通过关联查询(inner join):
from dbo.[[zping.com]]] a
inner join workflowbase b on a.workflowid=b.id
and operator='4028814111ad9dc10111afc134f10041'
查询结果:
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 293 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
还有一种写法使用exists来取数据
from dbo.[[zping.com]]] a where exists
(select 'X' from workflowbase b where a.workflowid=b.id)
and operator='4028814111ad9dc10111afc134f10041'
执行结果:
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 291 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这里两着的IO次数,EXISTS比inner join少 2个IO, 对比执行计划成本不一样, 看看两着的差异:
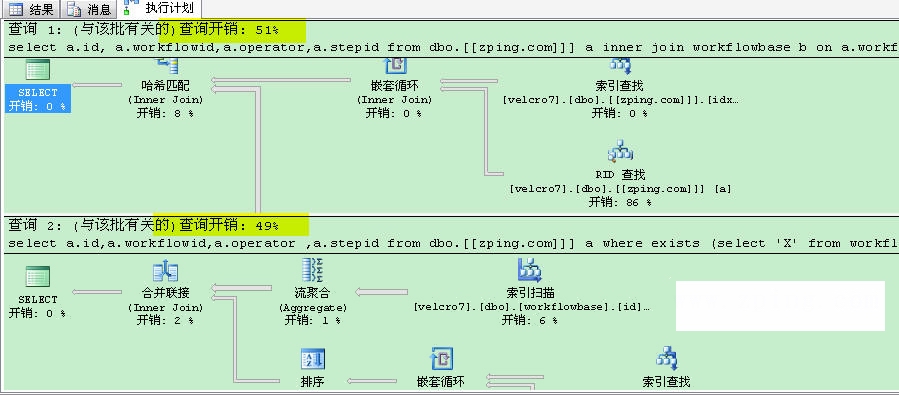
这时我们发现使用EXISTS要比inner join效率稍微高一下。
2,使用Exists代替 in
要求:编写workflowbase表中id不在表中dbo.[[zping.com]]]的行:
一般的写法:
where id not in (
select a.workflowid
from dbo.[[zping.com]]] a )
执行结果:

(1 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 5,逻辑读取 56952 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
使用Existsl来写:
where not exists(
select 'X'
from dbo.[[zping.com]]] a where a.workflowid=b.id )
看看执行结果
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 3,逻辑读取 18984 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
两个io的差距:56952+1589=58541次 (使用IN)
18984+1589=20573次 (使用Exists)
使用exists是in的2.8倍,查询性能提高很大。
EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果。
in和inner join在大多数情况下都是返回两表的交集,但是两者还是有区别的,如下例子
mysql> select * from a;
+------+------+
| id | name |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
+------+------+
MySQL> select * from b;
+------+------+
| id | name |
+------+------+
| 1 | d |
| 1 | g |
| 2 | e |
| 4 | f |
+------+------+
mysql> select a.id, a.name from a where a.id in (select b.id from b);
+------+------+
| id | name |
+------+------+
| 1 | a |
| 2 | b |
+------+------+
mysql> select a.id, a.name from a inner join b on (a.id = b.id);
+------+------+
| id | name |
+------+------+
| 1 | a |
| 1 | a |
| 2 | b |
+------+------+
mysql> select * from a inner join b on (a.id = b.id);
+------+------+------+------+
| id | name | id | name |
+------+------+------+------+
| 1 | a | 1 | d |
| 1 | a | 1 | g |
| 2 | b | 2 | e |
+------+------+------+------+
从查询结果中可以看出,in的结果是不会有重复的,对非主键进行join时,join的结果是有重复的。如果说还有另一个区别的话就是join会产生一个两表合并的临时表,in不会产生两表合并的临时表。
使用 EXISTS 代替 IN 和 inner join的更多相关文章
- MySql学习(三) —— 子查询(where、from、exists) 及 连接查询(left join、right join、inner join、union join)
注:该MySql系列博客仅为个人学习笔记. 同样的,使用goods表来练习子查询,表结构如下: 所有数据(cat_id与category.cat_id关联): 类别表: mingoods(连接查询时作 ...
- SQL优化--使用 EXISTS 代替 IN 和 inner join来选择正确的执行计划
在使用Exists时,如果能正确使用,有时会提高查询速度: 1,使用Exists代替inner join 2,使用Exists代替 in 1,使用Exists代替inner join例子: 在一般写s ...
- Sql语句优化-查询两表不同行NOT IN、NOT EXISTS、连接查询Left Join
在实际开发中,我们往往需要比较两个或多个表数据的差别,比较那些数据相同那些数据不相同,这时我们有一下三种方法可以使用:1. IN或NOT IN,2. EXIST或NOTEXIST,3.使用连接查询(i ...
- 为什么 EXISTS(NOT EXIST) 与 JOIN(LEFT JOIN) 的性能会比 IN(NOT IN) 好
前言 网络上有大量的资料提及将 IN 改成 JOIN 或者 exist,然后修改完成之后确实变快了,可是为什么会变快呢?IN.EXIST.JOIN 在 MySQL 中的实现逻辑如何理解呢?本文也是比较 ...
- SQL语句 in和inner join各有什么优点
比如A1表 100W行 A2表50W行select a.* from A1 a where a.column1 in (select b.column1 from A2 b where b.colum ...
- MySQL中exists和in的区别及使用场景
exists和in的使用方式: 1 #对B查询涉及id,使用索引,故B表效率高,可用大表 -->外小内大 1 select * from A where exists (select * fro ...
- MySQL Execution Plan--NOT EXISTS子查询优化
在很多业务场景中,会使用NOT EXISTS语句来确保返回数据不存在于特定集合,部分场景下NOT EXISTS语句性能较差,网上甚至存在谣言"NOT EXISTS无法走索引". 首 ...
- in和exists
exists和in的使用方式: #对B查询涉及id,使用索引,故B表效率高,可用大表 -->外小内大 select * from A where exists (select * from B ...
- MySQL中Exists和In的使用
Exists关键字: exists表示存在,是对外表做loop循环,每次loop循环再对内表(子查询)进行查询,那么因为对内表的查询使用的索引(内表效率高,故可用大表),而外表有多大都需要遍历,不可避 ...
随机推荐
- EZ 2018 01 14 2018noip第四次膜你赛
这次惨烈的炸了个精光(只有20),然后对我的OI想法造成了巨大的转折. (以上有点作,其实我只是再也不用vector存图了而已(用邻接表)) 难度很不均匀,而且题型很狗(还有结论题???) T1 坑人 ...
- python3获取指定目录内容的详细信息
不同平台获取指定目录内容的详细信息命令各不相同: Linux中可以通过ls -al获取获取 windows中可以通过dir命令获取 下面是我写的一个通用获取目录内容详细信息的python3脚本: #! ...
- ElasticSearch入门 第三篇:索引
这是ElasticSearch 2.4 版本系列的第三篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- Execute SQL Task 如何返回结果数据集
Execute Sql Task的Result DataSet 主要有以下四种,当Execute Sql Task返回结果之后,需要使用SSIS Variable 来接收数据. 例子中使用的数据表代码 ...
- Android——界面特效 相关知识总结贴
帮助android UI实现动画特效 http://www.apkbus.com/android-79595-1-1.html 帮助android应用程序实现动画特效 http://www.apkbu ...
- Ubuntu环境如何上传项目到GitHub网站?
http://blog.csdn.net/ajianyingxiaoqinghan/article/details/70544159
- 20135202闫佳歆--week6 分析Linux内核创建一个新进程的过程——实验及总结
week 6 实验:分析Linux内核创建一个新进程的过程 1.使用gdb跟踪创建新进程的过程 准备工作: rm menu -rf git clone https://github.com/mengn ...
- Linux内核分析(第五周)
系统调用的三层皮(下) 一.给MenuOs增加time和time-asm命令 ls rm menu -rf git clone xx(克隆新版本) cd menu make rootfs(自动编译生成 ...
- [UWP 开发] 一个简单的Toast实现
Toast简介 在安卓里Toast是内置原生支持,它是Android中用来显示显示信息的一种机制.它主要用于向用户显示提示消息,没有焦点,显示的时间有限,过一定的时间就会自动消失.在UWP中虽然没有原 ...
- 通俗易懂的word2Vec负采样理解
理解:http://www.shuang0420.com/2017/03/21/NLP%20%E7%AC%94%E8%AE%B0%20-%20%E5%86%8D%E8%B0%88%E8%AF%8D%E ...