机器学习-正则化(岭回归、lasso)和前向逐步回归
机器学习-正则化(岭回归、lasso)和前向逐步回归
观看本文之前,您也许可以先看一下后来写的一篇补充:https://www.cnblogs.com/jiading/p/12104854.html
本文代码均来自于《机器学习实战》
这三种要处理的是同样的问题,也就是数据的特征数量大于样本数量的情况。这个时候会出现矩阵不可逆的情况,为什么呢?
矩阵可逆的条件是:1. 方阵 2. 满秩
X.t*X必然是方阵(nxmxmxn=nxn,最终行列数是原来的X矩阵的列数,也就是特征数),但是要满秩的话,由于线性代数的一个结论,X.t*X的秩不会比X大,而X的秩是样本数和特征数中较小的那一个,所以,如果样本数小于特征数的话,X.t*X就不会是可逆的。
遇到这种情况,我们可以采用正则化的方式或者剔除多余特征,这里我们介绍一些正则化的方式,例如岭回归、lasso,以及另外的一种方法:前向逐步回归
lasso方法效果很好但是计算复杂,前向逐步回归可以得到和lasso差不多的效果,但是实现起来更加容易
---当然来自于《机器学习实战》
正则化
先解释一下这个词吧,毕竟这个词,每次听都感觉很玄妙的样子,但是也说不清到底哪里玄妙了。
在数学,统计学和计算机科学中,尤其是在机器学习和逆问题中,正则化是添加信息以解决不适定问题或防止过度拟合的过程。 正则化适用于不适定的优化问题中的目标函数。。
来源:https://en.wikipedia.org/wiki/Regularization_(mathematics)
唔,这里知乎有个答主写的很靠谱,把正则化的概念从头到尾撸了一遍。这里搬运一下:
先po一下题主题的问题:
机器学习中常常提到的正则化到底是什么意思?
举个例子 这是个基于多核的支持向量机的目标函数 d是多核函数的参数 它说r(d)是正则项。为什么要令r(d)为正则项,有什么目的?来源:https://www.zhihu.com/question/20924039,陶轻松的回答
作者:陶轻松
我尽量用通俗一点的话来解答一下楼主的问题,
r(d)可以理解为有d的参数进行约束,或者 D 向量有d个维度。
咱们将楼主的给的凸优化结构细化一点,别搞得那么抽象,不好解释;
, 其中,
咱们可以令: f() =
.
ok,这个先介绍到这里,至于f(x)为什么用多项式的方式去模拟?相信也是很多人的疑问,很简单,大家看看高等数学当中的泰勒展开式就行了,任何函数都可以用多项式的方式去趋近,
log x,lnx,
等等都可以去趋近,而不同的函数曲线其实就是这些基础函数的组合,理所当然也可以用多项式去趋近,好了,这个就先解释到这里了。
接下来咱们看一下拟合的基础概念。
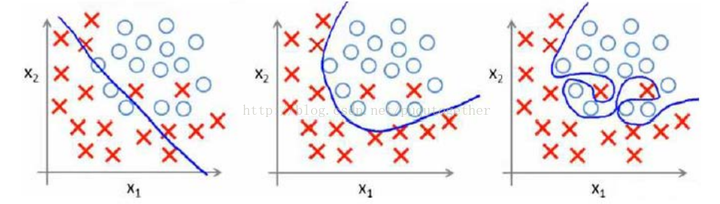
首先,用一个例子来理解什么是过拟合,假设我们要根据特征分类{男人X,女人O}。
请看下面三幅图,x1、x2、x3;
这三幅图很容易理解:1、 图x1明显分类的有点欠缺,有很多的“男人”被分类成了“女人”。2、 图x2虽然有两个点分类错误,但是能够理解,毕竟现实世界有噪音干扰,比如有些人男人留长发、化妆、人妖等等。3、 图x3分类全部是正确的,但是看着这副图片,明显觉得过了,连人妖都区分的出来,可想而知,学习的时候需要更多的参数项,甚至将生殖器官的形状、喉结的大小、有没有胡须特征等都作为特征取用了,总而言之f(x)多项式的N特别的大,因为需要提供的特征多,或者提供的测试用例中我们使用到的特征非常多(一般而言,机器学习的过程中,很多特征是可以被丢弃掉的)。
好了,总结一下三幅图:
x1我们称之为【欠拟合】
x2我们称之为【分类正拟合】,随便取的名字,反正就是容错情况下刚好的意思。
x3我们称之为【过拟合】,这种情况是我们不希望出现的状况,为什么呢?很简单,它的分类只是适合于自己这个测试用例,对需要分类的真实样本而言,实用性可想而知的低。恩,知道了过拟合是怎么回事之后,我们来看一下如何去规避这种风险。先不管什么书上说的、老师讲的、经验之说之类的文言文。咱们就站在第一次去接触这种分类模型的角度去看待这个问题,发散一下思维,我们应该如何去防止过拟合?
显而易见,我们应该从【过拟合】出现的特征去判别,才能规避吧?
显而易见,我们应该、而且只能去看【过拟合】的f(x)形式吧?
显而易见,我们从【过拟合】的图形可以看出f(x)的涉及到的特征项一定很多吧,即等等很多吧?
显而易见,N很大的时候,是等数量增长的吧?
显而易见,w系数都是学习来的吧?So,现在知道这些信息之后,如何去防止过拟合,我们首先想到的就是控制N的数量吧,即让N最小化吧,而让N最小化,其实就是让W向量中项的个数最小化吧?
其中,W=(PS: 可能有人会问,为什么是考虑W,而不是考虑X?很简单,你不知道下一个样本想x输入的是什么,所以你怎么知道如何去考虑x呢?相对而言,在下一次输入
,即第k个样本之前,我们已经根据
次测试样本的输入,计算(学习)出了W.就是这么个道理,很简单。
ok,any way.回到上面的思维导图的位置,我们再来思考,如何求解“让W向量中项的个数最小化”这个问题,学过数学的人是不是看到这个问题有点感觉?对,没错,这就是0范数的概念!什么是范数,我在这里只是给出个0-2范数定义,不做深究,以后有时间在给大家写点文章去分析范数的有趣玩法;
0范数,向量中非零元素的个数。
1范数,为绝对值之和。
2范数,就是通常意义上的模。PS,貌似有人又会问,上面不是说求解“让W向量中项的个数最小化”吗?怎么与0范数的定义有点不一样,一句话,向量中0元素,对应的x样本中的项我们是不需要考虑的,可以砍掉。因为
没有啥意义,说明
ok,现在来回答楼主的问题,r(d) = “让W向量中项的个数最小化” =
**所以为了防止过拟合,咱们除了需要前面的相加项最小,即楼主公式当中的
=
最小,我们还需要让r(d)=
最小,所以,为了同时满足两项都最小化,咱们可以求解让
说到这里我觉得楼主的问题我已经回答了,那就是为什么需要有个r(d)项,为什么r(d)能够防止过拟合原因了。**
根据《男人帮》电影大结局的剧情:本来故事已经完成了,为了让大家不至于厌恶课本的正规理论,我们在加上一集内容,用以表达我对机器学习出书者的尊重;书本中,或者很多机器学习的资料中,为了让全球的机器学习人员有个通用的术语,同时让大家便于死记硬本,给我上一段黑体字的部分的内容加上了一坨定义,例如:
我们管
By the way,各位计算机界的叔叔、阿姨、伯伯、婶婶,经过不懈的努力,发现了这个公式很多有意思的地方,它们发现0范数比较恶心,很难求,求解的难度是个NP完全问题。然后很多脑袋瓜子聪明的叔叔、阿姨、伯伯、婶婶就想啊,0范数难求,咱们就求1范数呗,然后就研究出了下面的等式:
一定的条件我就不解释了,这里有一堆算法,例如主成分KPCA等等,例子我就不在举了,还是原话,以后我会尽量多写点这些算法生动点的推到过程,很简单,注重过程,不要死记硬背书本上的结果就好。上面概括而言就是一句话总结:1范数和0范数可以实现稀疏,1因具有比L0更好的优化求解特性而被广泛应用。然后L2范数,是下面这么理解的,我就直接查别人给的解释好了,反正简单,就不自己动脑子解释了: L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的正则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的哦;所以大家比起1范数,更钟爱2范数。所以我们就看到书籍中,一来就是,r(d)=
这种结构了,然后在机器学习当中还能看到下面的结构:min{
} ,
>=0都是这么来的啦,万变不离其中。
讲一点自己机器学习过程的体验,大家都觉得机器学习入门难,绝大部分人反应知其然不知其所以然,这个原因很多时候在于中国教育工作者的教学、科研氛围,尤其是中文书籍出书者自己都不去搞懂原理,一个劲的为了利益而出书、翻译书,纯粹利益驱动。再加之机器学习起源于国外,很多经典的、有趣的历史没有被人翻译、或者归类整理,直接被舍弃掉了。个人感觉这是中国教育的缺失导致的。希望更多的人真的爱好计算机,爱好机器学习以及算法这些知识。喜欢就是喜欢。希望国内机器学习的爱好者慢慢的齐心合力去多多引荐这些高级计算机知识的基础。教育也不是由于利益而跟风,AI热出版社就翻译AI,机器学习热就翻译机器学习,知识层面不断架空,必然导致大家学习热情的不断衰减!愿共勉之。
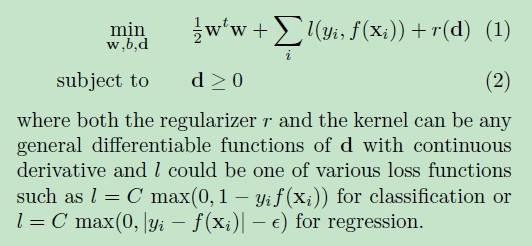


所以从定义上来看,原本用来进行正则化的是0范数,但是由于计算困难,大家才转而使用2范数的。
岭回归
先贴一张《机器学习实战》的图哈

加入偏差:牺牲无偏性
加一点百度百科的数学性解释(感觉又回到了那个被数值分析支配的学期。。。)
来源:https://baike.baidu.com/item/%E5%B2%AD%E5%9B%9E%E5%BD%92
对于有些矩阵,矩阵中某个元素的一个很小的变动,会引起最后计算结果误差很大,这种矩阵称为“病态矩阵”。有些时候不正确的计算方法也会使一个正常的矩阵在运算中表现出病态。
当X不是列满秩时,或者某些列之间的线性相关性比较大时,
的行列式接近于0,即
时误差会很大,传统的最小二乘法缺乏稳定性与可靠性。
为了解决上述问题,我们需要将不适定问题转化为适定问题:我们为上述损失函数加上一个正则化项,变为
其中,我们定义
,于是:
上式中,
是单位矩阵。
随着
的增大,
的绝对值均趋于不断变小,它们相对于正确值
趋于无穷大时,
趋于0。其中,
的改变而变化的轨迹,就称为岭迹。实际计算中可选非常多的
岭回归是对最小二乘回归的一种补充,它损失了无偏性(就是计算没有偏差的意思),来换取高的数值稳定性,从而得到较高的计算精度。


知乎上有位答主说的很透,这里转一下:
来源:https://www.zhihu.com/question/28221429,某知乎用户的回答

所以具体实施其实挺简单的。但是注意,“为了使用岭回归和缩减技术,首先要对特征做标准化处理,使得每个维度的特征具有相同的重要性”,注意这里的“标准化”指的其实是Standardization,是改变了原有分布、变成均值为0方差为1的。具体可以看这篇博文:https://www.cnblogs.com/jiading/p/11575038.html
为什么要标准化,因为很明显,由文章最上面的议论我们可以看出来,在损失函数中加入二范数惩罚项是为了能将一些不必要的w设置为0,这才是岭回归的真正目的,而不仅仅是为X.t/*X“撑场子”保证其可逆。所以,我们可以想象,如果不标准化的话,一些y_i会变的非常大,那么通过公式,我们就很难将这些项对应的w设置为0,而它们却是有可能是不相关的。所以,我们必须让每一项都有一样的“重要性”。使用Standardization之后,连每个特征的样本分布都给你整一样的了,这才是真正的“泯然众人矣”。
特征的值的大小不重要,我们看的关键是它是否和我们要回归的量相关
岭回归的代码其实比较简单:
#岭回归
def ridgeRegres(xMat,yMat,lam=0.2):
xTx = xMat.T*xMat
denom = xTx + eye(shape(xMat)[1])*lam
if linalg.det(denom) == 0.0:
print ("This matrix is singular, cannot do inverse")
return
ws = denom.I * (xMat.T*yMat)
return ws
#岭回归的测试函数
def ridgeTest(xArr,yArr):
xMat = mat(xArr); yMat=mat(yArr).T
yMean = mean(yMat,0)
#数据必须先标准化,才能进行正则化
yMat = yMat - yMean #to eliminate X0 take mean off of Y
#regularize X's
xMeans = mean(xMat,0) #calc mean then subtract it off
xVar = var(xMat,0) #calc variance of Xi then divide by it
xMat = (xMat - xMeans)/xVar
numTestPts = 30
wMat = zeros((numTestPts,shape(xMat)[1]))
for i in range(numTestPts):
#让λ以指数级变换,只是为了看λ很小和很大的时候对结果的影响
ws = ridgeRegres(xMat,yMat,exp(i-10))
wMat[i,:]=ws.T
return wMat

这张图非常好!它直观地体现了上面说的正则化对w的惩罚作用:当λ设置较大的时候,几乎所有的参数都被惩罚到了接近0的地步,注意是接近0但不是0!
为什么不是0,这一点留到下面讲lasso的时候对比着说比较清楚
lasso
lasso和岭回归的唯一区别就是将使用的二范数换成了一范数。但是再引出lasso的公式之前,我们需要先把岭回归的公式修改一下:
这里借用了知乎少整酱的回答中的公式(https://zhuanlan.zhihu.com/p/30535220)
cost function的形式就为:
通过加入此惩罚项进行优化后,限制了回归系数wiwi的绝对值,数学上可以证明上式的等价形式如下:
其中t为某个阈值。
同学们,这里用到的是什么啊?用到的就是拉格朗日乘子法和KKT条件啊,下面的就是不等式约束,把t往左边一挪,就是熟悉的不等式约束的形式了。只不过那个t我们没有在代价函数里面体现,但是这也没什么影响,因为代价函数一求偏导数这些常数就都没有了。
那么类似的,lasso方法只是将上面的公式修改为了:
也就是用了一范数,但就是这一个范数的差别就造成了很大的不同:
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的正则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0
而对于lasso方法,则是会让一些系数真的为0.这一点从几何上比较好解释,这里再借用一下知乎少整酱的回答:
岭回归的几何意义
以两个变量为例, 残差平方和可以表示为
的一个二次函数,是一个在三维空间中的抛物面,可以用等值线来表示。而限制条件
, 相当于在二维平面的一个圆。这个时候等值线与圆相切的点便是在约束条件下的最优点,如下图所示,
LASSO的几何解释
同样以两个变量为例,标准线性回归的cost function还是可以用二维平面的等值线表示,而约束条件则与岭回归的圆不同,LASSO的约束条件可以用方形表示,如下图:
相比圆,方形的顶点更容易与抛物面相交,顶点就意味着对应的很多系数为0,而岭回归中的圆上的任意一点都很容易与抛物面相交很难得到正好等于0的系数。这也就意味着,lasso起到了很好的筛选变量的作用。.
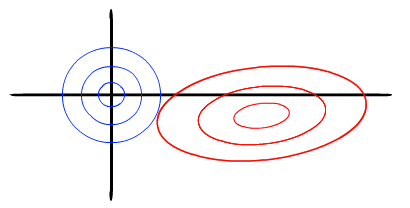
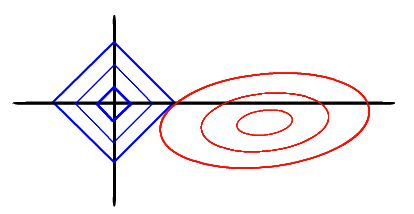
是不是说的特别清楚!
虽然惩罚函数只是做了细微的变化,但是相比岭回归可以直接通过矩阵运算得到回归系数相比,LASSO的计算变得相对复杂。由于惩罚项中含有绝对值,此函数的导数是连续不光滑的,所以无法进行求导并使用梯度下降优化。本部分使用坐标下降发对LASSO回归系数进行计算。
看到这里,同学可能有疑问了:那不能用梯度下降法,为什么不用正规方程法呢?因为正规方程法也是基于求导的呀,忘了的同学看下图(来源:https://blog.csdn.net/qq_36523839/article/details/82931559)

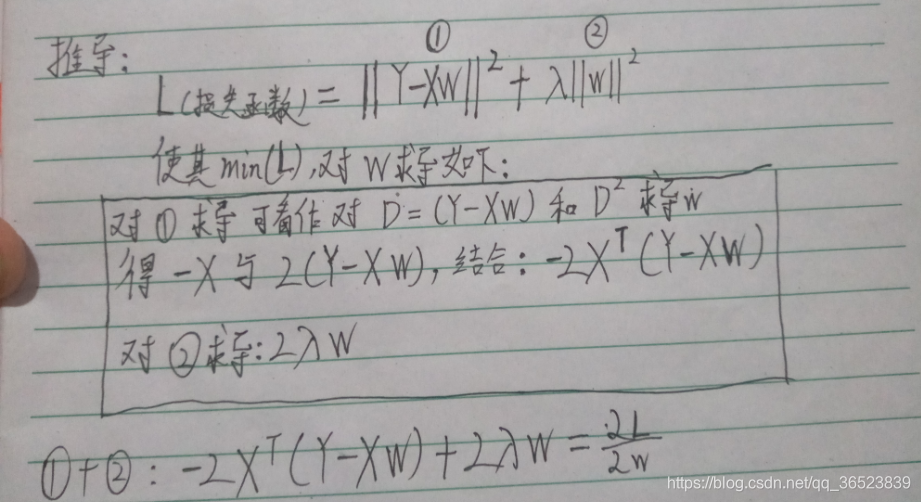
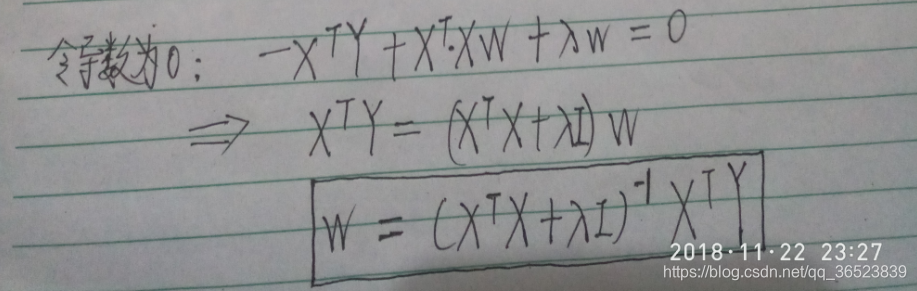
所以只能用坐标下降法。
前向逐步回归

这个算法听着挺玄乎,其实看代码就知道,是属于比较无脑和暴力的方法,效率不会太高。当然实现起来是真的简单。
代码:
'''
Created on Jan 8, 2011
@author: Peter
'''
from numpy import *
#加载数据
def loadDataSet(fileName): #general function to parse tab -delimited floats
#attribute的个数
numFeat = len(open(fileName).readline().split('\t')) - 1 #get number of fields
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat):
lineArr.append(float(curLine[i]))
#dataMat是一个二维矩阵,labelMat是一维的
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat
def rssError(yArr,yHatArr): #yArr and yHatArr both need to be arrays
return ((yArr-yHatArr)**2).sum()
def regularize(xMat):#regularize by columns
inMat = xMat.copy()
inMeans = mean(inMat,0) #calc mean then subtract it off
inVar = var(inMat,0) #calc variance of Xi then divide by it
inMat = (inMat - inMeans)/inVar
return inMat
#前向逐步线性回归,目的是输出线性回归的weight
def stageWise(xArr,yArr,eps=0.01,numIt=100):
#eps是每次迭代的步长,numIt是迭代的次数
xMat = mat(xArr); yMat=mat(yArr).T
yMean = mean(yMat,0)
#标准化,x的标准化使用的是Z-score Normalization,其实是Standardization,改变了原有分布的
yMat = yMat - yMean #can also regularize ys but will get smaller coef
xMat = regularize(xMat)
#m是样本个数,n是特征数
m,n=shape(xMat)
#保存每次迭代之后的结果,测试时候显示迭代过程用的,真正使用的时候只要最后一次就好了
returnMat = zeros((numIt,n)) #testing code remove
#初始的时候所有的weights置为0
ws = zeros((n,1)); wsTest = ws.copy(); wsMax = ws.copy()
for i in range(numIt):
print (ws.T)#输出现在的weight
lowestError = inf;
#对每个变量的系数进行尝试
for j in range(n):
#注意这里不是在-1到1的范围内遍历,而是遍历数组,这个数组中有-1和1两个元素
for sign in [-1,1]:
wsTest = ws.copy()
#改变一个变量的值,或者加上一个步长,或者减去一个步长
wsTest[j] += eps*sign
yTest = xMat*wsTest
#计算误差
rssE = rssError(yMat.A,yTest.A)
if rssE < lowestError:
#如果误差比最小误差小,这个weight的“配方”就留下了
lowestError = rssE
wsMax = wsTest
#最后留下那个最大的weight的配方
ws = wsMax.copy()
returnMat[i,:]=ws.T
return returnMat
机器学习-正则化(岭回归、lasso)和前向逐步回归的更多相关文章
- 岭回归&Lasso回归
转自:https://blog.csdn.net/dang_boy/article/details/78504258 https://www.cnblogs.com/Belter/p/8536939. ...
- python机器学习sklearn 岭回归(Ridge、RidgeCV)
1.介绍 Ridge 回归通过对系数的大小施加惩罚来解决 普通最小二乘法 的一些问题. 岭系数最小化的是带罚项的残差平方和, 其中,α≥0α≥0 是控制系数收缩量的复杂性参数: αα 的值越大,收缩量 ...
- 通俗易懂--岭回归(L2)、lasso回归(L1)、ElasticNet讲解(算法+案例)
1.L2正则化(岭回归) 1.1问题 想要理解什么是正则化,首先我们先来了解上图的方程式.当训练的特征和数据很少时,往往会造成欠拟合的情况,对应的是左边的坐标:而我们想要达到的目的往往是中间的坐标,适 ...
- 线性回归——lasso回归和岭回归(ridge regression)
目录 线性回归--最小二乘 Lasso回归和岭回归 为什么 lasso 更容易使部分权重变为 0 而 ridge 不行? References 线性回归很简单,用线性函数拟合数据,用 mean squ ...
- sklearn 岭回归
可以理解的原理描述: [机器学习]岭回归(L2正则) 最小二乘法与岭回归的介绍与对比 多重共线性的解决方法之——岭回归与LASSO
- 【机器学习】正则化的线性回归 —— 岭回归与Lasso回归
注:正则化是用来防止过拟合的方法.在最开始学习机器学习的课程时,只是觉得这个方法就像某种魔法一样非常神奇的改变了模型的参数.但是一直也无法对其基本原理有一个透彻.直观的理解.直到最近再次接触到这个概念 ...
- 机器学习之五 正则化的线性回归-岭回归与Lasso回归
机器学习之五 正则化的线性回归-岭回归与Lasso回归 注:正则化是用来防止过拟合的方法.在最开始学习机器学习的课程时,只是觉得这个方法就像某种魔法一样非常神奇的改变了模型的参数.但是一直也无法对其基 ...
- 机器学习--Lasso回归和岭回归
之前我们介绍了多元线性回归的原理, 又通过一个案例对多元线性回归模型进一步了解, 其中谈到自变量之间存在高度相关, 容易产生多重共线性问题, 对于多重共线性问题的解决方法有: 删除自变量, 改变数据形 ...
- 机器学习入门线性回归 岭回归与Lasso回归(二)
一 线性回归(Linear Regression ) 1. 线性回归概述 回归的目的是预测数值型数据的目标值,最直接的方法就是根据输入写出一个求出目标值的计算公式,也就是所谓的回归方程,例如y = a ...
随机推荐
- FastAdmin 添加新字段后,不显示,可以直接去修改对应的js
- dnSpy PE format ( Portable Executable File Format)
Portable Executable File Format PE Format 微软官方的 What is a .PE file in the .NET framework? [closed] ...
- springboot备忘
1.springboot中有ApplicationRunner类,如果项目中的启动类名称也是ApplicationRunner,单元测试时需要注意:import不要import到springboot的 ...
- __declspec(dllexport)的使用
1. 用法 在 VS 的“预编译”选项里定义_EXPORTING宏 #ifdef _EXPORTING #define API_DECLSPEC __declspec(dllexport) #else ...
- DAY 5 & 6
DAY 5 之前整过一个DP 动态规划 DP 啥是DP? DP等价于DAG!!! (1)无后效性:DP的所有状态之间组成一个DAG (2)最优子结构 (3)阶段性 (4)转移方程:如何计算状态 一般 ...
- JDK压缩指针
https://www.cnblogs.com/iceAeterNa/p/4877549.html
- leetcode315 计算右侧小于当前元素的个数
1. 采用归并排序计算逆序数组对的方法来计算右侧更小的元素 time O(nlogn): 计算逆序对可以采用两种思路: a. 在左有序数组元素出列时计算右侧比该元素小的数字的数目为 cnt=r-mid ...
- shell案例(6):1、创建用户 2、创建目录 3、创建文件 4、退出
脚本基本要求 1.创建用户2.创建目录3.创建文件4.退出 #!/bin/bash #author:zhiping.wang Check_error() { ] then echo "$1 ...
- 五十六:flask文件上传之上传文件与访问上传的文件
实现上传文件 1.在form表单中,需指定enctype="multipart/form-data",且文件上传的input标签type="file"2.在后台 ...
- linux常用命令(16)locate命令
locate 让使用者可以很快速的搜寻档案系统内是否有指定的档案.其方法是先建立一个包括系统内所有档案名称及路径的数据库,之后当寻找时就只需查询这个数据库,而不必实际深入档案系统之中了.在一般的 di ...