使用selenium 多线程爬取爱奇艺电影信息
使用selenium 多线程爬取爱奇艺电影信息
转载请注明出处。
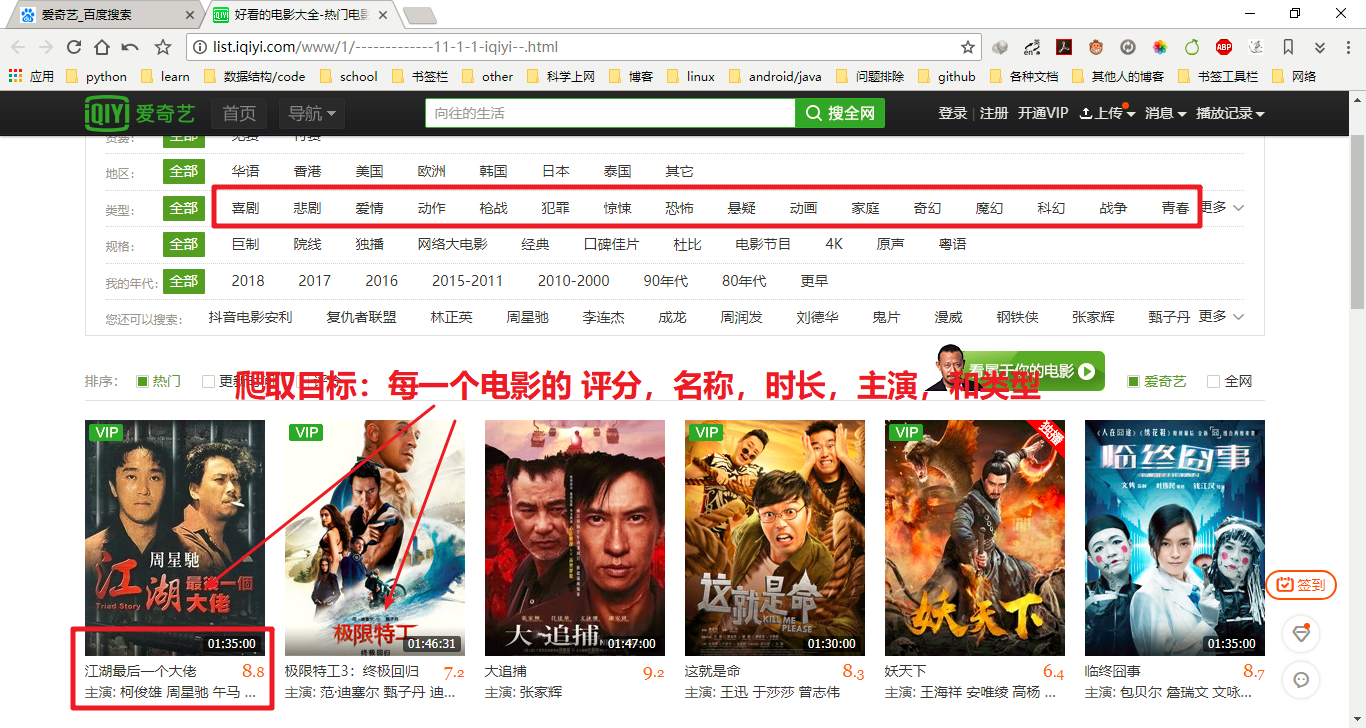
爬取目标:每个电影的评分、名称、时长、主演、和类型
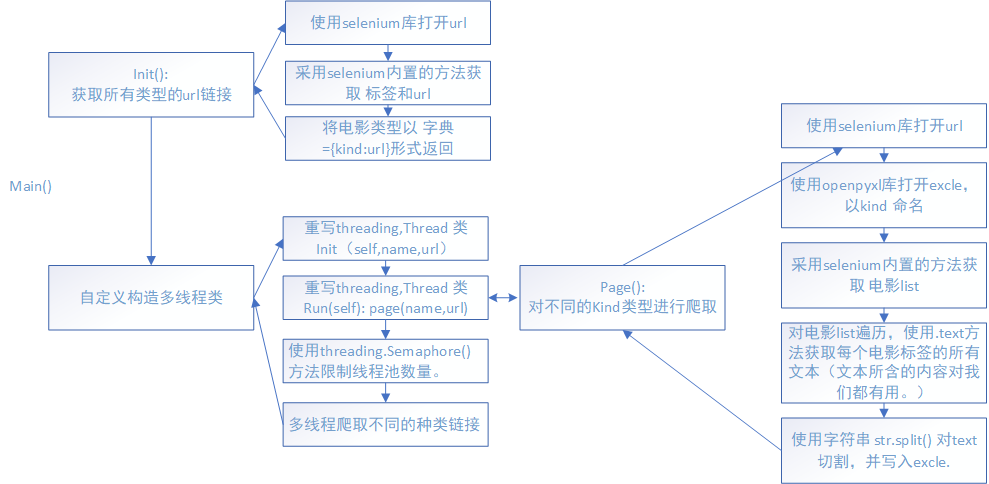
爬取思路:
源文件:(有注释)
from selenium import webdriver
from threading import Thread
import threading
import time
import openpyxl #操作excel
#爱奇艺的看电影的url 不是首页。
url='http://list.iqiyi.com/www/1/-8------------11-1-1-iqiyi--.html'
#自定义一个线程类 实现多线程爬取
class M_Thread(Thread):
def __init__(self,name1,url):
Thread.__init__(self)
self.url=url
self.name1=name1
def run(self):
self.kind_movie=page(self.name1,self.url)
#page运行完后lock进行 让 当前movie 结束
# 初始化爬虫,从url中爬爬取各个种类相对于的连接。
def init():
# 浏览器 无界面 和有界面。
fireFoxOptions = webdriver.FirefoxOptions()
fireFoxOptions.set_headless()
Brower = webdriver.Firefox(firefox_options=fireFoxOptions)
# Brower = webdriver.Firefox()
Brower.get(url)
#定位到种类标签 (发现不用Xpath容易出错)
kind=Brower.find_element_by_xpath("/html/body/div[3]/div/div/div[1]/div[4]/ul")
#a标签就是那个 连接
kinds=kind.find_elements_by_tag_name("a")
#将每个类型的页面连接储存到kinds_dict中
movie_kind_link={}
for a in kinds:
try:
if(a.text=="全部" or a.text==""): #去掉 全部类型 和一个空类型。
continue
movie_kind_link[a.text] = a.get_attribute("href")
except:
print("error!")
continue
Brower.close()
return movie_kind_link #返回的是 种类:url 字典。
def page(name,link):
#每一个种类 都打开一个excle储存
wordbook=openpyxl.Workbook()
sheet1=wordbook.active
num=1
#初始化excle第一行
for qwe in ["电影名","时长","评分","类型","演员"]:
sheet1.cell(row=1,column=num,value=qwe)
num+=1
num=2
#本来一开始是用txt写的但是布局太丑。 优点是速度快!
# 采用过 用数据库存 ,但是同时写入大量数据 总是会出莫名奇妙的错误。暂时没解决
# file=open(name+".txt","w",encoding="utf-8")
fireFoxOptions = webdriver.FirefoxOptions()
fireFoxOptions.set_headless()
Br = webdriver.Firefox(firefox_options=fireFoxOptions)
# Br = webdriver.Firefox()
# try:
Br.get(link)
print("正在打开 %s 页面"%name)
page = Br.find_element_by_class_name("mod-page")
page_href=[]
for aa in page.find_elements_by_tag_name("a"):
page_href.append(aa.get_attribute("href"))
for cc in page_href:
print("*****正在爬取 {} 的第 {} 页*****".format(name,page_href.index(cc)+1))
# time.sleep(1)
# 第一页不用重新打开
if(page_href.index(cc)!=0):
Br.get(cc)
#movie 即当前页面的 电影tag 列表
movie=Br.find_element_by_class_name("wrapper-piclist").find_elements_by_tag_name("li")
for bb in movie:
# try:
things=bb.text.split("\n")
"""
这里为什么要区分?
爱奇艺很垃圾,有点电影评分不给,
但是在直接获取text在if判断和分元素去获取四个属性,我觉得还是if好用。
"""
if(len(things)==4):
sheet1.cell(row=num, column=1, value=things[2])
sheet1.cell(row=num, column=2, value=things[0])
sheet1.cell(row=num, column=3, value=things[1])
sheet1.cell(row=num, column=4, value=name)
sheet1.cell(row=num, column=5, value=things[3])
num+=1
elif (len(things) == 3):
sheet1.cell(row=num, column=1, value=things[1])
sheet1.cell(row=num, column=2, value="*")
sheet1.cell(row=num, column=3, value=things[0])
sheet1.cell(row=num, column=4, value=name)
sheet1.cell(row=num, column=5, value=things[2])
num +=1
else:
print("error (moive)")
# break
Lock_thread.release() # 解锁
wordbook.save(name+".xlsx")
Br.close()
if __name__=="__main__":
#控制线程最大数量为3
Lock_thread= threading.Semaphore(3) #控制线程数为3
#kind:link
dict=init()
# print(dict)
#多线程爬取
for name1,link in dict.items():
Lock_thread.acquire() #枷锁 ,在每一个page()运行完后解锁
thread_live=M_Thread(name1,link)
print(name1," begin")
thread_live.start()
time.sleep(3)
使用selenium 多线程爬取爱奇艺电影信息的更多相关文章
- Python爬取爱奇艺资源
像iqiyi这种视频网站,现在下载视频都需要下载相应的客户端.那么如何不用下载客户端,直接下载非vip视频? 选择你想要爬取的内容 该安装的程序以及运行环境都配置好 下面这段代码就是我在爱奇艺里搜素“ ...
- 如何利用python爬虫爬取爱奇艺VIP电影?
环境:windows python3.7 思路: 1.先选取你要爬取的电影 2.用vip解析工具解析,获取地址 3.写好脚本,下载片断 4.将片断利用电脑合成 需要的python模块: ##第一 ...
- Python爬虫实战案例:爬取爱奇艺VIP视频
一.实战背景 爱奇艺的VIP视频只有会员能看,普通用户只能看前6分钟.比如加勒比海盗5的URL:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1 ...
- Python 爬虫实例(5)—— 爬取爱奇艺视频电视剧的链接(2017-06-30 10:37)
1. 我们找到 爱奇艺电视剧的链接地址 http://list.iqiyi.com/www/2/-------------11-1-1-iqiyi--.html 我们点击翻页发现爱奇艺的链接是这样的 ...
- Python爬取爱奇艺【老子传奇】评论数据
# -*- coding: utf-8 -*- import requests import os import csv import time import random base_url = 'h ...
- 爬取爱奇艺电视剧url
----因为需要顺序,所有就用串行了---- import requests from requests.exceptions import RequestException import re im ...
- 使用Beautiful Soup爬取猫眼TOP100的电影信息
使用Beautiful Soup爬取猫眼TOP100的电影信息,将排名.图片.电影名称.演员.时间.评分等信息,提取的结果以文件形式保存下来. import time import json impo ...
- casperjs 抓取爱奇艺高清视频
CasperJS 是一个开源的导航脚本和测试工具,使用 JavaScript 基于 PhantomJS 编写,用于测试 Web 应用功能,Phantom JS是一个服务器端的 JavaScript A ...
- 爬取迷你mp4各个电影信息
网站:www.minimp4.com # coding=utf-8 import requests from lxml import etree class Minimpe_moves(object) ...
随机推荐
- [Visual Studio] - Unable to launch the IIS Express Web server 问题之解决
背景 Visual Studio 2015 在 Debug 模式下调试失败. 错误 解决 删除解决方案下 .vs/config 文件夹,重新运行解决方案可进行调试. 参考资料 https://stac ...
- Node.js安装windows环境
一.安装环境 1.本机系统:Windows 10 Pro(64位)2.Node.js:v6.9.2LTS(64位) 二.安装Node.js步骤 1.下载对应你系统的Node.js版本:https:// ...
- Redis搭建Windows平台
安装程序下载 从官网下载安装程序. https://redis.io/download https://github.com/MicrosoftArchive/redis/releases 新地址:h ...
- python使用ORM之如何调用多对多关系
在models.py中,我创建了两张表,他们分别是作者表和书籍表,且之间的关系是多对多. # 书 class Book(models.Model): id = models.AutoField(pri ...
- Django REST framework 基本组件
一.序列化组件 简单使用 开发我们的Web API的第一件事是为我们的Web API提供一种将代码片段实例序列化和反序列化为诸如json之类的表示形式的方式.我们可以通过声明与Django forms ...
- youku项目总结(粗略总结)
一.ORM 之前我们都是以文件保存的形式存储数据,这次我们用的是数据库结合python使用,用到 ORM:关系型映射 类>>数据库的一张表 对象>>表一条记录 对象.属性> ...
- C/C++中vector与list的区别
1.vector数据结构vector和数组类似,拥有一段连续的内存空间,并且起始地址不变.因此能高效的进行随机存取,时间复杂度为o(1);但因为内存空间是连续的,所以在进行插入和删除操作时,会造成内存 ...
- 【Leetcode】746. Min Cost Climbing Stairs
题目地址: https://leetcode.com/problems/min-cost-climbing-stairs/description/ 解题思路: 官方给出的做法是倒着来,其实正着来也可以 ...
- git出现Invalid path
今天换了电脑,我直接把整个仓库从电脑A复制到了电脑B,包括仓库下面的 .git 文件夹. 修改代码后我执行了一下 git add . 出现了一个报错 fatal: Invalid path 'D:/S ...
- 湖北校园网PC端拨号算法逆向
湖北校园网PC端拨号算法逆向 前言 上一文 PPPoE中间人拦截以及校园网突破漫谈我们谈到使用 PPPoE 拦截来获取真实的账号密码. 在这个的基础上,我对我们湖北的客户端进行了逆向,得到了拨号加密算 ...