mapreduce运行的bug收录
在8088端口可以看到日志文件(主要看error),操作如下:



1.window jdk版本最好和linux jdk 版本一致,不然容易出现莫名奇妙的bug
之前出现一个bug: UnsupportedClassVersionError: .......
就是版本错误引起的,花了好长的时间才搞定
2.当出现ClassNotFoundException 时,需要将src的文件export成jar包放入如下路径,然后在主函数加入代码如下:

3.如果出现 INFO mapreduce.Job: Job job_1398669840354_0003 failed with state FAILED due to:
Application application_1398669840354_0003 failed 2 times due to AM Container for appattempt_1398669840354_0003_000002 exited with exitCode: 1
due to: Exception from container-launch: org.apache.hadoop.util.Shell$ExitCodeException: .......
是mapred-default.xml,yarn-default.xml 没加如下参数(在最后添加即可):
mapred-default.xml:
- <property>
- <name>mapreduce.application.classpath</name>
- <value>
- $HADOOP_CONF_DIR,
- $HADOOP_COMMON_HOME/share/hadoop/common/*,
- $HADOOP_COMMON_HOME/share/hadoop/common/lib/*,
- $HADOOP_HDFS_HOME/share/hadoop/hdfs/*,
- $HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,
- $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,
- $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*,
- $HADOOP_YARN_HOME/share/hadoop/yarn/*,
- $HADOOP_YARN_HOME/share/hadoop/yarn/lib/*
- </value>
- </property>
yarn-default.xml :
- <property>
- <name>mapreduce.application.classpath</name>
- <value>
- $HADOOP_CONF_DIR,
- $HADOOP_COMMON_HOME/share/hadoop/common/*,
- $HADOOP_COMMON_HOME/share/hadoop/common/lib/*,
- $HADOOP_HDFS_HOME/share/hadoop/hdfs/*,
- $HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,
- $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,
- $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*,
- $HADOOP_YARN_HOME/share/hadoop/yarn/*,
- $HADOOP_YARN_HOME/share/hadoop/yarn/lib/*
- </value>
- </property>
(这两个文件分别在hadoop-mapreduce-client-core-2.8.5.jar,hadoop-yarn-api-2.8.5.jar 中)
注:得先将这两个jar包remove bulid Path ,然后才能修改 .xml文件
注:!!!如果你在eclipse启动mapreduce,则改window的jar包,在linux机则改hadoop的mapred-site.xml和yarn-site.xml文件
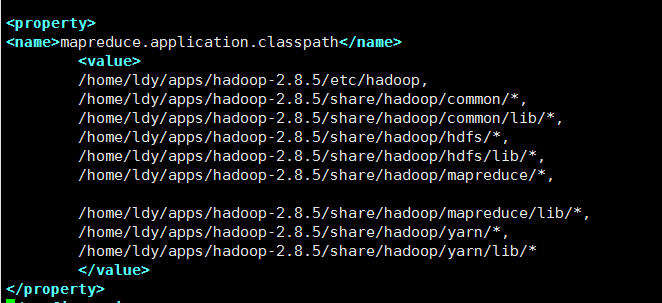
mapred-site.xml:
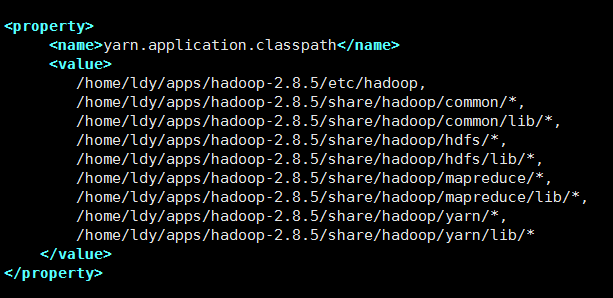
yarn-site.xml:
4.若出现AccessContorlException:Permisson denied:.........
应该是用户权限问题,加入如下代码:
- //1.设置yarn处理数据时的user
- System.setProperty("HADOOP_USER_NAME","root");
5.如出现ExitCodeException:exit code =1 : /bin/bash .........
是因为Job 任务是在window提交的,而接受方是yarn,编辑脚本命令时是以window为标准,所以运行脚本命令时就出错了
加如下代码:
- //4.跨平台提交时,需要加这个参数
- conf.set("mapreduce.app-submission.cross-platform", "true");
6.出现ExitCodeException exitCode=127:
- For more detailed output, check application tracking page:http://dev-hadoop6:8088/cluster/app/application_15447
- Diagnostics: Exception from container-launch.
- Container id: container_1544766080243_0018_02_000001
- Exit code: 127
- Stack trace: ExitCodeException exitCode=127:
- at org.apache.hadoop.util.Shell.runCommand(Shell.java:585)
- at org.apache.hadoop.util.Shell.run(Shell.java:482)
- at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:776)
- at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerE
- at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLa
- at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLa
- at java.util.concurrent.FutureTask.run(FutureTask.java:266)
- at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
- at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
- at java.lang.Thread.run(Thread.java:748)
- Container exited with a non-zero exit code 127
- Failing this attempt. Failing the application.
- 18/12/14 17:48:56 INFO mapreduce.Job: Counters: 0
- 18/12/14 17:48:56 WARN mapreduce.HdfsMapReduce: Path /mapred-temp/job-user-analysis-statistic/01/top_in is not
- java.io.IOException: Set input path failed !
- at com.tracker.offline.common.mapreduce.HdfsMapReduce.setInputPath(HdfsMapReduce.java:165)
- at com.tracker.offline.common.mapreduce.HdfsMapReduce.buildJob(HdfsMapReduce.java:122)
- at com.tracker.offline.common.mapreduce.HdfsMapReduce.waitForCompletion(HdfsMapReduce.java:65)
- at com.tracker.offline.business.job.user.JobAnalysisStatisticMR.main(JobAnalysisStatisticMR.java:88)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:498)
- at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
- at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
这是编码报错,yarn-env.sh不对
修改yarn-env.sh的java_home即可
mapreduce运行的bug收录的更多相关文章
- mapreduce运行机制
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt243 谈mapreduce运行机制,可以从很多不同的角度来描述,比如说从ma ...
- MapReduce运行原理
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各 ...
- Hadoop 2.6 MapReduce运行原理详解
市面上的hadoop权威指南一类的都是老版本的书籍了,索性学习并翻译了下最新版的Hadoop:The Definitive Guide, 4th Edition与大家共同学习. 我们通过提交jar包, ...
- MapReduce 运行机制
Hadoop中的MapReduce是一个使用简单的软件框架,基于它写出来的应用程序能够运行在由上千个机器组成的大型集群上,并且以一种可靠容错并行处理TB级别的数据集. 一个MapReduce作业(jo ...
- Mapreduce运行过程分析(基于Hadoop2.4)——(一)
1 概述 该瞅瞅MapReduce的内部执行原理了,曾经仅仅知道个皮毛,再不搞搞,不然怎么死的都不晓得.下文会以2.4版本号中的WordCount这个经典样例作为分析的切入点.一步步来看里面究竟是个什 ...
- MapReduce运行流程分析
研究MapReduce已经有一段时间了.起初是从分析WordCount程序开始,后来开始阅读Hadoop源码,自认为已经看清MapReduce的运行流程.现在把自己的理解贴出来,与大家分享,欢迎纠错. ...
- Hadoop Mapreduce运行流程
Mapreduce的运算过程为两个阶段: 第一个阶段的map task相互独立,完全并行: 第二个阶段的reduce task也是相互独立,但依赖于上一阶段所有map task并发实例的输出: 这些t ...
- 2017.5.11 MapReduce运行机制
和HDFS一样,MapReduce也是采用Master/Slave的架构 MapReduce1包含4个部分:Client.JobTracker.TaskTracker和Task Client 将JAR ...
- MapReduce运行原理和过程
原文 一.Map的原理和运行流程 Map的输入数据源是多种多样的,我们使用hdfs作为数据源.文件在hdfs上是以block(块,Hdfs上的存储单元)为单位进行存储的. 1.分片 我们将这一个个bl ...
随机推荐
- hdu 5723 Abandoned country 最小生成树+子节点统计
Abandoned country Time Limit: 8000/4000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others ...
- luoguP2863 [USACO06JAN]牛的舞会The Cow Prom
P2863 [USACO06JAN]牛的舞会The Cow Prom 123通过 221提交 题目提供者 洛谷OnlineJudge 标签 USACO 2006 云端 难度 普及+/提高 时空限制 1 ...
- Codeforces 1167 F Scalar Queries 计算贡献+树状数组
题意 给一个数列\(a\),定义\(f(l,r)\)为\(b_1, b_2, \dots, b_{r - l + 1}\),\(b_i = a_{l - 1 + i}\),将\(b\)排序,\(f(l ...
- 创建虚拟机,安装操作系统,xshell6远程链接
一.创建虚拟机 1. 首先安装vmware,注意在安装中,下面的两项不要勾选,一路下一步 2.完成安装打开之后,创建新的虚拟机 3.虚拟机创建完成,需要改配置 4.然后设置网段 5.查看服务,在运行状 ...
- codeforces400C
Inna and Huge Candy Matrix CodeForces - 400C Inna and Dima decided to surprise Sereja. They brought ...
- [Ubuntu]更改所有子文件和子目录所有者权限
https://www.linuxidc.com/Linux/2015-03/114695.htm change mode -> chmod change owner -> chown 1 ...
- 微信小程序_(组件)可拖动movable-view
微信小程序movable-view组件官方文档 传送门 Learn 一.moveable-view组件 一.movable-view组件 direction:movable-view的移动方向,属性值 ...
- legend3---6、legend3爬坑杂记
legend3---6.legend3爬坑杂记 一.总结 一句话总结: 学东西不做项目也学不到深处,其实也就是学了没理解透, 1.lavarel中模型关联可以用的实质是? lavarel在数据库中插入 ...
- Android——NativeActivity - C/C++ Apk开发
android基本的四大组件之一Activity,android开发的第一个hello world 创建的就是这个继承了Activity类的类,拥有对应的生命周期,由AMS维护,只需要重写父类对应的方 ...
- defer
在Go语言的函数中return语句在底层并不是原子操作,它分为给返回值赋值和RET指令两步.而defer语句执行的时机就在返回值赋值操作后,RET指令执行前.具体如下图所示: 在defer函数定义时, ...