[爬虫] selenium介绍
认识selenium
在爬取百度文库的过程中,我们需要使用到一个工具selenium(浏览器自动测试框架),selenium是一个用于web应用程序测试的工具,它可以测试直接运行在浏览器中,就像我们平时用浏览器上网一样,支持IE(7,8,9,10,11),firefox,safari,chrome,opera等。所以,我们可以使用它去爬取网站的数据,用ajax加载的数据也可以爬取,还可以模拟用户登录,爬取登录之后的数据。
selenium的配置
首先 pip install selenium 安装,然后下载chromedirver.exe驱动器,网址为https://chromedriver.storage.googleapis.com/index.html,下载与浏览器对应版本,如果是 python,添加到 Python 目录下,我的是 Anaconda3,添加到 anaconda3 的 scripts 目录下即可,当然也可以使用绝对路径加载。
selenium使用
下面的代码实现了模拟提交搜索的功能,首先等页面加载完成,然后输入到搜索框文本,点击提交,然后使用page_source打印提交后的页面的信息。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome()
driver.get("http://www.python.org")
elem = driver.find_element_by_name("q")
elem.send_keys("pycon")
elem.send_keys(Keys.RETURN)
print(driver.page_source)
其中 driver.get 方法会打开请求的URL,WebDriver 会等待页面完全加载完成之后才会返回,即程序会等待页面的所有内容加载完成,JS渲染完毕之后才继续往下执行。注意:如果这里用到了特别多的 Ajax 的话,程序可能不知道是否已经完全加载完毕。
WebDriver 提供了许多寻找网页元素的方法,譬如 find_element_by_* 的方法。例如一个输入框可以通过 find_element_by_name 方法寻找 name 属性来确定。
然后我们输入来文本然后模拟点击了回车,就像我们敲击键盘一样。我们可以利用 Keys 这个类来模拟键盘输入。
最后最重要的一点是可以获取网页渲染后的源代码。通过,输出 page_source 属性即可。这样,我们就可以做到网页的动态爬取了。
元素选取
单个元素选取:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
多个元素选取:
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
这些方法跟JavaScript的一些方法有相似之处,find_element_by_id,就是根据标签的id属性查找元素,find_element_by_name,就是根据标签的name属性查找元素。举个简单的例子,比如我想找到下面这个元素:
<input type="text" name="passwd" id="passwd-id" />
我们可以这样获取它:
element = driver.find_element_by_id("passwd-id")
element = driver.find_element_by_name("passwd")
element = driver.find_elements_by_tag_name("input")
element = driver.find_element_by_xpath("//input[@id='passwd-id']")
前三个都很好理解,最后一个xpath什么意思?这个无需着急,xpath是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素,在后面我会进行单独讲解。
界面交互
通过元素选取,我们能够找到元素的位置,我们可以根据这个元素的位置进行相应的事件操作,例如输入文本框内容、鼠标单击、填充表单、元素拖拽等等。由于篇幅原因,我就不一一讲解了,主要讲解本次实战用到的鼠标单击,更详细的内容,可以查看官方文档。
elem = driver.find_element_by_xpath("//a[@data-fun='next']")
elem.click()
比如上面这句话,我使用find_element_by_xpath()找到元素位置,暂且不用理会这句话什么意思,暂且理解为找到了一个按键的位置。然后我们使用click()方法,就可以触发鼠标左键单击事件。是不是很简单?但是有一点需要注意,就是在点击的时候,元素不能有遮挡。什么意思?就是说我在点击这个按键之前,窗口最好移动到那里,因为如果这个按键被其他元素遮挡,click()就触发异常。因此稳妥起见,在触发鼠标左键单击事件之前,滑动窗口,移动到按键上方的一个元素位置:
page = driver.find_elements_by_xpath("//div[@class='page']")
driver.execute_script('arguments[0].scrollIntoView();', page[-1]) #拖动到可见的元素去
上面的代码,就是将窗口滑动到page这个位置,在这个位置,我们能够看到我们需要点击的按键。
添加User-Agent
使用webdriver,是可以更改User-Agent的,代码如下:
from selenium import webdriver options = webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"')
driver = webdriver.Chrome(chrome_options=options)
driver.get('https://www.baidu.com/')
在电脑的User-Agent下办不到的事情,可以试试在手机的User-Agent下弄弄,没准就简单了好多。
Xpath
这个方法是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素。在正式开始使用XPath进行定位前,我们先了解下什么是XPath。XPath是XML Path的简称,由于HTML文档本身就是一个标准的XML页面,所以我们可以使用XPath的语法来定位页面元素。
假设我们现在以图所示HTML代码为例,要引用对应的对象,XPath语法如下:

绝对路径写法(只有一种),写法如下:
引用页面上的form元素(即源码中的第3行):
/html/body/form[1]
下面是相对路径的引用写法:
查找页面根元素:
//查找页面上所有的input元素:
//input查找页面上第一个form元素内的直接子input元素(即只包括form元素的下一级input元素,使用绝对路径表示,单/号):
//form[1]/input查找页面上第一个form元素内的所有子input元素(只要在form元素内的input都算,不管还嵌套了多少个其他标签,使用相对路径表示,双//号):
//form[1]//input查找页面上第一个form元素:
//form[1]查找页面上id为loginForm的form元素:
//form[@id='loginForm']查找页面上具有name属性为username的input元素:
//input[@name='username']查找页面上id为loginForm的form元素下的第一个input元素:
//form[@id='loginForm']/input[1]查找页面具有name属性为contiune并且type属性为button的input元素:
//input[@name='continue'][@type='button']查找页面上id为loginForm的form元素下第4个input元素:
//form[@id='loginForm']/input[4]
动手实战
爬取目标网页的内容,由于网页的百度文库页面复杂,可能抓取内容不全,因此使用User-Agent,模拟手机登录。
需要匹配的内容如下
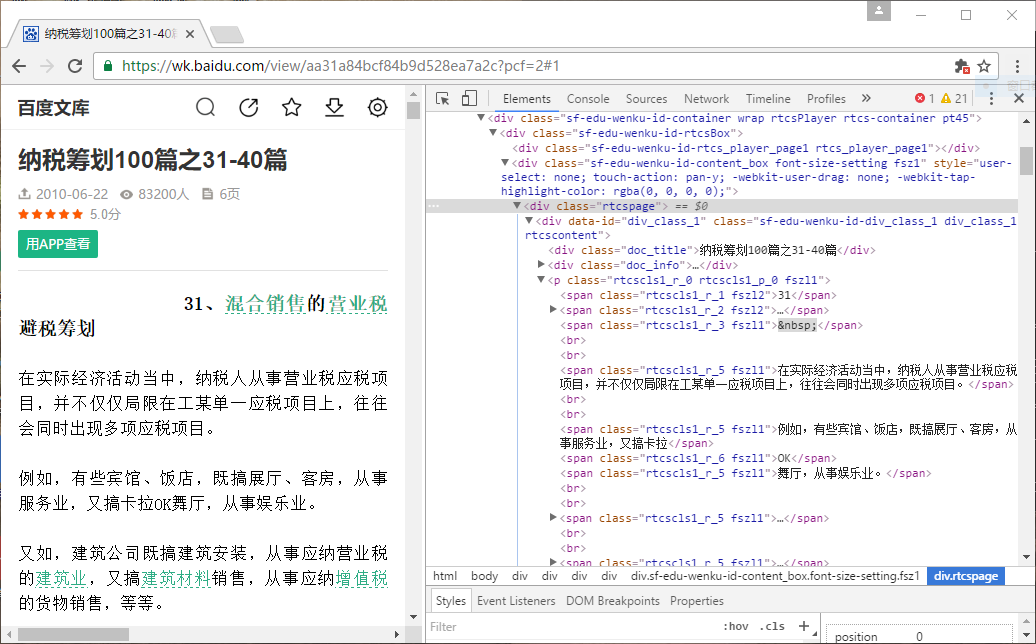
代码如下:
# -*- coding: utf-8 -*-
from selenium import webdriver
from bs4 import BeautifulSoup
import time options = webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"')
driver = webdriver.Chrome(chrome_options=options)
driver.get('https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html')
time.sleep(5)
html = driver.page_source
bf1 = BeautifulSoup(html, 'html.parser')
result = bf1.find_all(class_='rtcspage')
for each_result in result:
for page in each_result.find_all('p'):
for each in page.children:
if each.name == 'span':
if each.children == None:
print(each.string,end='')
else:
for x in each.children:
if(x.string == None):pass
else:print(x.string,end='')
elif each.name == 'br':print('')
print('')
其中 class_ 是为了避免与关键词 class 冲突。
爬取结果如下,内容还是蛮规整的
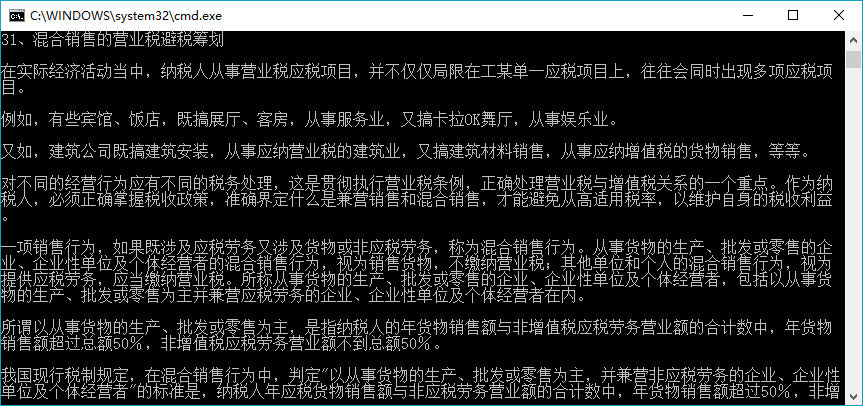
reference:
http://blog.csdn.net/c406495762/article/details/72331737
http://blog.csdn.net/sinat_29957455/article/details/77905719
[爬虫] selenium介绍的更多相关文章
- [Python爬虫] Selenium实现自动登录163邮箱和Locating Elements介绍
前三篇文章介绍了安装过程和通过Selenium实现访问Firefox浏览器并自动搜索"Eastmount"关键字及截图的功能.而这篇文章主要简单介绍如何实现自动登录163邮箱,同时 ...
- [python爬虫] Selenium常见元素定位方法和操作的学习介绍
这篇文章主要Selenium+Python自动测试或爬虫中的常见定位方法.鼠标操作.键盘操作介绍,希望该篇基础性文章对你有所帮助,如果有错误或不足之处,请海涵~同时CSDN总是屏蔽这篇文章,再加上最近 ...
- Python 爬虫利器 Selenium 介绍
Python 爬虫利器 Selenium 介绍 转 https://mp.weixin.qq.com/s/YJGjZkUejEos_yJ1ukp5kw 前面几节,我们学习了用 requests 构造页 ...
- [python爬虫] Selenium常见元素定位方法和操作的学习介绍(转载)
转载地址:[python爬虫] Selenium常见元素定位方法和操作的学习介绍 一. 定位元素方法 官网地址:http://selenium-python.readthedocs.org/locat ...
- [Python爬虫] Selenium+Phantomjs动态获取CSDN下载资源信息和评论
前面几篇文章介绍了Selenium.PhantomJS的基础知识及安装过程,这篇文章是一篇应用.通过Selenium调用Phantomjs获取CSDN下载资源的信息,最重要的是动态获取资源的评论,它是 ...
- [Python爬虫] Selenium获取百度百科旅游景点的InfoBox消息盒
前面我讲述过如何通过BeautifulSoup获取维基百科的消息盒,同样可以通过Spider获取网站内容,最近学习了Selenium+Phantomjs后,准备利用它们获取百度百科的旅游景点消息盒(I ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- 爬虫-----selenium模块自动爬取网页资源
selenium介绍与使用 1 selenium介绍 什么是selenium?selenium是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作. sel ...
- python爬虫---selenium库的用法
python爬虫---selenium库的用法 selenium是一个自动化测试工具,支持Firefox,Chrome等众多浏览器 在爬虫中的应用主要是用来解决JS渲染的问题. 1.使用前需要安装这个 ...
随机推荐
- TensorFlow2.0提示Cannot find reference 'keras' in __init__.py
使用TensorFlow2.0导入from tensorflow.keras import layers会出现Cannot find reference 'keras' in __init__.py提 ...
- if语句分析
1.if语句的反汇编判断 if语句反汇编后的标志: 执行各类影响标志位的指令 jxx xxxx 如果遇到上面的指令,则很可能是if语句: 例如: 1.案例一 ...
- VirtualBox 安装CentOS虚拟机网卡配置
VirtualBox虚拟机网络设置(NAT+HOST-ONLY) 目标: 虚拟机可以像宿主机一样访问互联网和其他主机 宿主机和虚拟机可以相互访问 使用NAT实现目标一 使用Host-Only实现目标二 ...
- Linux和其他机器共享文件
在实际当中,Linux服务器在公网上,我们的windows电脑在局域网中,因此这个共享并不实际. 安装vsftpd 注:安装之后需要验证ftp是否工作,这时应该在本机验证,而不应该在windows电脑 ...
- hdu 5753
Permutation Bo Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others) ...
- 背景(background)
背景(background) 背景家族由5个主要的背景属性组成 background-color背景颜色 background-color:colorNome(取值 如:颜色名 red green. ...
- Python - 工具:将大图切片成小图,将小图组合成大图
训练keras时遇到了一个问题,就是内存不足,将 .fit 改成 .fit_generator以后还是放不下一张图(我的图片是8192×8192的大图==64M).于是解决方法是将大图切成小图,把小图 ...
- C与C++ 中 struct和typedef struct
总体分两块 1 首先://注意在C和C++里不同在C中定义一个结构体类型要用typedef: typedef struct Student { int a; }Stu; 于是在声明变量的时候就可:St ...
- Druid连接池(无框架)
关于连接池有不少技术可以用,例如c3p0,druid等等,因为druid有监控平台,性能在同类产品中算top0的.所以我采用的事druid连接池. 首先熟悉一个技术,我们要搞明白,为什么要用他, 他能 ...
- __declspec(dllexport)的使用
1. 用法 在 VS 的“预编译”选项里定义_EXPORTING宏 #ifdef _EXPORTING #define API_DECLSPEC __declspec(dllexport) #else ...