scrapy 学习笔记2 数据持久化
前情提要:校花网爬取,并进行数据持久化
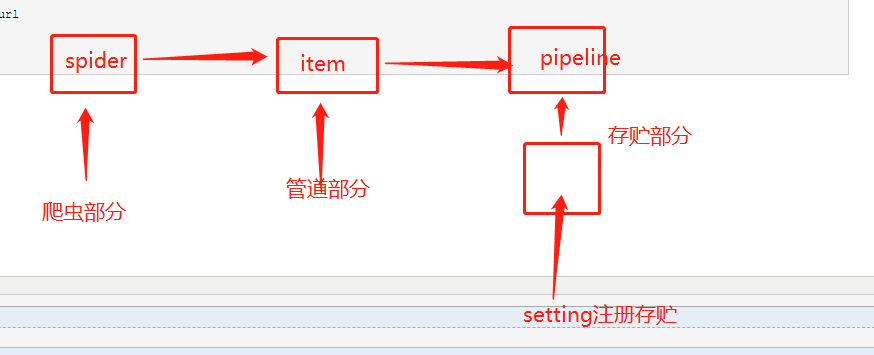
数据持久化操作
--编码流程:
1:数据解析
2:封装item 类
3: 将解析的数据存储到实例化好的item 对象中
4:提交item
5:管道接收item然后对item进行io操作
6:开启管道
-- 主意事项:
-将同一份数据存储到不同平台中:
-: 管道文件中一个管道类负责将item存储到某一个平台中
-: 配置文件中设定管道类的优先级
-:process_item方法中return item 的操作将item 传递给下一个即将被执行的管道类
全站数据爬取:
- 手动请求的发送
-: 设定一个通用的url模板
-: 手动请求的操作写在哪里: parse 方法:
-: yield scrapy.Request(url,callback)
POST请求
- strat_requests(self)
- post 请求手动的发送:yield scrapy.FormRequest(url,callback,formdata)
- cookies_Ennalle =False
日志等级和请求传参
- LOG_LEVEL ='ERROR'
- LOG_FILE ='path'
请求传参的应用场景:
-爬取且解析的数据没有在同一个页面上(如列表页,详情页)
-在请求方法中使用meta(字典)参数,该字典会传递给回调函数
-回调函数接收meta :response.meta['key']
步骤:
一: 创建项目
scrapy startproject xiaohua
二: 进入目录后创建爬虫
scrapy genspider xiaohuademo
三: 开始操作
1: 前提准备:
首先注释掉域名限制,防止不必要的错误:

2: 关闭setting里面的ROBOTSTXT_OBEY ,更改UA头

不遵守机器人协议
3: 书写spider 爬虫
4:代码:
爬虫部分代码
# -*- coding: utf- -*-
import scrapy
from xiaohua.items import XiaohuaItem class XiaohuaspiderSpider(scrapy.Spider):
name = 'xiaohuaspider'
# 注释掉域名方式下载发生问题
# allowed_domains = ['www.xxx.com']
# 写入起始url
start_urls = ['http://www.521609.com/daxuemeinv/'] def parse(self, response):
li_list = response.xpath('//div[@class="index_img list_center"]/ul/li')
for li in li_list:
# 解析获取数据
title = li.xpath('./a[2]/text()|./a[2]/b/text()').extract_first()
img_url = 'http://www.521609.com' + li.xpath('./a[1]/img/@src').extract_first()
#实例化一个item 管道对象
item =XiaohuaItem()
item['title']=title
item['img_url']=img_url
# 提交item 给管道
yield item
item 部分代码 (该部分用来定义接收数据名)----->需要在spider 中实例对象
# -*- coding: utf- -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class XiaohuaItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
img_url =scrapy.Field()
pipelines 代码
# -*- coding: utf- -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html # 利用管道,将数据通过管道解析到某一平台(数据库)
# 从写方法进行封装到本地内存
import pymysql
class XiaohuaPipeline(object):
fp = None # 从写open_spider 方法 def open_spider(self, spider):
print('开启爬虫')
self.fp = open('./xiaohua.txt', 'w', encoding='utf-8') # 作用:实现持久化存储的操作
# 从写open_spider可以降低 open的操作. 降低io 开启关闭减少内存
# 该方法接收item 的数据
# 只会被调用一次 def process_item(self, item, spider):
#获取解析内容
title = item['title']
img_url = item['img_url']
# 将的内容写入文件
self.fp.write(title+':'+img_url+'\n')
# 这里的return item 是方便其他管道内容调用
return item
def close_spider(self,spider):
print('爬虫结束')
self.fp.close() class MySqlPipeline(object):
conn =None # 创建连接数据库表示
cursor =None #创建事务标识回滚标识
def open_spider(self,spider):
self.conn =pymysql.Connect(host='127.0.0.1',port=,user='root',password='',db='xiaohua')
print(self.conn)
print('开始存入数据库')
def process_item(self,item,spider):
self.cursor=self.conn.cursor() # 创建回滚点
try:
self.cursor.execute('insert into demo1 value ("%s","%s")' %(item['title'],item['img_url']))
self.conn.commit() # 提交事务
except Exception as e:
print(e)
self.conn.rollback() # 如果出现异常回滚事务
return item
def close_spider(self,spider):
self.cursor.close() #关闭事务
self.conn.close() # 关闭连接
print('数据库入完成')
setting 代码:
# -*- coding: utf- -*- # Scrapy settings for xiaohua project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'xiaohua' SPIDER_MODULES = ['xiaohua.spiders']
NEWSPIDER_MODULE = 'xiaohua.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: )
#CONCURRENT_REQUESTS = # Configure a delay for requests for the same website (default: )
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY =
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN =
#CONCURRENT_REQUESTS_PER_IP = # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'xiaohua.middlewares.XiaohuaSpiderMiddleware': ,
#} # Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'xiaohua.middlewares.XiaohuaDownloaderMiddleware': ,
#} # Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
# 开启管道 ,开启管道才能进行数据存储
ITEM_PIPELINES = {
'xiaohua.pipelines.XiaohuaPipeline': ,
'xiaohua.pipelines.MySqlPipeline': ,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY =
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY =
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS =
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
5: 代码解析
scrapy 学习笔记2 数据持久化的更多相关文章
- ios学习笔记-数据持久化
沙盒 沙盒是一种数据安全策略,只允许自己的应用访问目录.可以使用NSHomeDirectory()获取. ios沙盒下有三个子目录: 1.Documents目录:用于存储比较大的文件活着需要频发女更新 ...
- Scrapy:学习笔记(2)——Scrapy项目
Scrapy:学习笔记(2)——Scrapy项目 1.创建项目 创建一个Scrapy项目,并将其命名为“demo” scrapy startproject demo cd demo 稍等片刻后,Scr ...
- Android:日常学习笔记(9)———探究持久化技术
Android:日常学习笔记(9)———探究持久化技术 引入持久化技术 什么是持久化技术 持久化技术就是指将那些内存中的瞬时数据保存到存储设备中,保证即使在手机或电脑关机的情况下,这些数据仍然不会丢失 ...
- Redis学习笔记六:持久化实验(AOF,RDB)
作者:Grey 原文地址:Redis学习笔记六:持久化实验(AOF,RDB) Redis几种持久化方案介绍和对比 AOF方式:https://blog.csdn.net/ctwctw/article/ ...
- Windows phone 8 学习笔记(2) 数据文件操作
原文:Windows phone 8 学习笔记(2) 数据文件操作 Windows phone 8 应用用于数据文件存储访问的位置仅仅限于安装文件夹.本地文件夹(独立存储空间).媒体库和SD卡四个地方 ...
- #学习笔记#JSP数据交互
#学习笔记#JSP数据交互 数据库的使用方式: 当用户在第一个页面的查询框输入查询语句点提交的时候我们是用什么样的方式完成这个查询的? 答:我们通过在第一个页面提交表单的形式,真正的数据库查询时在 ...
- ArcGIS案例学习笔记_3_2_CAD数据导入建库
ArcGIS案例学习笔记_3_2_CAD数据导入建库 计划时间:第3天下午 内容:CAD数据导入,建库和管理 目的:生成地块多边形,连接属性,管理 问题:CAD存在拓扑错误,标注位置偏移 教程:pdf ...
- GIS案例学习笔记-CAD数据分层导入现有模板实例教程
GIS案例学习笔记-CAD数据分层导入现有模板实例教程 联系方式:谢老师,135-4855-4328,xiexiaokui#qq.com 1. 原始数据: CAD数据 目标模板 2. 任务:分5个图层 ...
- ArcGIS案例学习笔记-CAD数据自动拓扑检查
ArcGIS案例学习笔记-CAD数据自动拓扑检查 联系方式:谢老师,135-4855-4328,xiexiaokui#qq.com 功能:针对CAD数据,自动进行拓扑检查 优点:类别:地理建模项目实例 ...
随机推荐
- BinaryTree(HDU-5573)【思维/构造】
题目链接:https://vjudge.net/problem/HDU-5573 题意:一棵二叉树,编号代表对应节点的取值,可以走k步,每次走的层数递增,问能够达到N的方案. 思路:首先看一下数据范围 ...
- JS 07 Dom
DOM(Document Object Model): 结点的概念:整个文档就是由层次不同的多个节点组成,可以说结点代表了全部内容. 结点类型 1.元素结点 2.属性结点 3.文本结点 结点的注意 ...
- IDEA中通过Maven插件使用MyBatis Generator
这样做更简单,参考: IDEA集成MyBatis Generator 插件 详解
- Interlocked
Interlocked MSDN 描述:为多个线程共享的变量提供原子操作.主要函数如下: Interlocked.Increment 原子操作,递增指定变量的值并存储结果.Interlocked.De ...
- (五)Maven中的聚合和继承
一.为什么要聚合? 定义:我们在开发过程中,创建了2个以上的模块,每个模块都是一个独立的maven project,在开始的时候我们可以独立的编译和测试运行每个模块,但是随着项目的不断变大和复杂化,我 ...
- (十)web服务与javaweb结合(1)
一.解决方法 A . 编写一个监听器,在监听器中发布服务 二.案例一 方法A:编写一个监听器,在监听器中发布服务 1. 编写服务接口 package com.shyroke.service; impo ...
- SOLID Principles
Intention: more understandable, easier to maintain and easier to extend.(通过良好的设计使得代码easy and simple, ...
- Reeds-Shepp曲线和Dubins曲线
转载:https://www.cnblogs.com/huyanan/articles/6243694.html 什么是Reeds-Shepp曲线? 想象你下班开车回家,到了小区后想把车停 ...
- 阿里高级架构师教你使用Spring Cloud Sleuth跟踪微服务
随着微服务数量不断增长,需要跟踪一个请求从一个微服务到下一个微服务的传播过程,Spring Cloud Sleuth 正是解决这个问题,它在日志中引入唯一ID,以保证微服务调用之间的一致性,这样你就能 ...
- Ubuntu18.0 解决python虚拟环境中不同用户下或者python多版本环境中指定虚拟环境的使用问题
一. 不同用户下配置virtualenvwrapper的问题 问题描述: 安装virtualnev和virtualnevwrapper之后,在.bashrc进行virtualenvwrapper的相关 ...