python自动华 (五)
Python自动化 【第五篇】:Python基础-常用模块
目录
- 模块介绍
- time和datetime模块
- random
- os
- sys
- shutil
- json和pickle
- shelve
- xml处理
- yaml处理
- configparser
- hashlib
- re正则表达式
1. 模块介绍
1.1 定义
能够实现某个功能的代码集合(本质是py文件) test.p的模块名是test包的定义:用来从逻辑上组织模块,本质就是一个目录(必须带有一个__init__.py文件)
1.2 导入方法
a) Import module
b) Import module1,module2
c) From module import *
d) From module import m1,m2,m3
e) From module import logger as module_logger
1.3 Import 本质
导入模块的本质就是把python文件解释一遍
导入包的本质就是在执行该包下的__init__.py文件
1.4 导入优化
From module import test as module_test
1.5 模块的分类
a) 标准库
b) 开源模块(第三方模块)
c) 自定义模块
2. time & datetime 模块
time的三种表现方式:
1)时间戳(用秒来表示)
2)格式化的时间字符串
3)元组(struct_time)共九个元素。
2.1 时间戳
1 1 import time
2
3 2 # print(time.clock()) #返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括sleep时间,不稳定,mac上测不出来
4
5 3 # print(time.altzone) #返回与utc时间的时间差,以秒计算\
6
7 4 # print(time.asctime()) #返回时间格式"Fri Aug 19 11:14:16 2016",
8
9 5 # print(time.localtime()) #返回本地时间 的struct time对象格式
10
11 6 # print(time.gmtime(time.time()-800000)) #返回utc时间的struc时间对象格式
12
13 7
14
15 8 # print(time.asctime(time.localtime())) #返回时间格式"Fri Aug 19 11:14:16 2016",
16
17 9 #print(time.ctime()) #返回Fri Aug 19 12:38:29 2016 格式, 同上
18
19 10
20
21 11 # 日期字符串 转成 时间戳
22
23 12 # string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式
24
25 13 # print(string_2_struct)
26
27 14 # struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳
28
29 15 # print(struct_2_stamp)
30
31 16 #将时间戳转为字符串格式
32
33 17 # print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式
34
35 18 # print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式
36
37 19 #时间加减
38
39 20 import datetime
40
41 21 # print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925
42
43 22 #print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19
44
45 23 # print(datetime.datetime.now() )
46
47 24 # print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
48
49 25 # print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
50
51 26 # print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
52
53 27 # print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
54
55 28 # c_time = datetime.datetime.now()
56
57 29 # print(c_time.replace(minute=3,hour=2)) #时间替换
2.2 格式化的时间字符串
格式参照:
%a 本地(locale)简化星期名称
%A 本地完整星期名称
%b 本地简化月份名称
%B 本地完整月份名称
%c 本地相应的日期和时间表示
%d 一个月中的第几天(01 - 31)
%H 一天中的第几个小时(24小时制,00 - 23)
%I 第几个小时(12小时制,01 - 12)
%j 一年中的第几天(001 - 366)
%m 月份(01 - 12)
%M 分钟数(00 - 59)
%p 本地am或者pm的相应符 一
%S 秒(01 - 61) 二
%U 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 三
%w 一个星期中的第几天(0 - 6,0是星期天) 三
%W 和%U基本相同,不同的是%W以星期一为一个星期的开始。
%x 本地相应日期
%X 本地相应时间
%y 去掉世纪的年份(00 - 99)
%Y 完整的年份
%Z 时区的名字(如果不存在为空字符)
%% ‘%’字符
2.3 时间关系转换
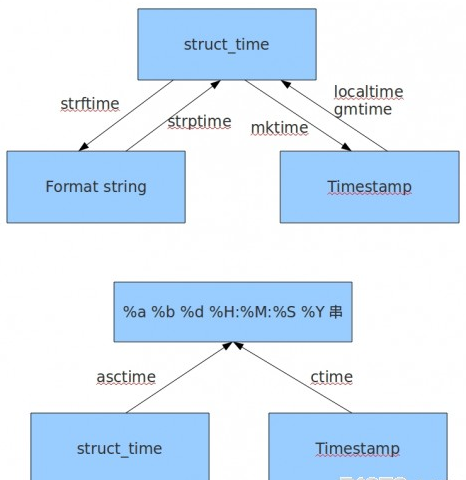
3. random模块
3.1 随机数
import random
print (random.random()) #0.6445010863311293
#random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0
print (random.randint(1,7)) #4
#random.randint()的函数原型为:random.randint(a, b),用于生成一个指定范围内的整数。
# 其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b
print (random.randrange(1,10)) #5
#random.randrange的函数原型为:random.randrange([start], stop[, step]),
# 从指定范围内,按指定基数递增的集合中 获取一个随机数。如:random.randrange(10, 100, 2),
# 结果相当于从[10, 12, 14, 16, ... 96, 98]序列中获取一个随机数。
# random.randrange(10, 100, 2)在结果上与 random.choice(range(10, 100, 2) 等效。
print(random.choice('liukuni')) #i
#random.choice从序列中获取一个随机元素。
# 其函数原型为:random.choice(sequence)。参数sequence表示一个有序类型。
# 这里要说明一下:sequence在python不是一种特定的类型,而是泛指一系列的类型。
# list, tuple, 字符串都属于sequence。有关sequence可以查看python手册数据模型这一章。
# 下面是使用choice的一些例子:
print(random.choice("学习Python"))#学
print(random.choice(["JGood","is","a","handsome","boy"])) #List
print(random.choice(("Tuple","List","Dict"))) #List
print(random.sample([1,2,3,4,5],3)) #[1, 2, 5]
#random.sample的函数原型为:random.sample(sequence, k),从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列。
3.2 实际应用
#!/usr/bin/env python
# encoding: utf-8
import random
import string
# 随机整数:
print(random.randint(0, 99)) # 70
# 随机选取0到100间的偶数:
print(random.randrange(0, 101, 2)) # 4
# 随机浮点数:
print(random.random()) # 0.2746445568079129
print(random.uniform(1, 10)) # 9.887001463194844
# 随机字符:
print(random.choice('abcdefg&#%^*f')) # f
# 多个字符中选取特定数量的字符:
print(random.sample('abcdefghij', 3)) # ['f', 'h', 'd']
# 随机选取字符串:
print(random.choice(['apple', 'pear', 'peach', 'orange', 'lemon'])) # apple
# 洗牌#
items = [1, 2, 3, 4, 5, 6, 7]
print(items) # [1, 2, 3, 4, 5, 6, 7]
random.shuffle(items)
print(items) # [1, 4, 7, 2, 5, 3, 6]
3.3 生成随机验证码
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print checkcode
4. os模块
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
5. sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
6. shutil模块
import shutil
f1 = open("file.txt", encoding="utf-8")
f2 = open("file2.txt", "w",encoding="utf-8")
shutil.copyfileobj(f1,f2)
shutil.copyfile() 输入源文件就copy:
shutil.copyfile("file1", "file2")
shutil.copymode() 仅拷贝权限,内容、组、用户均不变(待实验)
shutil.copystat() 拷贝权限,没有创建新文件
shutil.copy() 拷贝文件
shutil.copy2() 所有都拷贝(文件和状态信息)
shutil.copytree() 递归拷贝文件(将文件和所在目录都拷贝)
shutil.copytree("test1", "test2")
shutil.rmtree() 递归删除文件 比调用shell命令高效
shutil.rmtree("test3")
shutil.move() 递归的移动文件
shutil.make_archive(base_name, format, file)
import shutil
shutil.make_archive("shutil_archive_test", "zip", "E:\Pycharm\day5")
zipfile
import zipfile
z = zipfile.ZipFile("file1.zip", "w") # 指定压缩后的文件名是file1.txt
z.write("test1.py") # 先把test1.py压缩至file1.zip
print("----------") # 可以干些其他事
z.write("test2.py") # 然后把test2.py压缩至file1.zip
z.close()
7. json和pickle模块
解决了不同语言不同平台的之间的数据交换
参考:http://www.cnblogs.com/ZhPythonAuto/p/5786091.html
8. shelve模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式。
import shelve
import datetime
d = shelve.open('shelve_test') # 打开一个文件 # info = {"age":22,"job":"it"}
#
# name = ["alex", "rain", "test"]
# d["name"] = name # 持久化列表
# d["info"] = info # 持久化类
# d["date"] =datetime.datetime.now()
# d.close()
print(d.get("name"))
print(d.get("info"))
print(d.get("date"))
9. xml处理模块
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
xml协议在各个语言里的都是支持的,在python中可以用以下模块操作xml
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
# 遍历xml文档
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag, i.text, i.attrib)
# 只遍历year 节点
for node in root.iter('year'):
print(node.tag, node.text)
修改和删除xml文档内import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
# 修改
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated", "yes")
tree.write("xmltest.xml")
# 删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
自己创建xml文档
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml, "name", attrib={"enrolled": "yes"})
age = ET.SubElement(name, "age", attrib={"checked": "no"})
sex = ET.SubElement(name, "sex")
age.text = '33'
name2 = ET.SubElement(new_xml, "name", attrib={"enrolled": "no"})
age = ET.SubElement(name2, "age")
age.text = '19'
et = ET.ElementTree(new_xml) # 生成文档对象
et.write("test.xml", encoding="utf-8", xml_declaration=True)
ET.dump(new_xml) # 打印生成的格式
10. PyYAML模块
yaml语法(用作配置文件)
数据结构可以用类似大纲的缩排方式呈现,结构通过缩进来表示,连续的项目通过减号“-”来表示,map结构里面的key/value对用冒号“:”来分隔。样例如下:
house:
family:
name: Doe
parents:
- John
- Jane
children:
- Paul
- Mark
- Simone
address:
number: 34
street: Main Street
city: Nowheretown
zipcode: 12345
11. ComfigParser模块
用于生成和修改常见配置文档,当前模块的名称在 python 3.x 版本中变更为 configparser。
格式如下:
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
用python生成一个这样的文档
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9'}
config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022' # mutates the parser
topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'
with open('example.ini', 'w') as configfile:
config.write(configfile)
写完后还可以读出来:
>>> import configparser
>>> config = configparser.ConfigParser()
>>> config.sections()
[]
>>> config.read('example.ini')
['example.ini']
>>> config.sections()
['bitbucket.org', 'topsecret.server.com']
>>> 'bitbucket.org' in config
True
>>> 'bytebong.com' in config
False
>>> config['bitbucket.org']['User']
'hg'
>>> config['DEFAULT']['Compression']
'yes'
>>> topsecret = config['topsecret.server.com']
>>> topsecret['ForwardX11']
'no'
>>> topsecret['Port']
'50022'
>>> for key in config['bitbucket.org']: print(key)
...
user
compressionlevel
serveraliveinterval
compression
forwardx11
>>> config['bitbucket.org']['ForwardX11']
'yes'
configparser增删改查语法
[section1]
k1 = v1
k2:v2 [section2]
k1 = v1 import ConfigParser config = ConfigParser.ConfigParser()
config.read('i.cfg') # ########## 读 ##########
# secs = config.sections()
# print secs
# options = config.options('group2')
# print options # item_list = config.items('group2')
# print item_list # val = config.get('group1','key')
# val = config.getint('group1','key') # ########## 改写 ##########
# sec = config.remove_section('group1')
# config.write(open('i.cfg', "w")) # sec = config.has_section('wupeiqi')
# sec = config.add_section('wupeiqi')
# config.write(open('i.cfg', "w")) # config.set('group2','k1',11111)
# config.write(open('i.cfg', "w")) # config.remove_option('group2','age')
# config.write(open('i.cfg', "w"))
12. hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib
m = hashlib.md5()
m.update(b"Hello")
m.update(b"It's me")
print(m.digest())
m.update(b"It's been a long time since last time we ...")
print(m.digest()) # 2进制格式hash
print(len(m.hexdigest())) # 16进制格式hash
'''
def digest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of binary data. """
pass
def hexdigest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of hexadecimal digits. """
pass
'''
import hashlib
# ######## md5 ########
hash = hashlib.md5()
hash.update('admin')
print(hash.hexdigest())
# ######## sha1 ########
hash = hashlib.sha1()
hash.update('admin')
print(hash.hexdigest())
# ######## sha256 ########
hash = hashlib.sha256()
hash.update('admin')
print(hash.hexdigest())
# ######## sha384 ########
hash = hashlib.sha384()
hash.update('admin')
print(hash.hexdigest())
# ######## sha512 ########
hash = hashlib.sha512()
hash.update('admin')
print(hash.hexdigest())
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
import hmac
h = hmac.new('wueiqi')
h.update('hellowo')
print h.hexdigest()
13. re模块
常用正则表达式符号:
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
'\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符,\t、\n、\r , re.search("\s+","ab\tc1\n3").group(),结果 '\t'
'(?P<name>...)' 分组匹配,re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city"),结果{'province': '3714', 'city': '81', 'birthday': '1993'}
最常用的匹配语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
几个匹配模式
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为
S(DOTALL): 点任意匹配模式,改变'.'的行为
python自动华 (五)的更多相关文章
- python自动华 (十五)
Python自动化 [第十五篇]:CSS.JavaScript 和 Dom介绍 本节内容 CSS javascript dom CSS position标签 fixed: 固定在页面的某个位置 rel ...
- python自动华 (二)
Python自动化 [第二篇]:Python基础-列表.元组.字典 本节内容 模块初识 .pyc简介 数据类型初识 数据运算 列表.元组操作 字符串操作 字典操作 集合操作 字符编码与转码 一.模块初 ...
- python自动华 (十八)
Python自动化 [第十八篇]:JavaScript 正则表达式及Django初识 本节内容 JavaScript 正则表达式 Django初识 正则表达式 1.定义正则表达式 /.../ 用于定 ...
- python自动华 (十七)
Python自动化 [第十七篇]:jQuery介绍 jQuery jQuery是一个兼容多浏览器的javascript库,核心理念是write less,do more(写得更少,做得更多),对jav ...
- python自动华 (十六)
Python自动化 [第十六篇]:JavaScript作用域和Dom收尾 本节内容: javascript作用域 DOM收尾 JavaScript作用域 JavaScript的作用域一直以来是前端开发 ...
- python自动华 (十二)
Python自动化 [第十二篇]:Python进阶-MySQL和ORM 本节内容 数据库介绍 mysql 数据库安装使用 mysql管理 mysql 数据类型 常用mysql命令 创建数据库 外键 增 ...
- python自动华 (十)
Python自动化 [第十篇]:Python进阶-多进程/协程/事件驱动与Select\Poll\Epoll异步IO 本节内容: 多进程 协程 事件驱动与Select\Poll\Epoll异步IO ...
- python自动华 (八)
Python自动化 [第八篇]:Python基础-Socket编程进阶 本节内容: Socket语法及相关 SocketServer实现多并发 1. Socket语法及相关 sk = socket.s ...
- python自动华 (七)
Python自动化 [第七篇]:Python基础-面向对象高级语法.异常处理.Scoket开发基础 本节内容: 1. 面向对象高级语法部分 1.1 静态方法.类方法.属性方法 1.2 ...
随机推荐
- python并发编程之多线程(实践篇)
一.threading模块介绍 官网链接:https://docs.python.org/3/library/threading.html?highlight=threading# 1.开启线程的两种 ...
- 1269: 划分数(Java)
WUSTOJ 1269: 划分数 参考博客 果7的博客 题目 将 1 个数 n 分成 m 份,求划分的种数.更多内容点击标题. 分析 唯一需要注意的地方是不考虑顺序.其他的直接看代码即可. 代 ...
- Django中的Object Relational Mapping(ORM)
ORM 介绍 ORM 概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM是通过使用 ...
- JS 07 Dom
DOM(Document Object Model): 结点的概念:整个文档就是由层次不同的多个节点组成,可以说结点代表了全部内容. 结点类型 1.元素结点 2.属性结点 3.文本结点 结点的注意 ...
- java之理解面向对象
1.程序设计的三种基本结构 顺序结构 顺序结构表示程序中的各操作是按照它们在源代码中的排列顺序依次执行的 选择结构 选择结构表示程序的处理需要根据某个特定的条件选择其中的一个分支执行.选择结构有单选择 ...
- CMake入门-04-自定义编译选项
工作环境 系统:macOS Mojave 10.14.6 CMake: Version 3.15.0-rc4 Hello,World! - 自定义编译选项 CMake 允许为项目增加编译选项,从而可以 ...
- ...:ES6中扩展运算符(spread)和剩余运算符(rest)详解
1.扩展运算符(spread) demo1:传递数据代替多个字符串的形式 let test= function(a,b,c){ console.log(a); console.log(b); cons ...
- (二)Spring框架之JDBC的基本使用(p6spy插件的使用)
案例一: 用Spring IOC方式使用JDBC Test_2.java package jdbc; import java.lang.Thread.State; import java.sql.Co ...
- 解析Illumina+PacBio组装策略
解析Illumina+PacBio组装策略 (2016-12-08 13:21:58) 转载▼ 基于Illumina和PacBio平台的“二加三”组装策略,巧妙的融合了PacBio平台超长读长 ...
- ASP.NET WEB应用程序(.network4.5)MVC 工作原理
MVC就是模型.视图.控制器. 项目中控制器对应Controllers目录,视图对应Views目录,模型对应Models目录. 1.当我们创建一个控制器时,比如在Controllers目录新建一个名字 ...