SQL基础练习03---牛客网
目录
1 创建一个actor表
2 批量插入数据
3 批量插入数据不用replace
4 创建一个actor_name表
5 对first_name创建唯一索引
6 针对actor表创建视图actor_name_view
7 针对salaries表emp_no字段创建索引并查询
8 在last_update后面新增加一列
9 删除emp_no重复的记录,只保留最小的id对应的记录
10 将日期更新为null
11 修改id=5以及emp_no=10001的行数据
12 将titles_test表名修改为titles_2017
13 在audit表上创建外键约束
14 获取emp_v和employees有相同的数据
15 获取Employees中的first_name
16 按照dept_no进行汇总
17 分页查询employees表,每5行一页,返回第2页的数据
18 使用关键字exists查找未分配具体部门的员工信息
1 创建一个actor表
题目描述:创建一个actor表,包含如下列信息

牛客网的数据库和使用的mysql数据库格式上有差别,这里以mysql数据为准,用这个代码提交会报错的
CREATE TABLE IF NOT EXISTS actor (
actor_id SMALLINT(5) NOT NULL PRIMARY KEY,
first_name VARCHAR(45) NOT NULL,
last_name VARCHAR(45) NOT NULL,
last_update TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP)
2 批量插入数据
题目描述:对于表actor批量插入如下数据
INSERT INTO actor
VALUES (1, 'PENELOPE', 'GUINESS', '2006-02-15 12:34:33'),
(2, 'NICK', 'WAHLBERG', '2006-02-15 12:34:33')
3 批量插入数据不用replace
题目描述:对于表actor批量插入如下数据,如果数据已经存在,请忽略,不使用replace操作

同样由于数据库的差异,下面这段代码在mysql上运行可以成功,但提交就会报错这里仍以mysql为准。
INSERT IGNORE INTO actor
VALUES(3,'ED','CHASE','2006-02-15 12:34:33');
4 创建一个actor_name表
题目描述:对于如下表actor,其对应的数据为:
创建一个actor_name表,将actor表中的所有first_name以及last_name导入改表。actor_name表结构如下:
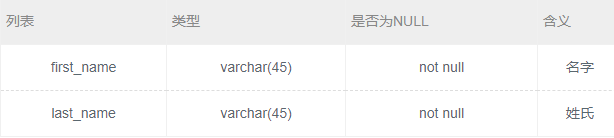
对于该题最直接的实现就是创建表,然后插入数据
CREATE TABLE actor_name(
first_name VARCHAR(45) NOT NULL,
last_name VARCHAR(45) NOT NULL); INSERT INTO actor_name SELECT first_name, last_name FROM actor;
对于上面的代码可以利用mysql的特性进行优化,只需要一句即可完成。这里的as可以去掉也可以不用去掉,不过在提交的数据库中as是不可以去掉的
CREATE TABLE actor_name AS
SELECT first_name,last_name FROM actor;
5 对first_name创建唯一索引
题目描述:针对如下表actor结构创建索引:对first_name创建唯一索引uniq_idx_firstname,对last_name创建普通索引idx_lastname
CREATE UNIQUE INDEX uniq_idx_firstname ON actor(first_name);
CREATE INDEX idx_lastname ON actor(last_name);
6 针对actor表创建视图actor_name_view
题目描述:针对actor表创建视图actor_name_view,只包含first_name以及last_name两列,并对这两列重新命名,first_name为first_name_v,last_name修改为last_name_v:
这段代码虽然没有通过是因为编译器的问题,应该是可以正常使用的
CREATE VIEW actor_name_view AS
SELECT first_name AS fist_name_v, last_name AS last_name_v
FROM actor
另外一种方式如下:不过总是没有通过但在mysql中是可以正常运行的。
CREATE VIEW actor_name_view (fist_name_v, last_name_v) AS
SELECT first_name, last_name FROM actor
7 针对salaries表emp_no字段创建索引并查询
题目描述:针对salaries表emp_no字段创建索引idx_emp_no,查询emp_no为10005, 使用强制索引。
创建索引:
CREATE INDEX idx_emp_no ON salaries(emp_no);
根据索引查询:同样由于数据库的原因在mysql中可以使用但在测试的数据库中是错误的
SELECT * FROM salaries FORCE INDEX (idx_emp_no) WHERE emp_no = 10005
8 在last_update后面新增加一列
题目描述:存在actor表,现在在last_update后面新增加一列名字为create_date, 类型为datetime, NOT NULL,默认值为‘0000-00-00 00:00:00’
ALTER TABLE actor
ADD `create_date` DATETIME NOT NULL DEFAULT '0000-00-00 00:00:00'
9 删除emp_no重复的记录,只保留最小的id对应的记录
题目描述:删除emp_no重复的记录,只保留最小的id对应的记录。
因为需要删除,所以题目中专门给了一个测试表
CREATE TABLE IF NOT EXISTS titles_test (
id INT(11) NOT NULL PRIMARY KEY,
emp_no INT(11) NOT NULL,
title VARCHAR(50) NOT NULL,
from_date DATE NOT NULL,
to_date DATE DEFAULT NULL); INSERT INTO titles_test VALUES ('', '', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('', '', 'Staff', '1996-08-03', '9999-01-01'),
('', '', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('', '', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('', '', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('', '', 'Staff', '1996-08-03', '9999-01-01'),
('', '', 'Senior Engineer', '1995-12-03', '9999-01-01');
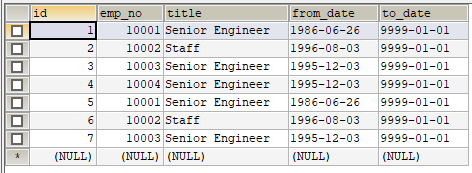
最直接的思路如下:
DELETE FROM titles_test WHERE id NOT IN
(SELECT MIN(id) AS id FROM titles_test GROUP BY emp_no)
但这样会报错:You can't specify target table 'titles_test' for update in FROM clause。百度发现解释如下:不能先select出同一表中的某些值,再update这个表(在同一语句中),即不能依据某字段值做判断再来更新某字段的值。既然不能直接进行操作,那么则需要创建一个中间表来进行操作。
DELETE FROM titles_test WHERE id NOT IN
(SELECT a.id FROM
(SELECT MIN(id) AS id FROM titles_test GROUP BY emp_no) AS a)
注意:后面题目的修改均是在test数据表中进行的
10 将日期更新为null
题目描述:将所有to_date为9999-01-01的全部更新为NULL,且 from_date更新为2001-01-01。
在更新时注意不要使用and使用逗号连接要更新的多个列的,最后一个更新的列没有逗号
UPDATE titles_test SET to_date = NULL, from_date = '2001-01-01'
WHERE to_date = '9999-01-01';
11 修改id=5以及emp_no=10001的行数据
题目描述:将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005,其他数据保持不变,使用replace实现。这个修改是在titles_test中实现的。
本题主要考察replace的使用:全字段更新替换。由于 REPLACE 的新记录中 id=5,与表中的主键 id=5 冲突,故会替换掉表中 id=5 的记录,否则会插入一条新记录(例如新插入的记录 id = 10)。并且要将所有字段的值写出,否则将置为空。
REPLACE INTO titles_test VALUES (5, 10005, 'Senior Engineer', '1986-06-26', '9999-01-01')
也可以直接从数据库读取出来,主键和要修改的保留:
REPLACE INTO titles_test
SELECT 5, 10005, title, from_date, to_date
FROM titles_test
WHERE id = 5;
12 将titles_test表名修改为titles_2017
题目描述:将titles_test表名修改为titles_2017。
在mysql中加不加to都可以的,而在oj系统中必须要加to
ALTER TABLE titles_test RENAME TO titles_2017
13 在audit表上创建外键约束
题目描述:在audit表上创建外键约束,其emp_no对应employees_test表的主键id
题目中用到的测试表:
CREATE TABLE employees_test(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
); CREATE TABLE audit(
EMP_no INT NOT NULL,
create_date DATETIME NOT NULL
);

在mysql中可以直接使用:
alter table audit
add foreign key(emp_no) references employees_test(id)
因为题目OJ系统的原因只能先删除表然后在创建表的过程中添加外键。
DROP TABLE audit;
CREATE TABLE audit(
EMP_no INT NOT NULL,
create_date datetime NOT NULL,
FOREIGN KEY(EMP_no) REFERENCES employees_test(ID));
14 获取emp_v和employees有相同的数据
题目描述:存在如下的视图:create view emp_v as select * from employees where emp_no >10005;
如何获取emp_v和employees有相同的数据?
输出描述:

一开始直接采用如下代码:
SELECT *
FROM employees AS e,emp_v AS ev
WHERE e.emp_no = ev.emp_no
结果不通过,看了讨论才发现直接用*号相当于对两张表都进行了查询,返回的是两张相同的记录,但只是要求一张记录因此要加一些限定:
SELECT e.*
FROM employees AS e,emp_v AS ev
WHERE e.emp_no = ev.emp_no
不过充分利用视图的定义话,emp_v表是从employees表中导出来的,那么可以直接输出就好了。
SELECT * FROM emp_v
15 获取Employees中的first_name
题目描述:获取Employees中的first_name,查询按照first_name最后两个字母,按照升序进行排列。
本题主要使用MySQL中的函数:substr(string,start,length)
string - 指定的要截取的字符串。start - 必需,规定在字符串的何处开始。正数 - 在字符串的指定位置开始,负数 - 在从字符串结尾的指定位置开始,0 - 在字符串中的第一个字符处开始。
length - 可选,指定要截取的字符串长度,缺省时返回字符表达式的值结束前的全部字符。根据上面的描述MySQL代码如下:
SELECT first_name FROM employees
ORDER BY SUBSTR(first_name,LENGTH(first_name)-1,2)
16 按照dept_no进行汇总
题目描述:按照dept_no进行汇总,属于同一个部门的emp_no按照逗号进行连接,结果给出dept_no以及连接出的结果employees
结果输出:
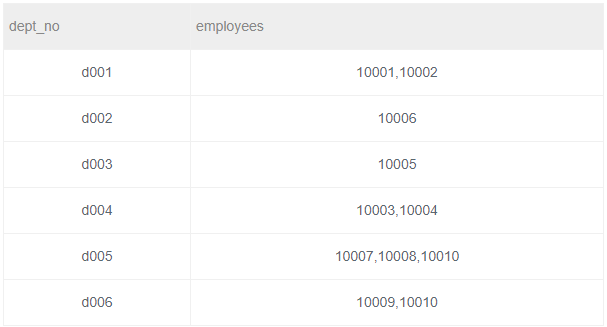
本题用到聚合函数:group_concat(X,Y),其中X是要连接的字段,Y是连接时用的符号,可省略,默认为逗号。此函数必须与 GROUP BY 配合使用。代码如下:
SELECT dept_no, GROUP_CONCAT(emp_no) AS employees
FROM dept_emp GROUP BY dept_no
17 分页查询employees表,每5行一页,返回第2页的数据
题目描述:分页查询employees表,每5行一页,返回第2页的数据
本题虽然是分页但还是对limit的使用:在 LIMIT X,Y 中,Y代表返回几条记录,X代表从第几条记录开始返回(第一条记录序号为0)。
SELECT * FROM employees LIMIT 5,5
18 使用关键字exists查找未分配具体部门的员工信息
题目描述:使用含有关键字exists查找未分配具体部门的员工的所有信息。
输出描述:

本题主要是关键字exists的使用:
SELECT * FROM employees WHERE NOT EXISTS
(SELECT * FROM dept_emp WHERE emp_no = employees.emp_no)
注意exists前是不用添加字段的,下面这样就是错误的:
SELECT * FROM employees WHERE emp_no NOT EXISTS
(SELECT * FROM dept_emp WHERE emp_no = employees.emp_no)
0
SQL基础练习03---牛客网的更多相关文章
- MySql面试题、知识汇总、牛客网SQL专题练习
点击名字直接跳转到链接: Linux运维必会的100道MySql面试题之(一) Linux运维必会的100道MySql面试题之(二) Linux运维必会的100道MySql面试题之(三) Linux运 ...
- 牛客网Sql
牛客网Sql: 1.查询最晚入职的员工信息 select * from employees where hire_date =(select max(hire_date) from employee ...
- 牛客网数据库SQL实战解析(51-61题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(41-50题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(31-40题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(21-30题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(11-20题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(1-10题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- Two Graphs 牛客网暑期ACM多校训练营(第一场)D 图论基础知识 全排列
链接:https://www.nowcoder.com/acm/contest/139/D来源:牛客网 Two undirected simple graphs and where are isomo ...
- 牛客网《BAT面试算法精品课》学习笔记
目录 牛客网<BAT面试算法精品课>学习笔记 牛客网<BAT面试算法精品课>笔记一:排序 牛客网<BAT面试算法精品课>笔记二:字符串 牛客网<BAT面试算法 ...
随机推荐
- Hadoop环境搭建过程中遇到的问题以及解决方法
1.启动hadoop之前,ssh免密登录slave主机正常,使用命令start-all.sh启动hadoop时,需要输入slave主机的密码,说明ssh文件权限有问题,需要执行以下操作: 1)进入.s ...
- java网络编程-面试题
1.网络编程时的同步.异步.阻塞.非阻塞? 同步:函数调用在没得到结果之前,没有调用结果,不返回任何结果.异步:函数调用在没得到结果之前,没有调用结果,返回状态信息.阻塞:函数调用在没得到结果之前,当 ...
- 二叉查找树 & B(B-)树 & B+树 & B*树
一 二叉查找树 1 特点 (1)所有非叶子结点至多拥有两个子节点, left和right (2)一个结点存储一个关键字 (3)非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树 2 ...
- mysql8.0.13下载与安装图文教程
一.进入mysql网站:https://dev.mysql.com/downloads/mysql/ 二.进入Community选择MySQL Communtiy Server 三.将页面拉到最下面选 ...
- thinkphp5.1中使用Bootstrap4分页样式修改
1.找到thinkphp下的Boorstrap的源码 \thinkphp\library\think\paginator\driver\Bootstrap.php 2丶直接修改源码 <?php ...
- 微信小程序 路由跳转 异步请求 存储数据,微信登录接口
1小程序路由跳转 wx.switchTab(Object object) 这里的tabBar是底下的导航栏指定的页面 跳转到 tabBar 页面,并关闭其他所有非 tabBar 页面 tabBar l ...
- StorageClass-动态PVC
StorageClass 之前我们部署了PV 和 PVC 的使用方法,但是前面的 PV 都是静态的,什么意思?就是我要使用的一个 PVC 的话就必须手动去创建一个 PV,我们也说过这种方式在很大程度上 ...
- Css解决表格超出部分用省略号显示
小伙伴们有没有的遇到页面显示时,因为数据太长导致显示的表格某一列过长,从而导致页面的不美观,下面我们来看一看如何用Css样式解决表格超出部分用省略号显示的问题. 主要设置两个样式: table{ ta ...
- NopCommerce的autofac的理解
nop项目4.1是core.2.1开发的,Startup.cs文件开始 从入口进去ServiceCollectionExtensions这个文件 this IServiceCollection ser ...
- 08 redis缓存穿透、缓存雪崩、缓存击穿
Redis缓存的使用,极大的提升了应用程序的性能和效率,特别是数据查询方面.但同时,它也带来了一些问题.其中,最要害的问题,就是数据的一致性问题,从严格意义上讲,这个问题无解.如果对数据的一致性要求很 ...