[NLP-CNN] Convolutional Neural Networks for Sentence Classification -2014-EMNLP
1. Overview
本文将CNN用于句子分类任务
(1) 使用静态vector + CNN即可取得很好的效果;=> 这表明预训练的vector是universal的特征提取器,可以被用于多种分类任务中。
(2) 根据特定任务进行fine-tuning 的vector + CNN 取得了更好的效果。
(3) 改进模型架构,使得可以使用 task-specific 和 static 的vector。
(4) 在7项任务中的4项取得了SOTA的效果。
思考:卷积神经网络的核心思想是捕获局部特征。在图像领域,由于图像本身具有局部相关性,因此,CNN是一个较为适用的特征提取器。在NLP中,可以将一段文本n-gram看做一个有相近特征的片段——窗口,因而希望通过CNN来捕获这个滑动窗口内的局部特征。卷积神经网络的优势在于可以对这样的n-gram特征进行组合和筛选,获取不同的抽象层次的语义信息。
2. Model
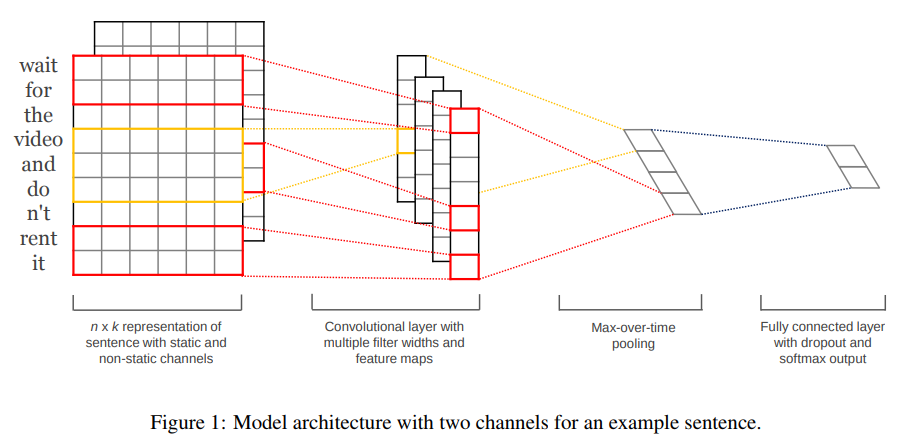
对于该模型,主要注意三点:
1. 如何应用的CNN,即在文本中如何使用CNN
2. 如何将static和fine-tuned vector结合在一个架构中
3. 正则化的策略
本文的思路是比较简单的。
2.1 CNN的应用
<1> feature map 的获取
word vector 是k维,sentence length = n (padded),则将该sentence表示为每个单词的简单的concat,如fig1所示,组成最左边的矩形。
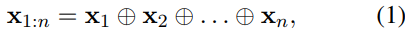
卷积核是对窗口大小为h的词进行卷积。大小为h的窗口内单词的表征为 h * k 维度,那么设定一个维度同样为h*k的卷积核 w,对其进行卷积运算。
之后加偏置,进行非线性变换即可得到经过CNN之后提取的特征的表征$c_i$。
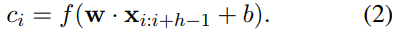
这个$c_i$是某一个卷积核对一个窗口的卷积后的特征表示,对于长度为n的sentence,滑动窗口可以滑动n - h + 1次,也就可以得到一个feature map
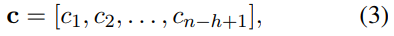
显然,$c$的维度为n - h + 1. 当然,这是对一个卷积核获取的feature map, 为了提取到多种特征,可以设置不同的卷积核,它们对应的卷积核的大小可以不同,也就是h可以不同。
这个过程对应了Figure1中最左边两个图形的过程。
<2> max pooling
这里的max pooling有个名词叫 max-over-time-pooling.它的over-time体现在:如图,每个feature map中选择值最大的组成到max pooling后的矩阵中,而这个feature map则是沿着滑动窗口,也就是沿着文本序列进行卷积得到的,那么也就是max pooling得到的是分别在每一个卷积核卷积下的,某一个滑动窗口--句子的某一个子序列卷积后的值,这个值相比于其他滑动窗口的更大。句子序列是有先后顺序的,滑动窗口也是,所以是 over-time.
这里记为: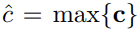 ,是对应该filter的最大值。
,是对应该filter的最大值。
<3> 全连接层
这里也是采用全连接层,将前面层提取的信息,映射到分类类别中,获取其概率分布。
2.2 static 和 fine-tuned vector的结合
paper中,将句子分别用 static 和fine-tuned vector 表征为两个channel。如Figure1最左边的图形所示,有两个矩阵,这两个矩阵分别表示用static 和fine-tuned vector拼接组成的句子的表征。比如,前面的矩阵的第一行 是wait这个词的static的vector;后面的矩阵的第一行 是wait这个词的fine-tuned的vector.
二者信息如何结合呢?
paper中的策略也很简单,用同样的卷积核对其进行特征提取后,将两个channel获得的值直接Add在一起,放到feature map中,这样Figure1中的feature map实际上是两种vector进行特征提取后信息的综合。
2.3 正则化的策略
为了避免co-adapation问题,Hinton提出了dropout。在本paper中,对于倒数第二层,也就是max pooling后获取的部分,也使用这样的正则化策略。
假设有m个feature map, 那么记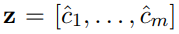 。
。
如果不使用dropout,其经过线性映射的表示为:

那么如果使用dropout,其经过线性映射的表示为:
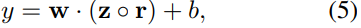
这里的$r$是m维的mask向量,其值或为0,或为1,其值为1的概率服从伯努利分布。
那么在进行反向传播时,只有对应mask为1的单元,其梯度才会传播更新。
在测试阶段,权值矩阵w会被scale p倍,即$\hat{w} = pw$,并且$\hat{w}$不进行dropout,来对训练阶段为遇到过的数据进行score.
另外可以选择对$w$进行$l_2$正则化,当在梯度下降后,$||w||_2 > s$ 时,将其值限制为s.
3. Datasets and Experimental Setup
3.1 Datasets:
1. MR: Movie reviews with one sentence per review. positive/negative reviews
2. SST-1: Stanford Sentiment Treebank—an extension of MR but with train/dev/test splits provided and fine-grained labels (very positive, positive, neutral, negative, very negative), re-labeled by Socher et al. (2013).4
3. SST-2: Same as SST-1 but with neutral reviews removed and binary labels.
4. Subj: Subjectivity dataset where the task is to classify a sentence as being subjective or objective (Pang and Lee, 2004)
5. TREC: TREC question dataset—task involves classifying a question into 6 question types (whether the question is about person, location, numeric information, etc.) (Li and Roth, 2002)
6. CR: Customer reviews of various products (cameras, MP3s etc.). Task is to predict positive/negative reviews (Hu and Liu, 2004)
7. MPQA: Opinion polarity detection subtask of the MPQA dataset (Wiebe et al., 2005).
3.2 Hyperparameters and Training
激活函数:ReLU
window(h): 3,4,5, 每个有100个feature map
dropout p = 0.5
l2(s) = 3
mini-batch size = 50
在SST-2的dev set上进行网格搜索(grid search)选择的以上超参数。
批量梯度下降
使用Adadelta update rule
对于没有提供标准dev set的数据集,随机在training data 中选10%作为dev set.
3.3 Pre-trained Word Vectors
word2vec vectors that were trained on 100 billion words from Google News
3.4 Model Variations
paper中提供的几种模型的变型主要为了测试,初始的word vector的设置对模型效果的影响。
CNN-rand: 完全随机初始化
CNN-static: 用word2vec预训练的初始化
CNN-non-static: 用针对特定任务fine-tuned的
CNN-multichannel: 将static与fine-tuned的结合,每个作为一个channel
效果:后三者相比于完全rand的在7个数据集上效果都有提升。
并且本文所提出的这个简单的CNN模型的效果,和一些利用parse-tree等复杂模型的效果相差很小。在SST-2, CR 中取得了SOTA.
本文提出multichannel的方法,本想希望通过避免overfitting来提升效果的,但是实验结果显示,并没有显示处完全的优势,在一些数据集上的效果,不及其他。
4. Code
Theano: 1. paper的实现代码:yoonkim/CNN_sentence: https://github.com/yoonkim/CNN_sentence
Tensorflow: 2. dennybritz/cnn-text-classification-tf: https://github.com/dennybritz/cnn-text-classification-tf
Keras: 3. alexander-rakhlin/CNN-for-Sentence-Classification-in-Keras: https://github.com/alexander-rakhlin/CNN-for-Sentence-Classification-in-Keras
Pytorch: 4. Shawn1993/cnn-text-classification-pytorch: https://github.com/Shawn1993/cnn-text-classification-pytorch
试验了MR的效果,eval准确率最高为73%,低于github中给出的77.5%和paper中76.1%的准确率;
试验了SST的效果,eval准确率最高为37%,低于github中给出的37.2%和paper中45.0%的准确率。
这里展示model.py的代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable class CNN_Text(nn.Module): def __init__(self, args):
super(CNN_Text, self).__init__()
self.args = args V = args.embed_num
D = args.embed_dim
C = args.class_num
Ci = 1
Co = args.kernel_num
Ks = args.kernel_sizes self.embed = nn.Embedding(V, D)
# self.convs1 = [nn.Conv2d(Ci, Co, (K, D)) for K in Ks]
self.convs1 = nn.ModuleList([nn.Conv2d(Ci, Co, (K, D)) for K in Ks])
'''
self.conv13 = nn.Conv2d(Ci, Co, (3, D))
self.conv14 = nn.Conv2d(Ci, Co, (4, D))
self.conv15 = nn.Conv2d(Ci, Co, (5, D))
'''
self.dropout = nn.Dropout(args.dropout)
self.fc1 = nn.Linear(len(Ks)*Co, C) def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3) # (N, Co, W)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x def forward(self, x):
x = self.embed(x) # (N, W, D) if self.args.static:
x = Variable(x) x = x.unsqueeze(1) # (N, Ci, W, D) x = [F.relu(conv(x)).squeeze(3) for conv in self.convs1] # [(N, Co, W), ...]*len(Ks) x = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in x] # [(N, Co), ...]*len(Ks) x = torch.cat(x, 1) '''
x1 = self.conv_and_pool(x,self.conv13) #(N,Co)
x2 = self.conv_and_pool(x,self.conv14) #(N,Co)
x3 = self.conv_and_pool(x,self.conv15) #(N,Co)
x = torch.cat((x1, x2, x3), 1) # (N,len(Ks)*Co)
'''
x = self.dropout(x) # (N, len(Ks)*Co)
logit = self.fc1(x) # (N, C)
return logit
Pytorch 5. prakashpandey9/Text-Classification-Pytorch: https://github.com/prakashpandey9/Text-Classification-Pytorch
注意,该代码中models的CNN部分是paper的简单实现,但是代码的main.py需要有修改
由于选用的是IMDB的数据集,其label是1,2,而pytorch在计算loss时,要求target的范围在0<= t < n_classes,也就是需要将标签(1,2)转换为(0,1),使其符合pytorch的要求,否则会报错:“Assertion `t >= 0 && t < n_classes` failed.”
可以通过将标签2改为0,来实现:
target = (target != 2)
target = target.long()
应为该代码中用的损失函数是cross_entropy, 所以应转为long类型。
方便起见,这里展示修改后的完整的main.py的代码,里面的超参数可以自行更改。
import os
import time
import load_data
import torch
import torch.nn.functional as F
from torch.autograd import Variable
import torch.optim as optim
import numpy as np
from models.LSTM import LSTMClassifier
from models.CNN import CNN TEXT, vocab_size, word_embeddings, train_iter, valid_iter, test_iter = load_data.load_dataset() def clip_gradient(model, clip_value):
params = list(filter(lambda p: p.grad is not None, model.parameters()))
for p in params:
p.grad.data.clamp_(-clip_value, clip_value) def train_model(model, train_iter, epoch):
total_epoch_loss = 0
total_epoch_acc = 0 device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# model.cuda()
# model.to(device) optim = torch.optim.Adam(filter(lambda p: p.requires_grad, model.parameters()))
steps = 0
model.train()
for idx, batch in enumerate(train_iter):
text = batch.text[0]
target = batch.label
##########Assertion `t >= 0 && t < n_classes` failed.###################
target = (target != 2)
target = target.long()
########################################################################
# target = torch.autograd.Variable(target).long() if torch.cuda.is_available():
text = text.cuda()
target = target.cuda() if (text.size()[0] is not 32):# One of the batch returned by BucketIterator has length different than 32.
continue
optim.zero_grad()
prediction = model(text) prediction.to(device) loss = loss_fn(prediction, target)
loss.to(device) num_corrects = (torch.max(prediction, 1)[1].view(target.size()).data == target.data).float().sum()
acc = 100.0 * num_corrects/len(batch) loss.backward()
clip_gradient(model, 1e-1)
optim.step()
steps += 1 if steps % 100 == 0:
print (f'Epoch: {epoch+1}, Idx: {idx+1}, Training Loss: {loss.item():.4f}, Training Accuracy: {acc.item(): .2f}%') total_epoch_loss += loss.item()
total_epoch_acc += acc.item() return total_epoch_loss/len(train_iter), total_epoch_acc/len(train_iter) def eval_model(model, val_iter):
total_epoch_loss = 0
total_epoch_acc = 0
model.eval()
with torch.no_grad():
for idx, batch in enumerate(val_iter):
text = batch.text[0]
if (text.size()[0] is not 32):
continue
target = batch.label
# target = torch.autograd.Variable(target).long() target = (target != 2)
target = target.long() if torch.cuda.is_available():
text = text.cuda()
target = target.cuda() prediction = model(text)
loss = loss_fn(prediction, target)
num_corrects = (torch.max(prediction, 1)[1].view(target.size()).data == target.data).sum()
acc = 100.0 * num_corrects/len(batch)
total_epoch_loss += loss.item()
total_epoch_acc += acc.item() return total_epoch_loss/len(val_iter), total_epoch_acc/len(val_iter) # learning_rate = 2e-5
# batch_size = 32
# output_size = 2
# hidden_size = 256
# embedding_length = 300 learning_rate = 1e-3
batch_size = 32
output_size = 1
# hidden_size = 256
embedding_length = 300 # model = LSTMClassifier(batch_size, output_size, hidden_size, vocab_size, embedding_length, word_embeddings) model = CNN(batch_size = batch_size, output_size = 2, in_channels = 1, out_channels = 100, kernel_heights = [3,4,5], stride = 1, padding = 0, keep_probab = 0.5, vocab_size = vocab_size, embedding_length = 300, weights = word_embeddings) device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device) loss_fn = F.cross_entropy for epoch in range(1):
train_loss, train_acc = train_model(model, train_iter, epoch)
val_loss, val_acc = eval_model(model, valid_iter) print(f'Epoch: {epoch+1:02}, Train Loss: {train_loss:.3f}, Train Acc: {train_acc:.2f}%, Val. Loss: {val_loss:3f}, Val. Acc: {val_acc:.2f}%') test_loss, test_acc = eval_model(model, test_iter)
print(f'Test Loss: {test_loss:.3f}, Test Acc: {test_acc:.2f}%') ''' Let us now predict the sentiment on a single sentence just for the testing purpose. '''
test_sen1 = "This is one of the best creation of Nolan. I can say, it's his magnum opus. Loved the soundtrack and especially those creative dialogues."
test_sen2 = "Ohh, such a ridiculous movie. Not gonna recommend it to anyone. Complete waste of time and money." test_sen1 = TEXT.preprocess(test_sen1)
test_sen1 = [[TEXT.vocab.stoi[x] for x in test_sen1]] test_sen2 = TEXT.preprocess(test_sen2)
test_sen2 = [[TEXT.vocab.stoi[x] for x in test_sen2]] test_sen = np.asarray(test_sen2)
test_sen = torch.LongTensor(test_sen) # test_tensor = Variable(test_sen, volatile=True) # test_tensor = torch.tensor(test_sen, dtype= torch.long)
# test_tensor.new_tensor(test_sen, requires_grad = False)
test_tensor = test_sen.clone().detach().requires_grad_(False) test_tensor = test_tensor.cuda() model.eval()
output = model(test_tensor, 1)
output = output.cuda()
out = F.softmax(output, 1) if (torch.argmax(out[0]) == 0):
print ("Sentiment: Positive")
else:
print ("Sentiment: Negative")
 [支付宝] Bless you~ O(∩_∩)O
[支付宝] Bless you~ O(∩_∩)O
As you start to walk out on the way, the way appears. ~Rumi
[NLP-CNN] Convolutional Neural Networks for Sentence Classification -2014-EMNLP的更多相关文章
- pytorch -- CNN 文本分类 -- 《 Convolutional Neural Networks for Sentence Classification》
论文 < Convolutional Neural Networks for Sentence Classification>通过CNN实现了文本分类. 论文地址: 666666 模型图 ...
- 《Convolutional Neural Networks for Sentence Classification》 文本分类
文本分类任务中可以利用CNN来提取句子中类似 n-gram 的关键信息. TextCNN的详细过程原理图见下: keras 代码: def convs_block(data, convs=[3, 3, ...
- 卷积神经网络用语句子分类---Convolutional Neural Networks for Sentence Classification 学习笔记
读了一篇文章,用到卷积神经网络的方法来进行文本分类,故写下一点自己的学习笔记: 本文在事先进行单词向量的学习的基础上,利用卷积神经网络(CNN)进行句子分类,然后通过微调学习任务特定的向量,提高性能. ...
- 卷积神经网络CNN(Convolutional Neural Networks)没有原理只有实现
零.说明: 本文的所有代码均可在 DML 找到,欢迎点星星. 注.CNN的这份代码非常慢,基本上没有实际使用的可能,所以我只是发出来,代表我还是实践过而已 一.引入: CNN这个模型实在是有些年份了, ...
- How to Use Convolutional Neural Networks for Time Series Classification
How to Use Convolutional Neural Networks for Time Series Classification 2019-10-08 12:09:35 This blo ...
- [转] Understanding Convolutional Neural Networks for NLP
http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/ 讲CNN以及其在NLP的应用,非常 ...
- Understanding Convolutional Neural Networks for NLP
When we hear about Convolutional Neural Network (CNNs), we typically think of Computer Vision. CNNs ...
- [转]XNOR-Net ImageNet Classification Using Binary Convolutional Neural Networks
感谢: XNOR-Net ImageNet Classification Using Binary Convolutional Neural Networks XNOR-Net ImageNet Cl ...
- Deep learning_CNN_Review:A Survey of the Recent Architectures of Deep Convolutional Neural Networks——2019
CNN综述文章 的翻译 [2019 CVPR] A Survey of the Recent Architectures of Deep Convolutional Neural Networks 翻 ...
随机推荐
- java对象序列化并存储到文件中
● 如何将一个Java对象序列化到文件里 使用输入输出流,,一个是ObjectOutputStream 对象,ObjectOutputStream 负责向指定的流中写入序列化的对象.当从文件中读取序列 ...
- 怎样发出一个HTTP请求
需要使用 xhr.send(); 参数为请求数据体, 如果没有就传入null, 一般来说, GET请求是不用传参的, POST就视情况而定, 理论上所有GET请求都可以改为POST, 反之则不行. v ...
- javaIO——BufferedReader
今天来学习一下 java.io.BufferedReader ,从命名可以看出,跟前面学习的 StringReader 和 CharArrayReader 有些不一样,这些都是按照数据源类型命名,Bu ...
- ES6入门十:iterator迭代器
迭代模式 ES6迭代器标准化接口 迭代循环 自定义迭代器 迭代器消耗 一.迭代模式 迭代模式中,通常有一个包含某种数据集合的对象.该数据可能存在一个复杂数据结构内部,而要提供一种简单的方法能够访问数据 ...
- java代码实现mock数据
废话不多说,直接上代码. /** * 发get请求,获取文本 * * @param getUrl * @return 网页context */ public static String sendGet ...
- 不显示Zetero导出的文献库中的部分内容
不显示Zetero导出的文献库中的部分内容 Zetero作为文献管理软件,收集到的参考文献的相关信息(域fields)比较齐全.文章或书籍的引用中仅仅只用到了其中的一部分,如作者.发表年.题名.期刊( ...
- 一秒钟教会你如何 使用jfreechart制作图表,扇形图,柱形图,线型图,时序图,附上详细代码,直接看效果
今天有小伙伴问到我怎么使用jfreeChat生成图标,去年就有一个这方便的的总结,今天再遇到,就总结出来,供大家参考: 第一个: 创建柱状图,效果图如下: 柱状图代码如下: package cn.xf ...
- appium-清空输入框的内容后,再次输入内容会回退最后两个字符串
问题描述 有两个输入框,用户名和密码输入框 调用set_text方法,输入用户名 再次调用set_text方法,输入密码 清空用户名输入框的内容后,再次输入内容会回退最后两个字符串 出问题的代码 de ...
- 使用Fiddler工具在夜神模拟器或手机上抓包
下载安装Fiddler 地址:https://www.telerik.com/download/fiddler-everywhere Fiddler端设置 Tools>Options>Co ...
- 小程序Flex布局
容器属性 容器支持的属性有:display:通过设置display属性,指定元素是否为Flex布局.flex-direction:指定主轴方向,决定了项目的排列方式.flex-wrap:排列换行设置. ...