mysql连表操作是先连表还是先查询条件
mysql连表操作是先连表还是先查询条件
一、总结
一句话总结:
连表操作时:先根据查询条件和查询字段确定驱动表,确定驱动表之后就可以开始连表操作了,然后再在缓存结果中根据查询条件找符合条件的数据
1、mysql连表中的驱动表如何选择?
在对最终结果集没影响的前提下,优先选择结果集最小的那张表作为驱动表。
2、mysql查询表的时候的预估结果集如何计算?
每行查询字节数 * 预估的行数 = 预估结果集
3、通过where预估结果行数,遵循哪些规则(每行查询字节数 * 预估的行数 = 预估结果集)?
如果where里没有相应表的筛选条件,无论on里是否有相关条件,默认为全表
如果where里有筛选条件,但是不能使用索引来筛选,那么默认为全表
如果where里有筛选条件,而且可以使用索引,那么会根据索引来预估返回的记录行数
4、a和c数据表如何,查询select a.*,c.* from a join c on a.a2=c.c2 where a.a1>5 and c.c1>5; 为何是以字段数多的c表做驱动表?
|||-begin
create table a(a1 int primary key, a2 int ,index(a2)); --双字段都有索引
create table c(c1 int primary key, c2 int ,index(c2), c3 int); --双字段都有索引
|||-end
用a做驱动表需要回查:因为通过已知的c.c2无法得到c.*,需要根据c表的主键再次回查c表
如果select的字段是a.*,c.c2的话就可以直接用a表做驱动表,此时不需要回查c表
如果用a作为驱动表,通过索引c2关联到c表,那么还需要再回表查询一次,因为仅仅通过c2获取不到c.*的数据,还需要通过c2上的主键c1再查询一次。而上一个sql查询的是c2,不需要额外查询。同时因为a表只有两个字段,通过a2索引能够直接获得a.*,不需要额外查询。
5、两表关联查询的内在逻辑是怎样的?
嵌套循环连接:mysql表与表之间的关联查询使用Nested-Loop join算法,顾名思义就是嵌套循环连接
在使用索引关联的情况下,有Index Nested-Loop join和Batched Key Access join两种算法;
在未使用索引关联的情况下,有Simple Nested-Loop join和Block Nested-Loop join两种算法;
mysql表与表之间的关联查询使用Nested-Loop join算法,顾名思义就是嵌套循环连接,但是根据场景不同可能有不同的变种:比如Index Nested-Loop join,Simple Nested-Loop join,Block Nested-Loop join, Betched Key Access join等。
6、驱动表一般怎么选(带索引)(人为的直观)?
where条件里的表:一般在where条件里面的那个表就是驱动表,where条件里面我们一般找的索引,所以会导致(每行查询字节数 * 预估的行数 = 预估结果集)公式里面的预估的行数非常小
7、连表(连接表的外键有索引)操作的具体操作步骤是怎样的(循环操作)?
1、从驱动表中取出一条符合要求的数据
2、回表:通过这条数据然后通过索引找到关联表中的数据(如果只需要where条件里面的字段就不需要这步回表操作)
3、数据加入缓存
8、连表操作的具体操作步骤给我们的启示是什么?
不仅主键使用索引,外键肯定一定要使用索引,where条件里面的那些字段最好都用上索引
二、Mysql多表连接查询的执行细节(一)
转自或参考:Mysql多表连接查询的执行细节(一)
https://blog.csdn.net/qq_27529917/article/details/87904179
先构建本篇博客的案列演示表:
create table a(a1 int primary key, a2 int ,index(a2)); --双字段都有索引
create table c(c1 int primary key, c2 int ,index(c2), c3 int); --双字段都有索引
create table b(b1 int primary key, b2 int); --有主键索引
create table d(d1 int, d2 int); --没有索引
insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
insert into b values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
insert into c values(1,1,1),(2,4,4),(3,6,6),(4,5,5),(5,3,3),(6,3,3),(7,2,2),(8,8,8),(9,5,5),(10,3,3);
insert into d values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
- 驱动表如何选择?
驱动表的概念是指多表关联查询时,第一个被处理的表,使用此表的记录去关联其他表。驱动表的确定很关键,会直接影响多表连接的关联顺序,也决定了后续关联时的查询性能。
驱动表的选择遵循一个原则:在对最终结果集没影响的前提下,优先选择结果集最小的那张表作为驱动表。改变驱动表就意味着改变连接顺序,只有在不会改变最终输出结果的前提下才可以对驱动表做优化选择。在外连接情况下,很多时候改变驱动表会对输出结果有影响,比如left join的左边表和right join的右边表,驱动表选择join的左边或者右边最终输出结果很有可能会不同。
用结果集来选择驱动表,那结果集是什么?如何计算结果集?mysql在选择前会根据where里的每个表的筛选条件,相应的对每个可作为驱动表的表做个结果记录预估,预估出每个表的返回记录行数,同时再根据select里查询的字段的字节大小总和做乘积:
每行查询字节数 * 预估的行数 = 预估结果集
通过where预估结果行数,遵循以下规则:
- 如果where里没有相应表的筛选条件,无论on里是否有相关条件,默认为全表
- 如果where里有筛选条件,但是不能使用索引来筛选,那么默认为全表
- 如果where里有筛选条件,而且可以使用索引,那么会根据索引来预估返回的记录行数
我们以上述创建的表为基础,用如下sql作为案列来演示:
select a.*,c.c2 from a join c on a.a2=c.c2 where a.a1>5 and c.c1>5;
通过explain查看其执行计划:

explain显示结果里排在第一行的就是驱动表,此时表c为驱动表。
如果将sql修改一下,将select 里的条件c.c2 修改为 c.* :
select a.*,c.* from a join c on a.a2=c.c2 where a.a1>5 and c.c1>5;
通过explain查看其执行计划:

此时驱动表还是c,按理来说 c.* 的数据量肯定是比 a.*大的,似乎结果集大小的规则在这里没有起作用。
此情形下如果用a作为驱动表,通过索引c2关联到c表,那么还需要再回表查询一次,因为仅仅通过c2获取不到c.*的数据,还需要通过c2上的主键c1再查询一次。而上一个sql查询的是c2,不需要额外查询。同时因为a表只有两个字段,通过a2索引能够直接获得a.*,不需要额外查询。
综上所述,虽然使用c表来驱动,结果集大一些,但是能够减少一次额外的回表查询,所以mysql认为使用c表作为驱动来效率更高。
结果集是作为选择驱动表的一个主要因素,但不是唯一因素。
2 . 两表关联查询的内在逻辑是怎样的?
mysql表与表之间的关联查询使用Nested-Loop join算法,顾名思义就是嵌套循环连接,但是根据场景不同可能有不同的变种:比如Index Nested-Loop join,Simple Nested-Loop join,Block Nested-Loop join, Betched Key Access join等。
- 在
使用索引关联的情况下,有Index Nested-Loop join和Batched Key Access join两种算法; - 在
未使用索引关联的情况下,有Simple Nested-Loop join和Block Nested-Loop join两种算法;
我们先来看有索引的情形,使用的是博客刚开始时建立的表,sql如下:
select a.*,c.* from a join c on a.a2=c.c2 where a.a1>4;
通过explain查看其执行计划:

首先根据第一步的逻辑来确定驱动表a,然后通过a.a1>4,a.来查询一条记录a1=5,将此记录的c2关联到c表,取得c2索引上的主键c1,然后用c1的值再去聚集索引上查询c.*,组成一条完整的结果,放入net buffer,然后再根据条件a.a1>4,a. 取下一条记录,循环此过程。过程图如下:
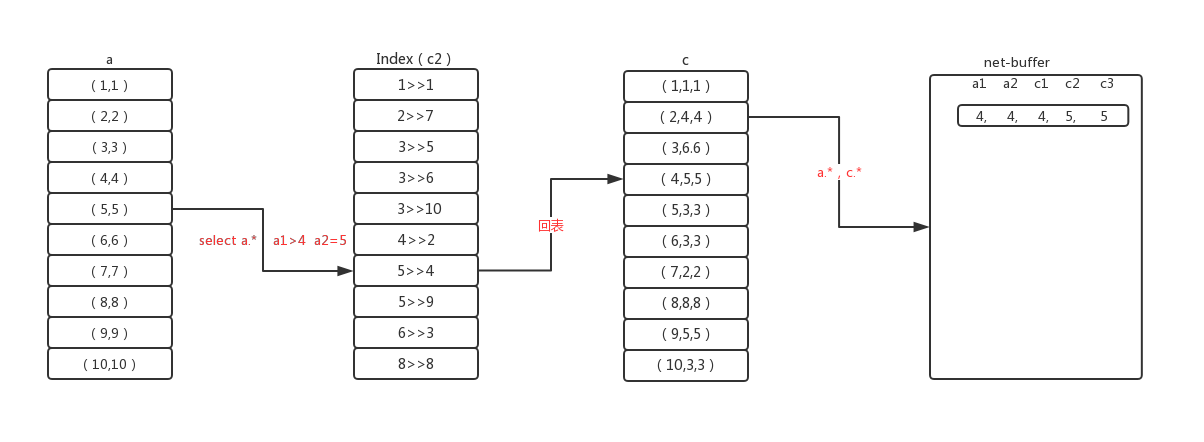
通过索引关联被驱动表,使用的是Index Nested-Loop join算法,不会使用msyql的join buffer。根据驱动表的筛选条件逐条地和被驱动表的索引做关联,每关联到一条符合的记录,放入net-buffer中,然后继续关联。此缓存区由net_buffer_length参数控制,最小4k,最大16M,默认是1M。 如果net-buffer满了,将其发送给client,清空net-buffer,继续上一过程。
通过上述流程知道,驱动表的每条记录在关联被驱动表时,如果需要用到索引不包含的数据时,就需要回表一次,去聚集索引上查询记录,这是一个随机查询的过程。每条记录就是一次随机查询,性能不是非常高。mysql对这种情况有选择的做了优化,将这种随机查询转换为顺序查询,执行过程如下图:
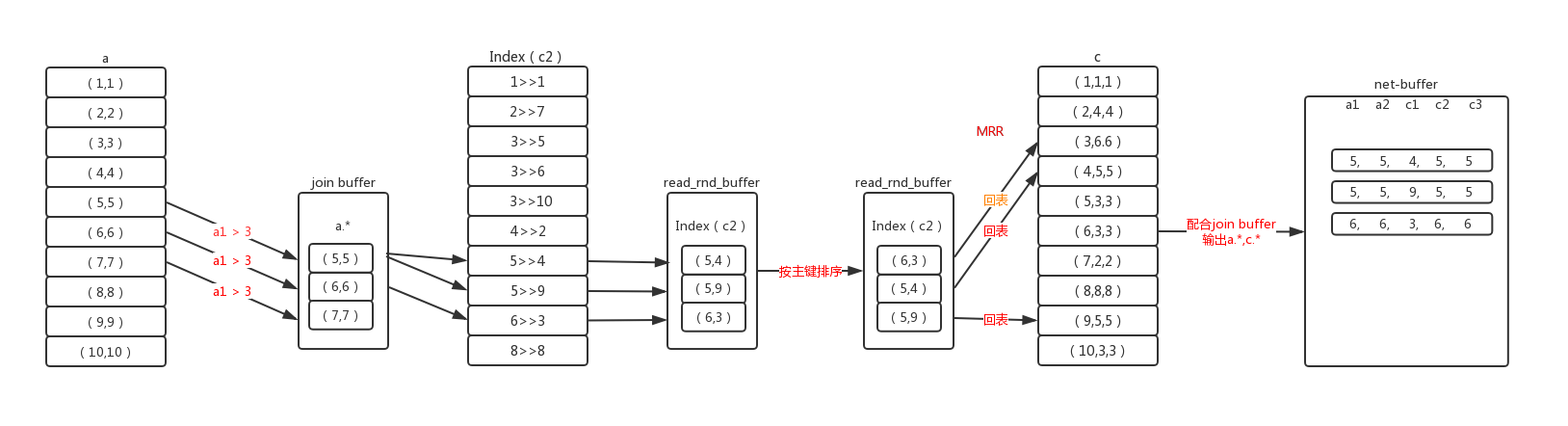
此时会使用Batched Key Access join 算法,顾名思义,就是批量的key访问连接。
逐条的根据where条件查询驱动表,将符合记录的数据行放入join buffer,然后根据关联的索引获取被驱动表的索引记录,存入read_rnd_buffer。join buffer和read_rnd_buffer都有大小限制,无论哪个到达上限都会停止此批次的数据处理,等处理完清空数据再执行下一批次。也就是驱动表符合条件的数据可能不能够一次处理完,而要分批次处理。
当达到批次上限后,对read_rnd_buffer里的被驱动表的索引按主键做递增排序,这样在回表查询时就能够做到近似顺序查询:
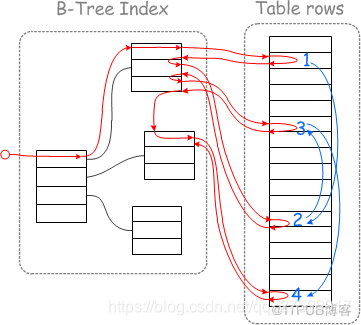
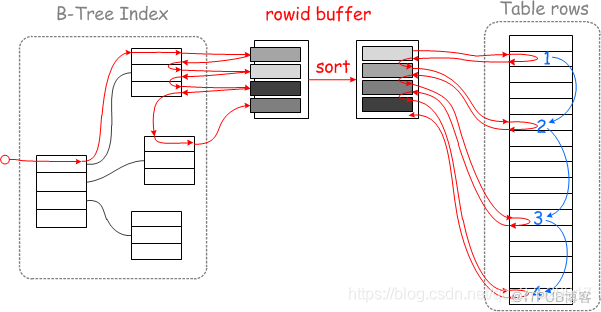
如上图,左边是未排序前的随机查询示意图,右边是排序后使用MRR(
Multi-Range Read)的顺序查询示意图。因为mysql的InnoDB引擎的数据是按聚集索引来排列的,当对非聚集索引按照主键来排序后,再用主键去查询就使得随机查询变为顺序查询,而计算机的顺序查询有预读机制,在读取一页数据时,会向后额外多读取最多1M数据。此时顺序读取就能排上用场。
BKA算法在需要对被驱动表回表的情况下能够优化执行逻辑,如果不需要会表,那么自然不需要BKA算法。
如果要使用 BKA 优化算法的话,你需要在执行 SQL 语句之前先设置:
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
前两个参数的作用是要启用 MRR(Multi-Range Read)。这么做的原因是,BKA 算法的优化需要依赖于MRR,官方文档的说法,是现在的优化器策略,判断消耗的时候,会更倾向于不使用 MRR,把 mrr_cost_based 设置为 off,就是固定使用 MRR 了。)
最后再用explain查看开启参数后的执行计划:

上述都是有索引关联被驱动表的情况,接下来我们看看没有索引关联被驱动表的情况。
没有使用索引关联,那么最简单的Simple Nested-Loop join,就是根据where条件,从驱动表取一条数据,然后全表扫面被驱动表,将符合条件的记录放入最终结果集中。这样驱动表的每条记录都伴随着被驱动表的一次全表扫描,这就是Simple Nested-Loop join。
当然mysql没有直接使用Simple Nested-Loop join,而是对其做了一个优化,不是逐条的获取驱动表的数据,而是多条的获取,也就是一块一块的获取,取名叫Block Nested-Loop join。每次取一批数据,上限是达到join buffer的大小,然后全表扫面被驱动表,每条数据和join buffer里的所有行做匹配,匹配上放入最终结果集中。这样就极大的减少了扫描被驱动表的次数。
BNL(Block Nested-Loop join) 和 BKA(Batched Key Access join)的流程有点类似, 但是没有read_rnd_buffer这个步骤。
示例sql如下:
select a.*, d.* from a join d on a.a2=d.d2 where a.a1>7;
用explain查看其执行计划:

3 . 多表连接如何执行?是先两表连接的结果集然后关联第三张表,还是一条记录贯穿全局?
其实看连接算法的名称:Nested-Loop join,嵌套循环连接,就知道是多表嵌套的循环连接,而不是先两表关联得出结果,然后再依次关联的形式,其形式类似于下面这样:
for row1 in table1 filtered by where{
for row2 in table2 associated by table1.index1 filtered by where{
for row3 in table3 associated by table2.index2 filtered by where{
put into net-buffer then send to client;
}
}
}
对于不同的join方式,有下列情况:
Index Nested-Loop join:
sql如下:
select a.*,b.*,c.* from a join c on a.a2=c.c2 join b on c.c2=b.b2 where b.b1>4;
通过explain查看其执行计划:

其内部执行流程如下: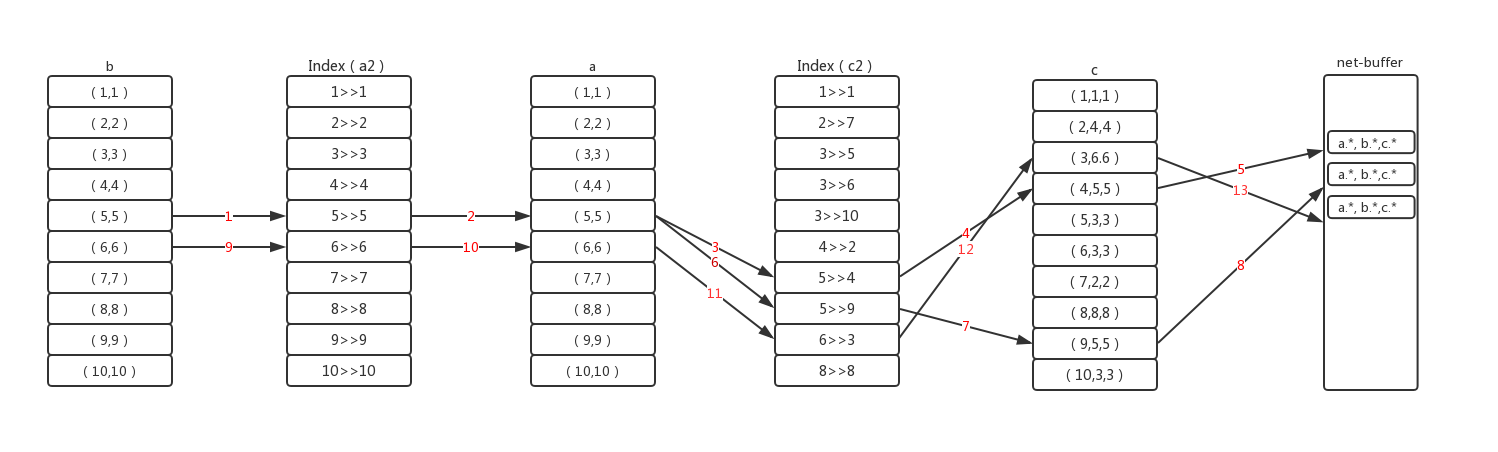
执行前mysql执行器会确定好各个表的关联顺序。首先通过where条件,筛选驱动表b的第一条记录b5,然后将用此记录的关联字段b2与第二张表a的索引a2做关联,通过Btree定位索引位置,匹配的索引可能不止一条。当匹配上一条,查看where里是否有a2的过滤条件且条件是否需要索引之外的数据,如果要则回表,用a2索引上的主键去查询数据,然后做判断。通过则用join后的信息再用同样的方式来关联第三章表c。
Block Nested-Loop join 和 Batched Key Access join : 这两个关联算法和Index Nested-Loop join算法类似,不过因为他们能使用join buffer,所以他们可以每次从驱动表筛选一批数据,而不是一条。同时每个join关键字就对应着一个join buffer,也就是驱动表和第二张表用一个join buffer,得到的块结果集与第三章表用一个join buffer。
本篇博客主要就是讲述上述三个问题,如何确定驱动表,两表关联的执行细节,多表关联的执行流程。
mysql连表操作是先连表还是先查询条件的更多相关文章
- MySQL DROP TABLE操作以及 DROP 大表时的注意事项【转】
删表 DROP TABLE Syntax DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ... [RESTRICT | CASCAD ...
- MySQL DROP TABLE操作以及 DROP 大表时的注意事项
语法: 删表 DROP TABLE Syntax DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ... [RESTRICT | CA ...
- sqlalchemy模块介绍、单表操作、一对多表操作、多对多表操作、flask集成.
今日内容概要 sqlalchemy介绍和快速使用 单表操作增删查改 一对多 多对多 flask集成 内容详细 1.sqlalchemy介绍和快速使用 # SQLAlchemy是一个基于 Python实 ...
- 广义表操作 (ava实现)——广义表深度、广义表长度、打印广义表信息
广义表是对线性表的扩展——线性表存储的所有的数据都是原子的(一个数或者不可分割的结构),且所有的数据类型相同.而广义表是允许线性表容纳自身结构的数据结构. 广义表定义: 广义表是由n个元素组成的序列: ...
- ORM多表操作之创建关联表及添加表记录
创建关联表 关于表关系的几个结论 (1)一旦确立表关系是一对多:建立一对多关系----在多对应的表中创建关联字段. (2)一旦确立表关系是多对多:建立多对多关系----创建第三张关系表----id和两 ...
- 阶段3 1.Mybatis_09.Mybatis的多表操作_2 完成account表的建立及实现单表查询
mybatis中的多表查询: 示例:用户和账户 一个用户可以有多个账户 一个账户只能属于一个用户(多个账户也可以属于同一个用户) ...
- mysql批量update操作时出现锁表
https://www.cnblogs.com/wodebudong/articles/7976474.html 最近遇到一件锁表的情况,发现更新的语句where检索的字段,没有建索引,且是批量操作的 ...
- Mysql执行Update操作时会锁住表
update tableA a,(select a.netbar_id,sum(a.reward_amt) reward_amt from tableB a group by a.netbar_id) ...
- Mysql表操作《一》表的增删改查
一.表介绍 表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应的标题,称为表的字段 id,name,qq,age称为字段,其余的,一行内容称为一条记录 二.创建表 语法 ...
随机推荐
- linux下Django Nginx+uwsgi 安装配置
原文链接 在前面的章节中我们使用 python manage.py runserver 来运行服务器.这只适用测试环境中使用. 正式发布的服务,我们需要一个可以稳定而持续的服务器,比如apache, ...
- DX使用随记--GroupControl
1. 创建按钮: (1)添加引用:Imports DevExpress.XtraEditors.ButtonsPanelControl (2)添加按钮语句:GroupControl1.CustomHe ...
- 一个SAP顾问的回忆:我过去很胖!
去年也是这个时候,SAP成都研究院体育界大神邓阳,曾经赏脸在Jerry这个公众号上赐文一篇,介绍了他和围绕在他身边的一群小伙伴们的体育故事:SAP成都研究院的体育故事 而今天文章的主角则是SAP成都研 ...
- 2.4 使用 xpath 对xml 进行解析
public class Demo1 { /** * XPath提取XML文档数据 * xpath很强大 用来提取xml文档数据非常方便 * @throws Exception */ public s ...
- Codeforces Round #588 (Div. 1) C. Konrad and Company Evaluation
直接建反边暴力 复杂度分析见https://blog.csdn.net/Izumi_Hanako/article/details/101267502 #include<bits/stdc++.h ...
- P2402 奶牛隐藏 二分+网络流
floyd搞出两点间最短距离 二分判答案 // luogu-judger-enable-o2 #include<bits/stdc++.h> using namespace std; ty ...
- Appium&Java自动化实现移动端几种典型动作
一.Appium4.0 Pinch&Zoom /* * @FileName Pinch_Zoom: Pinch_Zoom * @author davieyang * @create 2018- ...
- H5 页面 rem 布局适配方法
rem 布局适配方案 主要方法为: 按照设计稿与设备宽度的比例,动态计算并设置 html 根标签的 font-size 大小: css 中,设计稿元素的宽.高.相对位置等取值,按照同等比例换算为 re ...
- mongodb命令---花样查询语句
闲言少叙 查出价格低于200的商品信息----包含商品名称,货物编号,价格,添加信息等 db.goods.find( {}}, {,,,} ) 商品分类不为3的商品 db.goods.find( {} ...
- C# ado.net 操作(一)
简单的增删改查 class Program { private static string constr = "server=.;database=northwnd;integrated s ...