12.Flume的安装
先把flume包上传并解压
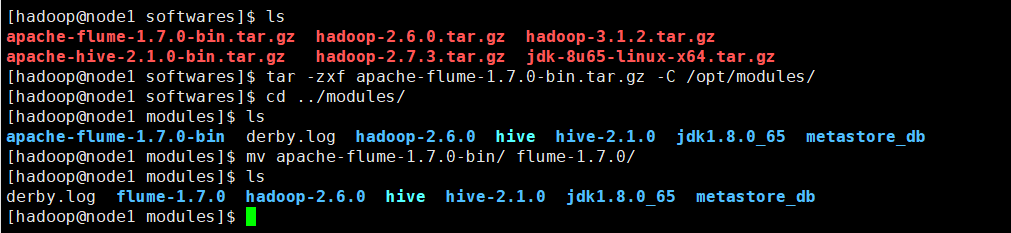
给flume创建一个软链接
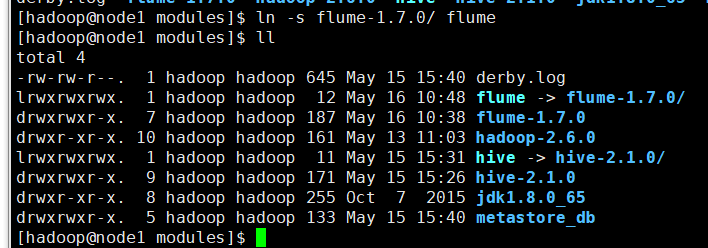
给flume配置环境变量


- #flume
- export FLUME_HOME=/opt/modules/flume
- export PATH=$PATH:$FLUME_HOME/bin
使环境变量生效

验证flume版本信息
- flume-ng version

然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME


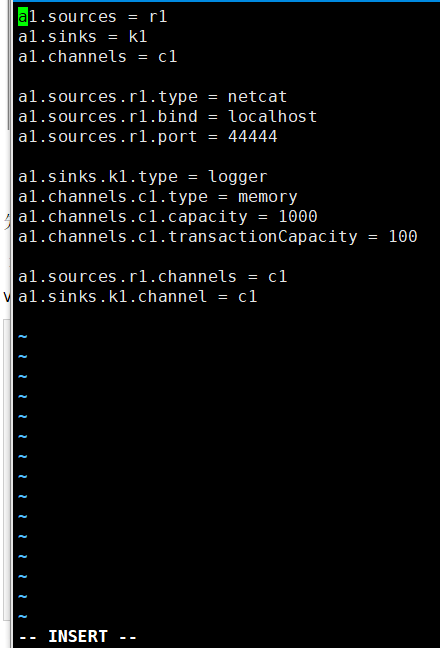
先用一个最简单的例子来测试一下程序环境是否正常
先在flume的conf目录下新建一个文件
vim netcat-logger.conf
# 定义这个agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 描述和配置sink组件:k1
a1.sinks.k1.type = logger
# 描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000 内存里面存放1000个事件
a1.channels.c1.transactionCapacity = 100
# 描述和配置source channel sink之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- a1.sources = r1
- a1.sinks = k1
- a1.channels = c1
- a1.sources.r1.type = netcat
- a1.sources.r1.bind = localhost
- a1.sources.r1.port =
- a1.sinks.k1.type = logger
- a1.channels.c1.type = memory
- a1.channels.c1.capacity =
- a1.channels.c1.transactionCapacity =
- a1.sources.r1.channels = c1
- a1.sinks.k1.channel = c1
启动agent去采集数据
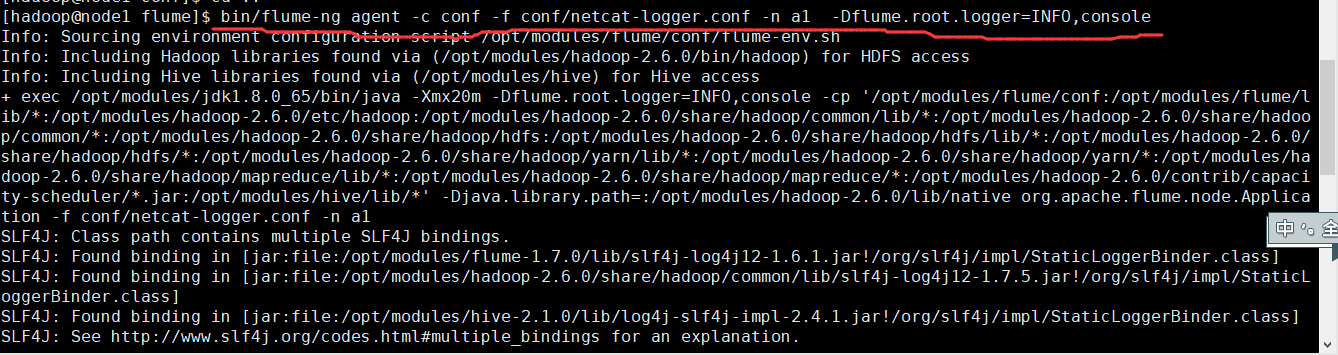
- bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.conf 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
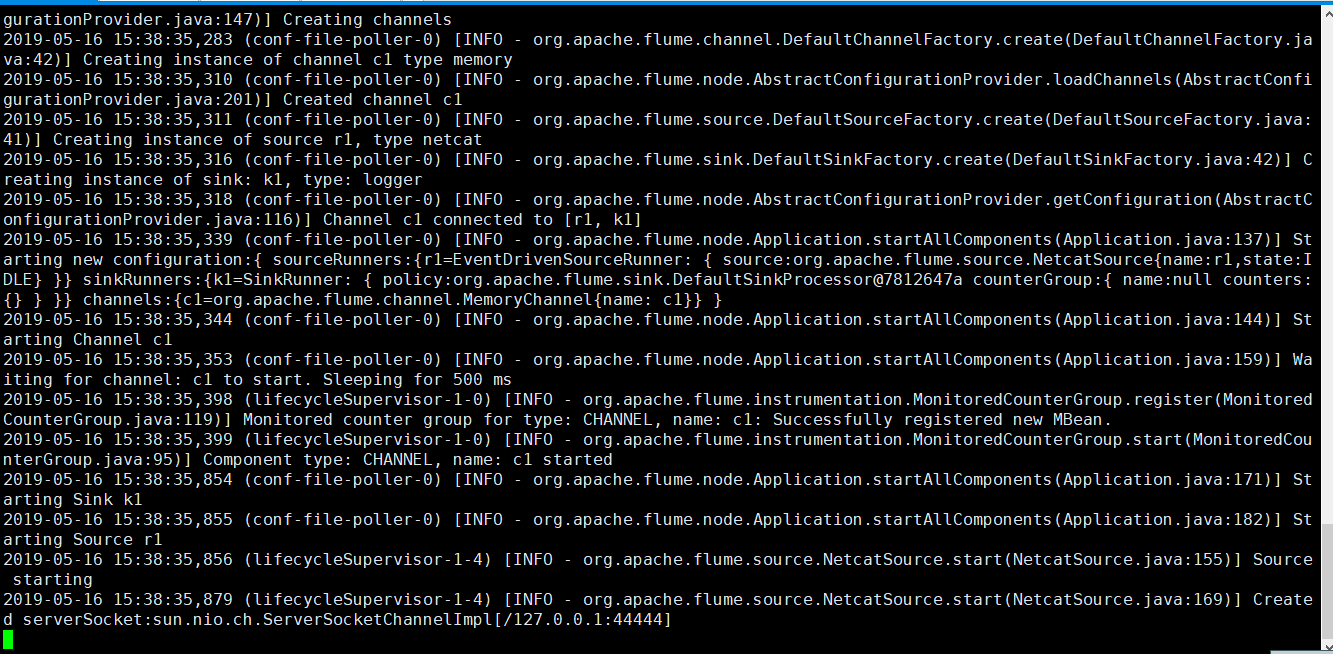
启动nc的客户端
$>nc localhost 44444
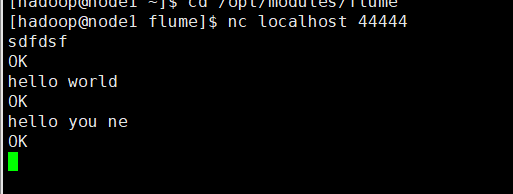
可以看到flume接收到

采集本地目录的数据文件到HDFS上
采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去
根据需求,首先定义以下3大要素
1.采集源,即source——监控文件目录 : spooldir
2.下沉目标,即sink——HDFS文件系统 : hdfs sink
3.source和sink之间的传递通道——channel,可用file channel 也可以用内存channel
新建配置文件
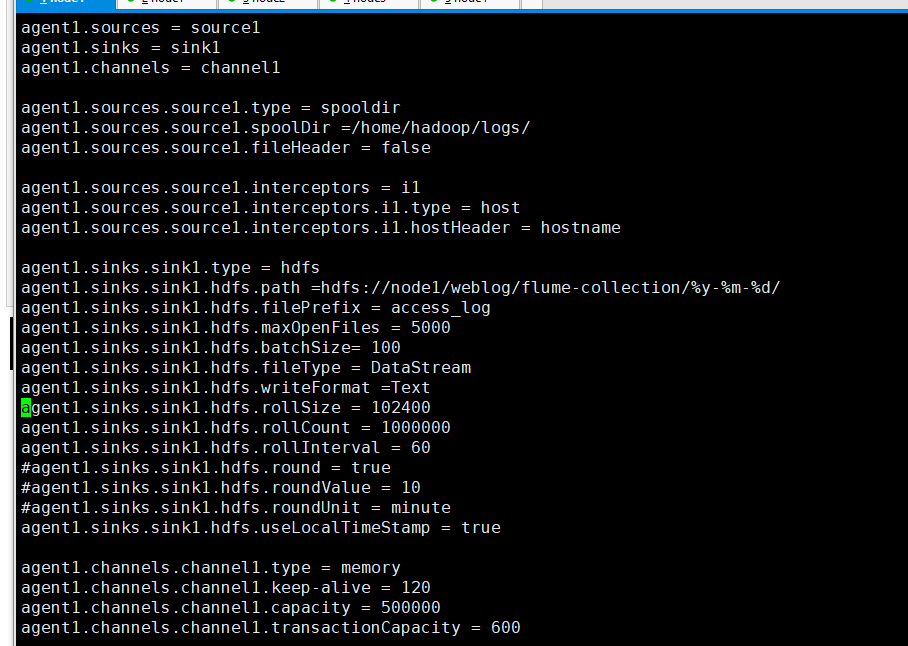
- #定义三大组件的名称
- agent1.sources = source1
- agent1.sinks = sink1
- agent1.channels = channel1
- # 配置source组件
- agent1.sources.source1.type = spooldir(监听的文件不能重复)
- agent1.sources.source1.spoolDir =/home/hadoop/logs/
- agent1.sources.source1.fileHeader = false
- #配置拦截器
- agent1.sources.source1.interceptors = i1
- agent1.sources.source1.interceptors.i1.type = host
- agent1.sources.source1.interceptors.i1.hostHeader = hostname
- # 配置sink组件
- agent1.sinks.sink1.type = hdfs
- agent1.sinks.sink1.hdfs.path =hdfs://node1/weblog/flume-collection/%y-%m-%d/
- agent1.sinks.sink1.hdfs.filePrefix = access_log
- agent1.sinks.sink1.hdfs.maxOpenFiles =
- agent1.sinks.sink1.hdfs.batchSize=
- agent1.sinks.sink1.hdfs.fileType = DataStream
- agent1.sinks.sink1.hdfs.writeFormat =Text
- agent1.sinks.sink1.hdfs.rollSize =
- agent1.sinks.sink1.hdfs.rollCount =
- agent1.sinks.sink1.hdfs.rollInterval =
- #agent1.sinks.sink1.hdfs.round = true
- #agent1.sinks.sink1.hdfs.roundValue =
- #agent1.sinks.sink1.hdfs.roundUnit = minute
- agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
- # Use a channel which buffers events in memory
- agent1.channels.channel1.type = memory
- agent1.channels.channel1.keep-alive =
- agent1.channels.channel1.capacity =
- agent1.channels.channel1.transactionCapacity =
- # Bind the source and sink to the channel
- agent1.sources.source1.channels = channel1
- agent1.sinks.sink1.channel = channel1

在本地创建目录

运行flume
- bin/flume-ng agent -c conf -f conf/spooldir.conf -n agent1 -Dflume.root.logger=INFO,console
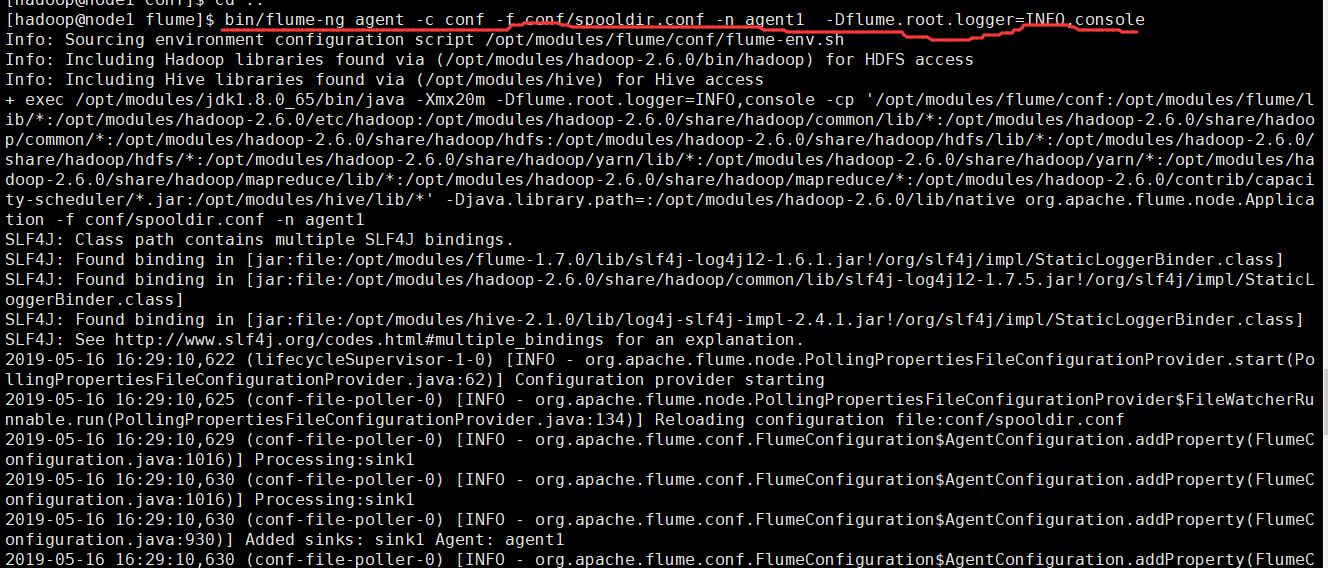
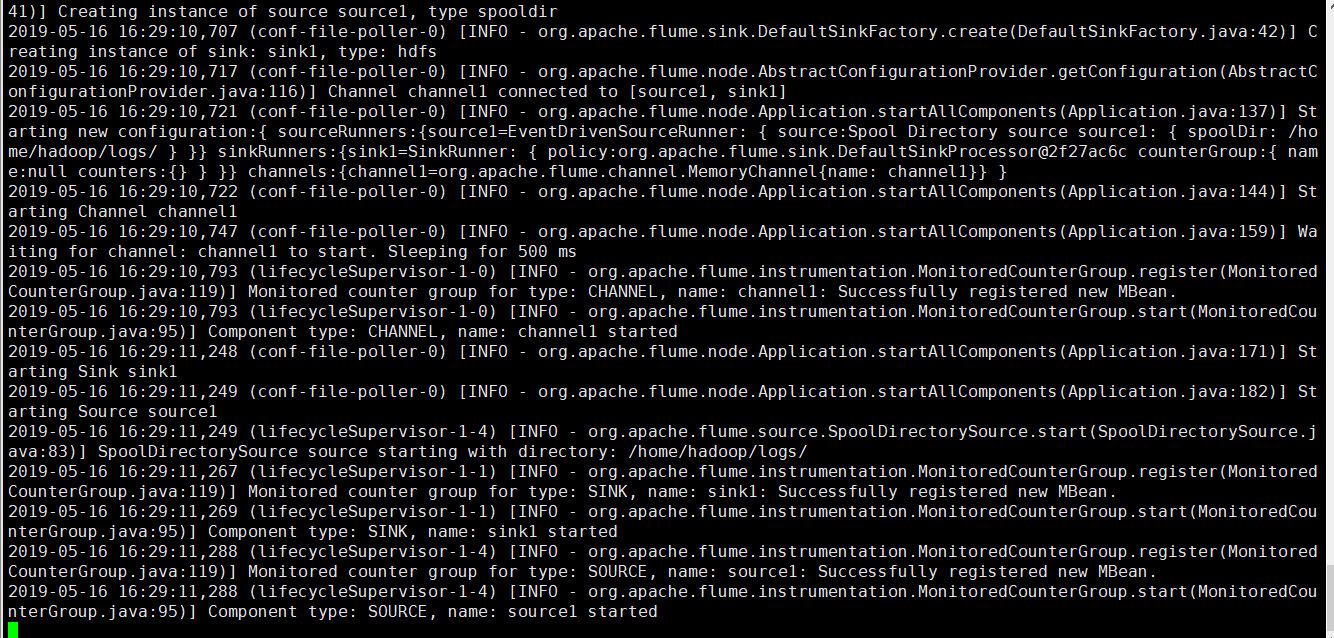
把a.txt数据文件拷贝到被监听的本地目录下

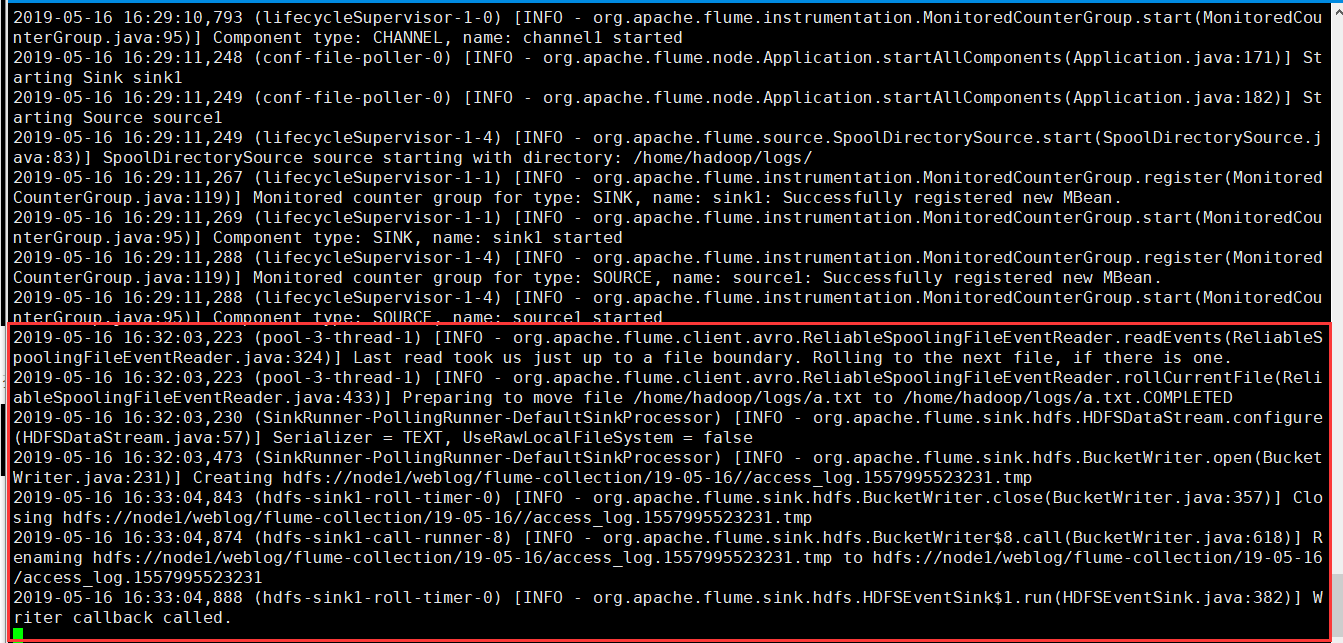
HDFS上多了个目录
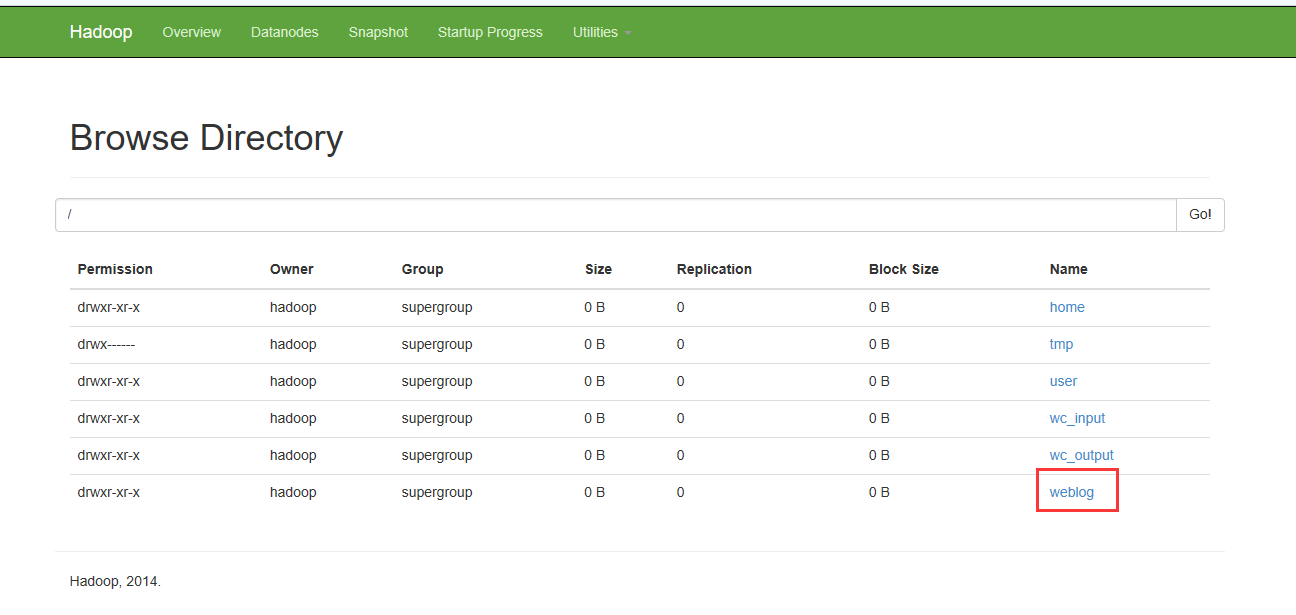
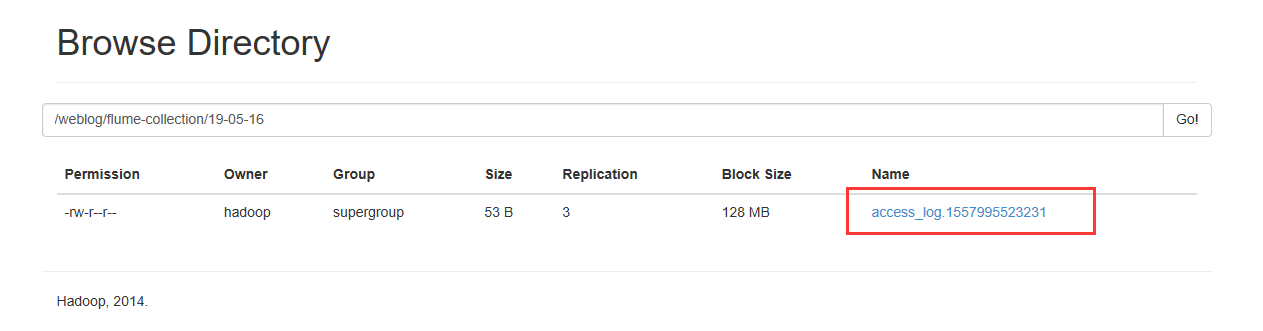
我们再上传一个数据文件到本地的监听目录下

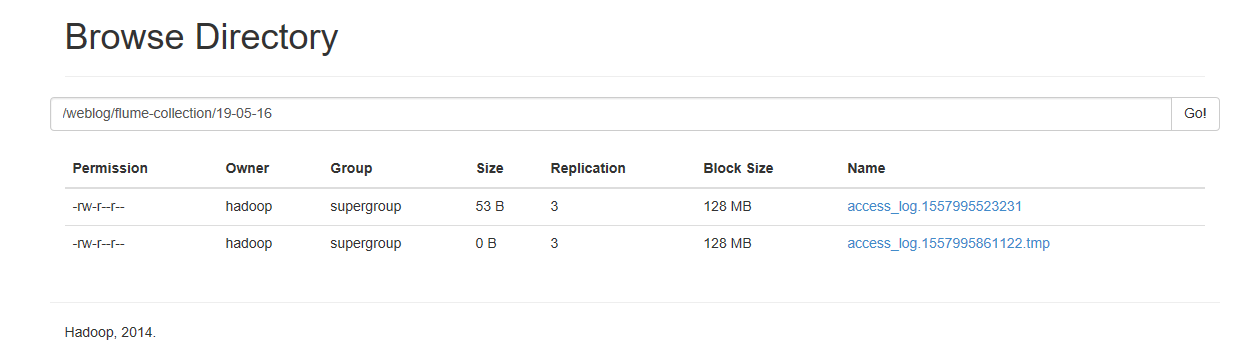
采集文件到HDFS
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs
根据需求,首先定义以下3大要素
1. 采集源,即source——监控文件内容更新 : exec ‘tail -F file’
即时输出文件变化后追加的数据。
tail -f file 动态跟踪文件file的增长情况,tail会每隔一秒去检查一下文件是否增加新的内容。如果增加就追加在原来的输出后面显示。但这种情况,必须保证在执行tail命令时,文件已经存在。
2.下沉目标,即sink——HDFS文件系统 : hdfs sink
3. Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
首先创建一个配置文件

- agent1.sources = source1
- agent1.sinks = sink1
- agent1.channels = channel1
- # Describe/configure tail -F source1
- agent1.sources.source1.type = exec
- agent1.sources.source1.command = tail -F /home/hadoop/logs/access_log
- agent1.sources.source1.channels = channel1
- #configure host for source
- agent1.sources.source1.interceptors = i1
- agent1.sources.source1.interceptors.i1.type = host
- agent1.sources.source1.interceptors.i1.hostHeader = hostname
- # Describe sink1
- agent1.sinks.sink1.type = hdfs
- #a1.sinks.k1.channel = c1
- agent1.sinks.sink1.hdfs.path =hdfs://node1/weblog/flume/%y-%m-%d/
- agent1.sinks.sink1.hdfs.filePrefix = access_log
- agent1.sinks.sink1.hdfs.maxOpenFiles =
- agent1.sinks.sink1.hdfs.batchSize=
- agent1.sinks.sink1.hdfs.fileType = DataStream
- agent1.sinks.sink1.hdfs.writeFormat =Text
- agent1.sinks.sink1.hdfs.rollSize =
- agent1.sinks.sink1.hdfs.rollCount =
- agent1.sinks.sink1.hdfs.rollInterval =
- #agent1.sinks.sink1.hdfs.round = true
- #agent1.sinks.sink1.hdfs.roundValue =
- #agent1.sinks.sink1.hdfs.roundUnit = minute
- agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
- # Use a channel which buffers events in memory
- agent1.channels.channel1.type = memory
- agent1.channels.channel1.keep-alive =
- agent1.channels.channel1.capacity =
- agent1.channels.channel1.transactionCapacity =
- # Bind the source and sink to the channel
- agent1.sources.source1.channels = channel1
- agent1.sinks.sink1.channel = channel1
配置完后就启动flume
- bin/flume-ng agent -c conf -f conf/exec.conf -n agent1 -Dflume.root.logger=INFO,console


先在本地的被监听目录下创建log日志文件,并往改文件写入内容


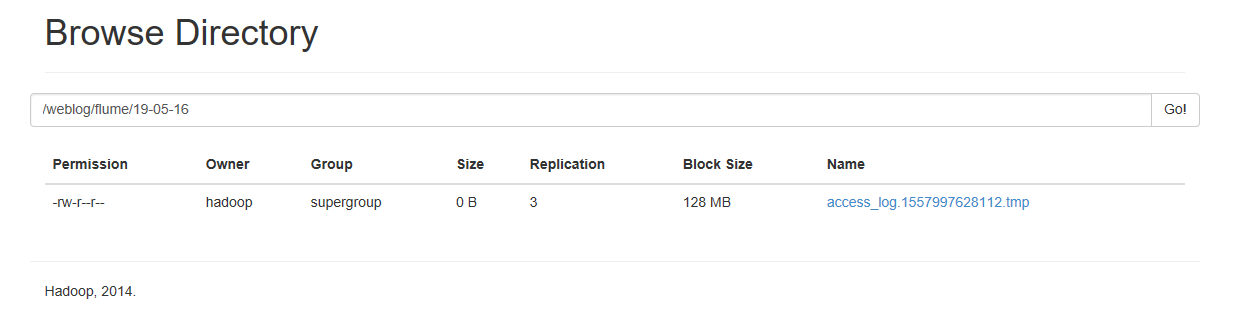
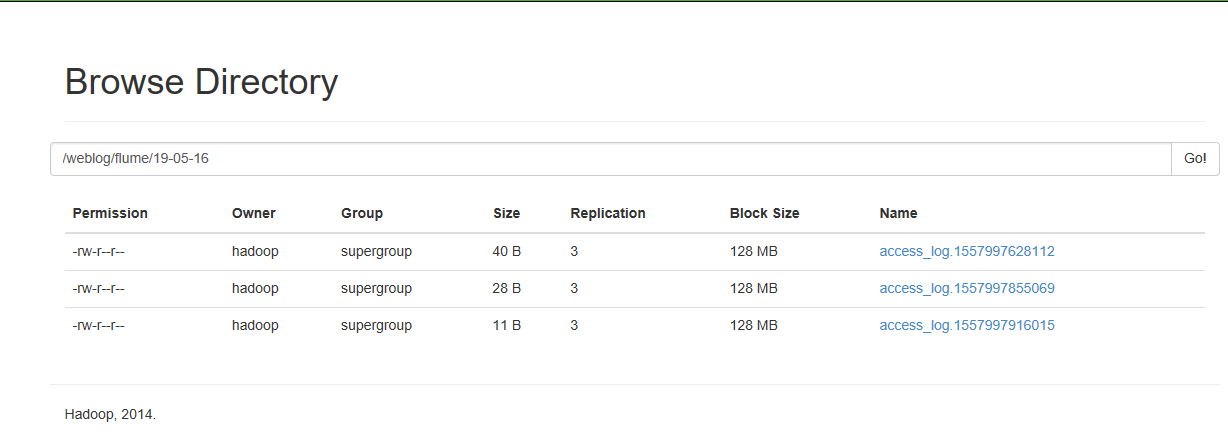
可以看到HDFS的目录上产生了对于的日志文件
我们给监听文件继续追加内容
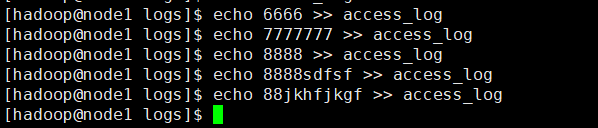
HDFS同时会更新日志文件
12.Flume的安装的更多相关文章
- Centos7的安装、Docker1.12.3的安装,以及Docker Swarm集群的简单实例
目录 [TOC] 1.环境准备 本文中的案例会有四台机器,他们的Host和IP地址如下 c1 -> 10.0.0.31 c2 -> 10.0.0.32 c3 -> 10.0.0. ...
- Angularjs学习---angularjs环境搭建,ubuntu 12.04下安装nodejs、npm和karma
1.下载angularjs 进入其官网下载:https://angularjs.org/,建议下载最新版的:https://ajax.googleapis.com/ajax/libs/angular ...
- Flume的安装与配置
Flume的安装与配置 一. 资源下载 资源地址:http://flume.apache.org/download.html 程序地址:http://apache.fayea.com/fl ...
- 如何在ubuntu 12.04 中安装经典的 GNOME桌面
这次介绍的是如何在ubuntu 12.04 中安装经典的 GNOME桌面,默认的 Ubuntu 12.04 默认unity桌面,一些用户不喜欢 Unity 桌面,所以想找回昔日的经典Gnome桌面. ...
- 对<< ubuntu 12.04编译安装linux-3.6.10内核笔记>>的修正
前题: 在前几个月的时候,写了一篇笔记,说的是kernel compile的事情,当时经验不足,虽说编译过了,但有些地方写的有错误--因为当时的理解是有错误的.今天一一更正,记录如下: 前文笔记链接: ...
- Ubuntu 12.04 下安装 Eclipse
方法一:(缺点是安装时附加openjdk等大量程序并无法去除,优点是安装简单) $ sudo apt-get install eclipse 方法二:(优点是安装内容清爽,缺点是配置麻烦)1.安装JD ...
- VMware Workstation 12 Pro 之安装Windows10 EP系统
VMware Workstation 12 Pro 之安装Windows10 EP系统... --------------- 先准备好要用的Win10的镜像文件ISO ---------------- ...
- VMware Workstation 12 Pro 之安装林耐斯Ubuntu X64系统
VMware Workstation 12 Pro 之安装林耐斯Ubuntu X64系统... -------------- Linux依照国际音标应该是/'linэks/——类似于“里讷克斯&quo ...
- VMware Workstation 12 Pro 之安装林耐斯Debian X64系统
VMware Workstation 12 Pro 之安装林耐斯Debian X64系统... --------------------- 看到它的LOGO就很喜欢: ---------------- ...
随机推荐
- map(callback)将一组元素转换成其他数组(不论是否是元素数组)
map(callback) 概述 将一组元素转换成其他数组(不论是否是元素数组) 你可以用这个函数来建立一个列表,不论是值.属性还是CSS样式,或者其他特别形式.这都可以用'$.map()'来方便的建 ...
- UVA 12501 Bulky process of bulk reduction ——(线段树成段更新)
和普通的线段树不同的是,查询x~y的话,给出的答案是第一个值的一倍加上第二个值的两倍一直到第n个值的n倍. 思路的话,就是关于query和pushup的方法.用一个新的变量sum记录一下这个区间里面按 ...
- win 内网frp反弹到内网liunx
前提:frp不同系统 但是版本必须完全相同 这是我的两个版本 我这个就是验证frp可以在不同系统之间使用 准备工作 靶机 win2003 ip 192.168.1.132 公网 vps windows ...
- 在linux写一个shell脚本用maven git自动更新代码并且打包部署
服务器上必须安装了git maven jdk 并且配置好环境变量 实际服务器中可能运行着多个Java进程,所以重新部署的时候需要先停止原来的java进程,写一个按照名称杀死进程的脚本 kill.sh ...
- nginx的ngx_str_t
在nginx里的ngx_tr_t结构是字符串定义如下 typedef struct { size_t len; u_char *data; }ngx_str_t; 在给这样的结构体赋值的时候,ngin ...
- Java并发指南开篇:Java并发编程学习大纲
Java并发编程一直是Java程序员必须懂但又是很难懂的技术内容. 这里不仅仅是指使用简单的多线程编程,或者使用juc的某个类.当然这些都是并发编程的基本知识,除了使用这些工具以外,Java并发编程中 ...
- centos6.9实现双网卡绑定
1.创建bond0文件 # vi /etc/sysconfig/network-scripts/ifcfg-bond0 DEVICE=bond0 NM_CONTROLLED=no #是否由networ ...
- 【零基础】Selenium:Webdriver图文入门教程java篇(附相关包下载)
一.selenium2.0简述 与一般的浏览器测试框架(爬虫框架)不同,Selenium2.0实际上由两个部分组成Selenium+webdriver,Selenium负责用户指令的解释(code), ...
- 黑马vue---16、vue中通过属性绑定为元素设置class类样式
黑马vue---16.vue中通过属性绑定为元素设置class类样式 一.总结 一句话总结: 这里就是为元素绑定class样式,和后面的style样式区别一下 vue中class样式绑定方式的相对于原 ...
- 3299 Humidex
Humidex Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 23219 Accepted: 8264 Descript ...