selenium反爬机制
使用selenium模拟浏览器进行数据抓取无疑是当下最通用的数据采集方案,它通吃各种数据加载方式,能够绕过客户JS加密,绕过爬虫检测,绕过签名机制。它的应用,使得许多网站的反采集策略形同虚设。由于selenium不会在HTTP请求数据中留下指纹,因此无法被网站直接识别和拦截。
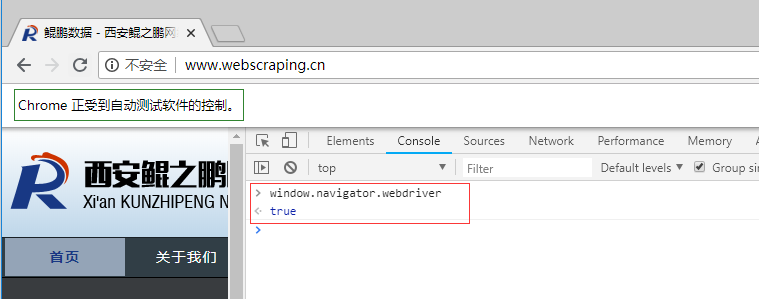
这是不是就意味着selenium真的就无法被网站屏蔽了呢?非也。selenium在运行的时候会暴露出一些预定义的Javascript变量(特征字符串),例如"window.navigator.webdriver",在非selenium环境下其值为undefined,而在selenium环境下,其值为true(如下图所示为selenium驱动下Chrome控制台打印出的值)。
除此之外,还有一些其它的标志性字符串(不同的浏览器可能会有所不同),常见的特征串如下所示:
- webdriver
- __driver_evaluate
- __webdriver_evaluate
- __selenium_evaluate
- __fxdriver_evaluate
- __driver_unwrapped
- __webdriver_unwrapped
- __selenium_unwrapped
- __fxdriver_unwrapped
- _Selenium_IDE_Recorder
- _selenium
- calledSelenium
- _WEBDRIVER_ELEM_CACHE
- ChromeDriverw
- driver-evaluate
- webdriver-evaluate
- selenium-evaluate
- webdriverCommand
- webdriver-evaluate-response
- __webdriverFunc
- __webdriver_script_fn
- __$webdriverAsyncExecutor
- __lastWatirAlert
- __lastWatirConfirm
- __lastWatirPrompt
- $chrome_asyncScriptInfo
- $cdc_asdjflasutopfhvcZLmcfl_
了解了这个特点之后,就可以在浏览器客户端JS中通过检测这些特征串来判断当前是否使用了selenium,并将检测结果附加到后续请求之中,这样服务端就能识别并拦截后续的请求。
下面讲一个具体的例子。
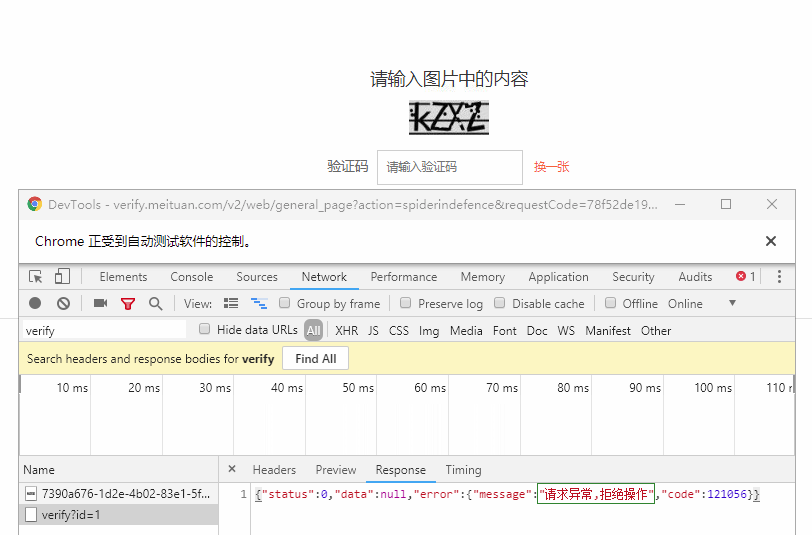
鲲之鹏的技术人员近期就发现了一个能够有效检测并屏蔽selenium的网站应用:大众点评网的验证码表单页,如果是正常的浏览器操作,能够有效的通过验证,但如果是使用selenium就会被识别,即便验证码输入正确,也会被提示“请求异常,拒绝操作”,无法通过验证(如下图所示)。
分析页面源码,可以找到 https://static.meituan.net/bs/yoda-static/file:file/d/js/yoda.e6e7c3988817eb17.js 这个JS文件,将代码格式化后,搜索webdriver可以看到如下代码:
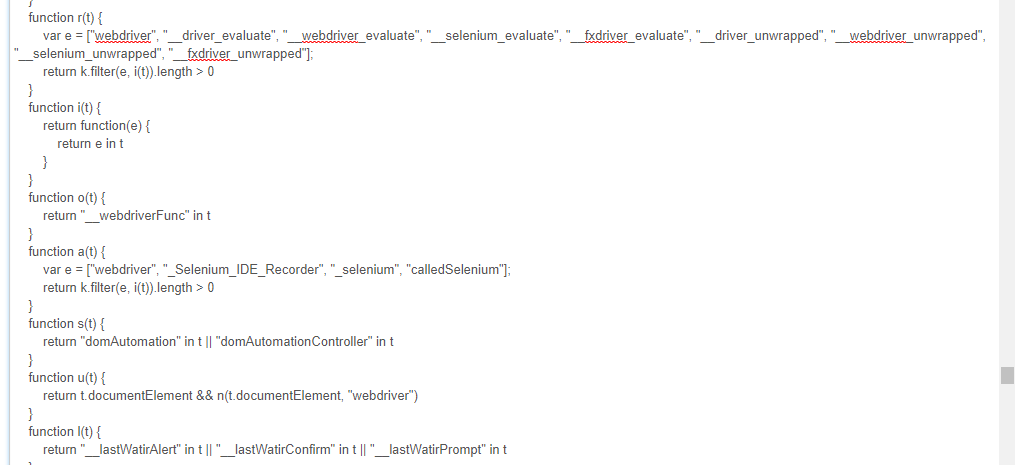
可以看到它检测了"webdriver", "__driver_evaluate", "__webdriver_evaluate"等等这些selenium的特征串。提交验证码的时候抓包可以看到一个_token参数(很长),selenium检测结果应该就包含在该参数里,服务端借以判断“请求异常,拒绝操作”。
现在才进入正题,如何突破网站的这种屏蔽呢?
我们已经知道了屏蔽的原理,只要我们能够隐藏这些特征串就可以了。但是还不能直接删除这些属性,因为这样可能会导致selenium不能正常工作了。我们采用曲线救国的方法,使用中间人代理,比如fidder, proxy2.py或者mitmproxy,将JS文件(本例是yoda.*.js这个文件)中的特征字符串给过滤掉(或者替换掉,比如替换成根本不存在的特征串),让它无法正常工作,从而达到让客户端脚本检测不到selenium的效果。
下面我们验证下这个思路。这里我们使用mitmproxy实现中间人代理),对JS文件(本例是yoda.*.js这个文件)内容进行过滤。启动mitmproxy代理并加载response处理脚本:
- mitmdump.exe -S modify_response.py
其中modify_response.py脚本如下所示:
- # coding: utf-8
- # modify_response.py
- import re
- from mitmproxy import ctx
- def response(flow):
- """修改应答数据
- """
- if '/js/yoda.' in flow.request.url:
- # 屏蔽selenium检测
- for webdriver_key in ['webdriver', '__driver_evaluate', '__webdriver_evaluate', '__selenium_evaluate', '__fxdriver_evaluate', '__driver_unwrapped', '__webdriver_unwrapped', '__selenium_unwrapped', '__fxdriver_unwrapped', '_Selenium_IDE_Recorder', '_selenium', 'calledSelenium', '_WEBDRIVER_ELEM_CACHE', 'ChromeDriverw', 'driver-evaluate', 'webdriver-evaluate', 'selenium-evaluate', 'webdriverCommand', 'webdriver-evaluate-response', '__webdriverFunc', '__webdriver_script_fn', '__$webdriverAsyncExecutor', '__lastWatirAlert', '__lastWatirConfirm', '__lastWatirPrompt', '$chrome_asyncScriptInfo', '$cdc_asdjflasutopfhvcZLmcfl_']:
- ctx.log.info('Remove "{}" from {}.'.format(webdriver_key, flow.request.url))
- flow.response.text = flow.response.text.replace('"{}"'.format(webdriver_key), '"NO-SUCH-ATTR"')
- flow.response.text = flow.response.text.replace('t.webdriver', 'false')
- flow.response.text = flow.response.text.replace('ChromeDriver', '')
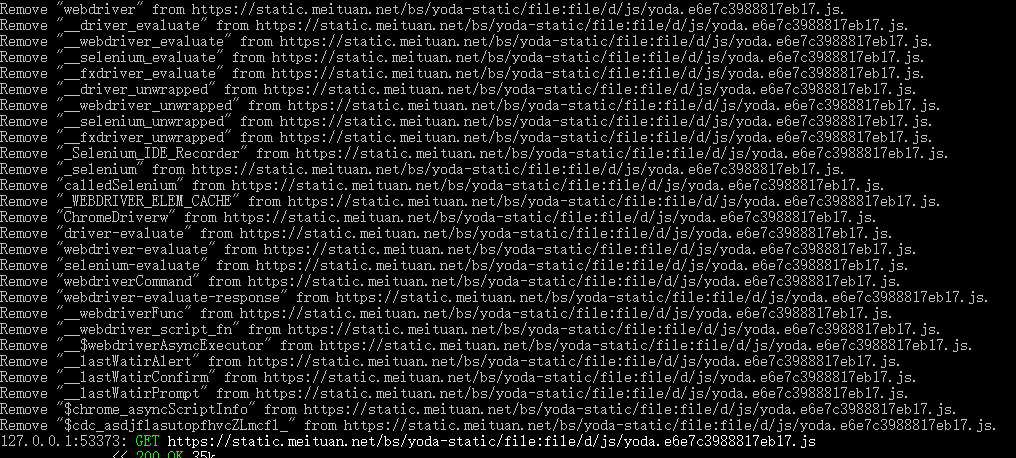
在selnium中使用该代理(mitmproxy默认监听127.0.0.1:8080)访问目标网站,mitmproxy将过滤JS中的特征符串,如下图所示:
经多次测试,该方法可以有效的绕过大众点评的selenium检测,成功提交大众点评网的验证码表单。
selenium反爬机制的更多相关文章
- 第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用.自动限速.自定义spider的settings,对抗反爬机制 cookie禁用 就是在Scrapy的配置文件set ...
- 用Nginx分流绕开Github反爬机制
用Nginx分流绕开Github反爬机制 0x00 前言 如果哪天有hacker进入到了公司内网为所欲为,你一定激动地以为这是一次蓄谋已久的APT,事实上,还有可能只是某位粗线条的员工把VPN信息泄露 ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题
python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题 一丶爬虫概述 通过编写程序'模拟浏览器'上网,然后通 ...
- Python爬虫实战——反爬机制的解决策略【阿里】
这一次呢,让我们来试一下"CSDN热门文章的抓取". 话不多说,让我们直接进入CSND官网. (其实是因为我被阿里的反爬磨到没脾气,不想说话--) 一.URL分析 输入" ...
- python爬虫破解带有RSA.js的RSA加密数据的反爬机制
前言 同上一篇的aes加密一样,也是偶然发现这个rsa加密的,目标网站我就不说了,保密. 当我发现这个网站是ajax加载时: 我已经习以为常,正在进行爬取时,发现返回为空,我开始用findler抓包, ...
- 破解另一家网站的反爬机制 & HMAC 算法
零.写在前面 本文涉及的反爬技术,仅供个人技术学习,禁止并做到: 干扰被访问网站的正常运行 抓取受到法律保护的特定类型的数据或信息 搜集到的数据禁止传播.交给第三方使用.或者牟利 如有可能,在爬到数据 ...
- 小白突破百度翻译反爬机制,33行Python代码实现汉译英小工具!
表弟17岁就没读书了,在我家呆了差不多一年吧. 呆的前几个月,每天上网打游戏,我又不好怎么在言语上管教他,就琢磨着看他要不要跟我学习Python编程.他开始问我Python编程什么?我打开了我给学生上 ...
- 二十八 Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
cookie禁用 就是在Scrapy的配置文件settings.py里禁用掉cookie禁用,可以防止被通过cookie禁用识别到是爬虫,注意,只适用于不需要登录的网页,cookie禁用后是无法登录的 ...
随机推荐
- BKP和RTC
Stm32内部有多个BKP寄存器,在主电源被切断或者系统产生复位的时候,BKP寄存器仍然可以利用备用电源的支持保持其重要内容. BKP在实际应用中可以存入重要数据,防止被恶意查看. BKP有入侵检测, ...
- cd .ssh返回-bash: cd: .ssh:No such file or directory怎么办
继续上一篇博文 今天再次陷入同样的问题 避免这个问题的另一个套路是用节点和其他节点直接ssh 远程连接,需要输入密码, 但是输入再次退出之后就OK了 cd 可以到.ssh了 然后就可以开心的免密了
- 二:MySQL系列之SQL基本操作(二)
本篇主要介绍SOL语句的基本操作,主要有分为 连接数据库,创建数据库.创建数据表.添加数据记录,基本的查询功能等操作. 一.针对数据库的操作 -- 1.连接数据库 mysql -uroot -p my ...
- TLS之殇如何把我逼上绝望
1.协议的形式化分析,前提是弄清楚协议结构和协议参与者之间的会话交互,以及会话之间使用的加解密算法,签名算法,认证算法,等牵扯的算法.之后便是将要分析的协议部分进行抽象化,具体抽象涉及协议参与者(发起 ...
- Python语言程序设计:Lab6
Reversing a List If you have time, you can try to write a function which will reverse a list recursi ...
- 检查shell脚本
1.检查solr服务监控脚本: #/bin/bash starttime=$(date +%Y-%m-%d\ %H:%M:%S) http_code=$(curl -I -m -o /dev//sol ...
- SASS 和 LESS 的区别
1.编译环境不同 SASS 的安装需要 Ruby 环境,是在服务端处理的: LESS 需要引入 less.js 来处理代码输出 CSS 到浏览器,也可以在开发环节使用 LESS,然后编译成 CSS 文 ...
- subprocess、struct模块的简单应用与ssh模型(黏包)
一.subprocess模块 #可以通过传递字符串命令,帮你去实现一些操作系统的命令. import subprocess res = subprocess.Popen("dir" ...
- 2016年第六届蓝桥杯C/C++程序设计本科B组决赛 ——一步之遥(填空题题)
一步之遥 从昏迷中醒来,小明发现自己被关在X星球的废矿车里.矿车停在平直的废弃的轨道上.他的面前是两个按钮,分别写着“F”和“B”. 小明突然记起来,这两个按钮可以控制矿车在轨道上前进和后退.按F,会 ...
- webpack 配置react脚手架(四):路由配置
1. 由于 react-router 是集成了 react-router-dom 和 react-router-native的一起的,所以这里要使用的是 react-router-dom, 2. 安装 ...