Tika结合Tesseract-OCR 实现光学汉字识别(简体、宋体的识别率百分之百)—附Java源码、测试数据和训练集下载地址

OCR(Optical character recognition) —— 光学字符识别,是图像处理的一个重要分支,中文的识别具有一定挑战性,特别是手写体和草书的识别,是重要和热门的科学研究方向。可惜国内的科研院所,基本没有几个高识别率的训练集——笔者联系过北京语言大学研究生一篇论文的作者,他们论文说有%90的正确识别率,结果只做了20个笔画简单的汉字(20/6753 = %0.3 常用简体汉字的千分之三),然后找了20个学生,各自手写了一遍。真的是为了论文而论文,而且很会选择样本(小而简单)

斯坦福大学有个工程项目,专门做中文汉字的识别——欧美发达国家的科研院所更有研究精神
提高识别率,训练集是关键!
提高识别率,训练集是关键!!
提高识别率,训练集是关键!!!
下载训练集—traineddata请移步:
https://github.com/tesseract-ocr/tessdata
中文请选如下4个:
chi_sim.traineddata (简体— 对于宋体,像素>= 300dpi:识别率高达%100,同时对英文及阿拉伯数字识别率高达百分之90以上)
chi_sim_vert.traineddata (简体,竖排)
chi_tra.traineddata (繁体)
chi_tra_vert.traineddata(繁体,竖排)【CoderBaby】
- 如何做自己的测试数据集
请参考官网: how to train tesseract
经过测试得出如下结论:
- 对于宋体,白色背景,非倾斜等,像素大于等于300dpi—识别率%100
- 英文和数字,识别率超过90%
- 特殊字符识别率不高
- 像素太低,识别率急剧下降
- 多种背景颜色变化,识别率极低
- 字体换成草书等,识别率大幅降低
- 电影屏幕字幕和网页截图识别率较低
- 扫描件如果字体太淡,太小,完全识别不出来
- 提高识别率,需要自己做训练集,工作量巨大的体力活(简体汉字最少6753个,混合一些复杂的,至少要10000个字符;不同字体要重新做,因为本质上是图形几何计算,国内科研院所和开源的做的不多)
- Java源码实现,tika结合Tesseract-OCR
(1)源码如下(支持多个图片识别)
@Test
public void testCode() throws IOException, SAXException, TikaException, InterruptedException {
List<String> fileNames = new ArrayList<>();
fileNames.add("chi_eng.png");
fileNames.add("chi_eng01.png");
fileNames.add("chi_old.png");
fileNames.add("chi-scan-75dpi.jpg");
fileNames.add("chi-scan-100dpi.jpg");
fileNames.add("chi-scan-300dpi.jpg");
fileNames.add("chi-smartphone.jpg");
fileNames.add("chi-subtitle-v1.jpg");
fileNames.add("english00.png");
fileNames.add("pdf_shaomiao.png");
fileNames.add("test.tiff");
fileNames.add("weather.png"); // 转载请注明出处:https://www.cnblogs.com/NaughtyCat/p/tika-support-Tesseract-OCR-with-source-code-and-test-data.html
TesseractOCRParser parser = new TesseractOCRParser(); TesseractOCRConfig config = new TesseractOCRConfig();
// 设置简体中文训练集
config.setLanguage("chi_sim");
// 设置Tesseract 安装路径
config.setTesseractPath("C:/Program Files/Tesseract-OCR");
// 设置train data 路径
config.setTessdataPath("C:/Program Files/Tesseract-OCR/tessdata"); ParseContext context = new ParseContext();
context.set(TesseractOCRConfig.class, config);
context.set(TesseractOCRParser.class, parser); fileNames.forEach(filename -> {
BodyContentHandler handler = new BodyContentHandler();
File file = new File("E:/tika/testData" + File.separator + filename);
if (file.exists()) {
Metadata metadata = new Metadata();
try (InputStream stream = new FileInputStream(file)) {
parser.parse(stream, handler, metadata, context);
} catch (Exception e) { }
handler.toString();
}
});
}
}
- 测试数据(图片)说明及下载地址
具体说明及测试效果请参见:https://ocr.space/blog/2015/03/best-ocr-software-for-chinese.html
相关测试图片请参见:https://github.com/A9T9/OCR-Benchmark
(2)原始图片及效果 ()
基于“chi_sim.traineddata ”— 即简体中文训练集
图1

转换效果如下:

【结论】
300dpi,识别率:%100
图2
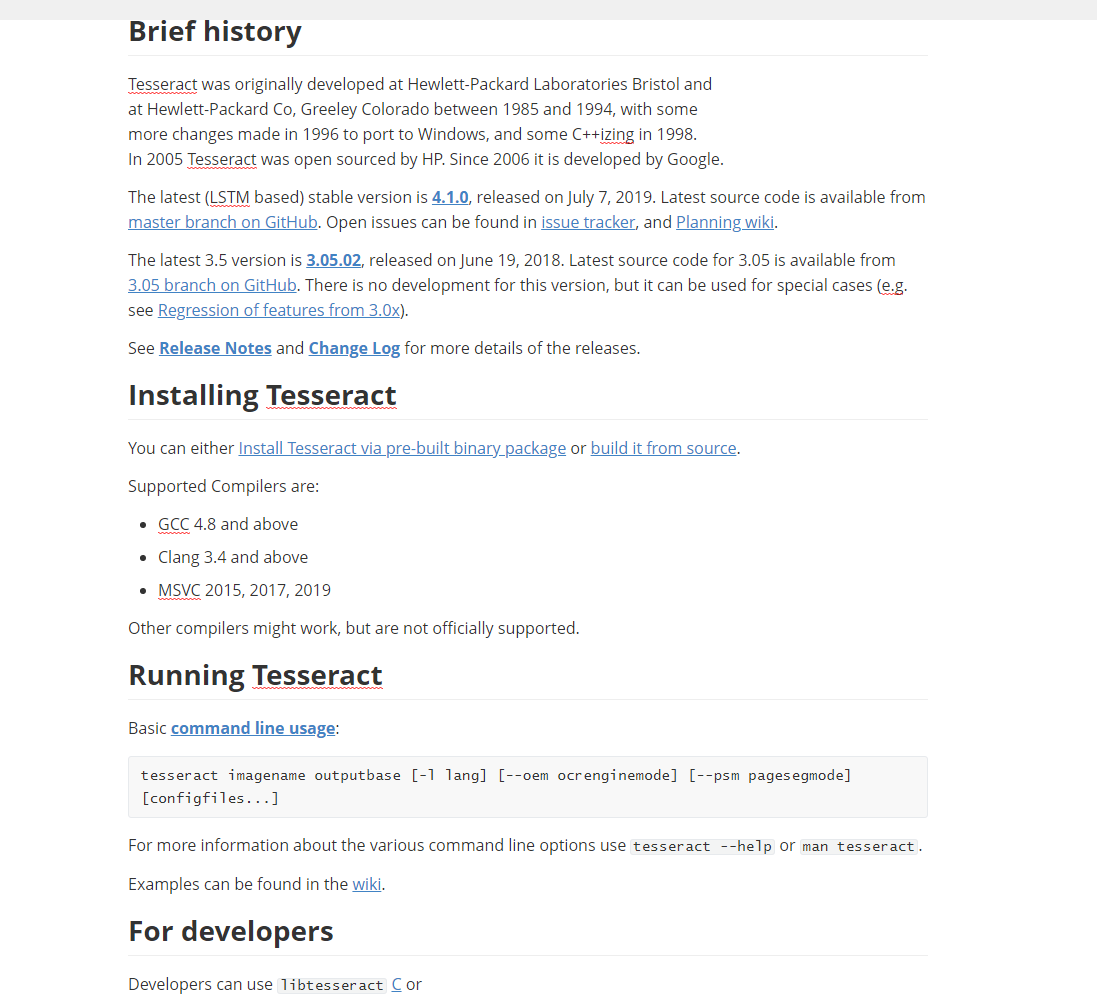
转换效果如下:
Brief history
Tesseractwes orginally developed at HewlettPackard Laboratones Bristol and
atHewettPackard Co Greeley Colorado beween 1985 and 1994 wthsome
more changes made in 1996 to portto Windows and some C++zing in1998
In2005 Tesseract was open sourced by HP Since 2006 itis developed by Goosgle
Thelatest (LSTM based]j stableversionis4.10, released on July 7.2019.Latest source codes avaable from
master branch on GlHub.Openissues can be foundin ssue racker and Planning iki
Thelatest35 version 5 3.05.02 released onjune 19,2018.Latestsource code for3.055 avaable from
305 branch on GlHHub.There sno development forthisversion,butitcan be used forspecial cases .
see Regression offeatures from 30x
See Release Notes and Change Log formore detas ofthe releases-
Installing Tesseract
You can ettherInstall Tesseractvia prepulltbinary package or pulld iLfrom sourcey
Supported Complersare:
* GCC48 and above
* ang34and above
* MSVC 2015.2017.2019
Othercompllersmightwork butare notofially supportedl
Running Tesseract
Basiccommand line usage:
tesseract inagenane outputbase [-1 ]ang】 [--osn ocrenginenode] [--psn pagesegnode
[configfiles...]
Formore information aboutthe various command line options use esseract --henp or man tesseract .
Examples can befoundin thewiki
For developers
Developers can use Tbtessaract Cor
【结论】
英文,特殊符号等会识别失败。识别率:>%80
图3.

转换效果如下:
E g 气
Even as Tvanja praised 8e parties Envoyed i 功 i5 7el gzamt7 comgpi 地 08
Qchieveze1 Q 7W7Der- Ofsocial media lsers appeared crilical of er as-
Sesszet 0f 加 e Trip adiistration「5 role 加 功 i5 endeavou7
IBM 表 示 不 服 ,Google 不 care。 下 而 让 我 们 逐 字 逐 句 来 看 他 们 的 论 文
吧 , 对 于 争 论 的 事 情 , 自 己 下 功 夫 搞 清 楚 。
松 贵 莹 坊 办 少
忠 : https:/ww.cnblogs-com/NaughtyCatpytranslate-of-google-
Quantum-supremacy-article-published-on-nature.html
Quantum supremacy using
a programmable
superconducting
processor
基 于 可 编 程 的 超 导 处 理 器 实 现 的 量 子 霸
权
动 关 盘 源 ,https://doorg/10.1038/s41586-019-1666-5
煌 收 船 2019 乐 7 历 20 历
旋 准 8 船 2019 乐 9 历 20 厂
坊 终 发 疗 2019 知 10 月 23 厅
Abstract
引 言
量 子 计 算 机 吹 牛 遢 说 , 对 于 特 定 的 计 算 任 务 , 基 于 量 子 处 理 器 的 计 算
机 , 其 速 度 相 较 于 经 典 处 理 器 呈 指 数 级 增 长 。 根 本 的 挑 战 在 于 构 建 一
【结论】
宋体,加粗,黑色——识别率%100;倾斜,绿色等——识别率:%70
图4(扫描件).

转换效果如下:
节 P a
为客户服务是华为存在的睢一理由” 从 公 司 层 面
看 , 为客户创造价值的主业务流只有一个!
Ipo - nisgniedProductDevelopment
B croeis PaFA 4 辜蒙扁)
Unc - LomdTocash
芸 a npe waa8 2 菅墨
E Ig - ssueToResoliton 林
P L a 颤〉
n i t t
6 P: 01
IP0 主 业 务 流 包 括 : MW 流 程 、0R 流 程 、IPD 流 程
D
4 一
【结论】
pdf扫描件,只有比较大,比较粗的字能识别出来,颜色较淡的识别不出来
识别率:约%10
图5.

转化效果如下:
大 行 佳 孔 当 自 弼 不 。
。
巧 者 劳 而 春 者 忱 , 无 能 者 无 所 必 , 作 食 而 邀
游 , 陆 若 不 系 之 舟 。
。
Chacgyuisdt.
。
124565.
。
12256 dogdogunnn
。
。
【结论】
汉字、英文、数字混合
识别率:%60~%70
图6(天气网页截图)
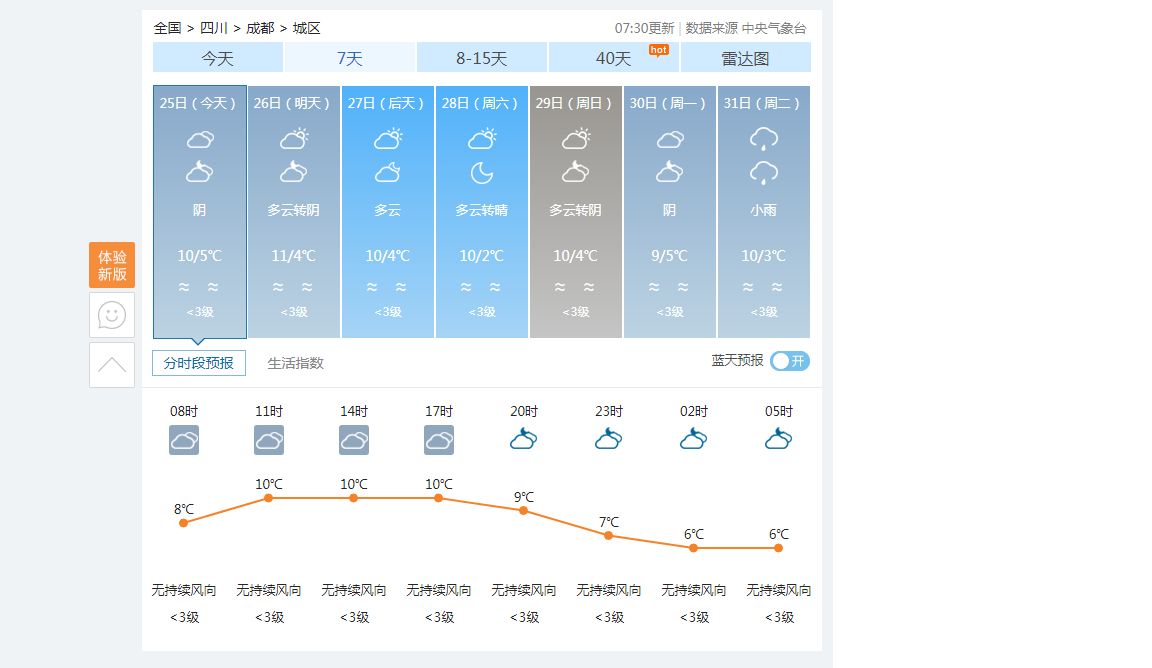
转换效果如下:
L f
全 国 > 囚 川 > 尿 膳 > 坂 区
今 夺 伟 8-15 天
llc/4rc
208 238 028 058
人 [ [ 92
s
c E E
无 RR 无 RR 无 RR 无 RR
< < < <
【结论】
背景颜色(蓝色,灰色,黑色、橙色);字体颜色(黑色、白色)。识别率:不到%10
图7.

转换效果如下:
机 器 人 餐 厅
cra arenzanmu nnanmes
seeu xraguagpt. ssepumes
人 吊 pahs ztpznaapsus anea
an sro an sessuassnet
e ssoangm crmazees aas
iusiaanorg.mmouz rpeae
snreenatesezur eeae t
+ngszensenapenecieme
矿 svapgzanohat
【结论】
75dpi,识别率:约为%5 【CoderBaby】
图8(电影字幕截图).

转换效果如下:
E
1 30
E
55
【结论】
背景颜色(渐变灰),字体为白色——识别率:%0
图9(古籍).

转换效果如下:
茂 长 万 灰 咆
恍 “ 望 泷 “ 松 驱
明 匹 一 图 抚 札 狐
东 非 “ 柳 一 吴
埕 跃 X“ 埋 煌 弟
仪 怀 坂 称 鸟 场 “
下 泊 聪 遇 林固 “
| 靴 犹 “
【结论】
竖排,古籍版 (需要“chi_tra.traineddata及“chi_tra_vert.traineddata”)——识别率:%0
图9(手机拍照图片).

转换效果如下:
在 中 国 , 餐 厅 里 的 菜 通 常 很 特 别 , 但 是 有 时 候 做 菜 和 服 务
的 人 也 很 特 别 : 不 久 前 昆 山 一 家 餐 厅 开 业 , 这 家 餐 厅 从 欢 迎 宰
人 、 点 菜 、 制 作 到 上 菜 , 大 部 分 工 作 都 由 机 器 人 完 成 。 餐 厅 经 理
宋 育 刚 对 他 的 “ 员 工 “ 很 满 意 。 这 些 机 咤 人 能 理 解 40 句 日 常 生
活 用 语 , 因 此 可 以 与 顾 客 交 流 。 让 宋 育 刚 最 满 意 的 是 , 他 的 这 些
员 工 们 既 不 会 生 病 也 不 会 请 假 。 充 电 两 个 小 时 后 , 它 们 就 又 能
投 入 使 用 了 , 因 此 它 们 要 比 普 通 员 工 优 秀 。 对 于 顾 客 来 说 , 技 术
水 平 有 没 有 达 到 能 使 这 些 机 蹇 人 厨 师 很 好 地 调 味 还 不 得 而 知 。
不 过 , 机 器 人 厨 师 倒 是 非 常 令 人 期 待 。
【结论】
手机拍照图片,还算清晰的——识别率:%100
转载请注明出处:https://www.cnblogs.com/NaughtyCat/p/tika-support-Tesseract-OCR-with-source-code-and-test-data.html
参考:
1)https://stackoverflow.com/questions/23792373/installing-tesseract-ocr-on-centos-6
2)http://www.zmonster.me/2015/04/17/tesseract-install-usage.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
*****************************************************************************************************
精力有限,想法太多,专注做好一件事就行
- 我只是一个程序猿。5年内把代码写好,技术博客字字推敲,坚持零拷贝和原创
- 写博客的意义在于打磨文笔,训练逻辑条理性,加深对知识的系统性理解;如果恰好又对别人有点帮助,那真是一件令人开心的事
*****************************************************************************************************
Tika结合Tesseract-OCR 实现光学汉字识别(简体、宋体的识别率百分之百)—附Java源码、测试数据和训练集下载地址的更多相关文章
- tesseract ocr文字识别Android实例程序和训练工具全部源代码
tesseract ocr是一个开源的文字识别引擎,Android系统中也可以使用.可以识别50多种语言,通过自己训练识别库的方式,可以大大提高识别的准确率. 为了节省大家的学习时间,现将自己近期的学 ...
- reCAPTCHA OCR 详解 , 验验证, OCR(光学自动识别)
WEB安全专题 reCAPTCHA的诞生及意义 CMU(卡耐基梅隆大学)设计了一个名叫reCAPTCHA的强大系统,让电脑去向人类求助.具体做法是:将OCR(光学自动识别)软件无法识别的文字扫 ...
- selenium使用笔记(二)——Tesseract OCR
在自动化测试过程中我们经常会遇到需要输入验证码的情况,而现在一般以图片验证码居多.通常我们处理这种情况应该用最简单的方式,让开发给个万能验证码或者直接将验证码这个环节跳过.之前在技术交流群里也跟朋友讨 ...
- Tesseract ocr 3.02学习记录一
光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程.OCR技术非常专业,一般多是印刷.打印行 ...
- text recognizer (OCR) Engine 光学字符识别
https://github.com/tesseract-ocr/tesseract/wiki https://github.com/UB-Mannheim/tesseract/wiki C:\Use ...
- Tesseract——OCR图像识别 入门篇
Tesseract——OCR图像识别 入门篇 最近给了我一个任务,让我研究图像识别,从我们项目的screenshot中识别文字信息,so我开始了学习,与大家分享下. 我看到目前OCR技术有很多,最主要 ...
- Tesseract Ocr引擎
Tesseract Ocr引擎 1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/t ...
- 开源图片文字识别引擎——Tesseract OCR
Tessseract为一款开源.免费的OCR引擎,能够支持中文十分难得.虽然其识别效果不是很理想,但是对于要求不高的中小型项目来说,已经足够用了. 文字识别可应用于许多领域,如阅读.翻译.文献资料的检 ...
- Python下Tesseract Ocr引擎及安装介绍
1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/tesseract,目前最新的源码 ...
随机推荐
- 2020牛客寒假算法基础集训营1 J. 缪斯的影响力 (矩阵快速幂/费马小定理降幂)
https://ac.nowcoder.com/acm/problem/200658 f(n) = f(n-1) * f(n-2) * ab ,f的第一项是x,第二项是y. 试着推出第三项是x·y·a ...
- Xlrd模块读取Excel文件数据
Xlrd模块使用 excel文件样例:
- 【动态规划】【C/C++】简单的背包问题
简单的背包问题 背包问题动态规划中非常经典的一个问题,本文只包含01背包,完全背包和多重背包.更加详尽的背包问题的讲解请参考崔添翼大神的<背包九讲> 简单的01背包 问题导入:新年到了,m ...
- SequoiaDB报告创建线程失败的解决办法
1.问题背景 对于分布式数据库和分布式环境,高并发和高性能压力的情况下,出现线程创建失败等等问题也是十分常见的,这时候就十分考虑数据库管理员的经验,需要能快速的定位到问题和瓶颈所在,快速解决.本文也是 ...
- Codeforces Round #602 (Div. 2, based on Technocup 2020 Elimination Round 3) A Math Problem
//只要从所有区间右端点的最小值覆盖到所有区间左端点的最大值即可 #include<iostream> using namespace std ; int x,y; int n; int ...
- Outlook365(Oulook2016 或2013) 写邮件输入收件人时的推荐联系人如何清理?
· 在Outlook365(Oulook2016 或2013) 中写邮件,输入收件人邮箱地址时,会出现“最近联系人” “其他建议”等推荐的联系人,可以方便选择.如果里面有很多邮箱地址的已经无效的话, ...
- CF399B Red and Blue Balls
题目 CF399B 洛谷RemoteJudge 思路 很容易发现,栈中靠上的蓝色球的出栈,对它下方的蓝色球没有影响. 举个例子: 第一步中靠上的蓝色球在第三步出栈了,这一过程对它下面的蓝色球(即第一步 ...
- [ZJOI2014] 力 - 多项式乘法 FFT
题意:给定 \({q_i}\),求 \[E_i = \sum_{i<j}{\frac{q_j}{(j-i)^2}} - \sum_{i>j}{\frac{q_j}{(j-i)^2}}\] ...
- DTW + python 矩阵操作 + debug
1. from here. diagonalReturn specified diagonals. diagflatCreate a 2-D array with the flattened inp ...
- C语言-字符串典型问题分析
1.典型问题一 下面的程序输出什么为什么? #include <stdio.h> int main() { ] = {}; char src[] = ...