《爬虫学习》(一)(HTTP协议)
Http请求:
1.在浏览器中发送一个http请求的过程:

2.url详解:
URL是Uniform Resource Locator的简写,统一资源定位符。 一个URL由以下几部分组成
scheme://host:port/path/?query-string=xxx#anchor
解析:

注意:写代码时,URL请求之中,中文必须转化为相对应的编码:%+16进制字符(例:何凯明=%E4%BD%95%E6%81%BA%E6%98%8E)
3.常用请求方法:
get请求:一般情况下,浏览器从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会使用get请求。
post请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生影响的时候会使用post请求。 以上是在网站开发中常用的两种方法。并且一般情况下都会遵循使用的原则。但是有的网站和服务器为了做反爬虫机制,也经常会不按常理出牌,有可能一个应该使用get方法的请求就一定要改成post请求,这个要视情况而定。
4.请求头以及参数:
在http协议中,向服务器发送一个请求,数据分为三部分,第一个是把数据放在url中,第二个是把数据放在body中(在post请求中),第三个就是把数据放在head中。这里介绍在网络爬虫中经常会用到的一些请求头参数:
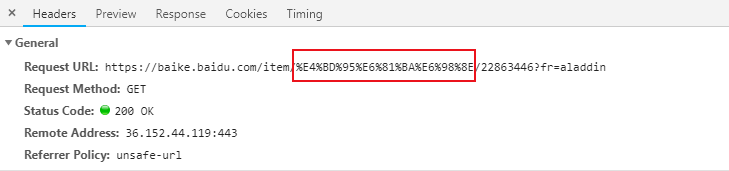
User-Agent:浏览器名称。这个在网络爬虫中经常会被使用到。请求一个网页的时候,服务器通过这个参数就可以知道这个请求是由哪种浏览器发送的。如果我们是通过爬虫发送请求,那么我们的User-Agent就是Python,这对于那些有反爬虫机制的网站来说,可以轻易的判断你这个请求是爬虫。因此我们要经常设置这个值为一些浏览器的值,来伪装我们的爬虫。
Referer:表明当前这个请求是从哪个url过来的。这个一般也可以用来做反爬虫技术。如果不是从指定页面过来的,那么就不做相关的响应。
Cookie:http协议是无状态的。也就是同一个人发送了两次请求,服务器没有能力知道这两个请求是否来自同一个人。因此这时候就用cookie来做标识。一般如果想要做登录后才能访问的网站,那么就需要发送cookie信息了。
5.状态码:

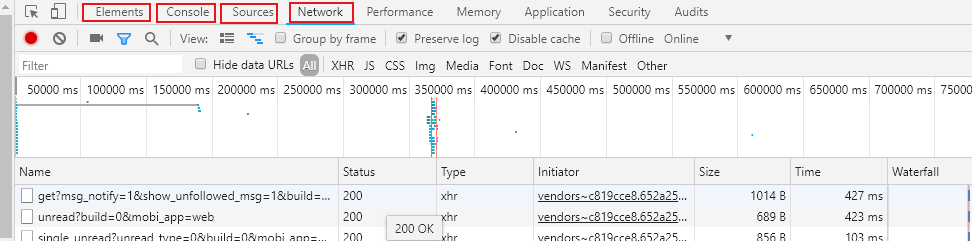
6.F12开发者工具:
Element整体布局
console一些js代码
source文件组成
network浏览器发送的请求
《爬虫学习》(一)(HTTP协议)的更多相关文章
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- HttpClient的使用-爬虫学习1
HttpClient的使用-爬虫学习(一) Apache真是伟大,为我们提供了HttpClient.jar,这个HttpClient是客户端的http通信实现库,这个类库的作用是接受和发送http报文 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- 爬虫学习之基于Scrapy的网络爬虫
###概述 在上一篇文章<爬虫学习之一个简单的网络爬虫>中我们对爬虫的概念有了一个初步的认识,并且通过Python的一些第三方库很方便的提取了我们想要的内容,但是通常面对工作当作复杂的需求 ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
随机推荐
- Pycharm常用快捷捷捷啊键= =
超多快捷键的其实,懒得都记住(主要是记不住……) 这里记录一下自己觉得用了确实会很省事的,特别是当你没有鼠标的时候 = = 超常用的 Ctrl + / 注释该行 Ctrl + D 复制该行到下一行 ...
- jQuery---jQuery初体验
jQuery初体验 1. 引入jquery文件 2. 入口函数标准 jQuery优点总结 (对应的就是js的缺点): 查找元素的方法多种多样,非常灵活 拥有隐式迭代特性,因此不需要手写for循环 完全 ...
- Vue组件中的Data为什么是函数。
简单点说,组件是要复用的,在很多地方都会调用. 如果data不是函数,而是属性,就又可能会发生多个地方的相同组件操作同一个Data属性,导致数据混乱. 而如果是函数,因为组件data函数的返回值是 ...
- Hibernate的理论知识点
转自网络 一. 对象持久化的理论 1.对象持久化:内存中的对象转存到外部持久设备上,在需要的时候还可以恢复. 2.对象持久化的原因(目标): 物理: 1) 内存不能持久,需要在硬盘上持久保存 //(物 ...
- js中迭代方法
基础遍历数组: for() for( in ) for(var i = 0;i<arr.length;i++){ ...
- js json -> <-object
1.利用原生JSON对象,将对象转为字符串 var jsObj = {}; jsObj.testArray = [1,2,3,4,5]; jsObj.name = 'CSS3'; jsObj.date ...
- Spring MVC3 + Ehcache 缓存实现
转自:http://www.coin163.com/it/490594393324999265/spring-ehcache Ehcache在很多项目中都出现过,用法也比较简单.一般的加些配置就可以了 ...
- 工具使用:xmind
概念 心智图,又称脑图.思维导图.灵感触发图.概念地图或思维地图,是一种图像式思维的工具与及一种利用图像式思考辅助工具来表达思维的工具. 详细的可以查看这里(维基百科)还有这里(百度百科) 用了思维导 ...
- js bug
1 加载模块脚本失败:服务器以非JavaScript MIME类型“text/html”响应. 描述:ES6 import Class时路径出错,少一个 / ,添上即可
- koa2第一天 安装koa2found 1 low severity vulnerability run `npm audit fix` to fix them, or `npm audit` for details
安装全局koa2:npm install -g koa2 -generator 创建一个koa2文件夹:koa2 -e koa2 进入koa2文件夹:cd koa2 安装npm模块:npm insta ...