第三十篇 玩转数据结构——字典树(Trie)
- Trie的形象化描述如下图:
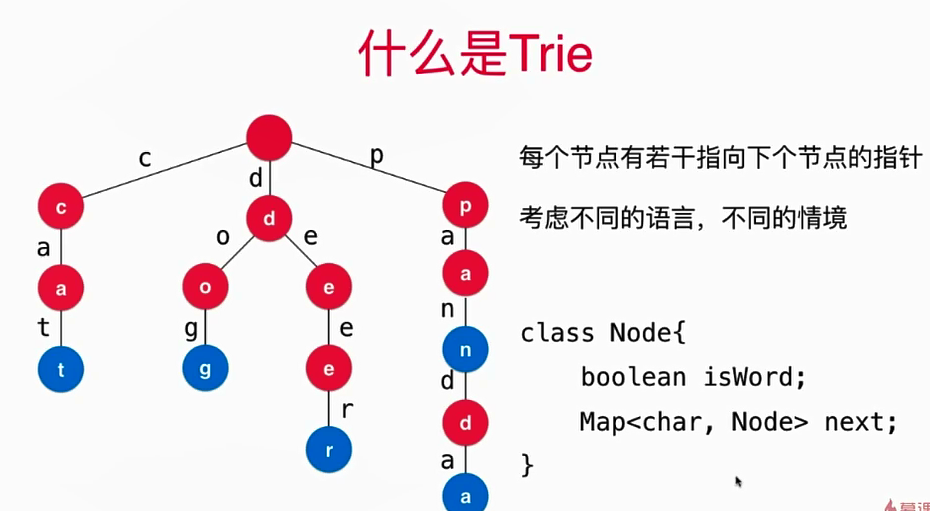
- Trie的优势和适用场景

- 实现Trie的业务无逻辑如下:
import java.util.TreeMap; public class Trie { private class Node { public boolean isWord;
public TreeMap<Character, Node> next; // 构造函数
public Node(boolean isWord) {
this.isWord = isWord;
next = new TreeMap<>();
} // 无参数构造函数
public Node() {
this(false);
}
} private Node root;
private int size; // 构造函数
public Trie() {
root = new Node();
size = 0;
} // 实现getSize方法,获得Trie中存储的单词数量
public int getSize() {
return size;
} // 实现add方法,向Trie中添加新的单词word
public void add(String word) { Node cur = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (cur.next.get(c) == null) {
cur.next.put(c, new Node());
}
cur = cur.next.get(c);
}
if (!cur.isWord) {
cur.isWord = true;
size++;
}
} // 实现contains方法,查询Trie中是否包含单词word
public boolean contains(String word) { Node cur = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (cur.next.get(c) == null) {
return false;
}
cur = cur.next.get(c);
}
return cur.isWord; // 好聪明
} // 实现isPrefix方法,查询Trie中时候保存了以prefix为前缀的单词
public boolean isPrefix(String prefix) { Node cur = root;
for (int i = 0; i < prefix.length(); i++) {
char c = prefix.charAt(i);
if (cur.next.get(c) == null) {
return false;
}
cur = cur.next.get(c);
}
return true;
}
}
3.. Trie和简单的模式匹配
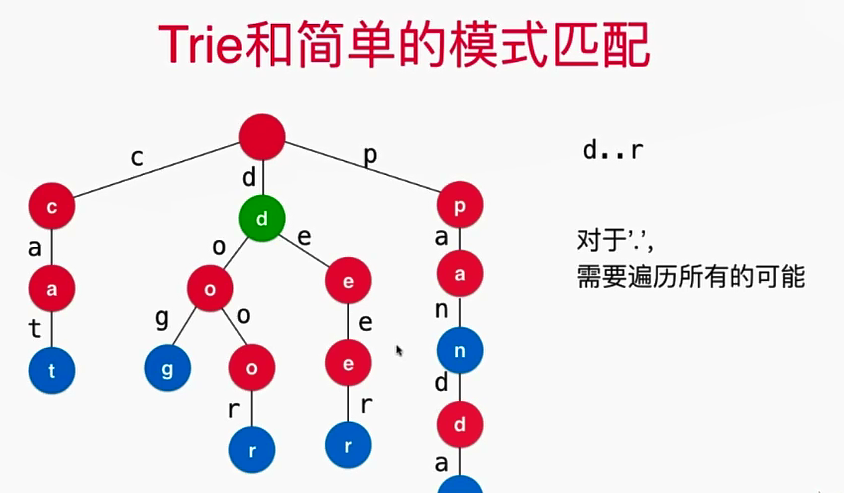
- 实现的业务逻辑如下:
import java.util.TreeMap; class WordDictionary { private class Node { public boolean isWord;
public TreeMap<Character, Node> next; public Node(boolean isWord) {
this.isWord = isWord;
next = new TreeMap<>();
} public Node() {
this(false);
} } /**
* Initialize your data structure here.
*/
private Node root; public WordDictionary() {
root = new Node();
} /**
* Adds a word into the data structure.
*/
public void addWord(String word) {
Node cur = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (cur.next.get(c) == null) {
cur.next.put(c, new Node());
}
cur = cur.next.get(c);
}
cur.isWord = true;
} /**
* Returns if the word is in the data structure. A word could contain the dot character '.' to represent any one letter.
*/
public boolean search(String word) {
return match(root, word, 0);
} private boolean match(Node node, String word, int index) {
if (index == word.length()) {
return node.isWord;
} char c = word.charAt(index);
if (c != '.') {
if (node.next.get(c) == null) {
return false;
}
return match(node.next.get(c), word, index + 1);
} else {
for (char nextChar : node.next.keySet()) {
if (match(node.next.get(nextChar), word, index + 1)) {
return true;
}
}
return false;
}
}
}
第三十篇 玩转数据结构——字典树(Trie)的更多相关文章
- 第三十二篇 玩转数据结构——AVL树(AVL Tree)
1.. 平衡二叉树 平衡二叉树要求,对于任意一个节点,左子树和右子树的高度差不能超过1. 平衡二叉树的高度和节点数量之间的关系也是O(logn) 为二叉树标注节点高度并计算平衡因子 AVL ...
- 第三十三篇 玩转数据结构——红黑树(Read Black Tree)
1.. 图解2-3树维持绝对平衡的原理: 2.. 红黑树与2-3树是等价的 3.. 红黑树的特点 简要概括如下: 所有节点非黑即红:根节点为黑:NULL节点为黑:红节点孩子为黑:黑平衡 4.. 实现红 ...
- 第三十一篇 玩转数据结构——并查集(Union Find)
1.. 并查集的应用场景 查看"网络"中节点的连接状态,这里的网络是广义上的网络 数学中的集合类的实现 2.. 并查集所支持的操作 对于一组数据,并查集主要支持两种操作:合并两 ...
- 第二十九篇 玩转数据结构——线段树(Segment Tree)
1.. 线段树引入 线段树也称为区间树 为什么要使用线段树:对于某些问题,我们只关心区间(线段) 经典的线段树问题:区间染色,有一面长度为n的墙,每次选择一段墙进行染色(染色允许覆盖),问 ...
- Java数据结构——字典树TRIE
又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种. 典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计. 它的优点是:利用字符串的公共 ...
- 模板 - 字符串/数据结构 - 字典树/Trie
使用静态数组的nxt指针的设计,大概比使用map作为nxt指针的设计要快1倍,但空间花费大概也大1倍.在数据量小的情况下,时间和空间效率都不及map<vector,int>.map< ...
- [POJ] #1002# 487-3279 : 桶排序/字典树(Trie树)/快速排序
一. 题目 487-3279 Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 274040 Accepted: 48891 ...
- Delphi 泛型(三十篇)
Delphi 泛型(三十篇)http://www.cnblogs.com/jxgxy/category/216671.html
- 字典树(Trie)详解
详解字典树(Trie) 本篇随笔简单讲解一下信息学奥林匹克竞赛中的较为常用的数据结构--字典树.字典树也叫Trie树.前缀树.顾名思义,它是一种针对字符串进行维护的数据结构.并且,它的用途超级广泛.建 ...
随机推荐
- 如何开发自己的第一个 Serverless Component
前言 上一篇 基于 Serverless Component 的全栈解决方案 介绍 Serverless Component 是什么和如何使用 Serverless Component 开发一个全栈应 ...
- JavaSE学习笔记(3)---面向对象三大特性
JavaSE学习笔记(3)---面向对象三大特性 面向对象的三大特征:继承.封装.多态 1.封装 面向对象编程语言是对客观世界的模拟,客观世界里成员变量都是隐藏在对象内部的,外界无法直接操作和修改.然 ...
- javascript当中arguments用法
8)arguments 例 3.8.1<head> <meta http-equiv="content-type" content="text/h ...
- Java第六节课总结
动手动脑: 多层的异常捕获-1:ArrayIndexOutOfBoundsException/内层try-catch发生ArithmeticException多层的异常捕获-2:ArrayIndexO ...
- 【HTML】html5 canvas全屏烟花动画特效
<!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF-8&quo ...
- 关于2008R2的序列号
windows server 2008 r2 企业版序列号 BX4WB-3WTB8-HCRC9-BFFG3-FW26F P63JV-9RWW2-DJW7V-RHTMT-W8KWJ MDB49-7MYG ...
- 全网最详细——Testlink在windows环境下搭建;提供环境下载
参考这篇文章,写的真不错https://www.jianshu.com/p/6c4321de26ea 工具下载 链接:https://pan.baidu.com/s/1_yzCIvsExbfzcRdl ...
- 《NVM-Express-1_4-2019.06.10-Ratified》学习笔记(5.2)-- Asynchronous Event Request command
5.2 异步事件请求命令 异步事件用于当状态.错误.健康信息这些事件发生时通知主机软件.为了使能这个controller报告的异步事件,主机软件需要提交一个或多个异步事件请求命令到controller ...
- 题解【AcWing10】有依赖的背包问题
题面 树形 DP 的经典问题. 我们设 \(dp_{i,j}\) 表示当前节点为 \(i\),当前节点的子树(包含当前节点)最多装的体积是 \(j\) 的最大价值. 我们遍历节点的过程就相当于做了一遍 ...
- PIE-SDK For C++栅格数据的金字塔创建
1.功能简介 金字塔可用于改善性能,可以加快栅格数据的显示速度.随着放大操作的进行,各个更精细的分辨率等级将逐渐得到绘制;但性能将保持不变:目前PIE SDK支持栅格数据的金字塔创建,下面对栅格数据格 ...