Quick BI 的模型设计与生成SQL原理剖析
一、摘要
随着物联网的告诉发展,数据量呈现井喷式的增长,如何来分析和使用这些数据,使数据产生商业价值,已经变得越来越重要。值得高兴的是,当前越来越多的人已经意识到了用数据分析决定商业策略的重要性,也都在进行着各行各业的数据分析。众所周知数据分析的核心是数据,为了更容易的分析数据,数据模型的设计需要遵循一定的规范。当前最流行的联机分析处理(OLAP)的规范为维度建模规范。本文介绍Quick BI如何进行维度建模,基于维度模型如何来自动化的生成分析查询的SQL语句,从而使数据分析变得更容易。
关键字: Quick BI、OLAP、维度建模、SQL
二、维度模型的分类
OLAP(On-line Analytical Processing,联机分析处理)根据存储数据的方式不同可以分为ROLAP、MOLAP、HOLAP。ROLAP表示基于关系数据库存储的OLAP实现(Relational OLAP),以关系数据库为核心,以关系型结构进行多维数据的表示和存储;MOLAP表示基于多维数据存储的OLAP实现(Multidimensional OLAP);HOLAP表示基于混合数据存储的OLAP实现(Hybrid OLAP),如低层用关系型数据库存储,高层是多维数组存储。接下来主要介绍基于关系型数据库的ROLAP的建模原理。
ROLAP将多维数据库中的表分为两类:事实表和维度表。事实表用于存储维度关键字和数值类型的事实数据,一般是围绕业务过程进行设计,例如:销售事实表,一般来存储用户在什么时间、地点购买了产品,销量和销售额等信息。维度表用于存储维度的详细数据,例如销售事实表中存储了产品维度的ID,产品维度表中存储产品的名称、品牌信息,两者通过产品ID进行关联。
ROLAP根据事实表、维度表间的关系,又可分为星型模型(Star Schema)、雪花模型(Snowflake Schema)。
1.星型模型
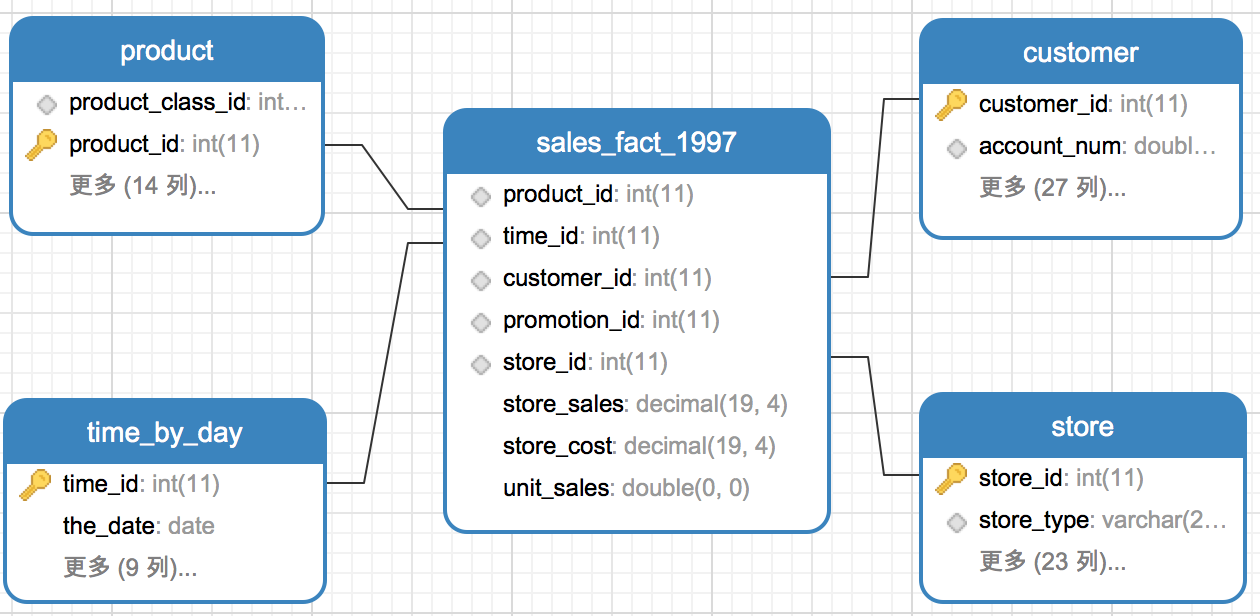
星型模型它由事实表(FactTable)和维表(DimensionTable)组成。事实表中的维度外键分别与相对应的维表中的主键相关联,关联之后由于形状看起来像是一个星星,所以形象的称为星型模型。以下示例为星型模型:其中sales_fact_1997为事实表,存储客户在某个时间、某个商店、购买了某个产品,购买量和销售额的信息,记录的是一个下单过程。事实表sales_fact_1997通过外键product_id、customer_id、time_id、store_id分别与维度表product(产品维表)、customer(客户维表)、time_by_day(时间维表)、store(商店维表)相关联,关联关系为多对一关联。
2.雪花模型
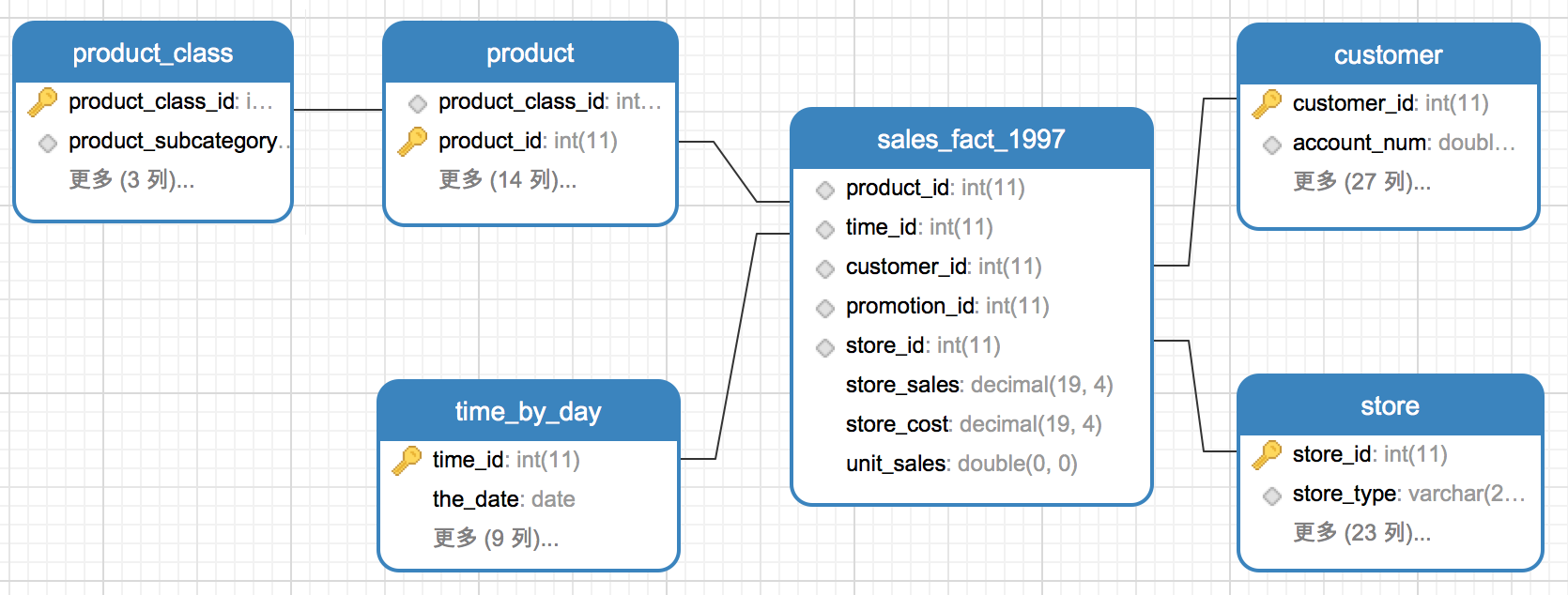
雪花模型是当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像一个雪花,故称雪花模型。下面示例product(产品)维度表与product_class(产品类别)维度表通过product_class_id相关联,关联关系为多对一。product_class没有与sales_fact_1997事实表直接关联。
三、基于ROLAP模型的SQL生成原理
模型构建好了后,接下来的重点就是针对分析需求来生成满足分析需要的SQL语句,然后将SQL语句下发到DB中来查询数据,返回分析结果。下面通过具体的需求场景来介绍如何生成SQL语句。
1.基于星型模型(或雪花模型)生成SQL
需求场景:
按日期、产品查看总的销售额、销售量,日期限定在1997年,总销售额限定在1000元以上,结果按照总的销售额倒序排列,看前5个。
2.生成SQL思路
1.分析需要用到的字段和表,目标是明确查询需要用到哪些表、表间关系、表上分组字段、聚合字段,确定SQL中select和from信息。
2.分析筛选条件,目标是明确SQL中where中需过滤的值。
3.分析分组维度,目标是明确SQL中group by的字段。
4.分析聚合后的筛选条件,目标是明确having中需要过滤的值。
5.分析需要排序的列和排序类型(升序还是降序)。
6.生成结果个数限制条件
7.根据以上信息生成查询SQL:
select 分组字段、聚合字段 from 表(含表关联) where 筛选条件 group by 分组维度 having 聚合后的筛选条件 order by 排序信息 结果条数限制。
3.生成SQL
按照上面的步骤,和本例子中的需求,分析查询中的关键信息(以下步骤与生成SQL思路中的步骤一一对应)
1.用到的分组字段:the_date、product_name, 其中分组字段the_date为日粒度,需处理为年粒度:DATE_FORMAT(`the_date` , '%Y')
聚合字段:store_sales、unit_sales,聚合方式都为sum;
用到的表:sales_fact_1997、product、time_by_day;
表间关系:sales_fact_1997. product_id= product. product_id
sales_fact_1997. time_id= time_by_day .time_id
2.筛选条件:
the_date`= STR_TO_DATE('1997-01-01 00:00:00' ,'%Y-%m-%d %H:%i:%s')
3.分组维度:DATE_FORMAT(`the_date` , '%Y')、product_name
4.聚合后的筛选条件:SUM(`store_sales`) > 1000
5.排序:order by 聚合后的别名 desc
6.限制结果个数:limit 0,5
7.生成的SQL如下
SELECT
DATE_FORMAT(TIME_T_4_.`the_date` , '%Y') AS TIME_THE_5_ ,
PRODUCT_T_2_.`product_name` AS PRODUCT_PRODUCT_6_ ,
SUM(SALES_T_1_.`store_sales`) AS SALES_STORE_7_ ,
SUM(SALES_T_1_.`unit_sales`) AS SALES_UNIT_8_
FROM
`quickbi_test`.`sales_fact_1997` AS SALES_T_1_
LEFT JOIN `quickbi_test`.`product` AS PRODUCT_T_2_ ON SALES_T_1_.`product_id` = PRODUCT_T_2_.`product_id`
LEFT JOIN `quickbi_test`.`time_by_day` AS TIME_T_4_ ON SALES_T_1_.`time_id` = TIME_T_4_.`time_id`
WHERE
四、附录-用到的表
下面罗列出以上示例中用到的表的建表语句,需要在 MySQL数据库下执行,其他类型数据库需要做一些调整。
1.sales_fact_1997表
CREATE TABLE `sales_fact_1997` (
`product_id` int(11) DEFAULT NULL,
`time_id` int(11) DEFAULT NULL,
`customer_id` int(11) DEFAULT NULL,
`promotion_id` int(11) DEFAULT NULL,
`store_id` int(11) DEFAULT NULL,
`store_sales` decimal(19,4) DEFAULT NULL,
`store_cost` decimal(19,4) DEFAULT NULL,
2.product表
CREATE TABLE `product` (
`product_class_id` int(11) DEFAULT '0',
`product_id` int(11) NOT NULL,
`brand_name` varchar(255) CHARACTER SET utf8 DEFAULT NULL,
`product_name` varchar(255) CHARACTER SET utf8 DEFAULT NULL,
`SKU` double DEFAULT NULL,
`SRP` decimal(19,4) DEFAULT '0.0000',
`gross_weight` float DEFAULT '0',
`net_weight` float DEFAULT '0',
`units_per_case` smallint(6) DEFAULT '0',
`cases_per_pallet` smallint(6) DEFAULT '0',
3.product_class表
CREATE TABLE `product_class` (
`product_class_id` int(11) NOT NULL,
`product_subcategory` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`product_category` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`product_department` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`product_family` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
4.time_by_day表
CREATE TABLE `time_by_day` (
`time_id` int(11) NOT NULL,
`the_date` date DEFAULT NULL,
`the_day` varchar(15) CHARACTER SET utf8 DEFAULT NULL,
`the_month` varchar(15) CHARACTER SET utf8 DEFAULT NULL,
`the_year` varchar(10) CHARACTER SET utf8 DEFAULT NULL,
`day_of_month` smallint(6) DEFAULT NULL,
`week_of_year` double DEFAULT NULL,
5.customer表
CREATE TABLE `customer` (
`customer_id` int(11) NOT NULL DEFAULT '0',
`account_num` double DEFAULT '0',
`lname` varchar(100) CHARACTER SET utf8 DEFAULT NULL,
`fname` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`mi` varchar(20) CHARACTER SET utf8 DEFAULT NULL,
`address1` varchar(100) CHARACTER SET utf8 DEFAULT NULL,
`city` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`state_province` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`postal_code` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`country` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`customer_region_id` int(11) DEFAULT '0',
`phone1` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`occupation` varchar(50) CHARACTER SET utf8 DEFAULT NU
6.store表
CREATE TABLE `store` (
`store_id` int(11) NOT NULL,
`store_type` varchar(255) CHARACTER SET utf8 DEFAULT NULL,
`region_id` int(11) DEFAULT '0',
`store_name` varchar(255) CHARACTER SET utf8 DEFAULT NULL,
`store_number` double DEFAULT NULL,
`store_street_address` varchar(255) CHARACTER SET utf8 DEFAULT NULL,
`store_city` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`store_state` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
`store_postal_code` varchar(50) CHARACTER SET utf8 DEFAULT NULL,
原文链接
更多技术干货 请关注阿里云云栖社区微信号 :yunqiinsight
Quick BI 的模型设计与生成SQL原理剖析的更多相关文章
- Quick BI的SQL传参建模可以用在什么场景
Quick B的SQL传参建模功能提供基于SQL的数据加工处理能力,减轻了IT支撑人员的工作量.在即席查询SQL中,我们用物理字段显示别名来表示参数的占位符,配置完占位符后,就可以在查询控件中进行参数 ...
- Quick BI 支持多种数据源进行多维分析
一.摘要 随着互联网的高速发展,数据量爆发式增长的同时,数据的存储形式也开始呈现出多样性,有结构化存储,如 Mysql, Oracle, SQLServer 等,半结构化甚至非结构化存储,如HBase ...
- Quick BI取数模型深度剖析
开发图表最关键的点在于选择准确的图表类型展示准确的数据,而准确的数据往往依赖于一个强大的取数模型,因此设计一个好的取数模型不仅可以解决数据安全的问题,更可以帮助每个访问者高效触达自己想要的数据,开发者 ...
- Quick BI 3.0 - 强大的多维分析表格:交叉表
写在开头 对于普通的表格展示数据,相信大家都非常熟悉了,今天给大家介绍的是BI领域的分析利器-交叉表,这个在BI分析场景中使用占比最多的分析利器.通过交叉表对数据的承载和管理,用户可以一目了然地分析出 ...
- Quick BI的复杂系统为例:那些年,我们一起做过的性能优化
背景 一直以来,性能都是技术层面不可避开的话题,尤其在中大型复杂项目中.犹如汽车整车性能,追求极速的同时,还要保障舒适性和实用性,而在汽车制造的每个环节.零件整合情况.发动机调校等等,都会最终影响用户 ...
- 46、Spark SQL工作原理剖析以及性能优化
一.工作原理剖析 1.图解 二.性能优化 1.设置Shuffle过程中的并行度:spark.sql.shuffle.partitions(SQLContext.setConf()) 2.在Hive数据 ...
- ASP.NET通过反射生成sql语句
最近对接一个接口,需要通过xml序列化成实体后添加额外信息后批量插入数据库,需要手动拼sql.因为涉及多张表,拼凑很麻烦而且容易出错,所以写了两个工具方法来生成sql,先写到博客里面,以便以后不时之需 ...
- Quick BI支持哪些数据源(配置操作篇)
Quick BI 潜心打造了核心技术底座(OLAP分析引擎),实现了SQL解析.SQL调度.SQL优化.查询加速等基础能力,支撑Quick BI的数据分析和查询加速.OLAP分析引擎包括数据源连接.数 ...
- Quick BI独创千人千面的行级权限管控机制
摘要 就数据访问权限而言,阿里巴巴以“被动式授权”为主,你需要什么权限就申请什么权限.但是,在客户交流过程中,我们发现绝大多数企业都是集中式授权,尤其是面向个人的行级权限管控,管理复杂度往往呈几何增长 ...
随机推荐
- thinkphp switch标签
用法: <switch name="变量" > <case value="值1" break="0或1">输出内容1 ...
- 扩展gcd求逆元
当模数为素数时可以用费马小定理求逆元. 模数为合数时,费马小定理大部分情况下失效,此时,只有与模数互质的数才有逆元(满足费马小定理的合数叫伪素数,讨论这个问题就需要新开一个博客了). (对于一个数n, ...
- D3.js+Es6+webpack构建人物关系图(力导向图)
功能列表:1. 增加下载SVG转PNG功能,图片尺寸超出可视区域也能够下载全部显示出来2. 增加图谱放大缩小平移功能3. 增加图谱初始化加载时自动缩放功能4. 增加导出excel功能,配合后台工具类达 ...
- 在core2.0中实现按程序集注入依赖
前言:在Autofac的使用中,提供了个种注入的API其中GetAssemblies()用着特别的舒坦. 1.core2.0也可以使用Autofac的包,但框架自身也提供了默认的注入Api,IServ ...
- 05_mybatis动态sql
1.sql片段 1.sql片段**** mybatis核心 对sql语句进行灵活操作,通过表达式进行判断,对sql进行灵活拼接.组装. 2.需求 用户信息综合查询列表和用户信息查询列表总数这两个sta ...
- CF875E Delivery Club
题意:两个邮递员,一个初始在s1,s2.需要依次给x1,x2,...,xn送快递.求所有时刻中两个邮递员的距离最大值的最小值.n<=100000,xi<=1e9. 标程: #include ...
- leetcode146周赛-1130-叶值的最小代价生成树*
题目描述: class Solution(object): def mctFromLeafValues(self, arr): """ :type arr: List[i ...
- index方法用于数据集的强制索引操作
index方法为3.2.3版本新增,用于数据集的强制索引操作,例如: $Model->index('user')->select(); 对查询强制使用user索引,user必须是数据表实际 ...
- ES6数组对象新增方法
1. Array.from() Array.from方法用于将两类对象转为真正的数组:类数组的对象( array-like object )和可遍历( iterable )的对象(包括 ES6 新增的 ...
- 我喜欢Mouding
我Smily喜欢Mouding