AdaBoost笔记之代码
最近要做二分类问题,先Mark一下知识点和代码,参考:Opencv2.4.9源码分析——Boosting 以下内容全部转自此文
一 原理
二 opencv源码
1、先看构建Boosting的参数:
CvBoostParams::CvBoostParams()
{
boost_type = CvBoost::REAL;
weak_count = ;
weight_trim_rate = 0.95;
cv_folds = ;
max_depth = ;
}
CvBoostParams::CvBoostParams( int _boost_type, int _weak_count,
double _weight_trim_rate, int _max_depth,
bool _use_surrogates, const float* _priors )
{
boost_type = _boost_type;
weak_count = _weak_count;
weight_trim_rate = _weight_trim_rate;
split_criteria = CvBoost::DEFAULT; //分叉准则,即用什么方法计算决策树节点的纯度
/*****************************
CvBoost::DEFAULT为特定的Boosting算法选择默认系数
CvBoost::GINI使用基尼指数,这是Real AdaBoost的默认方法,也可以被用于Discrete Adaboost
CvBoost::MISCLASS使用错误分类率,这是Discrete Adaboost的默认方法,也可以被用于Real AdaBoost
CvBoost::SQERR使用最小二乘准则,这是LogitBoost和Gentle AdaBoost的默认及唯一方法
******************************/
cv_folds = ; //表示构建决策树时,不执行剪枝操作
max_depth = _max_depth;
use_surrogates = _use_surrogates;
priors = _priors;
}
其中参数的含义为:
boost_type表示Boosting算法的类型,可以是CvBoost::DISCRETE、CvBoost::REAL、CvBoost::LOGIT或CvBoost::GENTLE这4类中的任意一个,OpenCV推荐使用GentleAdaBoost或Real AdaBoost算法
_weak_count表示弱分类器的数量,即迭代的次数
_weight_trim_rate表示裁剪率,在0~1之间,默认值为0.95,在迭代过程中,那些归一化后的样本权值wi(m)小于该裁剪率的样本将不进入下次迭代
_max_depth表示构建决策树的最大深度
_use_surrogates表示在构建决策树时,是否使用替代分叉属性
_priors表示样本的先验概率
2、CvBoost类的两个构造函数:
CvBoost::CvBoost( const Mat& _train_data, int _tflag,
const Mat& _responses, const Mat& _var_idx,
const Mat& _sample_idx, const Mat& _var_type,
const Mat& _missing_mask,
CvBoostParams _params )
//_train_data训练的样本数据
//_tflag训练数据的特征属性类型,如果为CV_ROW_SAMPLE,表示样本是以行的形式储存的,即_train_data矩阵的每一行为一个样本(或特征矢量);如果为CV_COL_SAMPLE,表示样本是以列的形式储存的
//_responses分类的结果,即分类的响应值
//_var_idx标识感兴趣的特征属性,即真正用于训练的那些特征属性,该值的形式与_sample_idx变量相似
//_sample_idx标识感兴趣的样本,即真正用于训练的样本,该值必须是一维矩阵的形式,即矢量的形式,并且类型必须是8UC1、8SU1或者32SC1。如果为8UC1或8SU1,则该值的含义是用掩码的形式表示对应的样本,即0表示不感兴趣的样本,其他数为感兴趣的样本,因此矢量的元素数量必须与训练样本数据_train_data的样本数一致;如果为32SC1,则该值的含义是那些感兴趣的样本的索引,而不感兴趣的样本的索引不在该矢量中出现,因此该矢量的元素数量可以小于或等于_train_data的样本数
//_var_type特征属性的形式,是类的形式还是数值的形式,用掩码的形式表现对应特征属性的形式,0表示为数值的形式,1表示为类的形式。该值必须是一维矩阵,并且元素的数量必须是真正用于训练的那些特征属性的数量加1,多余的一个元素表示的是响应值的形式,即是分类树还是回归树
//_missing_mask缺失的特征属性,用掩码的形式表现对应的特征属性,0表示没有缺失,而且必须与_train_data的矩阵尺寸大小一致
//_params为构建Boosting的参数
{
// CvSeq* weak,用于保存决策树,即最终的强分类器
weak = ;
// CvDTreeTrainData* data,所训练的样本数据
data = ;
// const char* default_model_name,该机器学习的模型名称
default_model_name = "my_boost_tree";
//所有变量的类型都为CvMat*
// active_vars表示那些对决策树的分叉起到作用的特征属性的索引值,该索引值是只相对于参与训练决策树的那些特征属性
// active_vars_abs表示那些对决策树的分叉起到作用的特征属性的索引值,但与active_vars变量不同,该索引值是针对所有的特征属性
// orig_response训练样本的原始响应值,即样本的分类,为-1或1
// sum_response弱分类器线性组合后的样本输出分类,即强分类器的分类结果
// weak_eval:弱分类器的分类评估结果,即弱分类器的响应值
// subsample_mask训练样本集的掩码集,即每一个样本都有一个掩码,当该值为0时,该样本被去掉,训练的时候不使用该样本
//weights每个训练样本数据的权值,即wi(m)
// subtree_weights每个决策树所应用的样本权值,它的值虽然也是wi(m),但样本的顺序与weights不同,即subtree_weights针对的是具体决策树
active_vars = active_vars_abs = orig_response = sum_response = weak_eval =
subsample_mask = weights = subtree_weights = ;
//AdaBoost训练
train( _train_data, _tflag, _responses, _var_idx, _sample_idx,
_var_type, _missing_mask, _params );
}
CvBoost::CvBoost()
{
data = ;
weak = ;
default_model_name = "my_boost_tree"; active_vars = active_vars_abs = orig_response = sum_response = weak_eval =
subsample_mask = weights = subtree_weights = ;
have_active_cat_vars = have_subsample = false; clear(); //清空一些参数
}
3、两个train函数:
bool CvBoost::train( CvMLData* _data, //训练样本数据
CvBoostParams _params, //构建Boosting的参数
bool update )
//update表示是更新分类器,还是重新创建分类器,默认是false,表示重新创建
{
bool result = false; CV_FUNCNAME( "CvBoost::train" ); __BEGIN__;
//从_data变量中提取各类数据
const CvMat* values = _data->get_values();
const CvMat* response = _data->get_responses();
const CvMat* missing = _data->get_missing();
const CvMat* var_types = _data->get_var_types();
const CvMat* train_sidx = _data->get_train_sample_idx();
const CvMat* var_idx = _data->get_var_idx();
//调用另一个train函数
CV_CALL( result = train( values, CV_ROW_SAMPLE, response, var_idx,
train_sidx, var_types, missing, _params, update ) ); __END__; return result;
} bool
CvBoost::train( const CvMat* _train_data, int _tflag,
const CvMat* _responses, const CvMat* _var_idx,
const CvMat* _sample_idx, const CvMat* _var_type,
const CvMat* _missing_mask,
CvBoostParams _params, bool _update )
{
bool ok = false; //算法训练正确与否的标识变量
//定义一段内存空间
CvMemStorage* storage = ; CV_FUNCNAME( "CvBoost::train" ); __BEGIN__; int i;
//调用CvBoost::set_params()函数,设置并判断Boosting参数的正确性
set_params( _params );
//释放active_vars和active_vars_abs矩阵变量
cvReleaseMat( &active_vars );
cvReleaseMat( &active_vars_abs ); if( !_update || !data ) //需要重新建立分类器,或者没有训练样本数据
{
//调用CvBoost::clear()函数,清空一些参数
clear();
//实例化CvDTreeTrainData类,并通过set_data函数设置决策树的训练样本数据,倒数第二个参数表示是否共享决策树,最后一个参数表示是否可以添加分类标签,该参数实现了把决策树中用于交叉验证的子集空间用于存储每个决策树的样本权值的目的
data = new CvDTreeTrainData( _train_data, _tflag, _responses, _var_idx,
_sample_idx, _var_type, _missing_mask, _params, true, true );
//确保Boosting只能用于两类问题
if( data->get_num_classes() != )
CV_ERROR( CV_StsNotImplemented,
"Boosted trees can only be used for 2-class classification." );
//创建一块内存空间,用于存储决策树weak
CV_CALL( storage = cvCreateMemStorage() );
//为AdaBoost创建一个序列
weak = cvCreateSeq( , sizeof(CvSeq), sizeof(CvBoostTree*), storage );
storage = ;
}
else //否则,为训练样本数据赋值
{
data->set_data( _train_data, _tflag, _responses, _var_idx,
_sample_idx, _var_type, _missing_mask, _params, true, true, true );
}
//如果AdaBoost算法的类型为Logit AdaBoost或Gentle AdaBoost,则生成一个样本响应值的副本
if ( (_params.boost_type == LOGIT) || (_params.boost_type == GENTLE) )
data->do_responses_copy();
//这里是第一次调用CvBoost::update_weights()函数,因此它的作用是初始化权值,该函数在后面有详细的介绍
update_weights( );
//执行AdaBoost算法,进行M次迭代
for( i = ; i < params.weak_count; i++ )
{
//定义一个弱分类器,它是用决策树的方法得到的
CvBoostTree* tree = new CvBoostTree;
//用决策树的方法训练得到一个弱分类器,如果训练失败,则退出迭代循环,CvBoostTree类中的train函数在后面给出详细的介绍,其中参数subsample_mask表示样本数据的掩码,如果样本数据相应位的值为1,则表示该样本可用,如果为0,则不可用
if( !tree->train( data, subsample_mask, this ) )
{
delete tree; //删除该弱分类器
break; //退出循环
}
//cvCheckArr( get_weak_response()); //检查该弱分类器的输出响应
//把得到的弱分类器tree添加进强分类器weak队列中
cvSeqPush( weak, &tree );
//更新权值,以备下次迭代循环之用
update_weights( tree );
//裁剪去掉那些权值wi(m+1)太小的训练样本数据
trim_weights();
//计算样本中没有被置1的数量,如果为零,则说明下次迭代将没有训练样本
if( cvCountNonZero(subsample_mask) == )
break; //退出迭代
} if(weak->total > ) //得到了若干个弱分类器
{
//计算active_vars和condensed_idx变量,这两个变量在预测时要用到,该函数的详细介绍在后面
get_active_vars(); // recompute active_vars* maps and condensed_idx's in the splits.
data->is_classifier = true; //重新赋值
data->free_train_data(); //释放一些矩阵变量
ok = true; //标识变量
}
else //没有得到弱分类器
clear(); //清空一些参数 __END__;
//得到了Boosting分类器,返回true,否则返回false
return ok;
}
4、更新权值函数,当要初始化权值时,参数tree为0,表示此时还没有弱分类器:
void
CvBoost::update_weights( CvBoostTree* tree ) {
double initial_weights[] = { , }; //该变量只有在初始化权值时用到
update_weights_impl( tree, initial_weights );
}
更新权值的核心函数:
void
CvBoost::update_weights_impl( CvBoostTree* tree, double initial_weights[] )
{
CV_FUNCNAME( "CvBoost::update_weights_impl" ); __BEGIN__;
//n表示训练样本的数量
int i, n = data->sample_count;
double sumw = .; //表示权值的和,权值归一化时要用
int step = ;
float* fdata = ;
int *sample_idx_buf;
const int* sample_idx = ;
cv::AutoBuffer<uchar> inn_buf;
//根据AdaBoost类型的不同,定义不同大小的缓存,Discrete和Real时为0,LogitBoost和Gentle时为所有训练样本的数据长度,存储着样本响应值的副本
size_t _buf_size = (params.boost_type == LOGIT) || (params.boost_type == GENTLE) ? (size_t)(data->sample_count)*sizeof(int) : ;
if( !tree ) //初始化权值,因为此时还没有弱分类器
_buf_size += n*sizeof(int); //增加_buf_size的大小,增加的长度为所有训练样本的数据长度,存储着样本响应值
else //训练样本的迭代过程中
{
//如果发生了样本裁剪,则_buf_size的增加长度为没有被裁剪掉的样本数据长度,即此次迭代中真正用到的那些样本的数据长度,存储的内容为该次迭代的训练样本数据的响应值
if( have_subsample )
_buf_size += data->get_length_subbuf()*(sizeof(float)+sizeof(uchar));
}
//为inn_buf分配_buf_size大小的内存空间
inn_buf.allocate(_buf_size);
// cur_buf_pos指向inn_buf的空间的首地址
uchar* cur_buf_pos = (uchar*)inn_buf;
//如果是LogitBoost和Gentle类型
if ( (params.boost_type == LOGIT) || (params.boost_type == GENTLE) )
{
//得到步长
step = CV_IS_MAT_CONT(data->responses_copy->type) ?
: data->responses_copy->step / CV_ELEM_SIZE(data->responses_copy->type);
fdata = data->responses_copy->data.fl; //指向样本响应值的副本
sample_idx_buf = (int*)cur_buf_pos; //指向inn_buf空间
// cur_buf_pos指向此次迭代训练的样本数据的首地址
cur_buf_pos = (uchar*)(sample_idx_buf + data->sample_count);
//得到训练样本序列索引
sample_idx = data->get_sample_indices( data->data_root, sample_idx_buf );
}
// dtree_data_buf指向训练数据的内存首地址,训练数据是以矩阵的形式进行存储的
CvMat* dtree_data_buf = data->buf;
// length_buf_row表示当前训练样本的数量,因为并不是所有的样本都用于本次迭代,有一些样本被剪切掉了
size_t length_buf_row = data->get_length_subbuf();
//进入if的条件是在第一次迭代之前,即还没有弱分类器的时候,它的作用是初始化一些变量和参数
if( !tree ) // before training the first tree, initialize weights and other parameters
{
// class_labels_buf表示分类结果,即响应值
int* class_labels_buf = (int*)cur_buf_pos;
// cur_buf_pos指向另一块内存空间
cur_buf_pos = (uchar*)(class_labels_buf + n);
//得到训练样本的响应值,也就是样本的分类结果
const int* class_labels = data->get_class_labels(data->data_root, class_labels_buf);
// in case of logitboost and gentle adaboost each weak tree is a regression tree,
// so we need to convert class labels to floating-point values
//由于LogitBoost和Gentle需要浮点型的数据,构建它们的弱分类器的决策树是回归树,所以需要重新定义一些变量,因为这些变量在初始化时都是整型的
//w0用于初始化权值wi(1)
double w0 = ./n;
// p[2] = { 1, 1 },表示两类问题的先验概率
double p[] = { initial_weights[], initial_weights[] };
//释放、重新分配一些矩阵
cvReleaseMat( &orig_response );
cvReleaseMat( &sum_response );
cvReleaseMat( &weak_eval );
cvReleaseMat( &subsample_mask );
cvReleaseMat( &weights );
cvReleaseMat( &subtree_weights );
//重新定义一些矩阵
CV_CALL( orig_response = cvCreateMat( , n, CV_32S ));
CV_CALL( weak_eval = cvCreateMat( , n, CV_64F ));
CV_CALL( subsample_mask = cvCreateMat( , n, CV_8U ));
CV_CALL( weights = cvCreateMat( , n, CV_64F ));
CV_CALL( subtree_weights = cvCreateMat( , n + , CV_64F ));
//如果在设置Boosting参数的时候设置了_priors值,并且AdaBoost算法为Discrete Adaboost或Real AdaBoost,则表示样本属性有先验概率,即have_priors为true,则需要根据训练样本的数量计算先验概率,具体内容见上一篇关于决策树的介绍
if( data->have_priors )
{
// compute weight scale for each class from their prior probabilities
//根据_priors值计算两类问题的两个分类结果的先验概率
int c1 = ;
//样本的分类class_labels,即响应值,只能为0或者为1
for( i = ; i < n; i++ )
c1 += class_labels[i]; //统计响应值为1的样本数量
//响应值为0的先验概率
p[] = data->priors->data.db[]*(c1 < n ? ./(n - c1) : .);
//响应值为1的先验概率
p[] = data->priors->data.db[]*(c1 > ? ./c1 : .);
//归一化p[0]和p[1]
p[] /= p[] + p[];
p[] = . - p[];
} if (data->is_buf_16u) //训练样本数量小于65536个,即可以用一个unsigned short数据类型表示该数量
{
// data->get_cv_labels函数访问的就是labels指向的空间,表示全体样本索引与构建决策树的样本索引的映射关系
unsigned short* labels = (unsigned short*)(dtree_data_buf->data.s + data->data_root->buf_idx*length_buf_row +
data->data_root->offset + (data->work_var_count-)*data->sample_count);
//遍历所有样本数据
for( i = ; i < n; i++ )
{
// save original categorical responses {0,1}, convert them to {-1,1}
//原始数据的响应值为0或1,我们要把它转换为-1或1的形式
// 0 × 2 – 1 = -1;1 × 2 - 1 = 1
orig_response->data.i[i] = class_labels[i]* - ;
// make all the samples active at start.
// later, in trim_weights() deactivate/reactive again some, if need
//第一次开始训练的时候,所有样本数据都应该被使用,所以样本对应的掩码都为1,表示可以使用,而在训练迭代的过程中,也许会有一些样本通过trim_weights()函数被裁剪掉,这时该样本的掩码就要为0
subsample_mask->data.ptr[i] = (uchar);
// make all the initial weights the same.
//初始化每个样本数据的权值,即步骤2。class_labels[i]不是为0就是为1,而在没有先验分类概率的情况下p[0]和p[1]都为1,即前面原理分析中步骤2的每个样本数据的权值为1/n;而在有先验分类概率的情况下,每个样本数据的权值还要根据响应值用先验概率p[0]或p[1]再乘以1/n
weights->data.db[i] = w0*p[class_labels[i]];
// set the labels to find (from within weak tree learning proc)
// the particular sample weight, and where to store the response.
//顺序存储样本的索引值,即得到一种映射关系
labels[i] = (unsigned short)i;
}
}
else //样本数据大于65536个,则需要用一个int数据类型表示
{
int* labels = dtree_data_buf->data.i + data->data_root->buf_idx*length_buf_row +
data->data_root->offset + (data->work_var_count-)*data->sample_count; for( i = ; i < n; i++ )
{
// save original categorical responses {0,1}, convert them to {-1,1}
orig_response->data.i[i] = class_labels[i]* - ;
// make all the samples active at start.
// later, in trim_weights() deactivate/reactive again some, if need
subsample_mask->data.ptr[i] = (uchar);
// make all the initial weights the same.
weights->data.db[i] = w0*p[class_labels[i]];
// set the labels to find (from within weak tree learning proc)
// the particular sample weight, and where to store the response.
labels[i] = i;
}
} if( params.boost_type == LOGIT ) //LogitBoost类型
{
CV_CALL( sum_response = cvCreateMat( , n, CV_64F )); //定义矩阵
//遍历所有样本,初始化变量
for( i = ; i < n; i++ )
{
sum_response->data.db[i] = ; //清零
//如果样本的响应值为1,则该样本对应的响应值副本为2;如果响应值不为1,则为-2
fdata[sample_idx[i]*step] = orig_response->data.i[i] > ? .f : -.f;
} // in case of logitboost each weak tree is a regression tree.
// the target function values are recalculated for each of the trees
data->is_classifier = false; // LogitBoost类型应用的是回归树
}
else if( params.boost_type == GENTLE ) // Gentle AdaBoost类型
{
//遍历所有样本,初始化变量
for( i = ; i < n; i++ )
//样本的响应值副本的值与原始响应值一致
fdata[sample_idx[i]*step] = (float)orig_response->data.i[i]; data->is_classifier = false; // Gentle AdaBoost类型应用的是回归树
}
}
else //真正进入循环迭代,更新权值的过程
{
// at this moment, for all the samples that participated in the training of the most
// recent weak classifier we know the responses. For other samples we need to compute them
//在上一次迭代中,如果利用的裁剪后的样本数据,说明有一些样本被裁剪掉而没有它们的弱分类器(即决策树)的响应值,但在后更新权值时,是需要所有的训练样本数据,因此这里我们通过构建好的决策树来预测这些裁剪掉的样本,从而得到它们的响应值
if( have_subsample ) //有训练样本被掩码裁剪掉
{
// values表示需要预测的样本数据
float* values = (float*)cur_buf_pos;
// values空间的长度为本次迭代训练样本的实际长度
cur_buf_pos = (uchar*)(values + data->get_length_subbuf());
uchar* missing = cur_buf_pos; //missing表示样本缺失特征属性的掩码
// cur_buf_pos再次指向一段内存空间
cur_buf_pos = missing + data->get_length_subbuf() * (size_t)CV_ELEM_SIZE(data->buf->type); CvMat _sample, _mask; // invert the subsample mask
//保留的样本掩码为1,裁剪掉的为0,现在反转掩码,即保留的为0,裁剪掉的为1
cvXorS( subsample_mask, cvScalar(.), subsample_mask );
//得到裁剪掉的样本数据
data->get_vectors( subsample_mask, values, missing, );
//定义矩阵
_sample = cvMat( , data->var_count, CV_32F ); //表示裁剪掉的样本
_mask = cvMat( , data->var_count, CV_8U ); //表示对应样本所缺失的特征 // run tree through all the non-processed samples
//遍历所有样本,但只处理那些被裁剪掉的样本
for( i = ; i < n; i++ )
if( subsample_mask->data.ptr[i] ) //被裁剪掉的样本数据
{
_sample.data.fl = values; //赋值
_mask.data.ptr = missing; //赋值
values += _sample.cols; //指向下一个样本
missing += _mask.cols; //指向下一个样本
//通过预测得到被裁剪掉的样本的弱分类器的响应值
weak_eval->data.db[i] = tree->predict( &_sample, &_mask, true )->value;
}
} // now update weights and other parameters for each type of boosting
//根据不同类型更新权值
if( params.boost_type == DISCRETE ) //Discrete Adaboost类型
{
// Discrete AdaBoost:
// weak_eval[i] (=f(x_i)) is in {-1,1}
// err = sum(w_i*(f(x_i) != y_i))/sum(w_i)
// C = log((1-err)/err)
// w_i *= exp(C*(f(x_i) != y_i)) double C, err = .;
double scale[] = { ., . };
//遍历所有样本数据
for( i = ; i < n; i++ )
{
//得到上次迭代后每个训练样本数据的权值,即wi(m)
double w = weights->data.db[i];
//权值之和,即式9中的分母部分
sumw += w;
//分类器分类错误的那些训练样本数据的权值之和,即式9中的分子部分
// weak_eval表示该次迭代的弱分类器的分类结果,orig_response为实际的分类结果,weak_eval->data.db[i] != orig_response->data.i[i]的作用是判断分类是否正确,正确为0,错误为1
err += w*(weak_eval->data.db[i] != orig_response->data.i[i]);
}
//得到误差率,即式9
if( sumw != )
err /= sumw;
//log_ratio(x)为内嵌函数,该函数的输出为ln[x/(1-x)]
//C和err的值为式13,C表示该次迭代得到的弱分类器的权值,即αm
C = err = -log_ratio( err );
// scale[1]为式10中括号内的部分,该值肯定大于1,而此时scale[0]仍然为1
scale[] = exp(err); sumw = ;
//再次遍历训练样本数据,更新样本权值wi(m+1)
for( i = ; i < n; i++ )
{
//分类正确为scale[0],分类错误为scale[1],即式14
double w = weights->data.db[i]*
scale[weak_eval->data.db[i] != orig_response->data.i[i]];
sumw += w; //权值之和,后面归一化要用
weights->data.db[i] = w; //赋值
}
//为弱分类器的权值赋值,即该决策树tree的每节点值都乘以C,也就是得到了式12的αmkm(x)
tree->scale( C );
}
else if( params.boost_type == REAL ) // Real AdaBoost类型
{
// Real AdaBoost:
// weak_eval[i] = f(x_i) = 0.5*log(p(x_i)/(1-p(x_i))), p(x_i)=P(y=1|x_i)
// w_i *= exp(-y_i*f(x_i))
//weak_eval变量在计算前为弱分类器km(x),但在遍历循环后被赋予新的含义,为式16中的e指数中的指数部分
for( i = ; i < n; i++ )
weak_eval->data.db[i] *= -orig_response->data.i[i];
//计算式16的e指数
cvExp( weak_eval, weak_eval );
//遍历训练样本数据,更新权值wi(m)
for( i = ; i < n; i++ )
{
//式16,得到权值wi(m+1)
double w = weights->data.db[i]*weak_eval->data.db[i];
sumw += w; //权值之和,后面归一化要用
weights->data.db[i] = w; //赋值
}
}
else if( params.boost_type == LOGIT ) //LogitBoost类型
{
// LogitBoost:
// weak_eval[i] = f(x_i) in [-z_max,z_max]
// sum_response = F(x_i).
// F(x_i) += 0.5*f(x_i)
// p(x_i) = exp(F(x_i))/(exp(F(x_i)) + exp(-F(x_i))=1/(1+exp(-2*F(x_i)))
// reuse weak_eval: weak_eval[i] <- p(x_i)
// w_i = p(x_i)*1(1 - p(x_i))
// z_i = ((y_i+1)/2 - p(x_i))/(p(x_i)*(1 - p(x_i)))
// store z_i to the data->data_root as the new target responses const double lb_weight_thresh = FLT_EPSILON;
const double lb_z_max = .;
/*float* responses_buf = data->get_resp_float_buf();
const float* responses = 0;
data->get_ord_responses(data->data_root, responses_buf, &responses);*/ /*if( weak->total == 7 )
putchar('*');*/ for( i = ; i < n; i++ )
{
//式22
double s = sum_response->data.db[i] + 0.5*weak_eval->data.db[i];
sum_response->data.db[i] = s; //赋值
weak_eval->data.db[i] = -*s; //该变量式21要用
}
//计算e指数
cvExp( weak_eval, weak_eval );
//遍历所有训练样本数据
for( i = ; i < n; i++ )
{
//式21,得到更新后的pm(xi)
double p = ./(. + weak_eval->data.db[i]);
//w为权值wi(m),式20
double w = p*( - p), z;
//确保w是具有一定意义的正数
w = MAX( w, lb_weight_thresh );
weights->data.db[i] = w; //权值赋值
sumw += w; //权值之和,后面归一化要用
//计算工作响应zi(m)
if( orig_response->data.i[i] > ) //样本数据属于y = 1的一类
{
z = ./p;
fdata[sample_idx[i]*step] = (float)MIN(z, lb_z_max);
}
else //样本数据属于y = -1的一类
{
z = ./(-p);
fdata[sample_idx[i]*step] = (float)-MIN(z, lb_z_max);
}
}
}
else //Gentle AdaBoost类型
{
// Gentle AdaBoost:
// weak_eval[i] = f(x_i) in [-1,1]
// w_i *= exp(-y_i*f(x_i))
//确保为Gentle AdaBoost类型
assert( params.boost_type == GENTLE );
//计算式24中e指数中的指数部分
for( i = ; i < n; i++ )
weak_eval->data.db[i] *= -orig_response->data.i[i];
//计算式24中的e指数
cvExp( weak_eval, weak_eval ); for( i = ; i < n; i++ )
{
//式24,更新权值
double w = weights->data.db[i] * weak_eval->data.db[i];
weights->data.db[i] = w; //赋值
sumw += w; //权值之和,后面归一化要用
}
}
} // renormalize weights
//归一化权值wi(m+1)
if( sumw > FLT_EPSILON )
{
sumw = ./sumw;
for( i = ; i < n; ++i )
weights->data.db[i] *= sumw;
} __END__;
}
5、裁剪去掉那些权值过小的样本数据:
void CvBoost::trim_weights()
{
//CV_FUNCNAME( "CvBoost::trim_weights" ); __BEGIN__;
//count为训练样本总数,nz_count表示裁剪以后保留下来的样本总数
int i, count = data->sample_count, nz_count = ;
double sum, threshold;
//裁剪率weight_trim_rate要在0和1之间
if( params.weight_trim_rate <= . || params.weight_trim_rate >= . )
EXIT; // use weak_eval as temporary buffer for sorted weights
//样本权值weights暂时保存到weak_eval中,以便用于对其进行排序
cvCopy( weights, weak_eval );
//对样本权值按由小到大的顺序进行排序
icvSort_64f( weak_eval->data.db, count, ); // as weight trimming occurs immediately after updating the weights,
// where they are renormalized, we assume that the weight sum = 1.
sum = . - params.weight_trim_rate;
//由小到大遍历所有训练样本,找到裁剪率所对应的那个权值
for( i = ; i < count; i++ )
{
double w = weak_eval->data.db[i];
if( sum <= )
break;
sum -= w;
}
//得到阈值
threshold = i < count ? weak_eval->data.db[i] : DBL_MAX;
//再次遍历所有训练样本(这一次不是按照大小顺序遍历),确定哪些样本被裁剪掉
for( i = ; i < count; i++ )
{
double w = weights->data.db[i]; //得到权值
//权值与阈值比较,权值大则f为1,反之f为0
int f = w >= threshold;
//把权值大于阈值的样本所对应的掩码为置1,反之清0
subsample_mask->data.ptr[i] = (uchar)f;
nz_count += f; //计数
}
// nz_count < count表示有裁剪掉的样本,此时have_subsample为1,反之为0
have_subsample = nz_count < count; __END__;
}
6、计算active_vars和active_vars_abs值,这两个值的含义都是记录那些对决策树的分叉起到作用的特征属性的索引值,active_vars存储的索引值是只相对于参与训练决策树的那些特征属性,而active_vars_abs存储的索引值是针对所有的特征属性,包括那些被掩码掉的特征属性。
const CvMat*
CvBoost::get_active_vars( bool absolute_idx )
{
CvMat* mask = ;
CvMat* inv_map = ;
CvMat* result = ; CV_FUNCNAME( "CvBoost::get_active_vars" ); __BEGIN__; if( !weak ) //确保已得到分类器
CV_ERROR( CV_StsError, "The boosted tree ensemble has not been trained yet" );
//还没有为active_vars和active_vars_abs变量赋值
if( !active_vars || !active_vars_abs )
{
CvSeqReader reader;
int i, j, nactive_vars;
CvBoostTree* wtree;
const CvDTreeNode* node; assert(!active_vars && !active_vars_abs);
mask = cvCreateMat( , data->var_count, CV_8U );
inv_map = cvCreateMat( , data->var_count, CV_32S );
cvZero( mask ); //mask矩阵清零
cvSet( inv_map, cvScalar(-) ); //inv_map矩阵赋值为-1 // first pass: compute the mask of used variables
//把强分类器序列weak保存到reader变量中
cvStartReadSeq( weak, &reader );
//遍历所有的弱分类器
for( i = ; i < weak->total; i++ )
{
CV_READ_SEQ_ELEM(wtree, reader); //得到一个弱分类器,即决策树 node = wtree->get_root(); //得到决策树的根节点
assert( node != ); //确保根节点不为零,即该决策树存在
for(;;) //遍历决策树的各个节点
{
const CvDTreeNode* parent; //定义父节点
for(;;) 沿着左分子向叶节点遍历
{
CvDTreeSplit* split = node->split; //分叉属性
//遍历该节点的所有分叉属性,包括最佳分叉属性和替代分叉属性
for( ; split != ; split = split->next )
mask->data.ptr[split->var_idx] = ; //分叉属性相应位置1
if( !node->left ) //到达了叶节点,则退出for死循环
break;
node = node->left; //下一个左分支
}
//从叶节点沿着右分支向父节点遍历
for( parent = node->parent; parent && parent->right == node;
node = parent, parent = parent->parent )
; if( !parent ) //到达了根节点,则退出for死循环
break; node = parent->right; //下一个右分支
}
} nactive_vars = cvCountNonZero(mask); //统计mask中非0元素的数量 //if ( nactive_vars > 0 )
{
//定义两个矩阵
active_vars = cvCreateMat( , nactive_vars, CV_32S );
active_vars_abs = cvCreateMat( , nactive_vars, CV_32S ); have_active_cat_vars = false; //标识赋值
//遍历所有特征属性
for( i = j = ; i < data->var_count; i++ )
{
if( mask->data.ptr[i] )
{
//赋值为特征属性的索引
active_vars->data.i[j] = i;
active_vars_abs->data.i[j] = data->var_idx ? data->var_idx->data.i[i] : i;
// inv_map存储的形式与active_vars相反,即反映射
inv_map->data.i[i] = j;
//如果这些特征属性中只要有一个特征属性是类的形式,则have_active_cat_vars变量就为true
if( data->var_type->data.i[i] >= )
have_active_cat_vars = true;
j++; //计数
}
} // second pass: now compute the condensed indices
cvStartReadSeq( weak, &reader );
for( i = ; i < weak->total; i++ ) //再次遍历所有的弱分类器
{
CV_READ_SEQ_ELEM(wtree, reader);
node = wtree->get_root();
for(;;) //再次遍历决策树
{
const CvDTreeNode* parent;
for(;;)
{
CvDTreeSplit* split = node->split;
for( ; split != ; split = split->next )
{
// condensed_idx的值为该分叉属性在active_vars的索引,该索引值也是样本数据中特征属性分布排序的索引
split->condensed_idx = inv_map->data.i[split->var_idx];
assert( split->condensed_idx >= );
} if( !node->left )
break;
node = node->left;
} for( parent = node->parent; parent && parent->right == node;
node = parent, parent = parent->parent )
; if( !parent )
break; node = parent->right;
}
}
}
}
//行参absolute_idx为true,则该函数返回active_vars_abs,否则返回active_vars
result = absolute_idx ? active_vars_abs : active_vars; __END__; cvReleaseMat( &mask );
cvReleaseMat( &inv_map ); return result;
}
7、CvBoostTree类中的一个train函数:
bool CvBoostTree::train( CvDTreeTrainData* _train_data,
const CvMat* _subsample_idx, CvBoost* _ensemble )
{
clear();
ensemble = _ensemble;
data = _train_data; //样本数据
data->shared = true;
return do_train( _subsample_idx );
}
从上面的train函数可以看出,它主要是调用do_train函数,而CvBoostTree类没有do_train函数,因此train函数是调用CvBoostTree类的父类CvDTree中的do_train函数。
bool CvDTree::do_train( const CvMat* _subsample_idx )
{
bool result = false; CV_FUNCNAME( "CvDTree::do_train" ); __BEGIN__;
//得到训练样本数据
root = data->subsample_data( _subsample_idx ); CV_CALL( try_split_node(root)); if( root->split )
{
CV_Assert( root->left );
CV_Assert( root->right );
//用于弱分类器的决策树不需要剪枝,所以这里不会调用prune_cv函数
if( data->params.cv_folds > )
CV_CALL( prune_cv() ); if( !data->shared )
data->free_train_data(); result = true;
} __END__; return result;
}
递归调用try_split_node函数,完成决策树的构造:
void CvBoostTree::try_split_node( CvDTreeNode* node )
{
//调用CvDTree::try_split_node函数
CvDTree::try_split_node( node );
//在构建决策树的过程中,一旦某个节点再也不能分叉,则进入下面的if语句,完成该节点内所有样本的弱分类器(即响应值)的赋值
if( !node->left )
{
// if the node has not been split,
// store the responses for the corresponding training samples
//指向弱分类器的响应值
double* weak_eval = ensemble->get_weak_response()->data.db;
//开辟一块大小为该节点样本数据长的内存
cv::AutoBuffer<int> inn_buf(node->sample_count);
//labels表示该节点node内的样本在全体训练样本集中的索引
const int* labels = data->get_cv_labels( node, (int*)inn_buf );
int i, count = node->sample_count; //count表示该节点的样本数
//该节点的值,当该节点有多个样本是,如果是分类树,节点的值等于拥有最大数量的那个分类的响应值;如果是回归树,节点的值等于所有样本的平均响应值;当该节点只有一个样本时,节点的值就是该样本的响应值
double value = node->value;
//遍历该节点的所有样本,为该节点内的样本所对应的弱分类器的响应值赋值
for( i = ; i < count; i++ )
weak_eval[labels[i]] = value;
}
}
8、下面我们介绍预测函数predict:
float
CvBoost::predict( const CvMat* _sample, const CvMat* _missing,
CvMat* weak_responses, CvSlice slice,
bool raw_mode, bool return_sum ) const
//_sample表示要预测的样本数据
//_missing表示预测样本中所缺失的特征属性,该变量为掩码的形式
// weak_responses表示弱分类器所对应的响应,因此它的元素个数必须与弱分类器的数量一致,默认值0,表示不使用该变量
//slice表示用于预测的弱分类器的连续子集,默认值为CV_WHOLE_SEQ,表示使用所有的弱分类器
// raw_mode与CvDTree::predict函数的第三个参数的含义相同,默认为false,具体请看上一篇文章
// return_sum表示该函数返回值的形式,默认为false,表示返回式12或式17的值,如果该值为true,则返回式12或式17中括号内的值,即不进行符号判断
{
float value = -FLT_MAX; //初始一个很大的负值 CvSeqReader reader;
double sum = ;
int wstep = ;
const float* sample_data; if( !weak ) //还没有强分类器
CV_Error( CV_StsError, "The boosted tree ensemble has not been trained yet" );
//判断输入参数_sample的正确性
if( !CV_IS_MAT(_sample) || CV_MAT_TYPE(_sample->type) != CV_32FC1 ||
(_sample->cols != && _sample->rows != ) ||
(_sample->cols + _sample->rows - != data->var_all && !raw_mode) ||
(active_vars && _sample->cols + _sample->rows - != active_vars->cols && raw_mode) )
CV_Error( CV_StsBadArg,
"the input sample must be 1d floating-point vector with the same "
"number of elements as the total number of variables or "
"as the number of variables used for training" ); if( _missing ) //判断输入参数_missing的正确性
{
if( !CV_IS_MAT(_missing) || !CV_IS_MASK_ARR(_missing) ||
!CV_ARE_SIZES_EQ(_missing, _sample) )
CV_Error( CV_StsBadArg,
"the missing data mask must be 8-bit vector of the same size as input sample" );
}
// weak_count为根据输入参数slice而得到的弱分类器的数量
int i, weak_count = cvSliceLength( slice, weak );
//确保weak_count正确
if( weak_count >= weak->total )
{
weak_count = weak->total;
slice.start_index = ;
} if( weak_responses ) //确保输入参数weak_responses的正确性
{
if( !CV_IS_MAT(weak_responses) ||
CV_MAT_TYPE(weak_responses->type) != CV_32FC1 ||
(weak_responses->cols != && weak_responses->rows != ) ||
weak_responses->cols + weak_responses->rows - != weak_count )
CV_Error( CV_StsBadArg,
"The output matrix of weak classifier responses must be valid "
"floating-point vector of the same number of components as the length of input slice" );
wstep = CV_IS_MAT_CONT(weak_responses->type) ? : weak_responses->step/sizeof(float);
}
//得到active_vars变量的行,即启作用的特征属性的数量
int var_count = active_vars->cols;
const int* vtype = data->var_type->data.i; //指向全体特征属性
const int* cmap = data->cat_map->data.i; //指向特征属性为类形式的映射
const int* cofs = data->cat_ofs->data.i; //表示特征属性为类形式的各个属性的偏移量 cv::Mat sample = _sample; //预测样本
cv::Mat missing; //缺失特征属性的掩码
if(!_missing)
missing = _missing; //赋值 // if need, preprocess the input vector
//对预测样本的特征属性做规范化处理,具体内容请看我的上一篇关于决策树的文章
if( !raw_mode )
{
int sstep, mstep = ;
const float* src_sample;
const uchar* src_mask = ;
float* dst_sample;
uchar* dst_mask;
const int* vidx = active_vars->data.i;
const int* vidx_abs = active_vars_abs->data.i;
bool have_mask = _missing != ; sample = cv::Mat(, var_count, CV_32FC1);
missing = cv::Mat(, var_count, CV_8UC1); dst_sample = sample.ptr<float>();
dst_mask = missing.ptr<uchar>(); src_sample = _sample->data.fl;
sstep = CV_IS_MAT_CONT(_sample->type) ? : _sample->step/sizeof(src_sample[]); if( _missing )
{
src_mask = _missing->data.ptr;
mstep = CV_IS_MAT_CONT(_missing->type) ? : _missing->step;
} for( i = ; i < var_count; i++ )
{
int idx = vidx[i], idx_abs = vidx_abs[i];
float val = src_sample[idx_abs*sstep];
int ci = vtype[idx];
uchar m = src_mask ? src_mask[idx_abs*mstep] : (uchar); if( ci >= )
{
int a = cofs[ci], b = (ci+ >= data->cat_ofs->cols) ? data->cat_map->cols : cofs[ci+],
c = a;
int ival = cvRound(val);
if ( (ival != val) && (!m) )
CV_Error( CV_StsBadArg,
"one of input categorical variable is not an integer" ); while( a < b )
{
c = (a + b) >> ;
if( ival < cmap[c] )
b = c;
else if( ival > cmap[c] )
a = c+;
else
break;
} if( c < || ival != cmap[c] )
{
m = ;
have_mask = true;
}
else
{
val = (float)(c - cofs[ci]);
}
} dst_sample[i] = val;
dst_mask[i] = m;
} if( !have_mask )
missing.release();
}
else
{
if( !CV_IS_MAT_CONT(_sample->type & (_missing ? _missing->type : -)) )
CV_Error( CV_StsBadArg, "In raw mode the input vectors must be continuous" );
} cvStartReadSeq( weak, &reader ); //读取各个弱分类器
cvSetSeqReaderPos( &reader, slice.start_index ); //指定起始地址 sample_data = sample.ptr<float>(); //预测样本数据的指针
// !have_active_cat_vars表示启作用的特征属性中没有任何一个是类的形式,missing.empty()预测样本没有缺失的特征属性,!weak_responses表示该输入参数不存在
if( !have_active_cat_vars && missing.empty() && !weak_responses )
{
//遍历所有的弱分类器
for( i = ; i < weak_count; i++ )
{
CvBoostTree* wtree; //表示代表该弱分类器的决策树
const CvDTreeNode* node;
CV_READ_SEQ_ELEM( wtree, reader ); //提取当前的决策树 node = wtree->get_root(); //得到决策树的根节点
//遍历该决策树,直到到达了叶节点
while( node->left )
{
CvDTreeSplit* split = node->split; //节点分叉
//得到该节点分叉属性在样本中特征属性排序的索引
int vi = split->condensed_idx;
float val = sample_data[vi]; //得到该特征属性所对应的样本值
//与分叉值比较,确定方向信息
int dir = val <= split->ord.c ? - : ;
if( split->inversed ) //方向需要反转的处理
dir = -dir;
//由方向信息确定下一步是向左分支遍历还是向右分支遍历
node = dir < ? node->left : node->right;
}
//累加各个弱分类器响应值,即式12或式17括号内的部分
sum += node->value;
}
}
else //其他情况的处理
{
const int* avars = active_vars->data.i; //指向active_vars变量
//如果有缺失的特征属性,则m指向掩码变量missing,否则m为空
const uchar* m = !missing.empty() ? missing.ptr<uchar>() : ; // full-featured version
//遍历所有的弱分类器
for( i = ; i < weak_count; i++ )
{
CvBoostTree* wtree; //弱分类器,即决策树
const CvDTreeNode* node;
CV_READ_SEQ_ELEM( wtree, reader ); //提取当前决策树 node = wtree->get_root(); //根节点
//遍历该决策树,直到到达了叶节点
while( node->left )
{
const CvDTreeSplit* split = node->split; //得到该节点的分叉
int dir = ;
//按照从最佳分叉属性到替代分叉属性的顺序遍历分叉属性,直到得到了节点的方向信息为止,
for( ; !dir && split != ; split = split->next )
{
//得到该节点分叉属性在样本中特征属性排序的索引
int vi = split->condensed_idx;
int ci = vtype[avars[vi]]; //得到分叉属性的特征属性类型
float val = sample_data[vi]; //得到该特征属性所对应的样本值
//如果该特征属性是缺失的特征属性,则进入下次循环
if( m && m[vi] )
continue;
if( ci < ) // ordered 特征属性是数值的形式
//与分叉值比较,确定方向信息
dir = val <= split->ord.c ? - : ;
else // categorical 特征属性是类的形式
{
int c = cvRound(val); //取整
//对应找到split->subset中所对应的位,从而得到方向信息
dir = CV_DTREE_CAT_DIR(c, split->subset);
}
if( split->inversed ) //方向需要反转的处理
dir = -dir;
} if( !dir ) //如果方向信息还是没有得到
{
//该节点的哪个分支的样本数量多,方向dir就指向哪
int diff = node->right->sample_count - node->left->sample_count;
dir = diff < ? - : ;
}
//由方向信息确定下一步是向左分支遍历还是向右分支遍历
node = dir < ? node->left : node->right;
}
//如果定义了输入参数weak_responses,则输出弱分类器的值
if( weak_responses )
weak_responses->data.fl[i*wstep] = (float)node->value;
//累加各个弱分类器响应值,即式12或式17括号内的部分
sum += node->value;
}
} if( return_sum )
value = (float)sum; //直接返回式12或式17中括号内的值
else
{
int cls_idx = sum >= ; //符号判断,即式12或式17的值
if( raw_mode )
value = (float)cls_idx; //得到原始的数据
else //得到其所代表的数据
value = (float)cmap[cofs[vtype[data->var_count]] + cls_idx];
} return value; //返回
}
OpenCV是用决策树来得到弱分类器的,因此实现弱分类器的类CvBoostTree继承于构建决策树的类CvDTree,前面介绍过的CvBoostTree类内的train函数和try_split_node函数都是虚函数,它们是针对用于弱分类器设计的决策树的特殊性而重写的函数,这样的虚函数还有许多,如find_surrogate_split_ord、find_split_ord_class、calc_node_value等。对这些函数就不再详细阐述,这里主要把与CvDTree类的不同的地方说明一下,关于CvDTree类的介绍请看此文。
1、构建弱分类器的每个样本都有权值,即wi(m),在决策树中被称为是先验概率;
2、用于衡量分类树纯度的不仅有基尼指数,还有错误分类率这种方法;
3、弱分类器只是一个用于研究两类问题的决策树,所有要相对简单一点;
4、不同的弱分类器所应用的训练样本的数量可能会不同。
三 例子
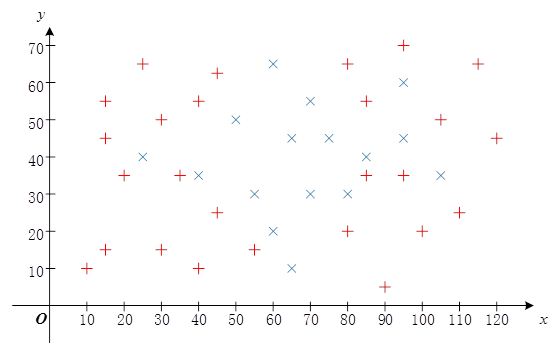
如上图所示,红色“+”的采样点的坐标为:(40,55),(35,35),(55,15),(45,25),(10,10),(15,15),(40,10),(30,15),(30,50),(100,20),(45,65),(20,35),(80,20),(90,5),(95,35),(80,65),(15,55),(25,65),(85,35),(85,55),(95,70),(105,50),(115,65),(110,25),(120,45),(15,45);
蓝色“×”的采样点的坐标为:(55,30),(60,65),(95,60),(25,40),(75,45),(105,35),(65,10),(50,50),(40,35),(70,55),(80,30),(95,45),(60,20),(70,30),(65,45),(85,40)。
我们用AdaBoost算法判断新的坐标(55,25)是属于红色标注的区域还是蓝色标注的区域,程序为:
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/ml/ml.hpp" #include <iostream>
using namespace cv;
using namespace std; int main( int argc, char** argv )
{
//训练样本
float trainingData[][]={ {, },{, },{, },{, },{, },{, },{, },
{, },{, },{, },{, },{, },{, },{, },
{, },{, },{, },{, },{, },{, },{, },
{, },{, },{, },{, },{, },
{, },{, },{, },{, },{, },{, },{, },
{, },{, },{, },{, },{, },{, },{, },
{, },{, } };
Mat trainingDataMat(, , CV_32FC1, trainingData);
//训练样本的响应值
float responses[] = {'R','R','R','R','R','R','R','R','R','R','R','R','R','R','R','R',
'R','R','R','R','R','R','R','R','R','R',
'B','B','B','B','B','B','B','B','B','B','B','B','B','B','B','B' };
Mat responsesMat(, , CV_32FC1, responses); float priors[] = {, }; //先验概率 CvBoostParams params( CvBoost::REAL, // boost_type
, // weak_count
0.95, // weight_trim_rate
, // max_depth
false, // use_surrogates
priors // priors
); CvBoost boost;
boost.train ( trainingDataMat,
CV_ROW_SAMPLE,
responsesMat,
Mat(),
Mat(),
Mat(),
Mat(),
params
);
//预测样本
float myData[] = {, };
Mat myDataMat(, , CV_32FC1, myData);
double r = boost.predict( myDataMat ); cout<<endl<<"result: "<<(char)r<<endl; return ;
}
输出的结果为:
result: R
我们也可以用下列代码把训练好的分类器保存为xml文件:
boost->save("boost.xml");
如果要使用该分类器,只需要加载该文件即可,如:
CvBoost * boost= new CvBoost();
boost->load("boost.xml");
AdaBoost笔记之代码的更多相关文章
- 机器学习之AdaBoost原理与代码实现
AdaBoost原理与代码实现 本文系作者原创,转载请注明出处: https://www.cnblogs.com/further-further-further/p/9642899.html 基本思路 ...
- Adaboost算法及其代码实现
. . Adaboost算法及其代码实现 算法概述 AdaBoost(adaptive boosting),即自适应提升算法. Boosting 是一类算法的总称,这类算法的特点是通过训练若干弱分类器 ...
- 机器学习实战笔记--AdaBoost(实例代码)
#coding=utf-8 from numpy import * def loadSimpleData(): dataMat = matrix([[1. , 2.1], [2. , 1.1], [1 ...
- [学习笔记] SSD代码笔记 + EifficientNet backbone 练习
SSD代码笔记 + EifficientNet backbone 练习 ssd代码完全ok了,然后用最近性能和速度都非常牛的Eifficient Net做backbone设计了自己的TinySSD网络 ...
- AdaBoost笔记之通俗易懂原理介绍
转自:https://blog.csdn.net/px_528/article/details/72963977 写在前面 说到Adaboost,公式与代码网上到处都有,<统计学习方法>里 ...
- AdaBoost笔记之原理
转自:https://www.cnblogs.com/ScorpioLu/p/8295990.html 一.Boosting提升算法 AdaBoost是典型的Boosting算法,属于Boosting ...
- linux源代码阅读笔记 get_free_page()代码分析
/* 34 * Get physical address of first (actually last :-) free page, and mark it 35 * used. If no fre ...
- ROBOTS.TXT屏蔽笔记、代码、示例大全
自己网站的ROBOTS.TXT屏蔽的记录,以及一些代码和示例: 屏蔽后台目录,为了安全,做双层管理后台目录/a/xxxx/,蜘蛛屏蔽/a/,既不透露后台路径,也屏蔽蜘蛛爬后台目录 缓存,阻止蜘蛛爬静态 ...
- JavaWeb学习笔记--Servlet代码集
目录: 登录系统提交表单数据打开PDFCookieURL传递参数URL重写跟踪会话使用HttpSession对象跟踪会话Servlet间协作过滤器Filter 登录系统 <!DOCTYPE HT ...
随机推荐
- 02-python 学习第二天
今天学习了以下几个方面的内容,虽然部分内容不能理解,跟着老师写出了代码. 列表.元组操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 程序练习1:购物车程序 请闭眼写出以下程序. 程序: ...
- 压测:mysqlslap
MySQL从5.1.4版开始带有一个压力测试工具mysqlslap,通过模拟多个并发客户端访问mysql来执行测试,使用起来非常简单,通过mysqlslap –help可以获得可用的选项.这里列一些主 ...
- POJ 2398 map /// 判断点与直线的位置关系
题目大意: poj2318改个输出 输出 a: b 即有a个玩具的格子有b个 可以先看下poj2318的报告 用map就很方便 #include <cstdio> #include < ...
- Python 字符串切片(slice)
切片操作(slice)可以从一个字符串中获取子字符串(字符串的一部分).我们使用一对方括号.起始偏移量start.终止偏移量end 以及可选的步长step 来定义一个分片. 格式: [start:en ...
- Java工具类NumberUtils使用
int数据类型和long数据类型 int占32位,long占64位,long表示的数据更大:public static int toInt(String str) NumberUtils.toInt( ...
- pom.xml文件配置maven仓库地址
中央仓库就是Maven的一个默认的远程仓库,Maven的安装文件中自带了中央仓库的配置($M2_HOME/lib/maven-model-builder.jar) 在很多情况下,默认的中央仓库无法满足 ...
- godaddy账号以及域名被盗找回经历以及网络信息安全的思考
本案涉及到公司的一些机密信息,因此涉及到机密信息,我都将会用一些其他的代号进行替代.不影响读者理解本案.我会按照时间顺序讲述本案经过,是如何一步步找回godaddy账号的. 我供职的公司是一家网络科技 ...
- Luogu P2717 寒假作业(平衡树)
P2717 寒假作业 题意 题目背景 \(zzs\)和\(zzy\)正在被寒假作业折磨,然而他们有答案可以抄啊. 题目描述 他们共有\(n\)项寒假作业.\(zzy\)给每项寒假作业都定义了一个疲劳值 ...
- Qt plugins(插件)目录
今天在打包Qt程序时,出现了因为缺少插件,导致背景图无法显示的问题.第一次将plugins目录全部拷贝到了应用程序根目录下,还是无法运行.查阅资料,需要拷贝plugins子目录到应用程序跟目录.虽然最 ...
- react中使用屏保
1,默认路由路径为屏保组件 <HashRouter history={hashHistory}> <Switch> <Route exact path="/&q ...