UCI 人口收入数据分析(python)
一、项目介绍
UCI上有许多免费的数据集可以拿来练习,可以在下面的网站找寻
http://archive.ics.uci.edu/ml/datasets.html
这次我使用的是人口收入调查,里面会有每个人的教育程度、每周工时、职业、性别等数据,并以50K为界线,分为收入大于50K和收入小于50K的人群。
首先利用pandas将数据抓下,由于数据是在网页上,直接抓网页就可以,并且用table的格式,以逗号区分列,由于原始数据没有列名称,所以需要为每列设定一个名称,下面为代码
import pandas as pd
import sklearn
file = pd.read_table('http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data',
sep=',',
names=['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital_states', 'occupation', 'relationship', 'race',
'sex', 'capital_gain',
'capital_loss', 'hours_per_week', 'native_country', 'income'])
file为表名,接着利用file.head()查看前五行的数据
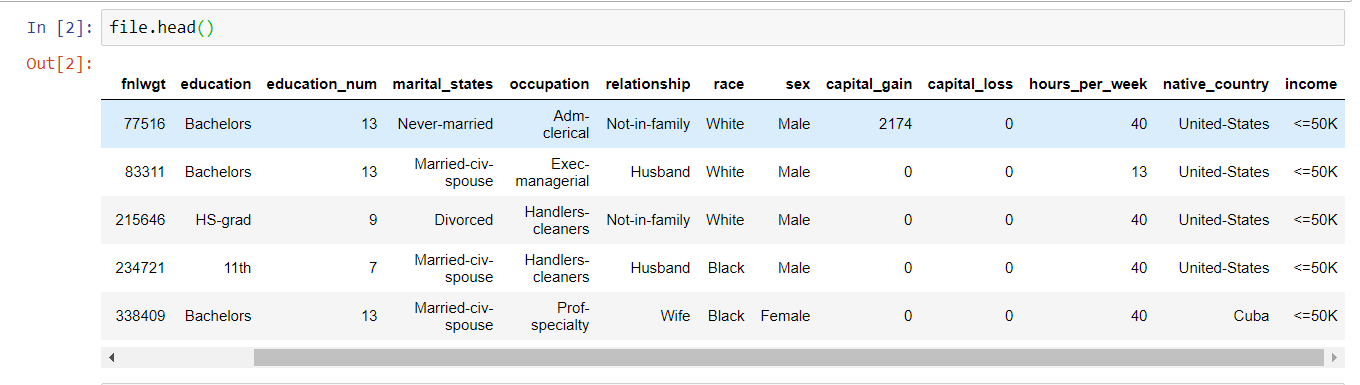
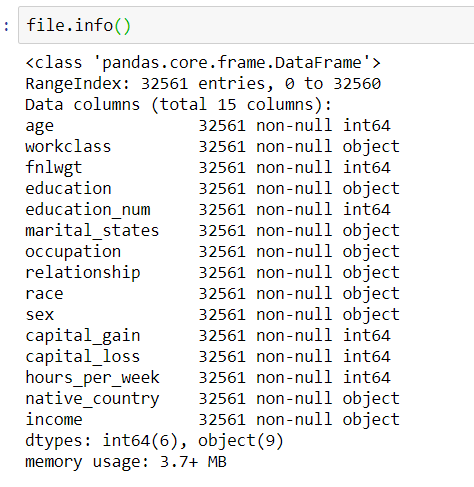
接着用file.info()查看表的信息,发现数据挺完整的,没有缺失数据,只是里面数据大部分都是object,必须要做处理才有办法计算(机器是无法对文字进行计算的,需要转成数字或是矩阵)
接着用hist来看几个int的分布
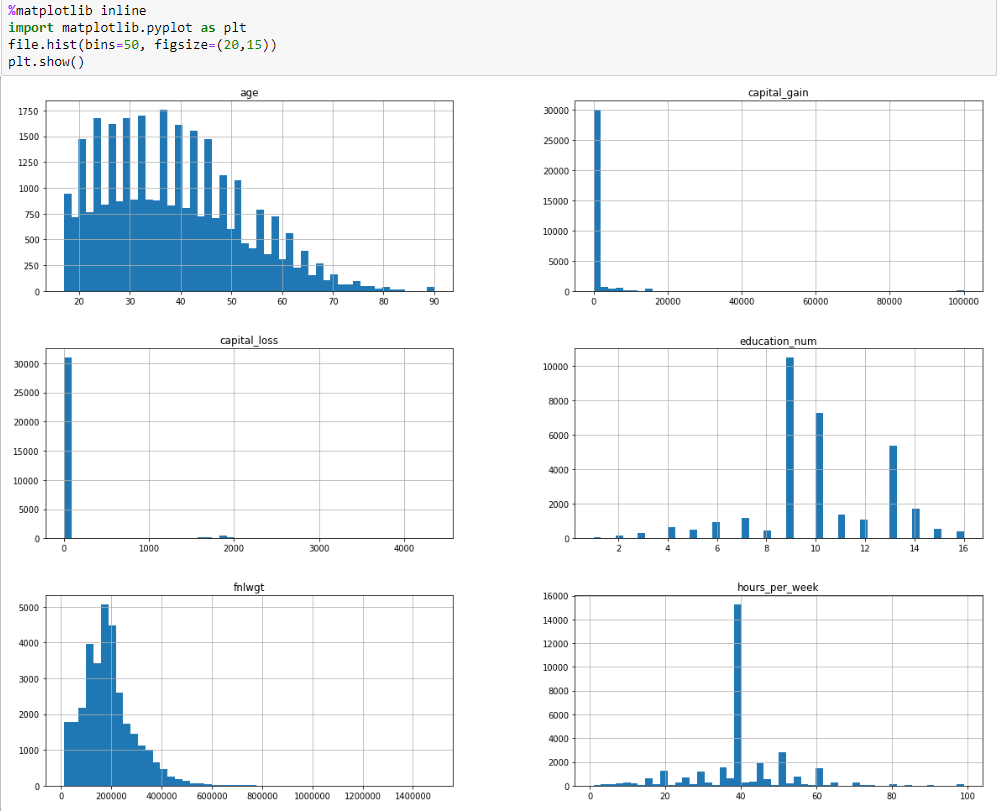
可以看到capital_gain和capital_loss的分布特别奇怪,绝大部分的数据都是0,其他的数据分布都还算是正常。
接着利用value_counts来查看各列的数据统计
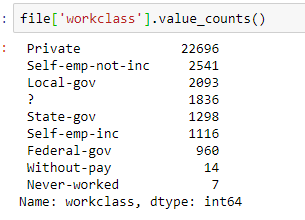
像是雇主的话有三分之二的人都是在私企工作,第二多的是自由业,剩下的部分在国企,还有大约1800个是不名的
从这边我们可以推断,这个数据集里虽然没有数据缺失,但是有非常多的0和?这种数据,估计是没问出结果就填了个东西,而这些填充数据会严重影响到时候的分析结果。
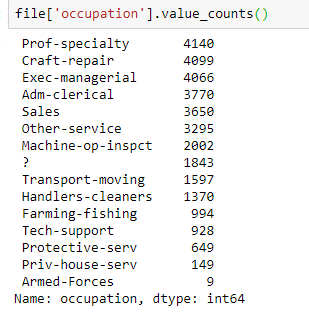
剩下的列就不一一展示了,可以看到有些列分布平均,像是职业,最多的也不超过20%,而且前面几名的人数相差不大,这边也可以发现每一列大约都有1800左右的填充数据。
接着我们需要去做相关性的分析,为什么要做相关性分析呢?因为我们想要找出列跟列之间是否有某种关联,还有每个列跟我们要预测的结果(income)是否有关联。
由于关联性是用数字去计算的,但是这个数据集里面大部分的列都是文字,需要先转成可以计算的数字。
这边要注意的是,大部分的文字列数据并没有连续性,所以不能直接转成数字(数字是有连续性的),需要转成矩阵,这边可以用dummies这个功能将文字列转为矩阵列
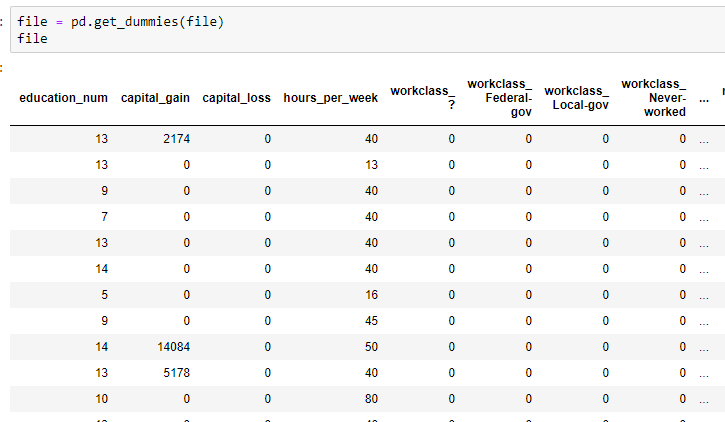
可以看到原本的workclass这一列,被拆分成了workclass_?, workclass_Federal-gov, workclass_Local-gov等,0代表不是,1代表是,也由于这样的拆分,原本的15列现在变成了110列。
这个时候我们先看看有哪些列跟我们的结果有正相关吧,我们利用corr这个功能来对每一列跟结果列做相关分析

由结果可以看到,相关性最强的是已婚人士,再过来是家庭里的丈夫,再过来是受教育的长度,年纪,工作时长,男性。而职业里公司高管是相关性最强的,再过来是专业人员,这边有点意外的是本科毕业的比硕士、博士毕业的相关性更强,种族是白人,下面是负相关最强的几个
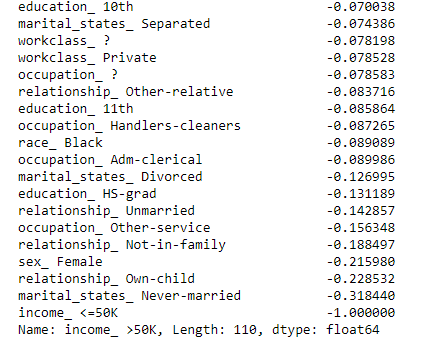
可以看到未婚人士是负相关最强的,正好跟前面的已婚做对比,再过来是小孩,女性等,可以看到这个数据集里影响收入最主要的因素是家庭、性别、教育程度和职业。
到这边我们可以了解收入较高的用户画像是受高等教育已婚的美国中年白人,而收入较低的是没结过婚高中毕业的黑人女性
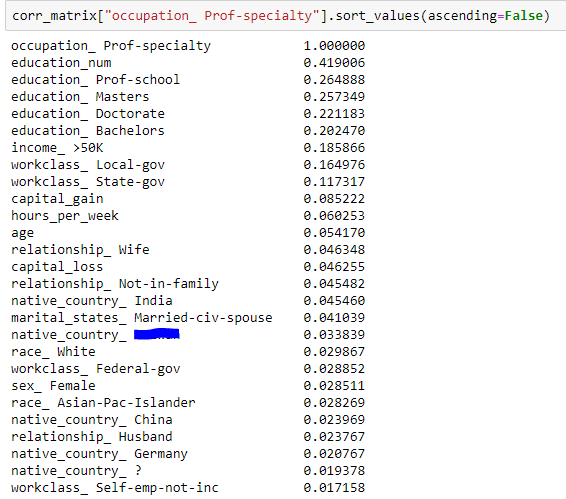
接着我们想了解收入最高的两个职业都是由什么样的人
先是看高管,可以发现高管大部分都是本科毕业居多,然后工作时间长,有很大一部分是自己开公司,然后也是已婚白人男性。

再来是专业人士,可以发现专业人士跟受教育程度相关性非常大,并且大部分工作单位是政府单位,重点是在专业人士里女性比男性的比例高,而且国籍正相关最强的不是美国而是印度和中国的亚洲女性。
可以分析出专业人士用户画像为已婚的高学历亚洲女性,并为政府工作。
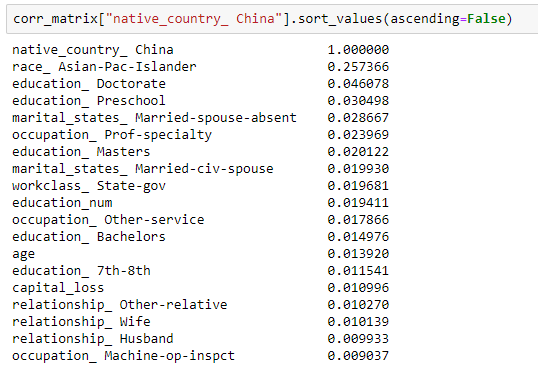
接着我们想看中国籍的美国人大概都是怎么样的人,可以发现非常学历非常极端,不是博士毕业就是没读书,专业人士居多,然后竟然大部分是已婚配偶缺席这种特殊的婚姻状态,其实我也搞不太懂为什么。
以上就是一些简单的用户画像分析,由于数据源是1994年的调查,距今已经20多年了,随着时代变迁,现在的用户画像跟以前应该会有很大的不同,不过也可以借由这些数据来了解当时美国的一些生活情况。
UCI 人口收入数据分析(python)的更多相关文章
- 号外号外:9月21号关于Speed-BI 《全国人口统计数据分析》开讲了
引言:如何快速分析纷繁复杂的数据?如何快速做出老板满意的报表?如何快速将Speed-BI云平台运用到实际场景中? 本课程将通过各行各业案例背景,将Speed-BI云平台运用到实际场景中,通 ...
- 读书笔记——《谁说菜鸟不会数据分析—Python篇》
最近刚读完一本新书,关注的公众号作者出的“谁说菜鸟不会数据分析—Python篇”,话说现在很多微信公众号大牛都在出书,这貌似是一个趋势.. 说说这本书吧,我之前看过一些网文,对于数据分析这一块也有过一 ...
- 数据分析——python基础
前言:python数据分析的基础知识,简单总结,主要是为了方便自己写的时候查看(你们可能看不太清楚T^T),发现有用的方法,随时补充,欢迎指正 数据分析专栏: 数据分析--python基础 数据分析- ...
- 吴裕雄--天生自然 PYTHON数据分析:人类发展报告——HDI, GDI,健康,全球人口数据数据分析
import pandas as pd # Data analysis import numpy as np #Data analysis import seaborn as sns # Data v ...
- Python数据分析Python库介绍(1)
一直想写点Python的笔记了,今天就闲着无聊随便抄点,(*^__^*) 嘻嘻…… ---------------------------------------------------------- ...
- Pandas数据分析python环境说明文档
1. 要求windows系统 2. pycharm编程环境并要求配置好python3.x环境 pycharm可在官网下载,下面是链接. https://www.jetbrains.com/zh/pyc ...
- 数据分析python应用到的ggplot
数据分析中应用到python中的ggplot库,可以用来画图 数据之类的用优达学院中课程七中的数据为例 数据是:https://s3.amazonaws.com/content.udacity-dat ...
- 小白数据分析——Python职位全链路分析
最近在做Python职位分析的项目,做这件事的背景是因为接触Python这么久,还没有对Python职位有一个全貌的了解.所以想通过本次分析了解Python相关的职位有哪些.在不同城市的需求量有何差异 ...
- 数据分析python应用到的ggplot(二)
还是优达学院的第七课 数据:https://s3.amazonaws.com/content.udacity-data.com/courses/ud359/hr_by_team_year_sf_la. ...
随机推荐
- 一些关于中国剩余定理的数论题(POJ 2891/HDU 3579/HDU 1573/HDU 1930)
2891 -- Strange Way to Express Integers import java.math.BigInteger; import java.util.Scanner; publi ...
- hdu 2473 Junk-Mail Filter (暴力并查集)
Problem - 2473 为什么标题写的是暴力并查集?因为我的解法跟网上的有所不同,方法暴力很多. 先解释题意,这是一个模拟处理垃圾邮件的问题.垃圾邮件要根据它们的性质进行分类.对于10w个邮件, ...
- H3C 命令行历史记录功能
- @noi.ac - 493@ trade
目录 @description@ @solution@ @part - 1@ @part - 2@ @part - 3@ @part - 4@ @accepted code@ @details@ @d ...
- sleep usleep nanosleep alarm setitimer使用
sleep使用的是alarm之类的定时器,定时器是使得进程被挂起,使进程处于就绪的状态. signal+alarm定时器 alarm参数的类型为uint, 并且不能填0 #include <st ...
- Linux 查看kafka版本
find /opt -name \*kafka_\* | head -1 | grep -o '\kafka[^\n]*'
- 深入理解String、StringBuffer、StringBuilder(转)
文章系转载,非原创,原地址: http://www.cnblogs.com/dolphin0520/p/3778589.html 相信String这个类是Java中使用得最频繁的类之一,并且又是各大公 ...
- 【b804】双栈排序
Time Limit: 1 second Memory Limit: 50 MB [问题描述] Tom最近在研究一个有趣的排序问题.如图所示,通过2个栈S1和S2,Tom希望借助以下4种操作实现将输入 ...
- Ubuntu 19.04安装phpipam软件
1ftp下载xampp2安装xampp chmod 777sudo ./xampp.run3,ftp phpipam.tar.gz 解压 ./opt/lampp/www/phpipam/cp conf ...
- ssh使用笔记
在集群管理和配置中有很多命令要在各个节点中发送(特别是Master->Worker),大家都不希望发送每一个命令时都输入一次密码,因此常常先配置实现Master无密码登录到所有的Worker节点 ...