第3章 JDK并发包(五)
3.3 不要重复发明轮子:JDK的并发容器
3.3.1 超好用的工具类:并发集合简介
- JDK提供的这些容器大部分在java.util.concurrent包中。
- ConcurrentHashMap:这是一个高效的并发HashMap。可以理解为一个线程安全的HashMap。
- CopyOnWriteArrayList:这是一个List,从名字看就是和ArrayList是一族的。在读多写少的场合,这个List的性能非常好,远远好于Vector。
- ConcurrentLinkedQueue:高效的并发队列,使用链表实现。可以看做一个线程安全的LinkedList。
- BlockingQueue:这是一个接口,JDK内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
- ConcurrentSkipListMap:跳表的实现。这是一个Map,使用跳表的数据结构进行快速查找。
- 除了以上并发包中的专有数据结构外,java.util下的Vector是用线程安全的,另外Collections工具类可以帮助我们将任意集合包装成线程安全的集合。
3.3.2 线程安全的HashMap
- 如果需要一个线程安全的HashMap应该怎样做呢?一种可行的方法是使用Collections.synchronizedMap()方法包装我们的HashMap。如下代码,产生的HashMap就是线程安全的:
public static Map m = Collections.synchronizedMap(new HashMap());
- Collections.synchronizedMap()会生成一个名为SynchronizedMap的Map。它使用委托,将自己所有Map相关的功能交给传入的HashMap实现,而自己则主要负责保证线程安全。
- 具体参考下面的实现,首先SynchronizedMap内包装了一个Map。
private static class SynchronizedMap<K, V> implements Map<K, V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K, V> m; //Backing Map
final Object mutex; //Object on which to synchronize
}
- 通过mutex实现对这个m的互斥操作。比如,对于Map.get()方法,它的实现如下:
public V get(Object key) {
synchronized (mutex) { return m.get(key);}
}
- 而其他所有相关的Map操作都会使用这个mutex进行同步。从而实现线程安全。
- 这个包装的Map可以满足线程安全的要求。但是,它在多线程环境中的性能表现并不算好。无论是对Map的读取或者写入,都需要获得mutex的锁,这会导致所有对Map的操作全部进入等待状态,直到mutex锁可用。如果并发级别不高,一般也够用。但是,在高并发环境中,我们也有必要寻求新的解决方案。
- 一个更加专业的并发HashMap是ConcurrentHashMap。它位于java.util.concurrent包内。它专门为并发进行了性能优化,因此,更加适合多线程的场合。
3.3.3 有关List的线程安全
- 在Java中,ArrayList和Vector都是使用数组作为其内部实现。两者最大的不同在于Vector是线程安全的,而ArrayList不是。此外,LinkedList使用链表的数据结构实现了List。但是很不幸,LinkedList并不是线程安全的。不过在这里我们也可以使用Collections.synchronizedList()方法来包装任意List,如下所示:
public static List<String> l = Collections.synchronizedList(new LinkedList<String>());
- 此时生成的List对象就是线程安全的。
3.3.4 高效读写的队列:深度剖析ConcurrentLinkedQueue
- 队列Queue也是常用的数据结构之一。在JDK中提供了一个ConcurrentLinkedQueue类用来实现高并发的队列。从名字来看,这个队列使用链表作为其数据结构。
- 作为一个链表,自然需要定义有关链表内的节点,在ConcurrentLinkedQueue中,定义的节点Node核心如下:
private static class Node<E> {
volatile E item;
volatile Node<E> next;
}
其中item是用来表示目标元素的。比如,当列表中存放String时,item就是String类型。字段next表示当前Node的下一个元素,这样每个Node就能环环相扣,串在一起了。如图3.11所示,显示了ConcurrentLinkedQueue的基本结构。
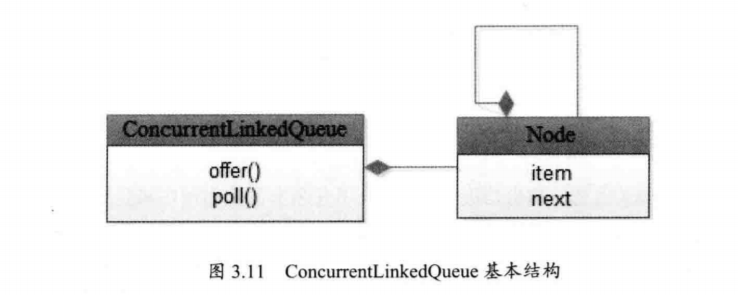
对Node进行操作时,使用了CAS操作。
boolean casItem(E, cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
方法casItem()方法表示设置当前Node的item值。它需要两个参数,第一个参数为期望值,第二个参数为设置目标值。当当前值等于cmp期望值时,就会将目标设置为val。同样casItem()方法也是类似的,但是它是用来设置next字段,而不是item字段。
ConcurrentLinkedQueue内部有两个重要的字段,head和tail,分别表示链表的头部和尾部,它们都是Node类型。对于head说,它永远不会为null,并且通过head以及succ()后继方法一定能完整地遍历整个链表。对于tail来说,它自然应该表示队列的末尾。
但ConcurrentLinkedQueue的内部实现非常复杂,它允许在运行时链表处于多个不同的状态。以tail为例,一般来说,我们期望tail总是链表的末尾,但实际上,tail的更新并不是及时的,而是可能会产生拖延现象。如图3.12所示,显示了插入时,tail的更新情况,可以看到tail的更新会产生滞后,并且每次更新会跳跃两个元素。
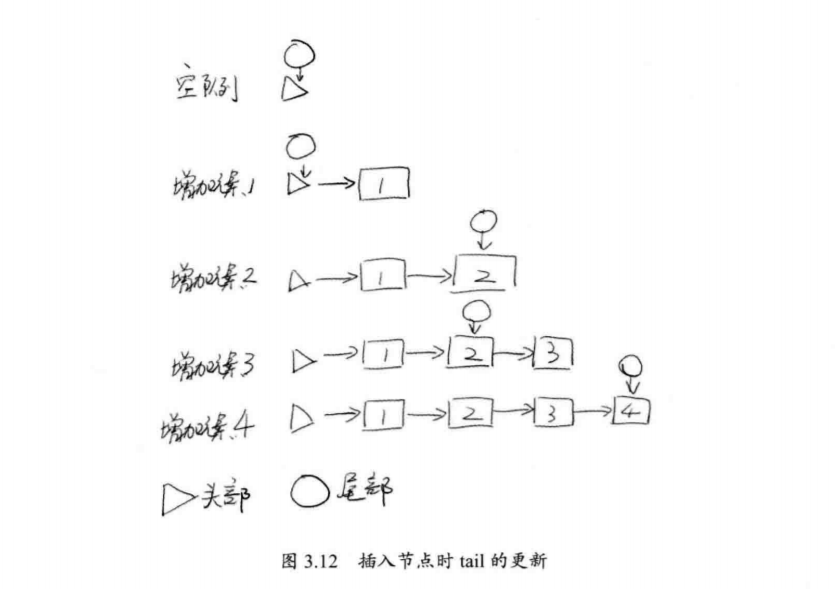
可以看到tail并不总是在更新。下面就是ConcurrentLinkedQueue中向队列中添加元素的offer()方法:
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// p是最后一个节点
if (p.casNext(null, newNode)) {
//每2次,更新一下tail
if (p != t) {
casTail(t, newNode);
}
return true;
}
//CAS竞争失败,再次尝试
} else if (p == q) {
//遇到哨兵节点,从都head开始遍历
//但如果tail修改,则使用tail(因为可能被修改正确了)
p = (t != (t = tail)) ? t : head;
} else {
//取下一个节点或者最后一个节点
p = (p != t && t != (t = tail)) ? t : q;
}
}
}
- 首先值得注意的是,这个方法没有任何锁操作。线程安全完全由CAS操作和队列的算法来保证。整个方法的核心是for循环,这个循环没有出口,直到尝试成功,这也符合CAS操作的流程。当第一次加入元素时,由于队列为空,因此p.next为null。程序将p的next节点赋值为newNode,也就是将新的元素加入到队列中。此时p==t成立,因此不会执行casTail(t, newNode),更新tail末尾。如果casNext()成功,程序直接返回,如果失败,则再进行一次循环尝试,知道成功。因此,增加一个元素后,tai并不会更新。
- 当程序试图增加第2个元素时,由于t还在head的位置上,因此p.next指向实际的第一个元素,因此Node q = p.next;,q!=null,这表示q不是最后的节点。由于往队列中增加元素需要最后一个节点的位置,因此,循环开始查找最后一个节点。于是,程序进入p = (p != t && t != (t = tail)) ? t : q;,获得最后一个节点。此时,p实际上是指向链表中的第一个元素,而它的next为null,故在第2个循环时,进入q == null里面。p更新自己的next,让它指向新加入的节点。如果成功,由于此时p!=t成功,则会更新t所在位置,将t移动到链表最后。
- 在第17行,处理了p==q的情况。这种情况是由于遇到了哨兵节点导致的。所谓哨兵节点,就是next指向自己的节点。这种节点在队列中的存在价值不大,主要表示要删除的节点,或者空节点。当遇到哨兵节点时,由于无法通过next取得后续的节点,因此很可能直接返回head,期望通过从链表头部开始遍历,进一步查找到链表末尾。但一旦发生在执行过程中,tail被其他线程修改的情况,则进行一次“打赌”,使用新的tail作为链表末尾。
- 如果大家对Java不是特别熟悉,可能会对类似下面的代码产生疑惑:
p = (t != (t = tail)) ? t : head;
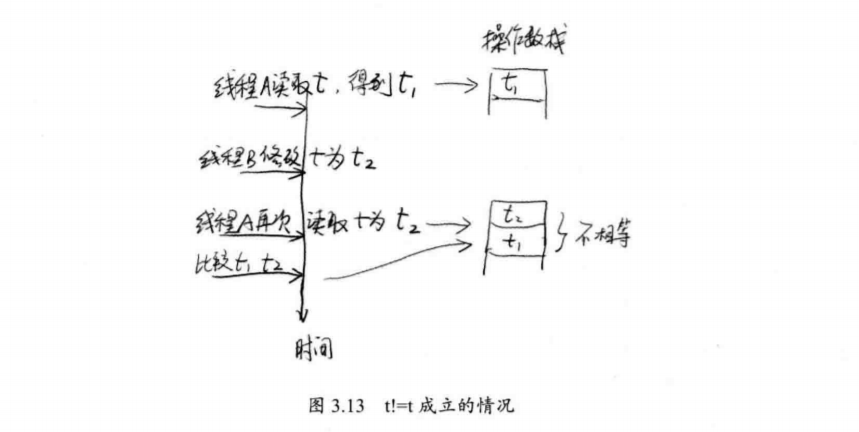
- 首先“!=”并不是原子操作,它是可以被中断的。也就是说,在执行“!=”时,程序会先取得t的值,再执行t=tail,并取得新的t的值。然后比较这两个值是否相等。在单线程时,t!=t这种语句显然不会成立。但是在并发环境中,有可能在获得左边的t值后,右边的t值被其他线程修改。这样t!=t就可能成立。这里就是这种情况。如果在比较过程中,tail被其他线程修改,当它再次赋值给t时,就会导致等式左边的t和右边的t不同。如果两个t不相同,表示tail在中途被其他线程篡改。这时,我们就可以用新的tail作为链表末尾,也就是这里的等式右边的t。但如果tail没有被修改,则返回head,要求从头部开始,重新查找尾部。
- 作为简化问题,我们考察t!=t的字节码:
11:getstatic #10 // Field t : I
14:getstatic #10 // Field t : I
17:if_icmpeq 24
可以看到,在字节码层面,t被先后取了两次,在多线程环境下,我们自然无法保证两次对t的取值会是相同的,如图3.13所示,显示了这种情况。
下面我们来看一下哨兵节点是如何产生的:
ConcurrentLinkedQueue<String> q = new ConcurrentLinkedQueue<String>();
q.add("1");
q.poll();
- 上述代码第3行,弹出队列内的元素。其执行过程如下:
public E poll() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null && p.casItem(item, null)) {
if (p != h) {
updateHead(h, ((q = p.next) != null) ? q : p);
}
return item;
} else if ((q = p.next) == null) {
updateHead(h, p);
return null;
} else if (p == q) {
continue restartFromHead;
} else {
p = q;
}
}
}
}
- 由于队列中只有一个元素,根据前文的描述,此时tail并没有更新,而是指向和head相同的位置。而此时,head本身的item域为null,其next为列表第一个元素。故在第一个循环中,代码直接进入第18行,将p赋值给q,而q就算p.next,也就是当前列表中的第一个 元素。接着,在第2轮循环中,p.item显然不为null。因此,代码应该可以顺利进入第7行(如果CAS操作成功)。进入第7行,也意味着p的item域被设置为null(因为这是弹出元素,自然需要删除)。同时,此时p和h是不相等的(因为p已经指向原有的第一个元素了)。故执行了第8行的udpateHead()操作,其实现如下:
final void updateHead(Node<E> h, Node<E> p) {
if (h != p && casHead(h, p)) {
h.lazySetNext(h);
}
}
- 可以看到,在updateHead中,就将p作为新的链表头部(通过casHead()实现),而原有的head就被设置为哨兵(通过lazySetNext()实现)。
- 这样一个哨兵节点就产生了,而由于此时原有的head头部和tail实际上是同一个元素。因此,再次offer()插入元素时,就会遇到这个tail,也就是哨兵。这就是offer()代码中,if (p == q)的判断的意义。
- 通过这些说明,大家应该可以明显感觉到,不使用锁而单纯地使用CAS操作会要求在应用层保证线程安全,并处理一些可能存在的不一致问题,大大增加了程序设计和实现的难度。但是它带来的好处就是可以得到性能的飞速提升。因此,在有些场合也是值得的。
3.3.5 高效读取:不变模式下的CopyOnWriteArrayList
- 为了将读取的性能发挥到极致,JDK中提供了CopyOnWriteArrayList类。对它来说,读取是完全不用加锁的,并且更好的消息是:写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待。
- 从这个类的名字我们可以看到,所谓CopyOnWrite就是在写入操作时,进行一次自我复制。换句话说,当这个List需要修改时,我并不修改原有的内容(这对于保证当前在读线程的数据一致性非常重要),而是对原有的数据进行一次复制,将修改的内容写入副本中。写完之后,再将修改完的副本替换原来的数据。这样就可以保证写操作不会影响读了。
- 下面的代码展示了有关读取的实现:
private volatile transient Object[] array;
public E get(int index) {
return get(getArray(), index);
}
final Object[] getArray() {
return array;
}
private E get(Object[] a, int index) {
return (E) a[index];
}
- 需要注意的是:读取代码没有任何同步控制和锁操作,理由就是内部数组array不会发生修改,只会被另外一个array替换,因此可以保证数据安全。
- 和简单的读取相比,写入操作就有些麻烦了:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements,len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
- 首先,写入操作使用锁,当然这个锁仅限于控制写-写的情况。其重点在于第7行代码,进行了内部元素的完整复制。因此,会生成一个新的数组newElements。然后,将新的元素加入newElements。接着,在第9行,使用新的数组替换老的数组,修改就完成了。整个 过程不会影响读取,并且修改完后,读取线程可以立即“察觉”到这个修改(因为array变量是volatile类型)。
3.3.6 数据共享通道:BlockingQueue
与之前提到的ConcurrentLinkedQueue或者CopyOnWriteArrayList不同,BlockingQueue是一个接口,并非一个具体的实现。它的主要实现由下面一些,如图3.14所示。

这里我们主要介绍ArrayBlockingQueue和LinkedBlockingQueue。从名字应该可以得知,ArrayBlockingQueue是基于数组实现的,而LinkedBlockingQueue基于链表。ArrayBlockingQueue更适合做有界队列,因为队列中可容纳的最大元素需要在队列创建时指定。而 LinkedBlockingQueue适合做无界队列,或者那些边界值非常大的队列,因为其内部元素可以动态增加,它不会因为初值容量很大,而一口气吃掉你一大半的内存。
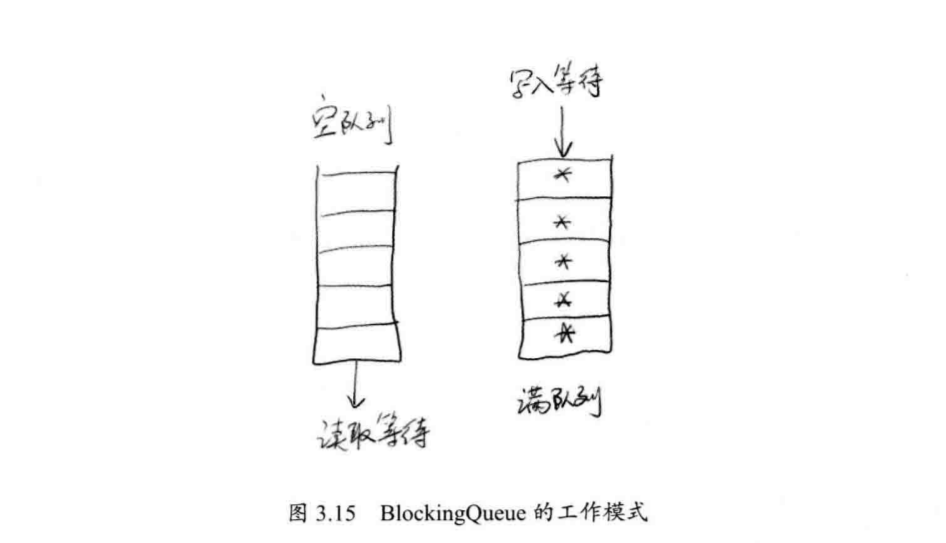
而BlockingQueue之所有适合作为数据共享的通道,其关键还在于Blocking上。Blocking是阻塞的意思,当服务线程(服务线程指不断获取队列中的消息,进行处理的线程)处理完成队列中所有的消息后,它如何知道下一条消息何时到来呢?
一种最傻瓜化的做法是让这个线程按照一定的时间间隔不停地循环和监控这个队列。这是可行的一种方案,但显然造成了不必要的资源浪费,而循环周期也难以确定。而BlockingQueue很好地解决了这个问题。它会让服务线程在队列为空时,进行等待,当有新的消 息进入队列后,自动将线程唤醒,如图3.15所示。那它是如何实现的呢?我们以ArrayBlockingQueue为例,来一探究竟。
ArrayBlockingQueue的内部元素都放置在一个对象数组中:
final Object[] items;
- 向队列中压人元素可以使用offer()方法和put()方法。对于offer()方法,如果当前队列已经满了,它就会立即返回false。如果没有满,则执行正常的入队操作。所以,我们不讨论这个方法。现在,我们需要关注的是put()方法。put()方法也是将元素压人队列末尾。但如果队列满了,它会一直等待,直到队列中有空闲的位置。
- 从队列中弹出元素可以使用poll()方法和take()方法。它们都从队列的头部获得一个元素。不同之处在于:如果队列为空poll()方法直接返回null,而take()方法会等待,直到队列内有可用元素。
- 因此,put()方法和take()方法才是体现Blocking的关键。为了做好等待和通知两件事,在ArrayBlockingQueue内部定义了以下一些字段:
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
- 当执行take()操作时,如果队列为空,则让当前线程等待在notEmpty上。新元素入队列,则进行一次notEmpty上的通知。
- 下面的代码显示了take()的过程:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0) {
notEmpty.await();
}
return extract();
} finally {
lock.unlock();
}
}
- 第6行代码,就要求当前线程进行等待。当队列中有新元素时,线程会得到一个通知。下面是元素入队时的一段代码:
private void insert(E x) {
items[putIndex] = x;
putIndex = inc(putIndex);
++count;
notEmpty.signal();
}
- 注意第5行代码,当新元素进入队列后,需要通知等待在notEmpty上的线程,让他们继续工作。
- 同理,对于put()操作也是一样的,当队列满时,需要让压入线程等待,如下面第7行。
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length) {
notFull.await();
}
insert(e);
} finally {
lock.unlock();
}
}
- 当有元素从队列中被挪走,队列中出现空位时,自然也需要通知等待入队的线程:
private E extract() {
final Object[] items = this.items;
E x = this.<E>cast(items[takeIndex]);
items[takeIndex] = null;
takeIndex = inc(takeIndex);
--count;
notFull.signal();
return x;
}
- 上述代码表示从队列中拿走一个元素。当有空闲位置时,在第7行,通知等待入队的线程。
3.3.7 随机数据结构:跳表(SkipList)
跳表是一种可以用来快速查找的数据结构,有点类似于平衡树。它们都可以对元素进行快速的查找。但一个重要的区别是:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整。而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。这样带来的好处是:在高并发的情况下,你会需要一个全局锁来保证整个平衡树的线程安全。而对于跳表,你只需要部分锁即可。这样,在高并发环境下,你就可以拥有更好的性能。而就查询的性能而言,跳表的时间复杂度也是O(logn)。所以在并发数据结构中,JDK使用跳表来实现一个Map。
跳表的另外一个特点是随机算法。跳表的本质是同时维护了多个链表,并且链表是分层的,如图3.16所示。
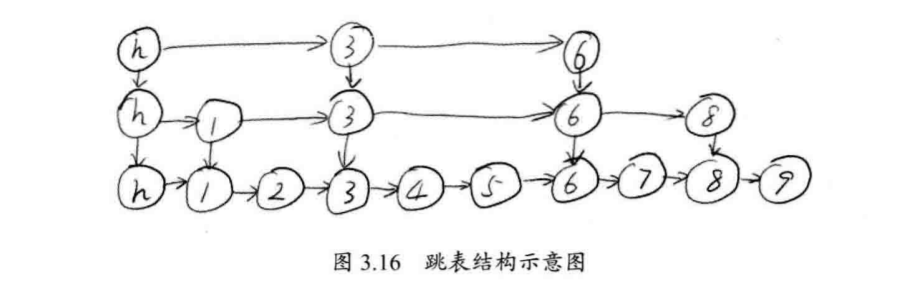
最底层的链表维护了跳表内所有的元素,每上面一层链表都是下面一层的子集,一个元素插入哪些层是完全随机的。因此,如果运气不好的话,你可能会得到一个性能很糟糕的结构。但是在实际工作中,它的表现是非常好的。
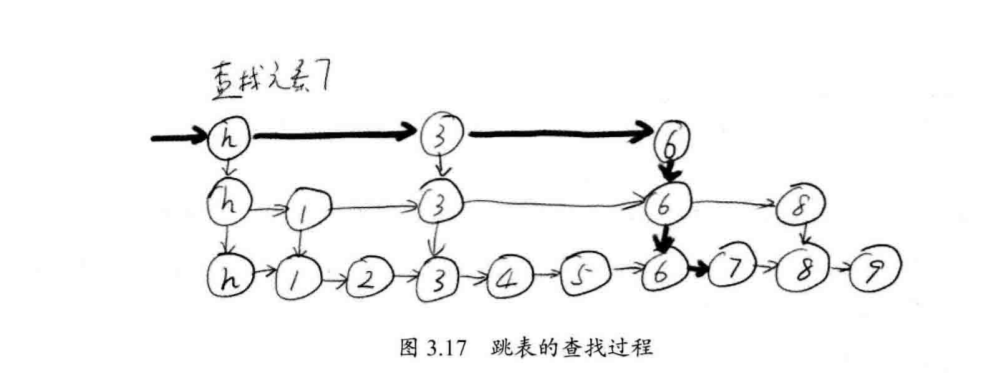
跳表内的所有链表的元素都是排序的。查找时,可以从顶级链表开始找。一旦发现被查找的元素大于当前链表中的取值,就会转入下一层链表继续找。这也就是说在查找过程中,搜索是跳跃式的,如图3.17所示,在跳表中查找元素7。查找从顶层的头部索引节点开 始。由于顶层的元素最少,因此,可以快速跳跃那些小于7的元素。很快,查找过程就能到元素6.由于在第2层,元素8大于7,故肯定无法在第2层找到元素7,故直接进入底层(包含所有元素)开始查找,并且很快就可以根据元素6搜索到元素7.整个过程,要比一般链表从元素1开始逐个搜索快很多。
因此,很显然,跳表是一种使用空间换时间的算法。
使用跳表实现Map和使用哈希算法实现Map的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内的所有元素都是有序的。因此在对跳表进行遍历时,你会得到一个有序的结果。所以,如果你的应用需要有序性,那么跳表就是你不二的选择。
实现这一数据结构的类是ConcurrentSkipListMap。下面展示了跳表的简单使用:
Map<Integer, Integer> map = new ConcurrentSkipListMap<Integer, Integer>();
for (int i = 0; i < 30; i++) {
map.put(i, i);
}
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey());
}
- 和HashMap不同,对跳表的遍历输出是有序的。
- 跳表的内部实现有几个关键的数据结构组成。首先是Node,一个Node就是表示一个节点,里面含有两个重要的元素key和value(就是Map的key和)。每个Node还会指向下一个Node,因此还有一个元素next。
static final class Node<K, V> {
final K key;
volatile Object value;
volatile Node<K, V> next;
}
- 对Node的所有操作,使用的CAS方法:
boolean casValue(Object cmp, Object val) {
return UNSAFE.compareAndSwapObject(this, valueOffset, cmp, val);
}
boolean casNext(Node<K, V> cmp, Node<K, V> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
- 方法casValue()用来设置value的值,相对的casNext()用来设置next的字段。
- 另外一个重要的数据结构是Index。顾名思义,这个表示索引。它内部包装了Node,同时增加了向下的引用和向右的引用。
static class Index<K, V> {
final Node<K, V> node;
final Index<K, V> down;
volatile Index<K, V> right;
}
- 整个跳表就是根据Index进行全网的组织的。
- 此外,对于每一层的表头,还需要记录当前处于哪一层。为此,还需要一个称为HeadIndex的数据结构,表示链表头部的第一个Index。它继承自Index。
static final class HeadIndex<K, V> exetends Index<K, V> {
final int level;
HeadIndex(Node<K, V> node, Index<K, V> down, Index<K, V> right, int level) {
super(node, down, right);
this.level = level;
}
}
- 这样核心的内部元素就介绍完成了。对于跳表的所有操作,就是组织好这些Index之间连接关系。
第3章 JDK并发包(五)的更多相关文章
- 第3章 JDK并发包(三)
3.2 线程复用:线程池 一种最为简单的线程创建和回收的方法类似如下代码: new Thread(new Runnable() { @Override public void run() { // d ...
- 第3章 JDK并发包(四)
3.2.5 自定义线程创建:ThreadFactory 线程池的主要作用是为了线程复用,也就是避免了线程的频繁创建. ThreadFactory是一个接口,它只有一个方法,用来创建线程: Thread ...
- 第3章 JDK并发包(二)
3.1.2 重入锁的好搭档:Condition条件 它和wait()和notify()方法的作用是大致相同的.但是wait()和notify()方法是和synchronized关键字合作使用的,而Co ...
- 第3章 JDK并发包(一)
3.1 多线程的团队协作:同步控制 3.1.1 synchronized的功能扩展:重入锁 重入锁可以完全替代synchronized关键字. 重入锁使用java.util.concurrent.lo ...
- Java 并发编程实践基础 读书笔记: 第三章 使用 JDK 并发包构建程序
一,JDK并发包实际上就是指java.util.concurrent包里面的那些类和接口等 主要分为以下几类: 1,原子量:2,并发集合:3,同步器:4,可重入锁:5,线程池 二,原子量 原子变量主要 ...
- Java并发程序设计(四)JDK并发包之同步控制
JDK并发包之同步控制 一.重入锁 重入锁使用java.util.concurrent.locks.ReentrantLock来实现.示例代码如下: public class TryReentrant ...
- 3 JDK并发包
JDK内部提供了大量实用的API和框架.本章主要介绍这些JDK内部功能,主要分为3大部分: 首先,介绍有关同步控制的工具,之前介绍的synchronized就是一种同步控制手段,将介绍更加丰富的多线程 ...
- Java多线程--JDK并发包(2)
Java多线程--JDK并发包(2) 线程池 在使用线程池后,创建线程变成了从线程池里获得空闲线程,关闭线程变成了将线程归坏给线程池. JDK有一套Executor框架,大概包括Executor.Ex ...
- Java多线程--JDK并发包(1)
Java多线程--JDK并发包(1) 之前介绍了synchronized关键字,它决定了额一个线程是否可以进入临界区:还有Object类的wait()和notify()方法,起到线程等待和唤醒作用.s ...
随机推荐
- 学习集合Collection_通用方法
Collection 常用接口 集合List和Set通用的方法 public boolean add(E e) 添加对象到集合 public boolean remove(E e) 删除指定元素 pu ...
- 字符串String类常见算法题
1.将一个字符串进行反转.将字符串中指定部分进行反转. public class StringDemo { //方式一:转换为char[] public String reverse(String s ...
- Spring Boot2 系列教程 (六) | 使用 JdbcTemplates 访问 Mysql
前言 如题,今天介绍 springboot 通过jdbc访问关系型mysql,通过 spring 的 JdbcTemplate 去访问. 准备工作 SpringBoot 2.x jdk 1.8 mav ...
- 搞定SpringBoot多数据源(2):动态数据源
目录 1. 引言 2. 动态数据源流程说明 3. 实现动态数据源 3.1 说明及数据源配置 3.1.1 包结构说明 3.1.2 数据库连接信息配置 3.1.3 数据源配置 3.2 动态数据源设置 3. ...
- Go 每日一库之 cobra
简介 cobra是一个命令行程序库,可以用来编写命令行程序.同时,它也提供了一个脚手架, 用于生成基于 cobra 的应用程序框架.非常多知名的开源项目使用了 cobra 库构建命令行,如Kubern ...
- 美团codem 数列互质 - 莫队
题目描述 给出一个长度为 nnn 的数列 a1,a2,a3,...,an{ a_1 , a_2 , a_3 , ... , a_n }a1,a2,a3,...,an,以及 mm ...
- 使用 OAS(OpenAPI标准)来描述 Web API
无论哪种类型的Web API, 都可能需要给其他开发者使用. 所以API的开发者体验是很重要的. API的开发者体验, 简写为 API DX (Developer Experience). 它包含很多 ...
- Activiti邮件任务
Activiti邮件任务 作者:Jesai 会不会有那么一天,你会妒忌 Activiti有一种任务叫做邮件任务,顾名思义,就是流程办理到邮件任务的时候,系统就会自动的给你发送任务. Activiti所 ...
- 异常java.lang.NoSuchMethodError: org.springframework.core.GenericTypeResolver.resolveTypeArguments(Ljava/lang/Class;Ljava/lang/Class;)[Ljava/lang/Class;
java.lang.NoSuchMethodError: org.springframework.core.GenericTypeResolver.resolveTypeArguments(Ljava ...
- THUWC2020 自闭记
DAY 1 报道 领胸牌和-围巾-! 发现我和 \(ssf\) 小姐姐一个考场. 合影+开幕式 宾馆睡了一觉-睡上午觉真的舒服. 合影时在c位! 开幕式.比上次夏令营不知道好到哪里去了,讲话都挺有意思 ...