requests库结合selenium库共同完成web自动化和爬虫工作
我们日常工作中,单纯的HTTP请求,程序员都倾向于使用万能的python Requests库。但大多数场景下,我们的需求页面不是纯静态网页,网页加载过程中伴随有大量的JS文件参与页面的整个渲染过程,且页面的每一步操作可能都能找到异步加载XHR的影子。所以Requests库不是万能的,Requests-Html库就能解决一部分问题,前提是您知道这个过程加载了哪些js文件。小爬的实际工作中,更倾向于Requests+selenium的模式来完成整个网页信息的爬取。
能用Requests库直接请求获得数据的,就直接用requests的Session类来请求,碰到页面中JS载入较多的,就切换到selenium来执行。
那么问题来了,如何从requests优雅地切换到selenium来完成整个网页的自动化过程呢?很多时候,我们的页面信息爬取,服务器都是要求用户先登陆的,然后每次请求的时候保证会话session和基本cookies不变,就可以一直保证后台的登陆状态。那么requests库的cookies如何传给selenium用呢?这样切换到selenium时,我们不用再次登陆,而是直接用requests给的cookies绑定到 selenium下,请求目标网页,打开的网页就可以天然是登陆状态了。
我们先使用requests库来登陆,代码通常是这样(需要抓包看后台的post请求的data参数,我们请求前构造这个参数就可以了,每个网页的登陆的data参数不尽相同):
loginData={'redirect':'','username':username,'password':psw}
session = requests.Session()
r=session.post('%sportal/u/a/login.do'%base_url,loginData)
完成这部操作后,我们可以通过Post请求的status_code是否等于200来判断页面是否成功登陆。一旦登陆成功,则我们的session请求该网站后续的网页时,这个session就可以一直保持下去了。
接下来,我么要拿到requests登陆网站后的cookies,它是requests的Cookiejar类的一个实例。Cookiejar简单来说就是获取响应的cookie,cookie是存储在浏览器的一些信息,包括用户的登陆信息和一些操作,我们从服务器中获取的响应信息中,有时候也会包含一些cookie信息。

问题是这个cookiejar对象不是我们常见的字典型cookies对象,我们需要利用requests库的utils.dict_from_cookiejar方法来把cookiejar对象转换为python的字典对象。
cookies=session.cookies
cookies=requests.utils.dict_from_cookiejar(cookies)
得到的cookies大概如下形式:
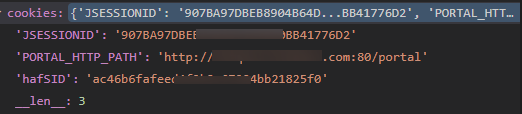
但是这依然不是selenium支持的cookies格式。实际上,selenium使用driver.get_cookies()方法得到的cookies如下:列表中包含多个cookie字典,每个字典中包含多个键值对,而所有的键中,有的不是必须的,但是“name","value"这两个键是必填的。
"""传递request cookie给 selenium用"""
for k,v in cookies.items():
driver.add_cookie({"name":k,"value":v})
需要注意的是,必须先要driver.get(your url),然后才能使用driver.add_cookie方法,否则selenium会报错。
至此,我们的selenium就成功添加了requests中捕获的响应的cookies,我们的selenium就不用再被服务器要求先登陆了。requests就和selenium完成了无缝衔接,完美!
requests库结合selenium库共同完成web自动化和爬虫工作的更多相关文章
- Selenium+Python+jenkins搭建web自动化测测试框架
python-3.6.2 chrome 59.0.3071.115 chromedriver 2.9 安装python https://www.python.org/downloads/ (Wind ...
- windiows下搭建python+selenium+unittest+Chrome的Web自动化环境
一.selenium.unittest概念 Selenium 是用于测试 Web 应用程序用户界面 (UI) 的常用框架.它是一款用于运行端到端功能测试的超强工具.您可以使用多个编程语言编写测试,并且 ...
- Java+Selenium 3.x 实现Web自动化 - 1.自动化准备
(一)自动化准备 说明:本文主要记录了基于公司现有项目(一个电子商务平台),从0开始实现UI自动化的历程.从准备阶段,部分内容直接省略了基础知识,一切以最终做成自动化项目为目标,难免会有晦涩之处.文章 ...
- Java+Selenium 3.x 实现Web自动化 - Maven打包TestNG,利用jenkins执行测试
1. Jenkins本地执行测试 or 服务器端执行测试 测试代码计划通过jenkins执行时,通过网上查询各种教程,大多数为本地执行测试,由此可见,本地执行是大多数人的选择. 经过探讨,最终决定采用 ...
- python应用之爬虫实战2 请求库与解析库
知识内容: 1.requests库 2.selenium库 3.BeautifulSoup4库 4.re正则解析库 5.lxml库 参考: http://www.cnblogs.com/wupeiqi ...
- 爬虫实战:爬虫之 web 自动化终极杀手 ( 上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:陈象 导语: 最近写了好几个简单的爬虫,踩了好几个深坑,在这里总结一下,给大家在编写爬虫时候能给点思路.本次爬虫内容有:静态页面的爬 ...
- 爬虫 - 请求库之selenium
介绍 官方文档 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的 ...
- python爬虫---selenium库的用法
python爬虫---selenium库的用法 selenium是一个自动化测试工具,支持Firefox,Chrome等众多浏览器 在爬虫中的应用主要是用来解决JS渲染的问题. 1.使用前需要安装这个 ...
- Python3 使用selenium库登陆知乎并保存cookie为本地文件
Python3 使用selenium库登陆知乎并保存cookie为本地文件 学习使用selenium库模拟登陆知乎,并将cookie保存为本地文件,然后供以后(requests模块)使用,用selen ...
随机推荐
- sql —— group by
说明: 从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理. 原表: 执行分组查询: select G ...
- java代码简单实现栈
1. 基于数组简单实现 /** * @author <a herf="mailto:yanwu0527@163.com">XuBaofeng</a> * @ ...
- Hbase数据模型概念视图
- uva 11754 Code Feat (中国剩余定理)
UVA 11754 一道中国剩余定理加上搜索的题目.分两种情况来考虑,当组合总数比较大的时候,就选择枚举的方式,组合总数的时候比较小时就选择搜索然后用中国剩余定理求出得数. 代码如下: #includ ...
- DispatcherTimer 应用实例
public partial class MainWindow : Window { public MainWindow() { InitializeComponent(); //实例化 Dispat ...
- Element-ui学习笔记3--Form表单(三)
InputNumber <el-input-number v-model="num" @change="handleChange" :min=" ...
- js实现圆形的碰撞检测
文章地址:https://www.cnblogs.com/sandraryan/ 碰撞检测这个东西写小游戏挺有用der~~~ 注释写的还挺全,所以就不多说了,看注释 这是页面结构.wrap存放生成的小 ...
- 深入Java线程管理(五):线程池
这几天主要是狂看源程序,在弥补了一些以前知识空白的同时,也学会了不少新的知识(比如 NIO),或者称为新技术吧. 线程池就是其中之一,一提到线程,我们会想到以前<操作系统>的生产者与消费者 ...
- JS中数组声明
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 深入java面向对象四:Java 内部类种类及使用解析(转)
内部类Inner Class 将相关的类组织在一起,从而降低了命名空间的混乱. 一个内部类可以定义在另一个类里,可以定义在函数里,甚至可以作为一个表达式的一部分. Java中的内部类共分为四种: 静态 ...