kafka学习默认端口号9092
一 Kafka 概述
1.1 Kafka 是什么
在流式计算中,Kafka 一般用来缓存数据,Storm 通过消费 Kafka 的数据进行计算。
1)Apache Kafka 是一个开源消息系统(微信公众号、QQ、微信等群),由 Scala 写成。
是由 Apache 软件基金会开发的一个开源消息系统项目。
2)Kafka 最初是由 LinkedIn 公司开发,并于 2011 年初开源。2012 年 10 月从 Apache
Incubator 毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低延时的平台。
3)Kafka 是一个分布式消息队列。Kafka 对消息保存时根据 Topic 进行归类,发送消息
者称为 Producer,消息接受者称为 Consumer,此外 kafka 集群有多个 kafka 实例组成,每个
实例(server)成为 broker。Redis 分布式界内的小钢炮!!!!
4)无论是 kafka 集群,还是 producer 和 consumer 都依赖于 zookeeper 集群保存一些
meta 信息,来保证系统可用性。
1.2 消息队列内部实现原理
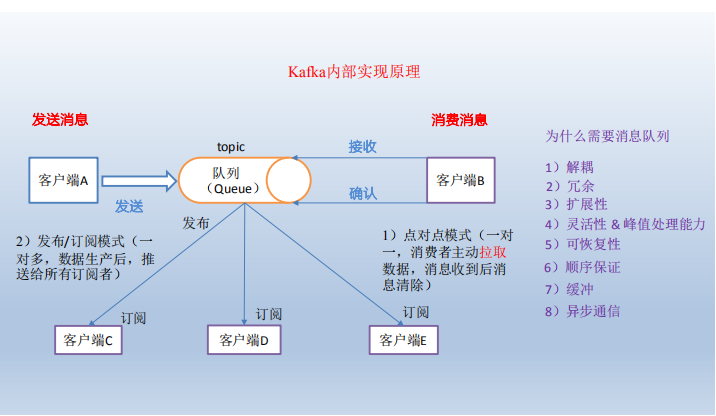
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信
息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接
收者接收处理,即使有多个消息监听者也是如此。
(2)发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅
者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即
使当前订阅者不可用,处于离线状态。
为什么需要消息队列
1)解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风
险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需
要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你
使用完毕。
3)扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要
另外增加处理过程即可。
4)灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。
如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列
能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所
以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6)顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且
能保证数据会按照特定的顺序来处理。(Kafka 保证一个 Partition 内的消息的有序性)
7)缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致
的情况。
8)异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户
把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要
的时候再去处理它们。
1.4 Kafka 架构
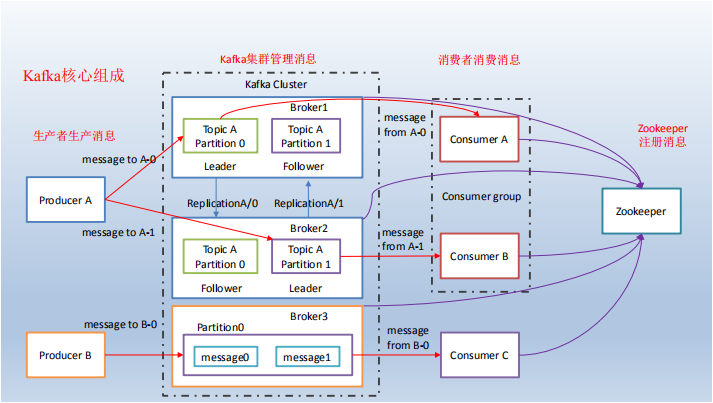
1)Producer :消息生产者,就是向 kafka broker 发消息的客户端。
2)Consumer :消息消费者,向 kafka broker 取消息的客户端
3)Topic :可以理解为一个队列。
4)Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)
和单播(发给任意一个 consumer)的手段。一个 topic 可以有多个 CG。topic 的消息会复制-
给 consumer。如果需要实现广播,只要每个 consumer 有一个独立的 CG 就可以了。要实现
单播只要所有的 consumer 在同一个 CG。用 CG 还可以将 consumer 进行自由的分组而不需
要多次发送消息到不同的 topic。
5)Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker
可以容纳多个 topic。
6)Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,
一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。partition 中的每条消息
都会被分配一个有序的 id(offset)。kafka 只保证按一个 partition 中的顺序将消息发给
consumer,不保证一个 topic 的整体(多个 partition 间)的顺序。
7)Offset:kafka 的存储文件都是按照 offset.kafka 来命名,用 offset 做名字的好处是方便查
找。例如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。当然 the first offset 就
是 00000000000.kafka
1.5 分布式模型
Kafka 每个主题的多个分区日志分布式地存储在 Kafka 集群上,同时为了故障容错,每
个分区都会以副本的方式复制到多个消息代理节点上。其中一个节点会作为主副本
(Leader),其他节点作为备份副本(Follower,也叫作从副本)。主副本会负责所有的客
户端读写操作,备份副本仅仅从主副本同步数据。当主副本出现故障时,备份副本中的一个
副本会被选择为新的主副本。因为每个分区的副本中只有主副本接受读写,所以每个服务器
端都会作为某些分区的主副本,以及另外一些分区的备份副本,这样 Kafka 集群的所有服务
端整体上对客户端是负载均衡的。
Kafka 的生产者和消费者相对于服务器端而言都是客户端。
Kafka 生产者客户端发布消息到服务端的指定主题,会指定消息所属的分区。生产者发
布消息时根据消息是否有键,采用不同的分区策略。消息没有键时,通过轮询方式进行客户
端负载均衡;消息有键时,根据分区语义(例如 hash)确保相同键的消息总是发送到同一
分区。
Kafka 的消费者通过订阅主题来消费消息,并且每个消费者都会设置一个消费组名称。
因为生产者发布到主题的每一条消息都只会发送给消费者组的一个消费者。所以,如果要实
现传统消息系统的“队列”模型,可以让每个消费者都拥有相同的消费组名称,这样消息就
会负责均衡到所有的消费者;如果要实现“发布-订阅”模型,则每个消费者的消费者组名
称都不相同,这样每条消息就会广播给所有的消费者。
分区是消费者现场模型的最小并行单位。如下图(图 1)所示,生产者发布消息到一台
服务器的 3 个分区时,只有一个消费者消费所有的 3 个分区。在下图(图 2)中,3 个分区
分布在 3 台服务器上,同时有 3 个消费者分别消费不同的分区。假设每个服务器的吞吐量时
300MB,在下图(图 1)中分摊到每个分区只有 100MB,而在下图(图 2)中,集群整体的
吞吐量有 900MB。可以看到,增加服务器节点会提升集群的性能,增加消费者数量会提升
处理性能。
同一个消费组下多个消费者互相协调消费工作,Kafka 会将所有的分区平均地分配给所
有的消费者实例,这样每个消费者都可以分配到数量均等的分区。Kafka 的消费组管理协议
会动态地维护消费组的成员列表,当一个新消费者加入消费者组,或者有消费者离开消费组,
都会触发再平衡操作。

Kafka 的消费者消费消息时,只保证在一个分区内的消息的完全有序性,并不保证同一
个主题汇中多个分区的消息顺序。而且,消费者读取一个分区消息的顺序和生产者写入到这
个分区的顺序是一致的。比如,生产者写入“hello”和“Kafka”两条消息到分区 P1,则消
费者读取到的顺序也一定是“hello”和“Kafka”。如果业务上需要保证所有消息完全一致,
只能通过设置一个分区完成,但这种做法的缺点是最多只能有一个消费者进行消费。一般来
说,只需要保证每个分区的有序性,再对消息假设键来保证相同键的所有消息落入同一分区,
就可以满足绝大多数的应用。
二 Kafka 集群部署
kafka学习默认端口号9092的更多相关文章
- SpringBoot修改默认端口号
SpringBoot修改默认端口号 server.port=8088 学习了:https://blog.csdn.net/zknxx/article/details/53433592 java -ja ...
- 修改Tomcat服务器的默认端口号
tomcat服务器的默认端口号是8080,我们也可以修改为其他端口号,并且在没有启动Apache,IIS等占用80端口的web服务时,我们也可以设置为80端口,这样在生产中域名之后就可以不带端口号了, ...
- SSAS更改默认端口号,使用非默认端口号的时候Olap连接字符串的格式
Sql server的Analysis Service服务默认使用的是2382或2383端口,但是实际上我们可以通过配置文件手动更改SSAS使用其它端口号. 修改SSAS使用端口号的方法如下,找到你的 ...
- MySql修改默认端口号,修改my.ini的端口号
MySql默认端口号为3306,如果安装多个或者冲突需要修改端口号,修改my.ini的端口号就可以了,文件一般情况下在安装目录下.下面是具体说明: 方法/步骤 先在服务里停止mysql的服务器,再找到 ...
- SQLSERVER 更改默认端口号
最近这几天,服务器的数据库(SQLSERVER)老是遭受到攻击,有人不断地轮训想登陆数据库,从SQL的日志里可以看出来,一开始我是通过本地安全策略禁用了对应的几个攻击ip,同时把数据库的sa账号给禁用 ...
- sqlserver、mysql、oracle各自的默认端口号
sqlserver默认端口号为:1433 URL:"jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=dbname" D ...
- RHEL 7修改ssh默认端口号
RHEL7修改默认端口号(默认port22)初次安装系统完毕后默认情况下系统已经启动了sshd服务当然我们也可以先进行检查: 步骤1,检查是否已安装ssh服务 步骤2,检查服务是否已开启 如上图所示显 ...
- react项目和next项目修改默认端口号
creat-react-app生成的项目默认端口号是3000,如下可以更改: 在package.json中修改 "start":"react-scripts start& ...
- jmeter修改ServerAgent的默认端口号
jmeter修改ServerAgent的默认端口号 1 java -jar ./CMDRunner.jar --tool PerfMonAgent --udp-port 5555 --tcp-port ...
随机推荐
- histroy.back和histroy.go的区别
histroy.back(-1):直接返回当前页的上一页,数据全部消失,是个新的页面: histroy.go(-1):直接返回当前页的上一页,不过表单里的数据全部还在: histroy.back(0) ...
- day9-数据库操作与Paramiko模块
堡垒机前戏 开发堡垒机之前,先来学习Python的paramiko模块,该模块机遇SSH用于连接远程服务器并执行相关操作 SSHClient 用于连接远程服务器并执行基本命令 基于用户名密码连接: 1 ...
- scrapy框架的持久化存储
一 . 基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存 ...
- Delphi IOS MusicPlayer 锁屏运行学习
[weak] FMusicPlayer: TMusicPlayer; [weak]修饰, 编译器在处理这个变量的时候不会调用该变量内容的__ObjAddRef和__ObjRelease., proce ...
- Python之路,Day9 , IO多路复用(番外篇)
同步IO和异步IO,阻塞IO和非阻塞IO分别是什么,到底有什么区别?不同的人在不同的上下文下给出的答案是不同的.所以先限定一下本文的上下文. 本文讨论的背景是Linux环境下的network IO. ...
- UNITY所谓的异步加载几乎全部是协程,不是线程;MAP3加载时解压非常慢
实践证明,以下东西都是协程,并非线程(thread): 1,WWW 2,AssetBundle.LoadFromFileAsync 3,LoadSceneAsync 其它未经测试 此问题的提出是由于一 ...
- 使用crontab设置定时任务
配置文件 crontab主要的配置文件如下: /etc/crontab:系统cron表 /etc/cron.d/*:保存由软件包安装脚本创建的cron文件的目录 /var/spool/cron/*:保 ...
- Hash表从了解到深入(浅谈)
· Hasn表,将一个数据进行Value化,再进行一个映射关系到Key直接进行访问的一个数据结构,这样可以通过直接的计算进行数据的访问和插入.关于Hash表的基本概念这里就不一一叙述,可以通过百度了解 ...
- slf4j日志框架
- Android开发实战之简单音乐播放器
最近开始学习音频相关.所以,很想自己做一个音乐播放器,于是,花了一天学习,将播放器的基本功能实现了出来.我觉得学习知识点还是蛮多的,所以写篇博客总结一下关于一个音乐播放器实现的逻辑.希望这篇博文对你的 ...