吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import cluster
from sklearn.metrics import adjusted_rand_score
from sklearn.datasets.samples_generator import make_blobs def create_data(centers,num=100,std=0.7):
X, labels_true = make_blobs(n_samples=num, centers=centers, cluster_std=std)
return X,labels_true # 用于产生聚类的中心点
centers=[[1,1],[2,2],[1,2],[10,20]]
# 产生用于聚类的数据集
X,labels_true=create_data(centers,1000,0.5) #K-MEANS聚类模型
def test_Kmeans(*data):
X,labels_true=data
clst=cluster.KMeans()
clst.fit(X)
predicted_labels=clst.predict(X)
print("ARI:%s"% adjusted_rand_score(labels_true,predicted_labels))
print("Sum center distance %s"%clst.inertia_) # 用于产生聚类的中心点
centers=[[1,1],[2,2],[1,2],[10,20]]
# 产生用于聚类的数据集
X,labels_true=create_data(centers,1000,0.5)
# 调用 test_Kmeans 函数
test_Kmeans(X,labels_true)
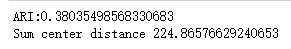
def test_Kmeans_nclusters(*data):
'''
测试 KMeans 的聚类结果随 n_clusters 参数的影响
'''
X,labels_true=data
nums=range(1,50)
ARIs=[]
Distances=[]
for num in nums:
clst=cluster.KMeans(n_clusters=num)
clst.fit(X)
predicted_labels=clst.predict(X)
ARIs.append(adjusted_rand_score(labels_true,predicted_labels))
Distances.append(clst.inertia_)
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,2,1)
ax.plot(nums,ARIs,marker="+")
ax.set_xlabel("n_clusters")
ax.set_ylabel("ARI")
ax=fig.add_subplot(1,2,2)
ax.plot(nums,Distances,marker='o')
ax.set_xlabel("n_clusters")
ax.set_ylabel("inertia_")
fig.suptitle("KMeans")
plt.show() test_Kmeans_nclusters(X,labels_true) # 调用 test_Kmeans_nclusters 函数

def test_Kmeans_n_init(*data):
'''
测试 KMeans 的聚类结果随 n_init 和 init 参数的影响
'''
X,labels_true=data
nums=range(1,50)
## 绘图
fig=plt.figure() ARIs_k=[]
Distances_k=[]
ARIs_r=[]
Distances_r=[]
for num in nums:
clst=cluster.KMeans(n_init=num,init='k-means++')
clst.fit(X)
predicted_labels=clst.predict(X)
ARIs_k.append(adjusted_rand_score(labels_true,predicted_labels))
Distances_k.append(clst.inertia_) clst=cluster.KMeans(n_init=num,init='random')
clst.fit(X)
predicted_labels=clst.predict(X)
ARIs_r.append(adjusted_rand_score(labels_true,predicted_labels))
Distances_r.append(clst.inertia_) ax=fig.add_subplot(1,2,1)
ax.plot(nums,ARIs_k,marker="+",label="k-means++")
ax.plot(nums,ARIs_r,marker="+",label="random")
ax.set_xlabel("n_init")
ax.set_ylabel("ARI")
ax.set_ylim(0,1)
ax.legend(loc='best')
ax=fig.add_subplot(1,2,2)
ax.plot(nums,Distances_k,marker='o',label="k-means++")
ax.plot(nums,Distances_r,marker='o',label="random")
ax.set_xlabel("n_init")
ax.set_ylabel("inertia_")
ax.legend(loc='best') fig.suptitle("KMeans")
plt.show() test_Kmeans_n_init(X,labels_true) # 调用 test_Kmeans_n_init 函数

吴裕雄 python 机器学习——K均值聚类KMeans模型的更多相关文章
- 吴裕雄 python 机器学习——混合高斯聚类GMM模型
import numpy as np import matplotlib.pyplot as plt from sklearn import mixture from sklearn.metrics ...
- 吴裕雄 python 机器学习——超大规模数据集降维IncrementalPCA模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——数据预处理正则化Normalizer模型
from sklearn.preprocessing import Normalizer #数据预处理正则化Normalizer模型 def test_Normalizer(): X=[[1,2,3, ...
- 吴裕雄 python 机器学习——数据预处理标准化MaxAbsScaler模型
from sklearn.preprocessing import MaxAbsScaler #数据预处理标准化MaxAbsScaler模型 def test_MaxAbsScaler(): X=[[ ...
- 吴裕雄 python 机器学习——数据预处理标准化StandardScaler模型
from sklearn.preprocessing import StandardScaler #数据预处理标准化StandardScaler模型 def test_StandardScaler() ...
- 吴裕雄 python 机器学习——数据预处理标准化MinMaxScaler模型
from sklearn.preprocessing import MinMaxScaler #数据预处理标准化MinMaxScaler模型 def test_MinMaxScaler(): X=[[ ...
- 吴裕雄 python 机器学习——支持向量机线性分类LinearSVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
- 吴裕雄 python 机器学习——数据预处理流水线Pipeline模型
from sklearn.svm import LinearSVC from sklearn.pipeline import Pipeline from sklearn import neighbor ...
随机推荐
- c/c++中关于String类型的思考
首先说明:String并不是一种内置类型,因此任何通过String声明出来的实例都不是一个变量,不同于内置类型因此String仅仅能称之为一种特殊的型别,没错String是一个类类型. 一般来说c语言 ...
- LSP(分层服务提供程序)
一.简介 LSP即分层服务提供商,Winsock 作为应用程序的 Windows 的网络套接字工具,可以由称为"分层服务提供商"的机制进行扩展.Winsock LSP 可用于非常广 ...
- Redis学习(3)——认识配置文件redis.conf[转]
#是否作为守护进程运行 daemonize yes #配置 pid 的存放路径及文件名,默认为当前路径下 pidfile redis.pid #Redis 默认监听端口 port 6379 ...
- MYSQl修改临时文件目录
MSYQL在执行查询语句时报出以下错误: ERROR 3(HY000):Error writing file 'tmp/MY1yjZEI'(Errcode:28) 看了下/tmp所在目录的磁盘情况,发 ...
- C#序列化效率对比
原文出处:https://www.cnblogs.com/landeanfen/p/4627383.html 从使用序列化到现在,用到的无非下面几种方式:(1)JavaScriptSerializer ...
- 转:开启命令行下的社交-webqq脚本
最近一直在命令行下工作,除了 Google Chrome,几乎很少接触 GUI 相关的软件.前段时间把手机上的 QQ 给卸载了,希望可以把时间凝聚在更加有价值的位置,今天突然又想起了这个软件,突发奇想 ...
- 基于JSP+Servlet开发手机销售购物商城系统(前台+后台)源码
基于JSP+Servlet开发手机销售购物商城系统(前台+后台) 开发环境: Windows操作系统 开发工具:Eclipse/MyEclipse+Jdk+Tomcat+MySQL数据库 运行效果图: ...
- [js]利用闭包向post回调函数传参数
最近在闲逛校园XX站的时候,打算搞个破坏,试试有多少人还是用初始密码登陆.比较懒,所以直接打开控制台来写. 所以问题可以描述为: 向后端不断的post数据,id从1~5000自增,后端会根据情况来返回 ...
- [javascript]模块化&命名污染—from 编程精解
最近看了编程精解里面的模块化一章,很受启发. /****************/ 在开发的实际过程中,根据页面或者逻辑布局,js代码可以按照功能划分为若干个区块:数据交互.表单验证.页面布局等等模块 ...
- SSL证书 .pem转.pfx
使用OpenSSL来进行转换 OpenSSL官网没有提供windows版本的安装包,可以选择其他开源平台提供的工具.例如 http://slproweb.com/products/Win32OpenS ...