3、TensorFlow基础(一) 设计思想与编程模型
1、TensorFlow系统架构
如图为TensorFlow的系统架构图:
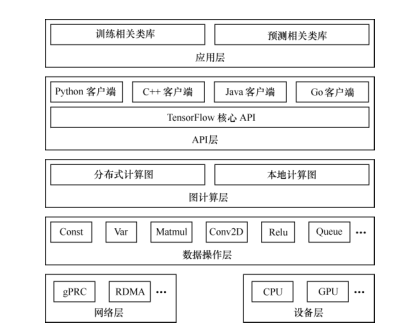
TensorFlow的系统架构图,自底向上分为设备层和网络层、数据操作层、图计算层、API层、应用层,其中设备层和网络层,数据操作层,图计算层是TensorFlow的核心层。
网络通信层和设备层:
网络通信层包括个gRPC(google Remote Procedure Call Protocol)和远程直接数据存取(Remote DirectMemory Access,RDMA),这都是在分布式计算时需要用到的。设备管理层包括 TensorFlow 分别在 CPU、GPU、FPGA 等设备上的实现,也就是对上层提供了一个统一的接口,使上层只需要处理卷积等逻辑,而不需要关心在硬件上的卷积的实现过程。
数据操作层:
主要包括卷积函数、激活函数等操作
图计算层:
包含本地计算图和分布式计算图的实现
API 层和应用层
编程语言的实现与应用
2、设计理念
TensorFlow的设计理念主要体现在两个方面
(1)、将图定义和图运算完全分开。
TensorFlow 被认为是一个“符号主义”的库。我们知道,编程模式通常分为命令式编程(imperative style programming)和符号式编程(symbolic style programming)。命令式编程就是编写我们理解的通常意义上的程序,很容易理解和调试,按照原有逻辑执行。符号式编程涉及很多的嵌入和优化,不容易理解和调试,但运行速度相对有所提升。现有的深度学习框架中,Torch 是典型的命令式的,Caffe、MXNet 采用了两种编程模式混合的方法,而 TensorFlow 完全采用符号式编程。
符号式计算一般是先定义各种变量,然后建立一个数据流图,在数据流图中规定各个变量间的计算关系,最后需要对据流图进行编译,但此时的数据流图还是一个空壳儿,里面没有任何实际数据,只有把需要运算的输入放进去后,才能在整个模型中形成数据流,从而形成输出值。
例如:
t = 8+ 9
print(t)
在传统的程序操作中,定义了 t 的运算,在运行时就执行了,并输出 17。而在 TensorFlow
中,数据流图中的节点,实际上对应的是 TensorFlow API 中的一个操作,并没有真正去运行:
import tensorflow as tf
t = tf.add(8,9)
print(t)
#输出 Tensor{"Add_1:0",shape={},dtype=int32}
(2)、TensorFlow 中涉及的运算都要放在图中,而图的运行只发生在会话(session)中。开启会话后,就可以用数据去填充节点,进行运算;关闭会话后,就不能进行计算了。因此,会话提供了操作运行和 Tensor 求值的环境。
例如:
import tensorflow as tf
#创建图
a = tf.constant([1.0,2.0])
b = tf.constant([3.0,4.0])
c = a * b
#创建会话
sess = tf.Session()
#计算c
print(sess.run(c))#进行矩阵乘法,输出[3.,8.]
sess.close()
3、TensorFlow编程模型
TensorFlow 是用数据流图做计算的,因此我们先创建一个数据流图(也称为网络结构图),
如图 下图 所示,看一下数据流图中的各个要素。
图 讲述了 TensorFlow 的运行原理。图中包含输入(input)、塑形(reshape)、Relu 层(Relulayer)、Logit 层(Logit layer)、Softmax、交叉熵(cross entropy)、梯度(gradient)、SGD 训练(SGD Trainer)等部分,是一个简单的回归模型。
它的计算过程是,首先从输入开始,经过塑形后,一层一层进行前向传播运算。Relu 层(隐藏层)里会有两个参数,即 W h1 和 b h1 ,在输出前使用 ReLu(Rectified Linear Units)激活函数做非线性处理。然后进入 Logit 层(输出层),学习两个参数 W sm 和 b sm 。用 Softmax 来计算输出结果中各个类别的概率分布。用交叉熵来度量两个概率分布(源样本的概率分布和输出结果的概率分布)之间的相似性。然后开始计算梯度,这里是需要参数 W h1 、b h1 、W sm 和 b sm ,以及交叉熵后的结果。随后进入 SGD 训练,也就是反向传播的过程,从上往下计算每一层的参数,依次进行更新。也就是说,计算和更新的顺序为 b sm 、W sm 、b h1 和 W h1 。
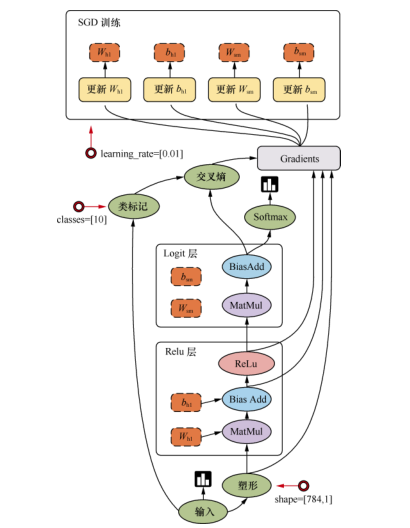
顾名思义,TensorFlow 是指“张量的流动”。TensorFlow 的数据流图是由节点(node)和边edge)组成的有向无环图(directed acycline graph,DAG)。TensorFlow 由 Tensor 和 Flow 两部分组成,Tensor(张量)代表了数据流图中的边,而 Flow(流动)这个动作就代表了数据流图中节点所做的操作
3.1、边
TensorFlow 的边有两种连接关系:数据依赖和控制依赖。其中,实线边表示数据依赖代表数据,即张量。任意维度的数据统称为张量。在机器学习算法中,张量在数据流图中从前往后流动一遍就完成了一次前向传播(forword propagation),而残差 从后向前流动一遍就完成了一次反向传播(backword propagation)。
注:在数理统计中,残差是指实际观测值于训练的估计值之间的差
还有一种特殊边,一般画为虚线边,称为控制依赖(control dependency),可以用于控制操作的运行,这被用来确保 happens-before 关系,这类边上没有数据流过,但源节点必须在目的节点开始执行前完成执行。常用代码:
tf.Graph.control_dependencies(control_inputs)
Tensorflow支持的张量的数据属性:
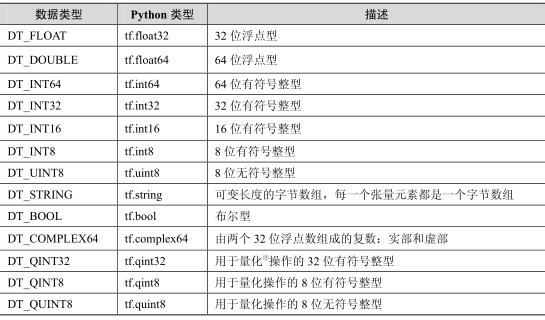
有关图及张量的实现的源代码均位于 tensorflow-1.1.0/tensorflow/python/framework/ops.py
3.2、节点
图中的节点又称为算子,它代表一个操作(operation,OP),一般用来表示施加的数学运算,也可以表示数据输入(feed in)的起点以及输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。下表列举了一些 TensorFlow 实现的算子。算子支持表所示的张量的各种数据属性,并且需要在建立图的时候确定下来。

与操作相关的代码位于 tensorflow-1.1.0/tensorflow/python/ops/目录下。以数学运算为例,代码为上述目录下的 math_ops.py,里面定义了 add、subtract、multiply、scalar_mul、div、divide、truediv、floordiv 等数学运算,每个函数里面调用了 gen_math_ops.py 中的方法,这个文件是在编译(安装时)TensorFlow 时生成的,位于 Python 库 site-packages/tensorflow/python/ops/gen_math_ops.py 中,随后又调用了 tensorflow1.1.0/tensorflow/core/kernels/下面的核函数实现。再例如,数据运算的代码位于 tensorflow-1.1.0/tensorflow/python/ops/array_ops.py 中,里面定义了concat、split、slice、size、rank 等运算,每个函数都调用了 gen_array_ops.py 中的方法,这个文件也是在编译TensorFlow 生成的,位于Python 库site-packages/tensorflow/python/ops/gen_array_ops.py中,随后又调用了 tensorflow-1.1.0/tensorflow/core/kernels/下面的核函数实现。
3.3、图
把操作任务描述成有向无环图。那么,如何构建一个图呢?构建图的第一步是创建各个节
点。具体如下:
import tensorflow as tf
# 创建一个常量运算操作,产生一个 1×2 矩阵
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量运算操作,产生一个 2×1 矩阵
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法运算 ,把 matrix1 和 matrix2 作为输入
# 返回值 product 代表矩阵乘法的结果
product = tf.matmul(matrix1, matrix2)
3.4、会话
启动图的第一步是创建一个 Session 对象。会话(session)提供在图中执行操作的一些方法。一般的模式是,建立会话,此时会生成一张空图,在会话中添加节点和边,形成一张图,然后执行。要创建一张图并运行操作的类,在 Python 的 API 中使用 tf.Session,在 C++ 的 API 中使用tensorflow::Session。示例如下:
with tf.Session() as sess:
result = sess.run([product])
print result
在调用 Session 对象的 run()方法来执行图时,传入一些 Tensor,这个过程叫填充(feed);返回的结果类型根据输入的类型而定,这个过程叫取回(fetch)。
与会话相关的源代码位于 tensorflow-1.1.0/tensorflow/python/client/session.py。
会话是图交互的一个桥梁,一个会话可以有个图,会话可以修改图的结构,也可以往图中注入数据进行计算。因此,会话主要有两个 API 接口:Extend 和 Run。Extend 操作是在 Graph中添加节点和边,Run 操作是输入计算的节点和填充必要的数据后,进行运算,并输出运算结果。
3.5、设备
设备(device)是指一块可以用来运算并且拥有自己的地址空间的硬件,如 GPU 和 CPU。TensorFlow 为了实现分布式执行操作,充分利用计算资源,可以明确指定操作在哪个设备上执行。具体如下:
with tf.Session() as sess:
# 指定在第二个 gpu 上运行
with tf.device("/gpu:1"):
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.],[2.]])
product = tf.matmul(matrix1, matrix2)
与设备相关的源代码位于 tensorflow-1.1.0/tensorflow/python/framework/device.py
3.6、变量
· 变量(variable)是一种特殊的数据,它在图中有固定的位置,不像普通张量那样可以流动。例如,创建一个变量张量,使用 tf.Variable()构造函数,这个构造函数需要一个初始值,初始值的形状和类型决定了这个变量的形状和类型:
# 创建一个变量,初始化为标量 0
state = tf.Variable(0, name="counter")
#创建一个常量张量:
input1 = tf.constant(3.0)
TensorFlow 还提供了填充机制,可以在构建图时使用 tf.placeholder()临时替代任意操作的张量,在调用 Session 对象的 run()方法去执行图时,使用填充数据作为调用的参数,调用结束后,填充数据就消失。代码示例如下:
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.multiply(input1, input2)
with tf.Session() as sess:
print sess.run([output], feed_dict={input1:[7.], input2:[2.]})
# 输出 [array([ 14.], dtype=float32)]
与变量相关的源代码位于 tensorflow/tensorflow/python/ops/variables.py。
3.7、内核
我们知道操作(operation)是对抽象操作(如 matmul 或者 add)的一个统称,而内核(kernel)则是能够运行在特定设备(如 CPU、GPU)上的一种对操作的实现。因此,同一个操作可能会对应多个内核。
当自定义一个操作时,需要把新操作和内核通过注册的方式添加到系统中
3、TensorFlow基础(一) 设计思想与编程模型的更多相关文章
- 学习笔记TF048:TensorFlow 系统架构、设计理念、编程模型、API、作用域、批标准化、神经元函数优化
系统架构.自底向上,设备层.网络层.数据操作层.图计算层.API层.应用层.核心层,设备层.网络层.数据操作层.图计算层.最下层是网络通信层和设备管理层.网络通信层包括gRPC(google Remo ...
- 一、基础篇--1.1Java基础-MVC设计思想
MVC简介: MVC(Model View Controller) 是模型(model)-视图(view)-控制器(controller)的缩写.一种软件设计典范,用一种业务逻辑.数据.界面显示分离的 ...
- 转:从《The C Programming Language》中学到的那些编程风格和设计思想
这儿有一篇写的很好的读后感:http://www.cnblogs.com/xkfz007/articles/2566424.html 读书不是目的,关键在于思考. 很早就在水木上看到有人推荐& ...
- 撰写一篇博客要求讲述四则运算2的设计思想,源程序代码、运行结果截图、编程总结分析,并按照PSP0级的要求记录开发过程中的时间记录日志。
一.撰写一篇博客要求讲述四则运算2的设计思想,源程序代码.运行结果截图.编程总结分析,并按照PSP0级的要求记录开发过程中的时间记录日志. 1.设计思想: ①创建test.jsp建立第一个前端界面,提 ...
- 小学生四则运算C/C++编程设计思想
题目: 1.题目避免重复: 2.可定制(数量(打印方式)): 3.可控制下列参数:是否有乘除法.是否有括号.数值范围.加减有无负数. 除法有无余数.是否支持分 ...
- 并行计算基础&编程模型与工具
在当前计算机应用中,对快速并行计算的需求是广泛的,归纳起来,主要有三种类型的应用需求: 计算密集(Computer-Intensive)型应用,如大型科学project计算与数值模拟: 数据密集(Da ...
- 老李分享: 并行计算基础&编程模型与工具 1
老李分享: 并行计算基础&编程模型与工具 在当前计算机应用中,对高速并行计算的需求是广泛的,归纳起来,主要有三种类型的应用需求: 计算密集(Computer-Intensive)型应用,如 ...
- 老李分享: 并行计算基础&编程模型与工具
在当前计算机应用中,对高速并行计算的需求是广泛的,归纳起来,主要有三种类型的应用需求: 计算密集(Computer-Intensive)型应用,如大型科学工程计算与数值模拟: 数据密集(Data-In ...
- FPGA设计思想与技巧(转载)
题记:这个笔记不是特权同学自己整理的,特权同学只是对这个笔记做了一下完善,也忘了是从那DOWNLOAD来的,首先对整理者表示感谢.这些知识点确实都很实用,这些设计思想或者也可以说是经验吧,是很值得每一 ...
随机推荐
- 8-机器分配(hud4045-组合+第二类斯特林数)
http://acm.hdu.edu.cn/showproblem.php?pid=4045 Machine schedulingTime Limit: 5000/2000 MS (Java/Othe ...
- linux常用的一些命令行操作(ubuntu)
软件安装 sudo apt-get install xxx 压缩和解压缩 1. *.tar 用 tar –xvf 解压 2. *.gz 用 gzip -d或者gunzip 解压 3. *.tar.gz ...
- jQuery中deferred对象的使用(一)
在jquery1.5之后的版本中,加入了一个deferred对象,也就是延迟对象,用来处理未来某一时间点发生的回调函数.同时,还改写了ajax方法,现在的ajax方法返回的是一个deferred对象. ...
- [Training Video - 6] [File Reading] [Java] Read Properties file
package com.file.properties; import java.io.FileInputStream; import java.util.Properties; public cla ...
- 福大软工 · BETA 版冲刺前准备(团队) [已完成]
写在前面 本次作业地址 林燊大哥 过去存在的问题 算法组 没有考虑到数据集不充足的情况.一开始我们将所有数据集按照8:1:1进行分割,分别分配给训练集.开发集和测试集.然鹅后来发现采集到的数据不够充足 ...
- IE6 BUG及解决方案
1.IE6中奇数宽高的BUG 一个外部的相对定位div,内部一个绝对定位的div(right:0) 可是在IE6下查看,却变成了right:1px的效果了: 解决方案就是将外部相对定位的div宽度改成 ...
- [GO]json解析到map
package main import ( "encoding/json" "fmt" ) var str string func main() { m := ...
- NBA常识 位置的划分 足球:越位等于抢跑
篮球:1号位——组织后卫(控球,组织)2号位——得分后卫(中远投篮,突破)3号位-----小前锋(突破,中远投篮)4号位——大前锋(二中锋,篮板,背身单打,禁区防守)5号位——中锋(篮板.背身单打,禁 ...
- [LintCode笔记了解一下]80.Median
Given a unsorted array with integers, find the median of it. A median is the middle number of the ar ...
- GCT感受
GCT考试已经结束了,但是复习GCT的时候一直没来得及总结点什么,GCT考的比较基础,所以复习起来并不是特别费力,但是还是有一些东西值得我们去学习的. 对于GCT考试,一开始在报名的时候其实心里是挺抵 ...