tensorflow(二)----线程队列与io操作
一、队列和线程
1、队列:
1)、tf.FIFOQueue(capacity, dtypes, name='fifo_queue') 创建一个以先进先出的顺序对元素进行排队的队列
参数:
capacity:整数。可能存储在此队列中的元素数量的上限
dtypes:DType对象列表。长度dtypes必须等于每个队列元 素中的张量数,dtype的类型形状,决定了后面进队列元素形状
方法:
q.dequeue()获取队列的数据
q.enqueue(值)将一个数据添加进队列
q.enqueue_many(列表或者元组)将多个数据添加进队列
q.size() 返回队列的大小
2)、tf.RandomShuffleQueue() 随机出的队列
2、队列管理器
tf.train.QueueRunner(queue, enqueue_ops=None)
参数:
queue:A Queue
enqueue_ops:添加线程的队列操作列表,[]*2,指定两个线程
create_threads(sess, coord=None,start=False) 创建线程来运行给定会话的入队操作
start:布尔值,如果True启动线程;如果为False调用者 必须调用start()启动线程
coord:线程协调器 用于线程的管理
3、线程协调器
tf.train.Coordinator() 线程协调员,实现一个简单的机制来协调一 组线程的终止
方法: 返回的是线程协调实例
request_stop() 请求停止
join(threads=None, stop_grace_period_secs=120) 等待线程终止
结合队列、队列管理器和线程协调器实现异步的小例:
import tensorflow as tf # 1.创建队列
Q = tf.FIFOQueue(2000, tf.float32) # 2.添加数据进队列
# 2.1创建一个数据(变量)
var = tf.Variable(0.0, tf.float32)
# 2.2数据自增
plus = tf.assign_add(var, 1)
# 2.3将数据添加进队列
en_q = Q.enqueue(plus) # 3.创建队列管理器
qr = tf.train.QueueRunner(Q, enqueue_ops=[en_q] * 2) # 4.变量初始化
init = tf.global_variables_initializer() # 5.创建会话
with tf.Session() as sess:
# 6.运行初始化
sess.run(init) # 7.创建线程协调器
coord = tf.train.Coordinator() # 8.开启子线程
threads = qr.create_threads(sess, coord=coord, start=True) # 9.主线程 从队列中取数据
for i in range(200):
print(sess.run(Q.dequeue())) # 10.线程回收
coord.request_stop()
coord.join(threads)
二、文件读取
1、文件读取流程
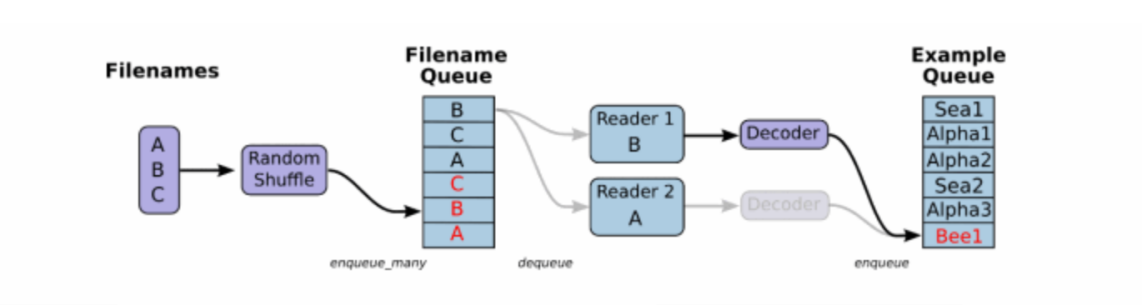
2、文件读取API
1)文件队列
tf.train.string_input_producer(string_tensor, ,shuffle=True) 将输出字符串(例如文件名)输入到管道队列
参数:
string_tensor 含有文件名的1阶张量
num_epochs:过几遍数据,默认无限过数据
返回:具有输出字符串的队列
2)文件阅读器(根据文件格式,选择对应的文件阅读器)
csv文件: class tf.TextLineReader 默认按行读取 返回:读取器实例
二进制文件: tf.FixedLengthRecordReader(record_bytes) record_bytes:整型,指定每次读取的字节数 返回:读取器实例
TfRecords文件: tf.TFRecordReader 返回:读取器实例
以上3个阅读器有一个相同的方法:
read(file_queue):从队列中指定数量内容 返回一个Tensors元组(key, value) 其中key是文件名字,value是默认的内容(行,字节)
3)文件内容解码器(由于从文件中读取的是字符串,需要函数去解析这些字符串到张量)
①tf.decode_csv(records,record_defaults=None,field_delim = None,name = None) 将CSV转换为张量,与tf.TextLineReader搭配使用
参数:
records:tensor型字符串,每个字符串是csv中的记录行
field_delim:默认分割符”,”
record_defaults:参数决定了所得张量的类型,并设置一个值在输入字符串中缺少使用默认值
②tf.decode_raw(bytes,out_type,little_endian = None,name = None) 将字节转换为一个数字向量表示,字节为一字符串类型的张量,与函数tf.FixedLengthRecordReader搭配使用,二进制读取为uint8格式
4)开启线程操作
tf.train.start_queue_runners(sess=None,coord=None) 收集所有图中的队列线程,并启动线程 sess:所在的会话中 coord:线程协调器 return:返回所有线程队列
5)管道读端批处理
①tf.train.batch(tensors,batch_size,num_threads = 1,capacity = 32,name=None) 读取指定大小(个数)的张量
参数:
tensors:可以是包含张量的列表
batch_size:从队列中读取的批处理大小
num_threads:进入队列的线程数
capacity:整数,队列中元素的最大数量
返回:tensors
②tf.train.shuffle_batch(tensors,batch_size,capacity,min_after_dequeue, num_threads=1,) 乱序读取指定大小(个数)的张量
参数:
min_after_dequeue:留下队列里的张量个数,能够保持随机打乱
3、文件读取案例
import tensorflow as tf
import os def csv_read(filelist):
# 构建文件队列
Q = tf.train.string_input_producer(filelist)
# 构建读取器
reader = tf.TextLineReader()
# 读取队列
key, value = reader.read(Q)
# 构建解码器
x1, y = tf.decode_csv(value, record_defaults=[["None"], ["None"]])
# 进行管道批处理
x1_batch, y_batch = tf.train.batch([x1, y], batch_size=12, num_threads=1, capacity=12)
# 开启会话
with tf.Session() as sess:
# 创建线程协调器
coord = tf.train.Coordinator()
# 开启线程
threads = tf.train.start_queue_runners(sess, coord=coord)
# 执行任务
print(sess.run([x1_batch, y_batch]))
# 线程回收
coord.request_stop()
coord.join(threads) if __name__ == "__main__":
filename = os.listdir("./data/") # 文件目录自己指定
filelist = [os.path.join("./data/", file) for file in filename]
csv_read(filelist)
三、图片读取与存储
1 图像数字化三要素:长度,宽度,通道数(一通道 : 灰度值 三通道 : RGB)
2 缩小图片大小:
tf.image.resize_images(images, size) 缩小图片
目的:
1、增加图片数据的统一性
2、所有图片转换成指定大小
3、缩小图片数据量,防止增加开销
3 图像读取API
1)图像读取器
tf.WholeFileReader 将文件的全部内容作为值输出的读取器
return:读取器实例 read(file_queue):输出将是一个文件名(key)和该文件的内容 (值)
2)图像解码器
tf.image.decode_jpeg(contents) 将JPEG编码的图像解码为uint8张量
return:uint8张量,3-D形状[height, width, channels]
tf.image.decode_png(contents) 将PNG编码的图像解码为uint8或uint16张量
return:张量类型,3-D形状[height, width, channels]
图片读取案的简单demo:
import tensorflow as tf
import os flags = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string("data_home", "./data/dog/", "狗的图片目录") # 文件路径自己指定 def picread(filelist):
# 构建文件名队列
file_q = tf.train.string_input_producer(filelist)
# 构建读取器
reader = tf.WholeFileReader()
# 读取内容
key, value = reader.read(file_q)
print(value)
# 构建解码器
image = tf.image.decode_jpeg(value)
print(image)
# 统一图片大小 设置长宽
resize_image = tf.image.resize_images(image, [256,256])
print(resize_image)
# 指定通道大小
resize_image.set_shape([256,256,3])
# 构建批量处理管道
image_batch = tf.train.batch([resize_image], batch_size=100,num_threads=1, capacity=100) return image_batch if __name__ == "__main__":
filename = os.listdir(flags.data_home)
filelist = [os.path.join(flags.data_home, file) for file in filename]
image_batch = picread(filelist) with tf.Session() as sess:
# 构建线程协调器
coord = tf.train.Coordinator()
# 开启线程
threads = tf.train.start_queue_runners(sess,coord=coord)
# 训练数据
print(sess.run(image_batch))
# 回收线程
coord.request_stop()
coord.join(threads)
四、TFRecords分析、存取
1 概念
TFRecords是Tensorflow设计的一种内置文件格式,是一种二进制文件, 它能更好的利用内存,更方便复制和移动 (将二进制数据和标签(训练的类别标签)数据存储在同一个文件中)
2 TFRecords文件分析
1)文件格式:*.tfrecords
2)写入文件内容:Example协议块
3 TFRecords存储
1)建立TFRecord存储器
tf.python_io.TFRecordWriter(path) 写入tfrecords文件
参数:
path: TFRecords文件的路径
return:无, 执行写文件操作
方法:
write(record):向文件中写入一个字符串记录 # 一个序列化的Example,Example.SerializeToString()
close():关闭文件写入器
2)构造每个样本的Example协议块
tf.train.Example(features=None) 写入tfrecords文件
参数:
features:tf.train.Features类型的特征实例
return:example格式协议块
tf.train.Features(feature=None) 构建每个样本的信息键值对
参数:
feature:字典数据,key为要保存的名字
value为tf.train.Feature实例
return:Features类型
tf.train.Feature(**options)
参数:
**options:例如 bytes_list=tf.train. BytesList(value=[Bytes])
int64_list=tf.train. Int64List(value=[Value])
float_list = tf.train. FloatList(value=[value])
4 TFRecords读取方法
1)构建文件队列
tf.train.string_input_producer(string_tensor, ,shuffle=True)
2)构建文件读取器,读取队列的数据
tf.TFRecordReader 返回:读取器实例
read(file_queue)
3)解析TFRecords的example协议内存块
①tf.parse_single_example(serialized,features=None,name=None) 解析一个单一的Example原型
参数:
serialized:标量字符串Tensor,一个序列化的Example
features:dict字典数据,键为读取的名字,值为FixedLenFeature
return:一个键值对组成的字典,键为读取的名字
②tf.FixedLenFeature(shape,dtype)
参数:
shape:输入数据的形状,一般不指定,为空列表
dtype:输入数据类型,与存储进文件的类型要一致 类型只能是float32,int64,string
4)解码
tf.decode_raw(bytes,out_type,little_endian = None,name = None) 将字节转换为一个数字向量表示,字节为一字符串类型的张量,与函数tf.FixedLengthRecordReader搭配使用,二进制读取为uint8格式
以下是从二进制文件中读取数据,写入tfrecords文件,再从tfrecords文件读取的小案例:
import tensorflow as tf
import os flags = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string("data_home", "./data/cifar10/cifar-10-batches-bin/", "二进制文件目录")
tf.app.flags.DEFINE_string("data_tfrecords", "./data/temp/tfrecords", "tfrecords文件路径") class cifarread(object):
def __init__(self, filelist):
self.filelist = filelist
# 构建图的一些数据
self.height = 32
self.width = 32
self.channel = 3
self.label_bytes = 1
self.image_bytes = self.height * self.width*self.channel
self.bytes = self.label_bytes + self.image_bytes def read_decode(self):
"""
读取二进制文件
:return: image_batch, label_batch
"""
# 构建文件名队列
file_q = tf.train.string_input_producer(self.filelist) # 构建阅读器
reader = tf.FixedLengthRecordReader(record_bytes=self.bytes) # 读取数据
key, value = reader.read(file_q) # 解码
label_image = tf.decode_raw(value, tf.uint8) # 分割数据集
label = tf.cast(tf.slice(label_image, [0], [self.label_bytes]), tf.int32)
image = tf.slice(label_image, [self.label_bytes], [self.image_bytes]) # 改变形状
image_tensor = tf.reshape(image, [self.height, self.width, self.channel]) # 批量处理
image_batch, label_batch = tf.train.batch([image_tensor, label], batch_size=10, num_threads=1, capacity=10) return image_batch, label_batch def write2tfrecords(self, image_batch, label_batch):
"""
将从二进制文件中读取的内容写入tfrecords文件
:param image_batch:
:param label_batch:
:return:
"""
# 构建一个tfrecords文件存储器
writer = tf.python_io.TFRecordWriter(flags.data_tfrecords)
# 对于每一个样本,都要构造example写入
for i in range(10):
# 取出特征值,转换成字符串
image_string = image_batch[i].eval().tostring() # 取出目标值
label_int = int(label_batch[i].eval()[0]) example = tf.train.Example(features=tf.train.Features(feature={
"image":tf.train.Feature(bytes_list = tf.train.BytesList(value=[image_string])),
"label":tf.train.Feature(int64_list = tf.train.Int64List(value=[label_int]))
}))
# 写入文件中,要先把协议序列化值之后才能存储
writer.write(example.SerializeToString()) writer.close()
return None def read_tfrecords(self):
"""
从tfrecords文件读取内容
:return: image_batch, label_batch
"""
# 构造文件队列
file_q = tf.train.string_input_producer([flags.data_tfrecords])
# 构造阅读器,读取数据
reader = tf.TFRecordReader()
# 一次只读取一个样本
key, value = reader.read(file_q)
# 解析内容 解析example协议
feature = tf.parse_single_example(value, features={
"image":tf.FixedLenFeature([], tf.string),
"label":tf.FixedLenFeature([], tf.int64)
}) # 解码 字符串需要解码, 整形不用
image = tf.decode_raw(feature["image"], tf.uint8) # 设置图片的形状,以便批处理
image_reshape = tf.reshape(image, [self.height, self.width])
label = tf.cast(feature["label"], tf.int32) # 批处理
image_batch, label_batch = tf.train.batch([image_reshape, label],batch_size=10 ,num_threads=1, capacity=10) return image_batch, label_batch if __name__ == "__main__":
filename = os.listdir(flags.data_home)
filelist = [os.path.join(flags.data_home, file) for file in filename if file[-3:] == "bin"]
cif = cifarread(filelist)
# 读取二进制文件
image_batch, label_batch = cif.read_decode()
# 读取tfrecords文件
# cif.read_tfrecords() with tf.Session() as sess:
# 构建线程协调器
coord = tf.train.Coordinator()
# 开启线程
threads = tf.train.start_queue_runners(sess, coord=coord)
# 执行任务
print(sess.run([image_batch, label_batch]))
# 存储tfrecords文件
# cif.write2tfrecords(image_batch, label_batch)
# 回收线程
coord.request_stop()
coord.join(threads)
tensorflow(二)----线程队列与io操作的更多相关文章
- 线程、进程、队列、IO多路模型
操作系统工作原理介绍.线程.进程演化史.特点.区别.互斥锁.信号.事件.join.GIL.进程间通信.管道.队列.生产者消息者模型.异步模型.IO多路复用模型.select\poll\epoll 高性 ...
- TensorFlow笔记-线程和队列
线程和队列 在使用TensorFlow进行异步计算时,队列是一种强大的机制. 为了感受一下队列,让我们来看一个简单的例子.我们先创建一个“先入先出”的队列(FIFOQueue),并将其内部所有元素初始 ...
- Python程序中的线程操作-线程队列
目录 一.线程队列 二.先进先出 三.后进先出 四.存储数据时可设置优先级的队列 4.1 优先级队列 4.2 更多方法说明 一.线程队列 queue队列:使用import queue,用法与进程Que ...
- C# IO操作(二)File类和Directory类的常用方法
本篇主要介绍一些常用的IO操作,对文件和目录的操作:留给自己复习之用. 1.创建文件 string sPath1=Path.GetDirectoryName(Assembly.GetExecuting ...
- AI学习---数据IO操作&神经网络基础
数据IO操作 TF支持3种文件读取: 1.直接把数据保存到变量中 2.占位符配合feed_dict使用 3. QueueRunner(TF中特有的) 文件读取流程 文件读取流程(多线 ...
- python之协程与IO操作
协程 协程,又称微线程,纤程.英文名Coroutine. 协程的概念很早就提出来了,但直到最近几年才在某些语言(如Lua)中得到广泛应用. 子程序,或者称为函数,在所有语言中都是层级调用,比如A调用B ...
- python全栈开发 * 线程队列 线程池 协程 * 180731
一.线程队列 队列:1.Queue 先进先出 自带锁 数据安全 from queue import Queue from multiprocessing import Queue (IPC队列)2.L ...
- Python进阶----异步同步,阻塞非阻塞,线程池(进程池)的异步+回调机制实行并发, 线程队列(Queue, LifoQueue,PriorityQueue), 事件Event,线程的三个状态(就绪,挂起,运行) ,***协程概念,yield模拟并发(有缺陷),Greenlet模块(手动切换),Gevent(协程并发)
Python进阶----异步同步,阻塞非阻塞,线程池(进程池)的异步+回调机制实行并发, 线程队列(Queue, LifoQueue,PriorityQueue), 事件Event,线程的三个状态(就 ...
- [并发编程 - 多线程:信号量、死锁与递归锁、时间Event、定时器Timer、线程队列、GIL锁]
[并发编程 - 多线程:信号量.死锁与递归锁.时间Event.定时器Timer.线程队列.GIL锁] 信号量 信号量Semaphore:管理一个内置的计数器 每当调用acquire()时内置计数器-1 ...
随机推荐
- [转]Loadrunner随机生成15位数字串
Loadrunner随机生成15位数字串 PS:http://www.51testing.com/html/43/6343-19789.html 今天看到一个网友的问题,是想生成一个15位的数字串来进 ...
- 【python】NLTK好文
From:http://m.blog.csdn.net/blog/huyoo/12188573 nltk是一个python工具包, 用来处理和自然语言处理相关的东西. 包括分词(tokenize), ...
- LAMP环境搭建博客
背景: 公司要用到lamp环境,让我装,我就开始着手找资料,一般分为源码装和yum装,源码装很容易出错,所以我选择了yum装,. 服务器:aliyun服务器 centos6.8系统 按照第一个安装完 ...
- android Contacts/Acore进程常常被Kill,导致联系人开机后丢失怎么办?
Contacts/Acore进程,在内存较少和开机进程过多的情况下会常常被 ActivityManager Kill 掉. 导致Sim卡联系人开机后未导入或者仅仅导入一部分,造成联系人丢失的现象,可是 ...
- 《从零开始学Swift》学习笔记(Day67)——Cocoa Touch设计模式及应用之MVC模式
原创文章,欢迎转载.转载请注明:关东升的博客 MVC(Model-View-Controller,模型-视图-控制器)模式是相当古老的设计模式之一,它最早出现在Smalltalk语言中.现在,很多计算 ...
- hibernate中持久化对象的状态
持久化对象有以下几种状态: 临时对象(Transient): 在使用代理主键的情况下, OID 通常为 null 不处于 Session 的缓存中 在数据库中没有对应的记录 持久化对象(也叫”托管 ...
- Bootstrap学习记录
中文官网 Bootstrap 插件 Bootstrap Multiselect bootstrap-multiselect 的简单使用,样式修改,动态创建option JS组件系列——Bootstra ...
- 第九课——redis集群
第九课时作业 静哥 by 2016.4.18~2016.4.25 1.节点 (1)节点概念:一个节点就是redis集群里的一台redis服务器.一个redis集群是由多个节点(node)组成,最初每个 ...
- linux日志自动分割shell
随着服务器运行时间不断增加,各种日志文件也会不断的增长,虽然硬盘已经是白菜价了,但是如果当你看到你的一个日志文件达到数十G的时候是什么感想?下面的脚本实现了如下功能: 自动对日志文件进行分割 对分割后 ...
- 排序算法review<1>--直接插入排序
简单插入排序的基本思想:对于原待排序记录中的第i(1<=i<=n-1)个元素Ki,保证其前面的i个元素已经是有序的,要在这前i个元素(K0--Ki-1)中找到合适的位置将第i个元素插入,具 ...