我要复习python啦(一)
一、变量
那些曾经怎么也看不懂的东西,突然有一天就懂了。这就是复习的力量吗?
1 变量的赋值
a = 10

做了上面的图所描述的事情
1)开辟一块内存,创建一个值为10的整数
2)创建一个a的标记
3)把a 指向内存中的值
关于堆和栈就先不考虑了,好吧。我自己不懂
再来一个难点的
a = 10
b = a
a = 20
这个够难了吧。你认为b是多少,是20吗,好吧。开始我也认为是20。但是b其实是10
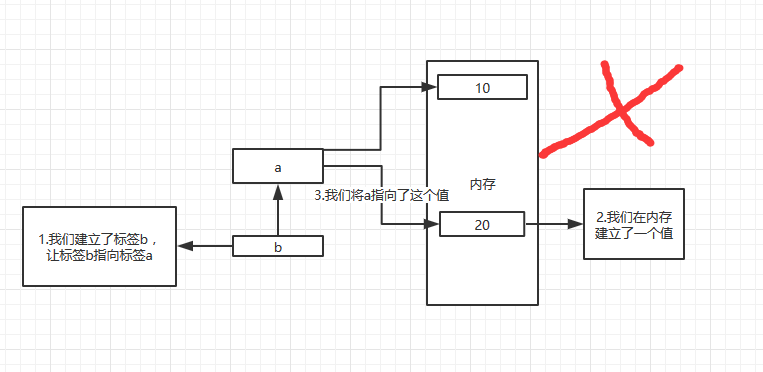
很明显这张图是错误的。b不是指向了a,而是指向了10
因为变量是一个标记,用来调用内存中的值,当我们将一个标记赋值给另一个标记的时候,应该是让其指向另一个标记的内存,而不是指向标记。
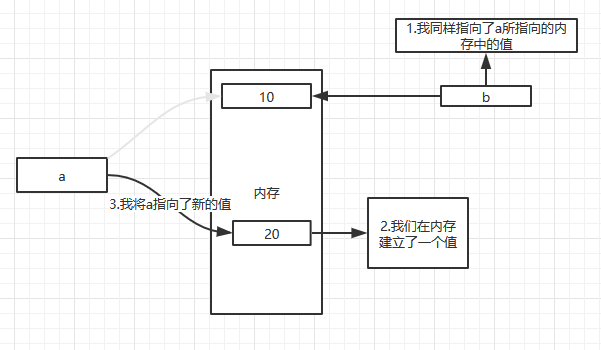
这张图才是正确的。b是指向了a指向的内存中的10,所以b是10
好了,变量赋值就到这里了
参考:https://www.cnblogs.com/scolia/p/5523883.html
好吧,我承认了,我只是复习我自己觉得模糊的东西,但是如果恰好你也对这些比较模糊,那咱俩还是挺有缘分的。如果你还对以外的东西比较模糊,那我只能说请移步到谷歌啥的
二 for中的迭代器和生成器
1 基础
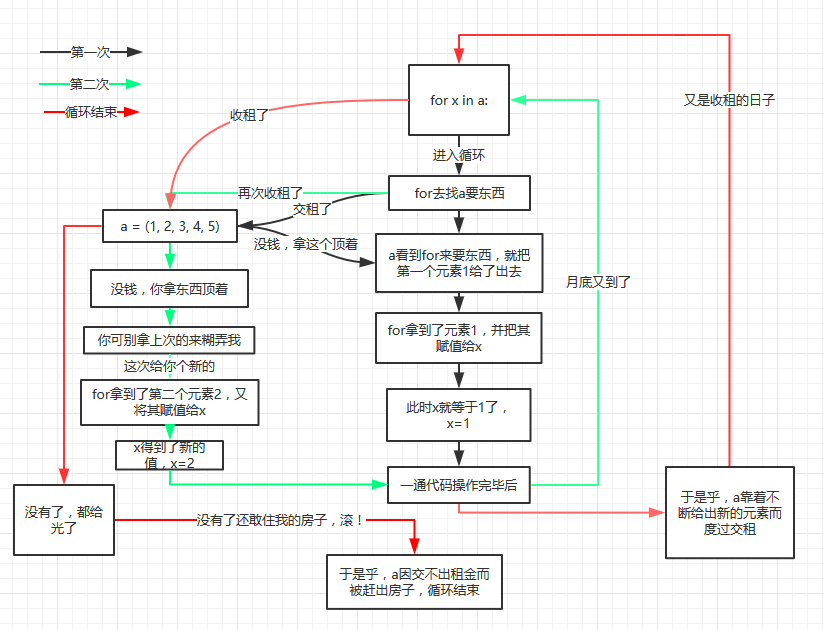
a = (1, 2, 3, 4, 5)
for x in a:
print x
参考http://www.cnblogs.com/scolia/p/5538666.html
不得不说上面的这哥们真是个好人。
for循环其实就是不断的去可迭代对象中拿去元素,而可迭代对象在每次迭代的时候都会把指针下移一格,也就是下次再来拿的时候,拿的是下一个。而这是因为可迭代对象有这样行为,才称其为可迭代。 这个时候我又要问一个问题,在迭代循环结束以后,x的值是否还存在? 当然还在,都说了作用域是函数的东西,迭代循环并不是函数。按照for循环的思路,x的值是不断更新的,所以在循环结束的时候,x应该等于最后一次迭代的值。以这里为例,x在循环结束的时候,其值应该为5。即x=5。
a = (1, 2, 3, 4, 5)
for x in a:
print x
print '----',x
print a
另外,虽说交租是交了出去自己没有了,但是迭代循环并不会改变a本身,也就是相当于借给别人看一眼,东西还是自己的。就想是以前的租碟吧哈哈
2)迭代器
迭代器是一个实现了迭代器协议的对象,Python中的迭代器协议就是有next方法的对象会前进到下一结果,而在一系列结果的末尾是,则会引发StopIteration。
而在for循环中,会自动调用 iter()将我们要迭代的对象转化为可迭代对象,每次循环都会调用 .next() 方法获取新元素,当引发StopIteration错误的时候自动退出循环,这就for循环的内部操作。
常用的数据类型,如:str、tuple、list、dict、set,都能进行迭代循环,因为其内部都有相应的方法
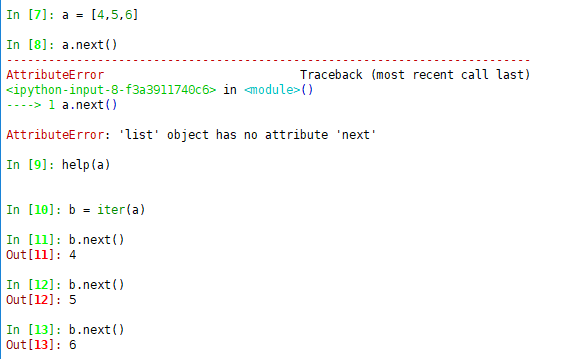
上面的例子可以看到a属于可迭代的对象,但是可迭代对象仍然没有next方法,必须使用iter转换为迭代器才有
我们自己也可以创建一个可迭代的类:
# coding:utf-8
# author:wanstack class Text(object):
def __init__(self,list_input):
"""
实现一个迭代器
:param list_input:
"""
self.list = list_input # 你输入的可迭代对象,例如列表,元组,集合等
self.index = 0 # 索引从0开始 def __iter__(self):
return self # 这里返回的是一个Text类的对象,不是很清楚为什么加上这个就从可迭代对象就变成了迭代器 def next(self):
if self.index >= len(self.list): # 这个应该不可能大于,应该是等于,不过这里应该不影响,索引到了最后
self.index = 0 # 将索引置为0
raise StopIteration # 触发异常 ret = self.list[self.index] # 取出元素中的值
self.index += 1 # 索引往后移动一位
return ret # 返回元素中的值 a = Text([1,2,3])
for i in a:
print(i)
这里python3中会报错,python2没问题。
下面是python3的版本,可以看一下差别,好吧。基本没啥差别,就是把next换成了__next__,好无奈
# coding:utf-8
# author:wanstack class Text(object):
def __init__(self,list_input):
"""
实现一个迭代器
:param list_input:
"""
self.list = list_input # 你输入的可迭代对象,例如列表,元组,集合等
self.index = 0 # 索引从0开始 def __iter__(self):
return self # 这里返回的是一个Text类的对象,不是很清楚为什么加上这个就从可迭代对象就变成了迭代器 def __next__(self):
if self.index >= len(self.list): # 这个应该不可能大于,应该是等于,不过这里应该不影响,索引到了最后
self.index = 0 # 将索引置为0
raise StopIteration # 触发异常 ret = self.list[self.index] # 取出元素中的值
self.index += 1 # 索引往后移动一位
return ret # 返回元素中的值 a = Text([1,2,3])
for i in a:
print(i)
3)生成器
所谓的生成器就是每次调用的时候返回一个对象,而不是一次性在内存中创建,从而达到节约内存的作用。
而生成器靠yield关键字实现,生成器的编写类似于函数,只不过将函数的return改成了yield:
好吧,我对yield也忘记的差不多了。关于生成器请移步这里吧。http://www.cnblogs.com/wanstack/articles/6993620.html
三 深浅拷贝
先来看一个现象
1)浅拷贝

上面修改b的值,a的值一样会变化。为什么呢?
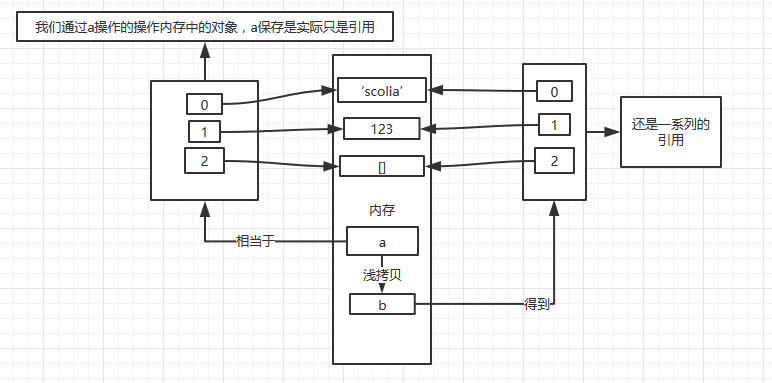
首先序列中保存的都是内存的引用,b是浅拷贝了a,所以a和b引用了同一个内存中的对象。所以,当我们通过b去修改里面的空列表的时候,其实就是修改内存中的同一个对象,所以会影响到a。
 地址是一样的啊。所以虽然a和b是两个不同的对象,但是里面的引用都是一样的。这就是所谓新的对象,旧的内容。
地址是一样的啊。所以虽然a和b是两个不同的对象,但是里面的引用都是一样的。这就是所谓新的对象,旧的内容。
但是下面的东西呢?
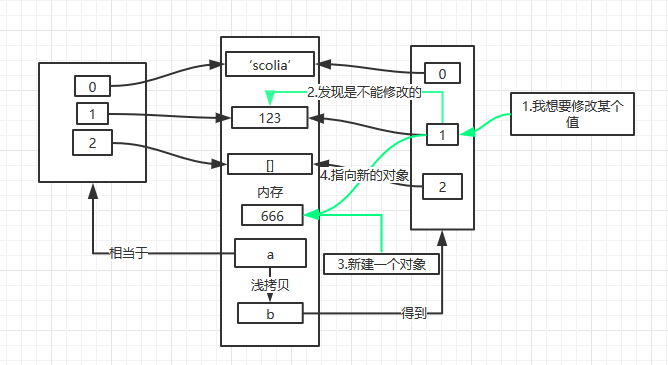
a = ['scolia', 123, [], ]
b = a[:]
b[1] = 666
print a
print b

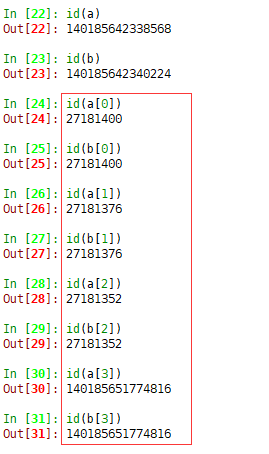
对于字符串、数字等不可变的数据类型,修改就相当于重新赋值。在这里就相当于刷新引用。
a = ['scolia', 123, [], ]
b = a[:]
b[1] = 666
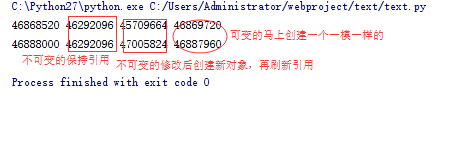
print id(a), id(a[0]), id(a[1]), id(a[2])
print id(b), id(b[0]), id(b[1]), id(b[2])

上面讲的这些就是浅拷贝,总结起来,浅拷贝只是拷贝了一系列引用,当我们在拷贝出来的对象对可修改的数据类型进行修改的时候,并没有改变引用,所以会影响原对象。而对不可修改的对象进行修改的是,则是新建了对象,刷新了引用,所以和原对象的引用不同,结果也就不同。
创建浅拷贝的方法:
1.切片操作
2.使用list()工厂函数新建对象。( b = list(a) )
3.使用copy模块的copy()方法。( b = copy.copy(a) )
2)深拷贝
那么深拷贝不就是将里面引用的对象重新创建了一遍并生成了一个新的一系列引用。
基本上是这样的,但是对于字符串、数字等不可修改的对象来说,重新创建一份似乎有点浪费内存,反正你到时要修改的时候都是新建对象,刷新引用的。所以还用原来的引用也无所谓,还能达到节省内存的目的。
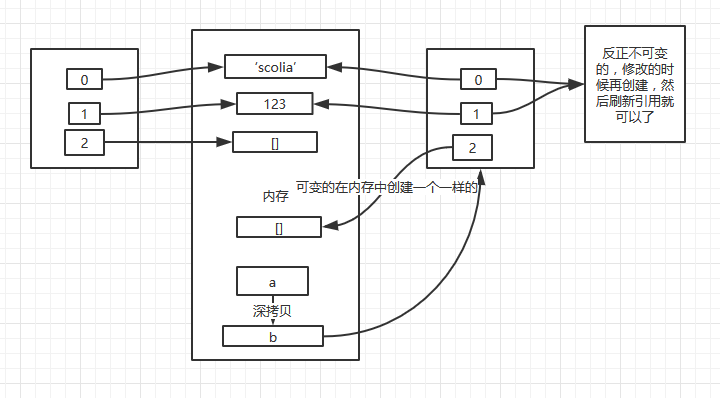
from copy import deepcopy
a = ['scolia', 123, [], ]
b = deepcopy(a)
b[1] = 666
print id(a), id(a[0]), id(a[1]), id(a[2])
print id(b), id(b[0]), id(b[1]), id(b[2])
四 编码问题
请移步 http://www.cnblogs.com/wanstack/articles/7147683.html
关于文件的编码问题参考:http://www.cnblogs.com/scolia/p/5557839.html
五 装饰器
终于到装饰器了
参考这个吧。 http://www.cnblogs.com/wanstack/articles/6973057.html
我要复习python啦(一)的更多相关文章
- 复习python(条件判断、循环、字符串格式化)
1.条件判断: 只有一种 if: *** elif:#多个条件加elif,想加几个加几个 **** else: **** python里靠缩进来表示表示语句块,见到冒号,下行就要缩进 2.循环 两种, ...
- 复习python
1当命令行键入python a.py的方式运行python程序时候,a.py不需要执行权,当已./a.py运行时,需要执行权 2.与c语言不同的地方 i = 3 print (i)#合法 #在pyth ...
- 复习python的多态,类的内部权限调用 整理
#多态的用法 class Dii: passclass Aii(Dii): def run(self): print('一号函数已调用')class Bii(Dii): def run(Dii): p ...
- 复习python的__call__ __str__ __repr__ __getattr__函数 整理
class Www: def __init__(self,name): self.name=name def __str__(self): return '名称 %s'%self.name #__re ...
- [0x01 用Python讲解数据结构与算法] 关于数据结构和算法还有编程
忍耐和坚持虽是痛苦的事情,但却能渐渐地为你带来好处. ——奥维德 一.学习目标 · 回顾在计算机科学.编程和问题解决过程中的基本知识: · 理解“抽象”在问题解决过程中的重要作用: · 理解并实现抽象 ...
- python之lambda函数
今天复习python,看见一个关于lambda函数的例子,在python中使用lambda在某些时候十分方便,因为不必为了实现某些简单功能而新建一个函数.但是有这么一个lambda实例令我有些疑惑,现 ...
- 2018-06-20 中文代码示例视频演示Python入门教程第三章 简介Python
知乎原链 Python 3.6.5官方入门教程中示例代码汉化后演示 对应在线文档: 3. An Informal Introduction to Python 不知如何合集, 请指教. 中文代码示例P ...
- python导入csv文件出现SyntaxError问题分析
python导入csv文件出现SyntaxError问题分析 先简单描述下碰到的题目,要求是写出2个print的结果 可以看到,a指向了一个列表list对象,在Python中,这样的赋值语句,其实内部 ...
- 重拾python所要知道的一些主干知识点
前言:因为有一段时间没有用python了,最近需要用到,只能回头过去看B站视频补一补,因为语言都是相通的,而且一些细节都可以去查表解决,所以呢,我们只需要知道一些python与其他语言的不同和常见的优 ...
随机推荐
- 10 Linux Commands Every Developer Should Know
转载:http://azer.bike/journal/10-linux-commands-every-developer-should-know/ As a software engineer, l ...
- maven shade插件小记
maven shade plugin插件小用 项目中一直使用assembly插件来整合依赖包到一个胖jar,在做这个akka http项目的时候,在scala ide的run/debug中都执行正常, ...
- Glide Picasso和Fresco的对比
比较Picasso.Glide 和 Fresco 三种图片加载库 比较 Picasso 与 Glide 总体来说二者极为相似,有着近乎相同的 API 的使用风格,但 Glide 在缓存策略和加载 gi ...
- iPhone X 游戏闪退:NSUnknownKeyException
目前很多游戏在iPhone X手机 wifi情况下,启动时候闪退,在4G网络时候不闪退. 闪退的log: #0 Thread NSUnknownKeyException [<UIStatusBa ...
- Table的一些设置(自适应以及溢出)
table的两个属性 单行溢出点点显示 表格的宽度设置 双栏自适应连续连续英文符换行 1.table重置的两个属性: ①border-collapse: collapse; /* 为表格设置 ...
- FFmpeg 入门(2):输出视频到屏幕
本文转自:FFmpeg 入门(2):输出视频到屏幕 | www.samirchen.com SDL 我们这里使用 SDL 来渲染视频到屏幕.SDL 是 Simple Direct Layer 的缩写, ...
- vultr VPS安装BBR
1.安装 wget --no-check-certificate https://github.com/teddysun/across/raw/master/bbr.sh chmod +x bbr.s ...
- RocEDU.阅读.写作《苏菲的世界》书摘(四)
亚理斯多德认为,快乐有三种形式.一种是过着享乐的生活,一种是做一个自由而负责的公民,另一种则是做一个思想家与哲学家.接着,他强调,人要同时达到这三个标准才能找到幸福与满足. 亚理斯多德提倡所谓的&qu ...
- python爬虫之新浪微博登录
fiddler 之前了解了一些常见到的反爬措施,JS加密算是比较困难,而微博的登录中正是用JS加密来反爬,今天来了解一下. 分析过程 首先我们去抓包,从登录到微博首页加载出来的过程.我们重点关注一下登 ...
- 解读:Hadoop序列化类
序列化(serialization)是指将结构化的对象转化字节流,以便在进程间通信或写入硬盘永久存储. 反序列化(deserialization)是指将字节流转回到结构化对象的过程. 需要注意的是,能 ...