Hadoop案例(四)倒排索引(多job串联)与全局计数器
一. 倒排索引(多job串联)
1. 需求分析
有大量的文本(文档、网页),需要建立搜索索引
xyg pingping
xyg ss
xyg ss
a.txt
xyg pingping
xyg pingping
pingping ss
b.txt
xyg ss
xyg pingping
c.txt
(1)第一次预期输出结果
xyg--a.txt
xyg--b.txt
xyg--c.txt
pingping--a.txt
pingping--b.txt
pingping--c.txt
ss--a.txt
ss--b.txt
ss--c.txt
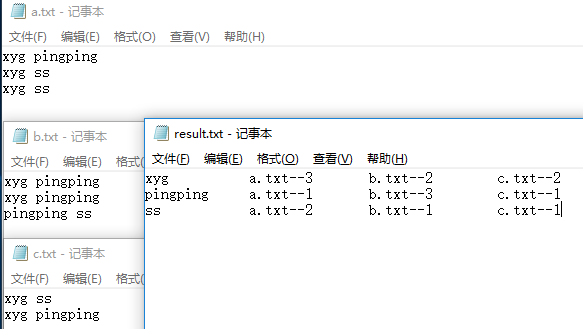
(2)第二次预期输出结果
xyg c.txt--> b.txt--> a.txt-->
pingping c.txt--> b.txt--> a.txt-->
ss c.txt--> b.txt--> a.txt-->
2. 第一次处理
(1)第一次处理,编写OneIndexMapper
package com.xyg.mapreduce.index;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class OneIndexMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Text k = new Text(); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取切片名称
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String name = inputSplit.getPath().getName(); // 2 获取1行
String line = value.toString(); // 3 截取
String[] words = line.split(" "); // 4 把每个单词和切片名称关联起来
for (String word : words) {
k.set(word + "--" + name); context.write(k, new IntWritable());
}
}
}
(2)第一次处理,编写OneIndexReducer
package com.xyg.mapreduce.index;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class OneIndexReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = ;
// 累加和
for(IntWritable value: values){
count +=value.get();
} // 写出
context.write(key, new IntWritable(count));
}
}
(3)第一次处理,编写OneIndexDriver
package com.xyg.mapreduce.index;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class OneIndexDriver { public static void main(String[] args) throws Exception { args = new String[] { "e:/inputoneindex", "e:/output5" }; Configuration conf = new Configuration(); Job job = Job.getInstance(conf);
job.setJarByClass(OneIndexDriver.class); job.setMapperClass(OneIndexMapper.class);
job.setReducerClass(OneIndexReducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path(args[]));
FileOutputFormat.setOutputPath(job, new Path(args[])); job.waitForCompletion(true);
}
}
(4)查看第一次输出结果
xyg--a.txt
xyg--b.txt
xyg--c.txt
pingping--a.txt
pingping--b.txt
pingping--c.txt
ss--a.txt
ss--b.txt
ss--c.txt
3. 第二次处理
(1)第二次处理,编写TwoIndexMapper
package com.xyg.mapreduce.index;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class TwoIndexMapper extends Mapper<LongWritable, Text, Text, Text>{
Text k = new Text();
Text v = new Text(); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 获取1行数据
String line = value.toString(); // 2用“--”切割
String[] fields = line.split("--"); k.set(fields[]);
v.set(fields[]); // 3 输出数据
context.write(k, v);
}
}
(2)第二次处理,编写TwoIndexReducer
package com.xyg.mapreduce.index;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class TwoIndexReducer extends Reducer<Text, Text, Text, Text> { @Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// xyg a.txt 3
// xyg b.txt 2
// xyg c.txt 2 // xyg c.txt-->2 b.txt-->2 a.txt-->3 StringBuilder sb = new StringBuilder(); for (Text value : values) {
sb.append(value.toString().replace("\t", "-->") + "\t");
} context.write(key, new Text(sb.toString()));
}
}
(3)第二次处理,编写TwoIndexDriver
package com.xyg.mapreduce.index;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TwoIndexDriver { public static void main(String[] args) throws Exception { args = new String[] { "e:/inputtwoindex", "e:/output6" }; Configuration config = new Configuration();
Job job = Job.getInstance(config); job.setMapperClass(TwoIndexMapper.class);
job.setReducerClass(TwoIndexReducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, new Path(args[]));
FileOutputFormat.setOutputPath(job, new Path(args[])); System.exit(job.waitForCompletion(true) ? : );
}
}
(4)第二次查看最终结果
xyg c.txt--> b.txt--> a.txt-->
pingping c.txt--> b.txt--> a.txt-->
ss c.txt--> b.txt--> a.txt-->
二. MapReduce 多 Job 串联
1. 需求
一个稍复杂点的处理逻辑往往需要多个 MapReduce 程序串联处理,多 job 的串联可以借助 MapReduce 框架的 JobControl 实现
2. 实例
以下有两个 MapReduce 任务,分别是 Flow 的 SumMR 和 SortMR,其中有依赖关系:SumMR 的输出是 SortMR 的输入,所以 SortMR 的启动得在 SumMR 完成之后
Configuration conf1 = new Configuration();
Configuration conf2 = new Configuration(); Job job1 = Job.getInstance(conf1);
Job job2 = Job.getInstance(conf2); job1.setJarByClass(MRScore3.class);
job1.setMapperClass(MRMapper3_1.class);
//job.setReducerClass(ScoreReducer3.class); job1.setMapOutputKeyClass(IntWritable.class);
job1.setMapOutputValueClass(StudentBean.class);
job1.setOutputKeyClass(IntWritable.class);
job1.setOutputValueClass(StudentBean.class); job1.setPartitionerClass(CoursePartitioner2.class); job1.setNumReduceTasks(4); Path inputPath = new Path("D:\\MR\\hw\\work3\\input");
Path outputPath = new Path("D:\\MR\\hw\\work3\\output_hw3_1"); FileInputFormat.setInputPaths(job1, inputPath);
FileOutputFormat.setOutputPath(job1, outputPath); job2.setMapperClass(MRMapper3_2.class);
job2.setReducerClass(MRReducer3_2.class); job2.setMapOutputKeyClass(IntWritable.class);
job2.setMapOutputValueClass(StudentBean.class);
job2.setOutputKeyClass(StudentBean.class);
job2.setOutputValueClass(NullWritable.class); Path inputPath2 = new Path("D:\\MR\\hw\\work3\\output_hw3_1");
Path outputPath2 = new Path("D:\\MR\\hw\\work3\\output_hw3_end"); FileInputFormat.setInputPaths(job2, inputPath2);
FileOutputFormat.setOutputPath(job2, outputPath2); JobControl control = new JobControl("Score3"); ControlledJob aJob = new ControlledJob(job1.getConfiguration());
ControlledJob bJob = new ControlledJob(job2.getConfiguration());
// 设置作业依赖关系
bJob.addDependingJob(aJob); control.addJob(aJob);
control.addJob(bJob); Thread thread = new Thread(control);
thread.start(); while(!control.allFinished()) {
thread.sleep(1000);
}
System.exit(0);
三. MapReduce 全局计数器
1.MapReduce计数器概念
计数器是用来记录job的执行进度和状态的。它的作用可以理解为日志。我们可以在程序的某个位置插入计数器,记录数据或者进度的变化情况。
2.MapReduce计数器作用
MapReduce 计数器(Counter)为我们提供一个窗口,用于观察 MapReduce Job 运行期的各种细节数据。对MapReduce性能调优很有帮助,MapReduce性能优化的评估大部分都是基于这些 Counter 的数值表现出来的。
3.MapReduce内置计数器分类
MapReduce 自带了许多默认Counter,现在我们来分析这些默认 Counter 的含义,方便大家观察 Job 结果,如输入的字节数、输出的字节数、Map端输入/输出的字节数和条数、Reduce端的输入/输出的字节数和条数等。下面我们只需了解这些内置计数器,知道计数器组名称(groupName)和计数器名称(counterName),以后使用计数器会查找groupName和counterName即可。
1、任务计数器
在任务执行过程中,任务计数器采集任务的相关信息,每个作业的所有任务的结果会被聚集起来。例如,MAP_INPUT_RECORDS 计数器统计每个map任务输入记录的总数,并在一个作业的所有map任务上进行聚集,使得最终数字是整个作业的所有输入记录的总数。任务计数器由其关联任务维护,并定期发送给TaskTracker,再由TaskTracker发送给 JobTracker。因此,计数器能够被全局地聚集。下面我们分别了解各种任务计数器。
1)MapReduce 任务计数器
MapReduce 任务计数器的 groupName为org.apache.hadoop.mapreduce.TaskCounter,它包含的计数器如下表所示
|
计数器名称 |
说明 |
|
map 输入的记录数(MAP_INPUT_RECORDS) |
作业中所有 map 已处理的输入记录数。每次 RecorderReader 读到一条记录并将其传给 map 的 map() 函数时,该计数器的值增加。 |
|
map 跳过的记录数(MAP_SKIPPED_RECORDS) |
作业中所有 map 跳过的输入记录数。 |
|
map 输入的字节数(MAP_INPUT_BYTES) |
作业中所有 map 已处理的未经压缩的输入数据的字节数。每次 RecorderReader 读到一条记录并 将其传给 map 的 map() 函数时,该计数器的值增加 |
|
分片split的原始字节数(SPLIT_RAW_BYTES) |
由 map 读取的输入-分片对象的字节数。这些对象描述分片元数据(文件的位移和长度),而不是分片的数据自身,因此总规模是小的 |
|
map 输出的记录数(MAP_OUTPUT_RECORDS) |
作业中所有 map 产生的 map 输出记录数。每次某一个 map 的Context 调用 write() 方法时,该计数器的值增加 |
|
map 输出的字节数(MAP_OUTPUT_BYTES) |
作业中所有 map 产生的 未经压缩的输出数据的字节数。每次某一个 map 的 Context 调用 write() 方法时,该计数器的值增加。 |
|
map 输出的物化字节数(MAP_OUTPUT_MATERIALIZED_BYTES) |
map 输出后确实写到磁盘上的字节数;若 map 输出压缩功能被启用,则会在计数器值上反映出来 |
|
combine 输入的记录数(COMBINE_INPUT_RECORDS) |
作业中所有 Combiner(如果有)已处理的输入记录数。Combiner 的迭代器每次读一个值,该计数器的值增加。 |
|
combine 输出的记录数(COMBINE_OUTPUT_RECORDS) |
作业中所有 Combiner(如果有)已产生的输出记录数。每当一个 Combiner 的 Context 调用 write() 方法时,该计数器的值增加。 |
|
reduce 输入的组(REDUCE_INPUT_GROUPS) |
作业中所有 reducer 已经处理的不同的码分组的个数。每当某一个 reducer 的 reduce() 被调用时,该计数器的值增加。 |
|
reduce 输入的记录数(REDUCE_INPUT_RECORDS) |
作业中所有 reducer 已经处理的输入记录的个数。每当某个 reducer 的迭代器读一个值时,该计数器的值增加。如果所有 reducer 已经处理完所有输入, 则该计数器的值与计数器 “map 输出的记录” 的值相同 |
|
reduce 输出的记录数(REDUCE_OUTPUT_RECORDS) |
作业中所有 map 已经产生的 reduce 输出记录数。每当某一个 reducer 的 Context 调用 write() 方法时,该计数器的值增加。 |
|
reduce 跳过的组数(REDUCE_SKIPPED_GROUPS) |
作业中所有 reducer 已经跳过的不同的码分组的个数。 |
|
reduce 跳过的记录数(REDUCE_SKIPPED_RECORDS) |
作业中所有 reducer 已经跳过输入记录数。 |
|
reduce 经过 shuffle 的字节数(REDUCE_SHUFFLE_BYTES) |
shuffle 将 map 的输出数据复制到 reducer 中的字节数。 |
|
溢出的记录数(SPILLED_RECORDS) |
作业中所有 map和reduce 任务溢出到磁盘的记录数 |
|
CPU 毫秒(CPU_MILLISECONDS) |
总计的 CPU 时间,以毫秒为单位,由/proc/cpuinfo获取 |
|
物理内存字节数(PHYSICAL_MEMORY_BYTES) |
一个任务所用物理内存的字节数,由/proc/cpuinfo获取 |
|
虚拟内存字节数(VIRTUAL_MEMORY_BYTES) |
一个任务所用虚拟内存的字节数,由/proc/cpuinfo获取 |
|
有效的堆字节数(COMMITTED_HEAP_BYTES) |
在 JVM 中的总有效内存量(以字节为单位),可由Runtime().getRuntime().totaoMemory()获取。 |
|
GC 运行时间毫秒数(GC_TIME_MILLIS) |
在任务执行过程中,垃圾收集器(garbage collection)花费的时间(以毫秒为单位), 可由 GarbageCollector MXBean.getCollectionTime()获取;该计数器并未出现在1.x版本中。 |
|
由 shuffle 传输的 map 输出数(SHUFFLED_MAPS) |
有 shuffle 传输到 reducer 的 map 输出文件数。 |
|
失败的 shuffle 数(SHUFFLE_MAPS) |
在 shuffle 过程中,发生拷贝错误的 map 输出文件数,该计数器并没有包含在 1.x 版本中。 |
|
被合并的 map 输出数 |
在 shuffle 过程中,在 reduce 端被合并的 map 输出文件数,该计数器没有包含在 1.x 版本中。 |
2)文件系统计数器
文件系统计数器的 groupName为org.apache.hadoop.mapreduce.FileSystemCounter,它包含的计数器如下表所示
|
计数器名称 |
说明 |
|
文件系统的读字节数(BYTES_READ) |
由 map 和 reduce 等任务在各个文件系统中读取的字节数,各个文件系统分别对应一个计数器,可以是 Local、HDFS、S3和KFS等。 |
|
文件系统的写字节数(BYTES_WRITTEN) |
由 map 和 reduce 等任务在各个文件系统中写的字节数。 |
3)FileInputFormat 计数器
FileInputFormat 计数器的 groupName为org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter,它包含的计数器如下表所示,计数器名称列的括号()内容即为counterName
|
计数器名称 |
说明 |
|
读取的字节数(BYTES_READ) |
由 map 任务通过 FileInputFormat 读取的字节数。 |
4)FileOutputFormat 计数器
FileOutputFormat 计数器的 groupName为org.apache.hadoop.mapreduce.lib.input.FileOutputFormatCounter,它包含的计数器如下表所示
|
计数器名称 |
说明 |
|
写的字节数(BYTES_WRITTEN) |
由 map 任务(针对仅含 map 的作业)或者 reduce 任务通过 FileOutputFormat 写的字节数。 |
2、作业计数器
作业计数器由 JobTracker(或者 YARN)维护,因此无需在网络间传输数据,这一点与包括 “用户定义的计数器” 在内的其它计数器不同。这些计数器都是作业级别的统计量,其值不会随着任务运行而改变。 作业计数器计数器的 groupName为org.apache.hadoop.mapreduce.JobCounter,它包含的计数器如下表所示
|
计数器名称 |
说明 |
|
启用的map任务数(TOTAL_LAUNCHED_MAPS) |
启动的map任务数,包括以“推测执行” 方式启动的任务。 |
|
启用的 reduce 任务数(TOTAL_LAUNCHED_REDUCES) |
启动的reduce任务数,包括以“推测执行” 方式启动的任务。 |
|
失败的map任务数(NUM_FAILED_MAPS) |
失败的map任务数。 |
|
失败的 reduce 任务数(NUM_FAILED_REDUCES) |
失败的reduce任务数。 |
|
数据本地化的 map 任务数(DATA_LOCAL_MAPS) |
与输入数据在同一节点的 map 任务数。 |
|
机架本地化的 map 任务数(RACK_LOCAL_MAPS) |
与输入数据在同一机架范围内、但不在同一节点上的 map 任务数。 |
|
其它本地化的 map 任务数(OTHER_LOCAL_MAPS) |
与输入数据不在同一机架范围内的 map 任务数。由于机架之间的宽带资源相对较少,Hadoop 会尽量让 map 任务靠近输入数据执行,因此该计数器值一般比较小。 |
|
map 任务的总运行时间(SLOTS_MILLIS_MAPS) |
map 任务的总运行时间,单位毫秒。该计数器包括以推测执行方式启动的任务。 |
|
reduce 任务的总运行时间(SLOTS_MILLIS_REDUCES) |
reduce任务的总运行时间,单位毫秒。该值包括以推测执行方式启动的任务。 |
|
在保留槽之后,map任务等待的总时间(FALLOW_SLOTS_MILLIS_MAPS) |
在为 map 任务保留槽之后所花费的总等待时间,单位是毫秒。 |
|
在保留槽之后,reduce 任务等待的总时间(FALLOW_SLOTS_MILLIS_REDUCES) |
在为 reduce 任务保留槽之后,花在等待上的总时间,单位为毫秒。 |
4.计数器的该如何使用
下面我们来介绍如何使用计数器。
1、定义计数器
1)枚举声明计数器
// 自定义枚举变量Enum
Counter counter = context.getCounter(Enum enum)
2)自定义计数器
/ 自己命名groupName和counterName
Counter counter = context.getCounter(String groupName,String counterName)
2、为计数器赋值
1)初始化计数器
counter.setValue(long value);// 设置初始值
2)计数器自增
counter.increment(long incr);// 增加计数
3、获取计数器的值
1) 获取枚举计数器的值
Configuration conf = new Configuration();
Job job = new Job(conf, "MyCounter");
job.waitForCompletion(true);
Counters counters=job.getCounters();
Counter counter=counters.findCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS_LONG);// 查找枚举计数器,假如Enum的变量为BAD_RECORDS_LONG
long value=counter.getValue();//获取计数值
2) 获取自定义计数器的值
Configuration conf = new Configuration();
Job job = new Job(conf, "MyCounter");
job.waitForCompletion(true);
Counters counters = job.getCounters();
Counter counter=counters.findCounter("ErrorCounter","toolong");// 假如groupName为ErrorCounter,counterName为toolong
long value = counter.getValue();// 获取计数值
3) 获取内置计数器的值
Configuration conf = new Configuration();
Job job = new Job(conf, "MyCounter");
job.waitForCompletion(true);
Counters counters=job.getCounters();
// 查找作业运行启动的reduce个数的计数器,groupName和counterName可以从内置计数器表格查询(前面已经列举有)
Counter counter=counters.findCounter("org.apache.hadoop.mapreduce.JobCounter","TOTAL_LAUNCHED_REDUCES");// 假如groupName为org.apache.hadoop.mapreduce.JobCounter,counterName为TOTAL_LAUNCHED_REDUCES
long value=counter.getValue();// 获取计数值
4) 获取所有计数器的值
Configuration conf = new Configuration();
Job job = new Job(conf, "MyCounter");
Counters counters = job.getCounters();
for (CounterGroup group : counters) {
for (Counter counter : group) {
System.out.println(counter.getDisplayName() + ": " + counter.getName() + ": "+ counter.getValue());
}
}
Hadoop案例(四)倒排索引(多job串联)与全局计数器的更多相关文章
- Hadoop学习之路(十五)MapReduce的多Job串联和全局计数器
MapReduce 多 Job 串联 需求 一个稍复杂点的处理逻辑往往需要多个 MapReduce 程序串联处理,多 job 的串联可以借助 MapReduce 框架的 JobControl 实现 实 ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- WPF案例 (四) 模拟Windows7桌面任务栏
原文:WPF案例 (四) 模拟Windows7桌面任务栏 这个程序模彷了Windows7的桌面任务栏,当在桌面上双击某个快捷方式时,将打开一个新的子界面,并且在任务栏里创建一个链接到此界面的任务栏图标 ...
- Android实训案例(四)——关于Game,2048方块的设计,逻辑,实现,编写,加上色彩,分数等深度剖析开发过程!
Android实训案例(四)--关于Game,2048方块的设计,逻辑,实现,编写,加上色彩,分数等深度剖析开发过程! 关于2048,我看到很多大神,比如医生,郭神,所以我也研究了一段时间,还好是研究 ...
- 马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- MR案例:倒排索引
1.map阶段:将单词和URI组成Key值(如“MapReduce :1.txt”),将词频作为value. 利用MR框架自带的Map端排序,将同一文档的相同单词的词频组成列表,传递给Combine过 ...
- 马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- Hadoop案例(十一)MapReduce的API使用
一学生成绩---增强版 数据信息 computer,huangxiaoming,,,,,,, computer,xuzheng,,,,, computer,huangbo,,,, english,zh ...
- Hadoop案例(七)MapReduce中多表合并
MapReduce中多表合并案例 一.案例需求 订单数据表t_order: id pid amount 1001 01 1 1002 02 2 1003 03 3 订单数据order.txt 商品信息 ...
随机推荐
- golang字符串常用函数
package utils import "fmt" import "strconv" import "strings" var str s ...
- Linux之进程通信20160720
好久没更新了,今天主要说一下Linux的进程通信,后续Linux方面的更新应该会变缓,因为最近在看Java和安卓方面的知识,后续会根据学习成果不断分享更新Java和安卓的方面的知识~ Linux进程通 ...
- 《剑指offer》— JavaScript(7)斐波那契数列
斐波那契数列 题目描述 大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项. n<=39 实现代码 function Fibonacci(n) { var arr = ...
- bzoj1511 [POI2006]OKR-Periods of Words kmp+乱搞
1511: [POI2006]OKR-Periods of Words Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 351 Solved: 220[S ...
- linux 隐藏权限
原文 ------通过chattr设置档案的隐藏权限------ [root@sdc ~]#chattr --helpUsage: chattr [-RV] [-+=AacDdijsSu] [-v v ...
- ubuntu系统安装mysql二进制压缩包(tar.gz)以及navicat远程连接服务器(linux系统)
一.ubuntu安装mysql5.6二进制压缩包(tar.gz) 准备 0. 获取 mysql-5.5.15-linux2.6-i686.tar.gz 二进制安装文件 mysql 官网下载页面选择 L ...
- winows下使用sourcetree的问题
sourcetree是基于git的版本控制工具,界面友好,并且多个平台下都有. 我在windows下是这么使用的: 1.先安装一个git(其实sourcetree有内嵌的git),然后生成ssh ke ...
- HTML不常用的表单属性-fieldset
这是代码 这是生成的样子 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http: ...
- 2017北京国庆刷题Day1 morning
期望得分:100+100+100=300 实际得分:100+100+70=270 T1位运算1(bit) Time Limit:1000ms Memory Limit:128MB 题目描述 LYK ...
- 2015/9/22 Python基础(18):组合、派生和继承
一个类被定义后,目标就是把它当成一个模块来使用,并把这些对象嵌入到你的代码中去,同其他数据类型及逻辑执行流混合使用.有两种方法可以在你的代码中利用类.第一种是组合,就是让不同的类混合并加入到其他类中, ...