TensorFlow学习笔记(四)图像识别与卷积神经网络
一、卷积神经网络简介
卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。 它包括卷积层(convolutional layer)和池化层(pooling layer)。
一般地,CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。
这是一个最典型的卷积网络,由卷积层、池化层、全连接层组成。其中卷积层与池化层配合,组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类。
卷积层完成的操作,可以认为是受局部感受野概念的启发,而池化层,主要是为了降低数据维度。
综合起来说,CNN通过卷积来模拟特征区分,并且通过卷积的权值共享及池化,来降低网络参数的数量级,最后通过传统神经网络完成分类等任务。

二、卷积神经网络常用结构
1、卷积层
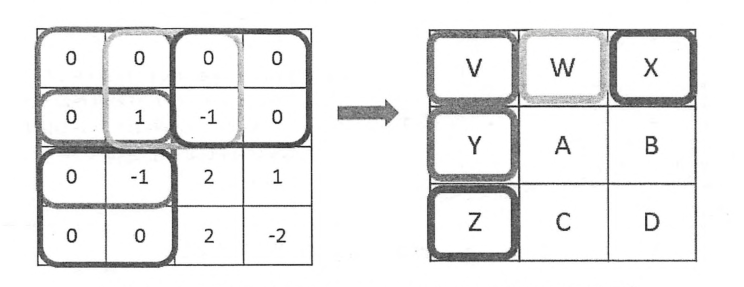
CNN最重要的部分就是卷积核。又称为过滤器或内核。
---恢复内容结束---
一、卷积神经网络简介
卷积神经网络(Convolutional Neural Network,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。 它包括卷积层(convolutional layer)和池化层(pooling layer)。
一般地,CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。
这是一个最典型的卷积网络,由卷积层、池化层、全连接层组成。其中卷积层与池化层配合,组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类。
卷积层完成的操作,可以认为是受局部感受野概念的启发,而池化层,主要是为了降低数据维度。
综合起来说,CNN通过卷积来模拟特征区分,并且通过卷积的权值共享及池化,来降低网络参数的数量级,最后通过传统神经网络完成分类等任务。
二、卷积神经网络常用结构
1、卷积层
CNN最重要的部分就是卷积核。又称为过滤器或内核。
CNN最重要的部分就是卷积核。又称为过滤器或内核。
共享每一个卷积层中过滤器的参数可以巨幅减少神经网络中的参数。
f(X.W+b)
为了避免尺寸变化,可以在当前层矩阵的边界中加入全0填充。
TensorFlow对卷积神经网络提供了非常好的支持,下面的程序实现了一个卷积层的前向传播过程。
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np
#通过tf.get_variable的方式创建过滤器的权重和偏置。
x = np.random.randn(4,5)
filter_weight = tf.get_variable("weight",[5,5,3,16],initializer=tf.truncated_normal_initializer(stddev=0.1))
#和卷积层的权重类似,当前层不同位置的偏置项也是共享的。
biases = tf.get_variable("biases",shape=[16],initializer=tf.constant_initializer(0.1))
#tf.nn.conv2d 提供了一个非常方便的函数来实现卷积层前向传播算法。
conv=tf.nn.conv2d(x,filter_weight,strides=[1,1,1,1],padding="SAME")
# tf.nn.bias_add函数给每个节点增加偏执项
bias = tf.nn.bias_add(conv,biases)
#通过relu激活函数去线性化
active_conv = tf.nn.relu(bias)
2池化层
池化层可以非常有效的缩小矩阵的尺寸, 从而减少后面全连接层的参数。使用池化层可以有效的加快计算速度,也可以防止过拟合。
池化层的过滤器不是加权求和,而是采用最大值或平均值运算。
池化层过滤器的移动和填充方式与卷积层的类似,唯一的区别是卷积层的过滤器是横跨整个深度的,而池化层使用的过滤器只影响一个深度上的节点。
3 经典的卷积神经网络
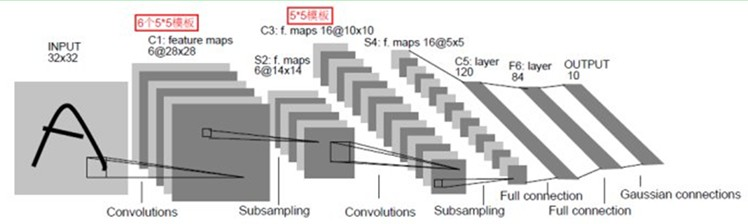
3.1 LeNet-5模型
模型总共七层,模型的结构如下

用TF来实现
#mnsit_inference
# -*- coding:utf-8 -*- import tensorflow as tf #定义神经网络的参数
INPUT_NODE = 784
OUTPUT_NODE = 10
IMAGE_SIZE = 28
NUM_CHANNELS = 1
NUM_LABELS = 10
#第一层conv参数
CONV1_DEEP = 32
CONV1_SIZE = 5 #第二层卷积层参数
CONV2_DEEP = 64
CONV2_SIZE = 5
#全连接层节点个数
FC_SIZE = 512 #定义神经网络的前向传播过程.这里添加了一个新的参数train ,用于区分训练过程和测试过程。在这个过程中将用到dropout方法。dropout方法只在训练中使用。 def inference(input_tensor,train,regularizer):
#第一层卷积层
with tf.variable_scope("layer1_conv1"):
conv1_weights = tf.get_variable("wight",[CONV1_SIZE,CONV1_SIZE,NUM_CHANNELS,CONV1_DEEP],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable("bias",shape=[CONV1_DEEP],initializer=tf.constant_initializer(0.0))
#使用边长为5,深度为32 的过滤器,过滤器的移动步长为1,填充为全0
conv1 = tf.nn.conv2d(input_tensor,conv1_weights,strides=[1,1,1,1],padding="SAME")
relu1 = tf.nn.relu(tf.nn.bias_add(conv1,conv1_biases))
#第二层pooling
with tf.variable_scope("layer2_pool1"):
pool1 = tf.nn.max_pool(relu1,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME")
#第三层,卷积层
with tf.variable_scope("layer3_conv2"):
conv2_weights = tf.get_variable("weight",[CONV2_SIZE,CONV2_SIZE,CONV1_DEEP,CONV2_DEEP],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable('bias',[CONV2_DEEP],initializer=tf.constant_initializer(0.0))
#使用边长为5,深度为64 的过滤器,过滤器的移动步长为1,填充为全0
conv2 = tf.nn.conv2d(pool1,conv2_weights,strides=[1,1,1,1],padding="SAME")
relu2 = tf.nn.relu(tf.nn.bias_add(conv2,conv2_biases))
#第四层,池化层
with tf.variable_scope("layer4_pool2"):
pool2=tf.nn.max_pool(relu2,[1,2,2,1],[1,2,2,1],padding="SAME")
#第四层的输出为7*7*64,然而第五层全连接层需要的输入格式为向量,所以这里需要将7*7*64拉伸为一个向量。pool2.get_shape。因为每层网络的输入输出都是一batch
#矩阵所以这里的维度也包含batch中数据的个数。
pool_shape = pool2.get_shape().as_list()
nodes = pool_shape[1]*pool_shape[2]*pool_shape[3]
reshaped = tf.reshape(pool2,[pool_shape[0],nodes])
with tf.variable_scope("layer5_fc1"):
fc1_weights = tf.get_variable('weight',[nodes,FC_SIZE],initializer=tf.truncated_normal_initializer(stddev=0.1))
fc1_biases = tf.get_variable("bias",[FC_SIZE],initializer=tf.constant_initializer(0.1))
#只有全连接层的权重需要加入正则化
if regularizer != None:
tf.add_to_collection("losses",regularizer(fc1_weights))
fc1 = tf.nn.relu(tf.matmul(reshaped,fc1_weights)+fc1_biases)
if train:
#利用dropout减少过拟合
fc1 = tf.nn.dropout(fc1,0.5)
#声明第六层-全连接层。输入为512的向量,输出为10的向量
with tf.variable_scope("layer6_fc2"):
fc2_weights = tf.get_variable('weight',[FC_SIZE,OUTPUT_NODE],initializer=tf.truncated_normal_initializer(stddev=0.1))
fc2_biases = tf.get_variable('biases',[OUTPUT_NODE],initializer=tf.constant_initializer(0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc2_weights))
logit = tf.matmul(fc1,fc2_weights)+ fc2_biases
return logit
#mnsit_train
# -*- coding:utf-8 -*-
import os
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#加载mnsit_inference.py中定义的变量和函数
from integerad_mnist import mnsit_inference
import numpy as np #配置神经网络的参数
BATCH_SIZE = 100
LR_BASE = 0.8
LR_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRANING_STEPS = 30000
MOVING_AVERAGE_DECAY = 0.99
#模型保存的文件名和路径
MODEL_SAVE_PATH = "path/to/model/"
MODEL_SAVE_NAME = "model.ckpt"
INPUT_SHAPE = [BATCH_SIZE,mnsit_inference.IMAGE_SIZE,mnsit_inference.IMAGE_SIZE,mnsit_inference.NUM_CHANNELS]
def train(mnsit):
#定义输入和输出的placeholder
x = tf.placeholder(tf.float32,shape=INPUT_SHAPE,name="x_input")
y_ = tf.placeholder(tf.float32,shape=[None,mnsit_inference.OUTPUT_NODE],name="y_input")
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
#直接使用mnsit_inference中定义的前向传播过程
y = mnsit_inference.inference(x,True,regularizer)
global_step = tf.Variable(0,trainable=False)
variable_average = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
variable_average_op = variable_average.apply(tf.trainable_variables())
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(y_,1),logits=y)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection("losses"))
learning_rate = tf.train.exponential_decay(LR_BASE,global_step,mnsit.train.num_examples/BATCH_SIZE,LR_DECAY)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step)
with tf.control_dependencies([train_step,variable_average_op]):
train_op = tf.no_op("train")
#初始化TF的持久化类
saver = tf.train.Saver()
with tf.Session() as sess:
tf.initialize_all_variables().run()
for i in range(TRANING_STEPS):
xs,ys = mnsit.train.next_batch(BATCH_SIZE)
reshaped_xs = np.reshape(xs,INPUT_SHAPE)
_,loss_value,step = sess.run([train_op,cross_entropy_mean,global_step],feed_dict={x:reshaped_xs,y_:ys})
#每1000轮保存一次模型
if i % 1000 == 0:
print("After {0} training steps,loss on training batch is {1}".format(step,loss_value))
saver.save(sess,os.path.join(MODEL_SAVE_PATH,MODEL_SAVE_NAME),global_step=global_step) def main(argv = None):
mnsit = input_data.read_data_sets("mnist_set",one_hot=True)
train(mnsit)
if __name__ == '__main__':
tf.app.run()
3.2 Inception-V3 模型
LeNet-5模型中,卷积层是通过串联的方式连接在一起的,而Inception-v3中的inception结构与之完全不同,它是通过并联的方式结合在一起的。如下图所示;
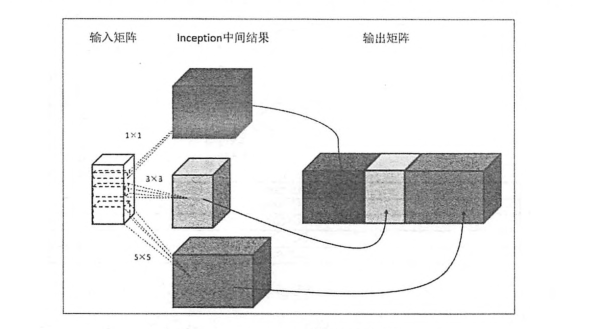
整体的inception-v3模型架构图
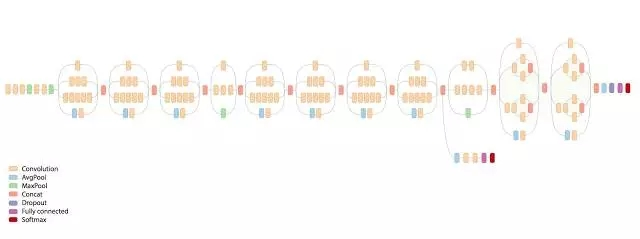
Inception-v3模型总共有46层,由11个inception模块组成。Inception-v3模型中有96个卷积层。如果还按照之前的代码,一个卷积5行代码,96个需要480行代码,代码可读性差,可以用TonserFlow=Slim来实现。一行即可实现一个conv层。
比较一下原始的tf和slim
import tensorflow as tf
import numpy as np
import tensorflow.contrib.slim as slim
#通过tf.get_variable的方式创建过滤器的权重和偏置。
x = np.random.randn(4,5)
filter_weight = tf.get_variable("weight",[5,5,3,16],initializer=tf.truncated_normal_initializer(stddev=0.1)) biases = tf.get_variable("biases",shape=[16],initializer=tf.constant_initializer(0.1))
conv=tf.nn.conv2d(x,filter_weight,strides=[1,1,1,1],padding="SAME")
bias = tf.nn.bias_add(conv,biases)
active_conv = tf.nn.relu(bias)
#使用TensorFlow-Slim实现卷积层。slim.conv2d函数有三个必填的参数,第一个为输入节点的矩阵,第二个为当前卷积层过滤器的深度,第三个为过滤器的尺寸
#可选参数有步长,填充0,激活函数和变量的命名空间
net = slim.conv2d(x,16,[5,5])
代码实现一个inception模块。
import tensorflow as tf
import numpy as np
import tensorflow.contrib.slim as slim #slim.arg_scope函数用来设置默认的参数取值,第一个参数是函数名列表。 with slim.arg_scope([slim.conv2d,slim.max_pool2d,slim.avg_pool2d],stride = 1,padding = "SAME"):
#.......此处省略了前面的网络结构,
net = "上一层网络的输出"
#为一个inception模块声明一个统一的变量命名空间
with tf.variable_scope("Mixed_7c"):
#给inception的每一条分支声明一个变量命名空间
with tf.get_variable('branch_0'):
branch_0 = slim.conv2d(net,320,[1,1],scope="Conv2d_0a-1X1")
#第二条路径本身也是一个inception
with tf.get_variable("branch_1"):
branch_1 = slim.conv2d(net,384,[1,1],scope="Conv2d_0a-1X1")
#tf.concat可以将多个矩阵进行拼接,第二个参数指定拼接的维度,这里的“3”代表深度。
branch_1 = tf.concat([slim.conv2d(branch_1,[1,3],scope="Conv2d_0b-1X3"),slim.conv2d(branch_1,[3,1],scope="Conv2d_0c-3X1")],3)
with tf.get_variable("branch_2"):
branch_2 = slim.conv2d(net,448,[1,1],scope="Conv2d_0a-1X1")
branch_2 = slim.conv2d(branch_2,384,[3,3],scope="Conv2d_0b-3X3")
branch_2 = tf.concat([slim.conv2d(branch_2,[1,3],scope="Conv2d_0c-1X3"),slim.conv2d(branch_2,[3,1],scope="Conv2d_0c-3X1")],3) #第四条inception路径
with tf.get_variable("branch_3"):
branch_3 = slim.avg_pool2d(net,[3,3],scope="avg_pool-0a-3X3")
#tf.concat可以将多个矩阵进行拼接,第二个参数指定拼接的维度,这里的“3”代表深度。
branch_3 = slim.conv2d(branch_3,192,[1,1],scope="Conv2d_0a-1X1")
#当前inception模块的最后输出由上面的四个结果拼接得到
net_output = tf.concat([branch_0,branch_1,branch_2,branch_3],3)
5、卷积神经网络的迁移学习
5.1什么是迁移学习?
所谓的迁移学习,就是将一个问题上训练好的模型通过简单的调整使其适用于一个新的问题。
瓶颈层:
在最后一层全连接层之间的网络层称之为瓶颈层。
一般来说,在数据量足够的情况下,迁移学习的效果不如完全重新学习。
5.2 TensorFlow 实现迁移学习
TensorFlow学习笔记(四)图像识别与卷积神经网络的更多相关文章
- UFLDL深度学习笔记 (六)卷积神经网络
UFLDL深度学习笔记 (六)卷积神经网络 1. 主要思路 "UFLDL 卷积神经网络"主要讲解了对大尺寸图像应用前面所讨论神经网络学习的方法,其中的变化有两条,第一,对大尺寸图像 ...
- 神经网络与深度学习笔记 Chapter 6之卷积神经网络
深度学习 Introducing convolutional networks:卷积神经网络介绍 卷积神经网络中有三个基本的概念:局部感受野(local receptive fields), 共享权重 ...
- tensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试
刚开始学习tf时,我们从简单的地方开始.卷积神经网络(CNN)是由简单的神经网络(NN)发展而来的,因此,我们的第一个例子,就从神经网络开始. 神经网络没有卷积功能,只有简单的三层:输入层,隐藏层和输 ...
- TensorFlow学习笔记(二)深层神经网络
一.深度学习与深层神经网络 深层神经网络是实现“多层非线性变换”的一种方法. 深层神经网络有两个非常重要的特性:深层和非线性. 1.1线性模型的局限性 线性模型:y =wx+b 线性模型的最大特点就是 ...
- TensorFlow学习笔记13-循环、递归神经网络
循环神经网络(RNN) 卷积网络专门处理网格化的数据,而循环网络专门处理序列化的数据. 一般的神经网络结构为: 一般的神经网络结构的前提假设是:元素之间是相互独立的,输入.输出都是独立的. 现实世界中 ...
- 深度学习笔记之CNN(卷积神经网络)基础
不多说,直接上干货! 卷积神经网络(ConvolutionalNeural Networks,简称CNN)提出于20世纪60年代,由Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经 ...
- TensorFlow学习笔记(六)循环神经网络
一.循环神经网络简介 循环神经网络的主要用途是处理和预测序列数据.循环神经网络刻画了一个序列当前的输出与之前信息的关系.从网络结构上,循环神经网络会记忆之前的信息,并利用之前的信息影响后面节点的输出. ...
- tensorflow学习笔记四----------构造线性回归模型
首先通过构造随机数,模拟数据. import numpy as np import tensorflow as tf import matplotlib.pyplot as plt # 随机生成100 ...
- 莫烦pytorch学习笔记(八)——卷积神经网络(手写数字识别实现)
莫烦视频网址 这个代码实现了预测和可视化 import os # third-party library import torch import torch.nn as nn import torch ...
- 吴裕雄--天生自然python Google深度学习框架:图像识别与卷积神经网络
随机推荐
- JS关于浏览器尺寸的方法
document.body.clientWidth BODY对象宽度.通配符未清零margin的时候,小于页面可见区域宽度document.body.clientHeight BODY对象高度.doc ...
- c/c++学习之c++ 中的list <>容器
http://blog.csdn.net/mazidao2008/article/details/4802617 push 实例化 即添加 http://www.cnblogs.com/BeyondA ...
- 登陆Oracle11g的企业管理器
本地:https://localhost:1158/em/ 如果远程:那么把localhost换成服务器IP
- React Native开发技术
http://www.lcode.org/react-native-week-issue22/
- iOS开发之--NSData与UIImage之间的转换
//NSData转换为UIImage NSData *imageData = [NSData dataWithContentsOfFile: imagePath]; UIImage *image = ...
- 【BZOJ2699】更新 动态规划
[BZOJ2699]更新 Description 对于一个数列A[1..N],一种寻找最大值的方法是:依次枚举A[2]到A[N],如果A[i]比当前的A[1]值要大,那么就令A[1]=A ...
- cocos2dx-draw绘制
[一]:函数 //1.设置绘制颜色 1.ccDrawColor4B("红","绿","蓝","透明"); //2.设 ...
- Web端测试
一.功能测试 1.链接测试 1)所有链接是否按指示的那样,链接正确? 2)所有链接是否存在? 3)保证Web应用系统上没有孤立的页面? 在线链接测试地址:http://v ...
- fidder教程
Fiddler是最强大最好用的Web调试工具之一,它能记录所有客户端和服务器的http和https请求,允许你监视,设置断点,甚至修改输入输出数据. 使用Fiddler无论对开发还是测试来说,都有很大 ...
- Java Filter过滤xss注入非法参数的方法
http://blog.csdn.NET/feng_an_qi/article/details/45666813 Java Filter过滤xss注入非法参数的方法 web.xml: <filt ...