8、双向一对多的关联关系(等同于双向多对一。1的一方有对n的一方的集合的引用,同时n的一方有对1的一方的引用)
双向一对多关联关系
“双向一对多关联关系”等同于“双向多对一关联关系”:1的一方有对n的一方的集合的引用,同时n的一方有对1的一方的引用。
还是用客户Customer和订单Order来解释:
“一对多”的物理意义:一个客户可以有多个订单,某个订单只能归宿于一个客户。
“双向”的物理意义:客户知道自己有哪些订单,订单也知道自己归宿于哪个客户。也就是说,通过客户对象可以检索到其拥有哪些订单;同时,通过订单也可以查找到其对应的客户信息。这是符合我们业务逻辑需求。
到现在为止(结合前面两节的阐述)我们可以很深刻的理解“双向”、“单向”、“一对多”、“多对一”这四个词语了:
①、“一对多”讲的是一个实体类中是否包含有对另外一个实体类的集合的引用。
②、“多对一”包含两层含义:a、一个实体类Ea是否包含有对另外一个实体类Eb的引用;b、是否允许实体类Ea的多个对象{ea1, ea2, ea3,...}同时对实体类Eb的某个对象eb有引用关系(如果不允许“多个对一个”,那么就是后面要讲的“一对一关联关系”),如下Figure_1所示:
Figure_1. 允许多对一关联

③、“双向”包含两个缺一不可的层面:a、1的一方有对n的一方的集合的引用;b、同时,n的一方也有对1的一方的对象的引用;也就是同时满足①、②两点。
④、“单向”就是③中阐述的两个层面只出现一个。也就是只满足①、②两点中的一点。
注:我们上面①~④所讲的集合是实体类中的集合,同时集合之上还要有映射注解(或映射配置文件)进行相关的关联映射。如果单单只是一个集合,却没有表示映射关系的注解或配置文件,那么这个集合就不是我们映射层面上的“集合”。实体类中的对象也是一样的道理。
下面我们通过Customer和Order的关系来印证我们上面的这种理解:
List_1. Customer实体类(有对Order的集合的引用)
@Table(name=“t_double_one2many_customer”)
@Entity
public class Customer2 { private Integer id;
private String lastName; private String email;
private int age; private Date birthday; private Date createdTime; // 有对Order2的集合的引用
//(这个引用还要被注解表示为一种映射关系才行)
private Set<Order2> orders = new HashSet<Order2>();
// 省略getter、setter方法
}
List_2. Order实体类(有对Customer的实体的对象的引用)
@Table(name=“t_double_one2many_order”)
@Entity
public class Order2 { private Integer id;
private String orderName; //n的一方有对1的一方的对象的引用
//①要有映射注解表明为映射;②、允许多对一,否则就是一对一
private Customer2 customer;
// 省略getter、setter方法
}
从Customer实体类和Order实体类的属性定义我们可以得出下面的东西:
1、满足上面③的要求,所以是“双向”。
2、同时还满足①、②两点要求(这里也可以推导出“双向”)
从以上可以看出,Customer和Order是“双向一对多”或“双向多对一”关联关系。
双向关联关系的默认策略和两个单项是一致的:
1、对1的一端的集合引用的检索采用采用延迟加载方式;对n的一端的对象引用的检索采用立即加载方式;可以通过设置@ManyToOne或@OneToMany的fetch属性来修改默认策略。
2、可以自由的删除n的一方的某个对象;但是,对1的一方的对象而言,如果还有n的一方的某个对象引用它,那么就不能够删除1的一方的该对象。可以通过设置@ManyToOne或@OneToMany的cascade属性来修改默认的删除策略;
配置双向多对一关联关系的具体操作:
1、如果双边都维护关联关系:
①n的一端做如下配置
List_3. n的一方的配置
@ManyToOne
@JoinColumn(name=“CUSTOMER_ID”)
public Customer2 getCustomer() {
return customer;
}
②、1的一端做如下配置
list_4. 1的一方的配置
@OneToMany
@JoinColumn(name=“CUSTOMER_ID”)
public Set<Order2> getOrders() {
return orders;
}
要注意的是,两边的@JoinColumn的name属性要一致(这里都是CUSTOMER_ID)。最后建立得到的数据表效果就是在n的一方对应的数据表中有一列外键,而1的一方没有外键列(可以想象,1的一方无法放置外键列)
这种双边都维护关联关系的时候,保存对象不可避免的要发送多余的update语句,和单向一对多关联关系一样。无论你是先保存1的一端,还是先保存n的一端都无法避免update语句的发送。
2、只靠n的一方维护关联关系(推荐使用):
在双向多对一关联关系中,1的一方没有必要维护关联关系,只靠n的一方维护就够了。这样做的好处就是:保存对象的时候先保存1的一端,后保存n的一端,可以避免发送update语句(和单向多对一关联关系一样)。
具体的配置方法就是:a、n的一方配置如 “List_3. n的一方的配置” 一样; b、1的一方配置不能使用@JoinColumn(name=“CUSTOMER_ID”)注解(如果有此注解,则会报错),同时在@OneToMany中配置mappedBy=“customer”属性指定由n的一方的哪个属性来维护关联关系(注意,这里的customer是n一端的对象引用的名称),如下List_5:
List_5. 1的一方不维护关联关系
/**
* 1、双向1-n关联的时候,一般1的一方放弃维护关联关系,而由n的一方维护关联关系。
* 这样做的好处就是:先保存1的一端,再保存n的一端的时候不会有多余的update sql语句
* 2、使用@OneToMany(mappedBy=“customer”)来指明由n的一方的哪个属性来维护关联关系
* 3、有一个值得注意的地方:如果指明了mappedBy=“customer”,那么就不能够再使用@JoinColumn注解了。 *
*/
// @JoinColumn(name=“CUSTOMER_ID”)
@OneToMany(mappedBy=“customer”)
public Set<Order2> getOrders() {
return orders;
}
说明:就创建的两张数据表而言,“双边维护关联关系”与“单边维护关联关系”所创建的数据表没有区别,都是由n的一方对应的数据表有一个外键参照列,而1的一方没有任何外键列。两张数据表如下:
Figure_2. Customer实体对应的数据表
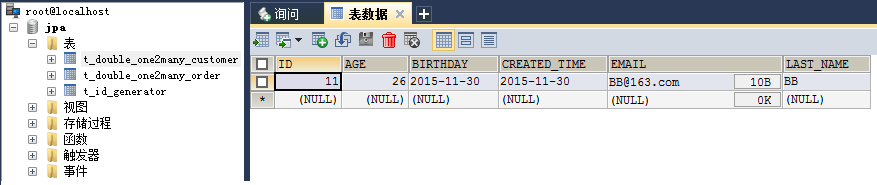
Figure_3. Order实体对应的数据表
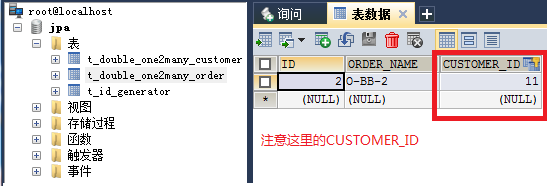
注意这里的“CUSTOMER_ID”是@JoinColumn(name=“CUSTOMER_ID”)中指定的CUSTOMER_ID。注意这里的Order实体表中有外键列,而Customer实体表中没有外键列。
下面是Customer和Order实体类:
List_6. Customer2.java(作为1的一方,有对n的一方的集合的引用,不维护关联关系)
package com.magicode.jpa.doubl.many2one; import java.util.Date;
import java.util.HashSet;
import java.util.Set; import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.OneToMany;
import javax.persistence.Table;
import javax.persistence.TableGenerator;
import javax.persistence.Temporal;
import javax.persistence.TemporalType;
import javax.persistence.Transient; /**
* @Entity 用于注明该类是一个实体类
* @Table(name=“t_customer”) 表明该实体类映射到数据库的 t_customer 表
*/
@Table(name=“t_double_one2many_customer”)
@Entity
public class Customer2 { private Integer id;
private String lastName; private String email;
private int age; private Date birthday; private Date createdTime; private Set<Order2> orders = new HashSet<Order2>();
@TableGenerator(name=“ID_GENERATOR_2”,
table=“t_id_generator”,
pkColumnName=“PK_NAME”,
pkColumnValue=“seedId_t_customer2”,
valueColumnName=“PK_VALUE”,
allocationSize=20,
initialValue=10
)
@GeneratedValue(strategy=GenerationType.TABLE, generator=“ID_GENERATOR_2”)
@Id
@Column(name=“ID”)
public Integer getId() {
return id;
} /**
* 1、双向1-n关联的时候,一般1的一方放弃维护关联关系,而由n的一方维护关联关系。
* 这样做的好处就是:先保存1的一端,再保存n的一端的时候不会有多余的update sql语句
* 2、使用@OneToMany(mappedBy=“customer”)来指明由n的一方的哪个属性来维护关联关系
* 3、有一个值得注意的地方:如果指明了mappedBy=“customer”,那么久不能够再使用@JoinColumn注解了。
*/
//@JoinColumn(name=“CUSTOMER_ID”)
@OneToMany(mappedBy=“customer”)
public Set<Order2> getOrders() {
return orders;
} public void setOrders(Set<Order2> orders) {
this.orders = orders;
} @Column(name=“LAST_NAME”, length=50, nullable=false)
public String getLastName() {
return lastName;
} @Column(name=“BIRTHDAY”)
@Temporal(TemporalType.DATE)
public Date getBirthday() {
return birthday;
} @Column(name=“CREATED_TIME”, columnDefinition=“DATE”)
public Date getCreatedTime() {
return createdTime;
} @Column(name=“EMAIL”,columnDefinition=“TEXT”)
public String getEmail() {
return email;
} /*
* 工具方法,不需要映射为数据表的一列
*/
@Transient
public String getInfo(){
return “lastName: ” + lastName + “ email: ” + email;
} @Column(name=“AGE”)
public int getAge() {
return age;
} @SuppressWarnings(“unused”)
private void setId(Integer id) {
this.id = id;
} public void setLastName(String lastName) {
this.lastName = lastName;
} public void setEmail(String email) {
this.email = email;
} public void setAge(int age) {
this.age = age;
} public void setBirthday(Date birthday) {
this.birthday = birthday;
} public void setCreatedTime(Date createdTime) {
this.createdTime = createdTime;
} }
List_7. Order2.java(作为n的一方,有对1的一方的对象的引用,维护关联关系)
package com.magicode.jpa.doubl.many2one; import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.ManyToOne;
import javax.persistence.Table;
import javax.persistence.TableGenerator; @Table(name=“t_double_one2many_order”)
@Entity
public class Order2 { private Integer id;
private String orderName; private Customer2 customer;
@TableGenerator(name=“order_id_generator_2”,
table=“t_id_generator”,
pkColumnName=“PK_NAME”,
pkColumnValue=“seedId_t_order2”,
valueColumnName=“PK_VALUE”,
initialValue=0,
allocationSize=20)
@GeneratedValue(generator=“order_id_generator_2”, strategy=GenerationType.TABLE)
@Id
@Column(name=“ID”)
public Integer getId() {
return id;
} /**
* 这里的name=“CUSTOMER_ID”会作为Order对象存放的数据库表的一个外键列
* 用于维护关联关系
*/
@ManyToOne
@JoinColumn(name=“CUSTOMER_ID”)
public Customer2 getCustomer() {
return customer;
} public void setCustomer(Customer2 customer) {
this.customer = customer;
} @Column(name=“ORDER_NAME”)
public String getOrderName() {
return orderName;
} @SuppressWarnings(“unused”)
private void setId(Integer id) {
this.id = id;
} public void setOrderName(String orderName) {
this.orderName = orderName;
} }
List_8. 测试代码
package com.magicode.jpa.doubl.many2one; import java.util.Date; import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence; import org.junit.After;
import org.junit.Before;
import org.junit.Test; public class DoubleMany2OneTest { EntityManagerFactory emf = null;
EntityManager em = null;
EntityTransaction transaction = null; @Before
public void before(){
emf = Persistence.createEntityManagerFactory(“jpa-1”);
em = emf.createEntityManager();
transaction = em.getTransaction();
transaction.begin();
} @After
public void after(){
transaction.commit();
em.close();
emf.close();
} @Test
public void testPersist(){ int i = 1; char c = (char) ('A' + i);
String strName = (“ ” + c + c).trim();
int age = 25 + i; Customer2 customer = new Customer2();
customer.setAge(age);
customer.setEmail(strName + “@163.com”);
customer.setLastName(strName);
customer.setBirthday(new Date());
customer.setCreatedTime(new Date()); Order2 order1 = new Order2();
order1.setOrderName(“O-” + strName + “-1”); Order2 order2 = new Order2();
order2.setOrderName(“O-” + strName + “-2”); //设置关联关系
customer.getOrders().add(order1);
customer.getOrders().add(order2); order1.setCustomer(customer);
order2.setCustomer(customer); //持久化操作
/**
* 双向1-n的关联关系中,1的一方放弃维护关联关系,由n的一方维护关联关系。
* 建议“先保存1的一端,再保存n的一端”,这样就不会有多余的update sql语句
*/
em.persist(customer);
em.persist(order1);
em.persist(order2);
} @Test
public void testFind(){
/**
* 双向多对一在查询时默认的策略如下:
* 1、检索1的一方的时候,其包含的对n的集合属性的检索默认采用延迟加载,
* 可以设置@OneToMany(fetch=FetchType.EAGER)来修改为立即加载策略;
*
* 2、检索n的一方的时候,对其包含的1的一方默认采用立即加载策略,
* 可以设置@ManyToOne(fetch=FetchType.LAZY)来修改为延迟加载策略;
*
* 很容易记混淆。但是我们可以深入思考一下,这样做是有道理的:
* ①、1的一方包含了对n的一方的集合属性,在检索的时候集合中到底有多少个元素我们根本
* 就不知道,可能是几个,也可能是1000000个呢!!!如果默认采用立即检索策略,可以想
* 象后果有多严重。
* ②、n的一方包含了1的一方的一个对象,这和一个Integer或者是String类型的对象
* 没有区别。也不会像集合那样可能占用巨大的内存资源。
*
*/
Customer2 customer = em.find(Customer2.class, 11); System.out.println(“---------”);
System.out.println(customer.getOrders().iterator().next().getOrderName()); System.out.println(“---------”);
Order2 order = em.find(Order2.class, 1);
System.out.println(“---------”);
System.out.println(order.getCustomer().getEmail());
} @Test
public void testRemove(){
/**
* 双向n-1关联关系,在默认的情况下,如果1的一方集合中还保存有n的一方的引用,那么是无法删除1的一方的;
* 但是可以任意删除n的一方。
* 可以设置@OneToMany(cascade={CascadeType.REMOVE})来进行级联删除:删除1的同时,把其
* 关联的n的一方同时删除;
*/
// Customer2 customer = em.find(Customer2.class, 11);
// em.remove(customer); Order2 order = em.find(Order2.class, 1);
em.remove(order);
}
}
8、双向一对多的关联关系(等同于双向多对一。1的一方有对n的一方的集合的引用,同时n的一方有对1的一方的引用)的更多相关文章
- JPA中实现双向一对多的关联关系
场景 JPA入门简介与搭建HelloWorld(附代码下载): https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/103473937 ...
- Hibernate5.2关联关系之双向一对多(三)
Hibernate之双向一对多(三) 一.简介 本篇博文接着上一章的内容接着开展,代码也是 ...
- JPA学习笔记(8)——映射双向一对多关联关系
双向一对多关联关系 前面的博客讲的都是单向的,而本问讲的是双向的(双向一对多 = 双向多对一) 什么是双向? 我们来对照一下单向和双向 单向/双向 User实体类中是否有List< Order& ...
- Mybatis框架中实现双向一对多关系映射
学习过Hibernate框架的伙伴们很容易就能简单的配置各种映射关系(Hibernate框架的映射关系在我的blogs中也有详细的讲解),但是在Mybatis框架中我们又如何去实现 一对多的关系映射呢 ...
- JPA(七):映射关联关系------映射双向多对一的关联关系
映射双向多对一的关联关系 修改Customer.java package com.dx.jpa.singlemanytoone; import java.util.Date; import java. ...
- Hibernate 双向一对多的关联映射
双向的一对多的关联关系是单项的一对多和单项的多对一的情况下产生的. 1.设计表结构 虽然关联关系变为双向的一对多,但是我们表结构不会发生改变,只是指向变了. 2.创建student对象 3.创建Gra ...
- Hibernate关联映射(单项多对一和一对多、双向一对多)
最近总是接触着新的知识点来扩展自己的知识面:不停的让自己在原地接触天空的感觉真的很美好!!!革命没有成功,程序员的我们怎么能不努力呢...... 一.用员工和部门来剖析关联映射的原理. 1)从这张截图 ...
- hibernate 自生双向一对多 多对一管理 (树)
<span style="font-size: large;">package com.javacrazyer.test; import java.io.Seriali ...
- hibernate中配置单向多对一关联,和双向一对多,双向多对多
什么是一对多,多对一? 一对多,比如你去找一个父亲的所有孩子,孩子可能有两个,三个甚至四个孩子. 这就是一对多 父亲是1 孩子是多 多对一,比如你到了两个孩子,它们都是有一个共同的父亲. 此时孩子就是 ...
随机推荐
- malloc函数
C语言中,使用malloc函数向内存中动态申请空间. 函数的原型是extern void *malloc(unsigned int num_bytes); 可见,函数返回的是指针类型,参数是要申请的空 ...
- django - transaction
def user_atomic(): User.objects.create(name='purk1', email='pwu1@maxprocessing.com') User.objects.cr ...
- PyQt4学习笔记1:PyQt4第一个程序
创建一个 PyQt4 一般可以通过很少的步骤完成.通常的方法是用Qt 提供的QtDesigner工具创建界面.使用QtDesigner,可以方便地创建复杂的GUI界面.然后,可以在窗口上创建部件, 添 ...
- 深入剖析——float之个人见解
浮动的原本作用仅仅是为了实现文字的环绕效果. 以下分别是html与css代码,显示效果如下图.因为两个div使用了float浮动属性,所以脱离了标准文档流.让父元素撑开高度,我们需要清除浮动. < ...
- hadoop集群默认配置和常用配置【转】
转自http://www.cnblogs.com/ggjucheng/archive/2012/04/17/2454590.html 获取默认配置 配置hadoop,主要是配置core-site.xm ...
- 从零开始学ios开发(二十):Application Settings and User Defaults(下)
在上一篇的学习中,我们知道了如何为一个App添加它的Settings设置项,在Settings设置项中我们可以添加哪些类型的控件,这些控件都是通过一个plist来进行管理的,我们只需对plist进行修 ...
- 简单的C#线程开发实例(隔一秒改变一下Label的Text)
要实现的效果:点击按纽,窗口上的label上出现1~100数字的变化. 第一个实例(把窗口上的label上文字改成0): using System; using System.Windows.Form ...
- 服务器端spice配置详解
1. 安装必要的工具 sudo apt-get install build-essential autoconf git-core intltool 2. 安装必要的依赖包 -dev libxfixe ...
- Careercup - Facebook面试题 - 5729456584916992
2014-05-02 00:59 题目链接 原题: Given a normal binary tree, write a function to serialize the tree into a ...
- WebApi参数传递总结
在WebAPI中,请求主体(HttpContent)只能被读取一次,不被缓存,只能向前读取的流. 举例子说明: 1. 请求地址:/?id=123&name=bob 服务端方法: void Ac ...