mapreduce 中 map数量与文件大小的关系
学习mapreduce过程中, map第一个阶段是从hdfs 中获取文件的并进行切片,我自己在好奇map的启动的数量和文件的大小有什么关系,进过学习得知map的数量和文件切片的数量有关系,那文件的大小和切片的数量的有什么关系 ,下面我就进入Hadoop的源代码进行研究一下 文件的大小和切片的数量有什么关系。
文件获取和切片和一个InputFormat 这个抽象类有关系 ,这个抽象类 只有两个抽象的方法 分别是
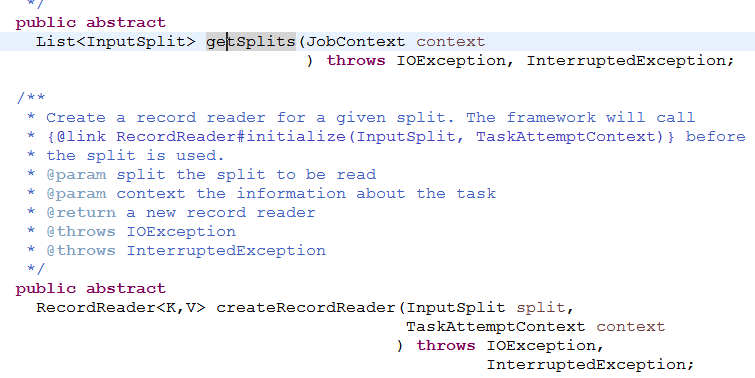
第一个方法是用来过去切片,第二方法使用获取文件。获取切片与第一个方法有关,我们进入研究这个方法 那我们看一下这个类的实现类是怎样来实现这个方法的
子类的实现方法太长 我们就看和我们相关的东西 来探究文件的大小和切片数量有什么关系

这一部分是用来处理文件大小和切片的关系,blocksize 是就是128M 那个SPLIT_SLOP 那个值是1.1 length 的长度是用来表示文件的长度,那从上面不难看出,如果有一个一个文件的大小与块大小进行求余运算的如果小于12.8的话 那多出来那部分不会重新分配一个切片,会和最后一个切片组成一个切片 也就是说,如果一个129M的文件的话他就会是一个切片而不是两个,我在某些书中看到这个这样的说法 就是如果一个文件的大小与块大小进行相除除不尽的话,就需要多分出一个切片这种说法是不正确的,这要看文件的大小来看,取余小于12.8M的话,那就不会分出一个切片。我想写这个代码的人也是有考虑的如果文件的大小仅仅比一个块多一点而运行一个map 这样是非常浪费资源的,所以会将最后一个切片的大小会进行改变。
mapreduce 中 map数量与文件大小的关系的更多相关文章
- 【Hadoop】三句话告诉你 mapreduce 中MAP进程的数量怎么控制?
1.果断先上结论 1.如果想增加map个数,则设置mapred.map.tasks 为一个较大的值. 2.如果想减小map个数,则设置mapred.min.split.size 为一个较大的值. 3. ...
- MapReduce中map并行度优化及源码分析
mapTask并行度的决定机制 一个job的map阶段并行度由客户端在提交job时决定,而客户端对map阶段并行度的规划的基本逻辑为:将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分 ...
- 如何确定Hadoop中map和reduce的个数--map和reduce数量之间的关系是什么?
一般情况下,在输入源是文件的时候,一个task的map数量由splitSize来决定的,那么splitSize是由以下几个来决定的 goalSize = totalSize / mapred.map. ...
- mapreduce中控制mapper的数量
很多文档中描述,Mapper的数量在默认情况下不可直接控制干预,因为Mapper的数量由输入的大小和个数决定.在默认情况下,最终input占据了多少block,就应该启动多少个Mapper.如果输入的 ...
- hadoop中map和reduce的数量设置
hadoop中map和reduce的数量设置,有以下几种方式来设置 一.mapred-default.xml 这个文件包含主要的你的站点定制的Hadoop.尽管文件名以mapred开头,通过它可以控制 ...
- hadoop中map和reduce的数量设置问题
转载http://my.oschina.net/Chanthon/blog/150500 map和reduce是hadoop的核心功能,hadoop正是通过多个map和reduce的并行运行来实现任务 ...
- java中map接口hashMap以及Enty之间的用法和关系
java中map接口hashMap以及Enty之间的转换 首先说的是map接口: Map提供了一种映射关系,其中的元素是以键值对(key-value)的形式存储的,能够实现根据key快速查找value ...
- Hadoop中maptask数量的决定因素
刚开始接触hadoop平台的时候 部分初学者对于mapreduce中的maptask的数量是怎么确定的 可能有点迷惑,如果看了jobclient里面的maptask初始化的那段源码,那么就比较清楚了, ...
- Hadoop学习笔记—12.MapReduce中的常见算法
一.MapReduce中有哪些常见算法 (1)经典之王:单词计数 这个是MapReduce的经典案例,经典的不能再经典了! (2)数据去重 "数据去重"主要是为了掌握和利用并行化思 ...
随机推荐
- [ISE 14.7] _pn.exe 崩溃问题 点击浏览崩溃问题
前言 装了大半天的ISE 14.7 结果新建工程的时候只要点击浏览文件夹,直接无响应,其实和其他_pn.exe崩溃是一样的. 解决方法 第一步:非常重要,进行文件备份,将"F:\Xilinx ...
- 转://oracle字符集
一.oracle字符集基础知识oracle数据库有国家字符集(national character set)与数据库字符集(database character set)之分.两者都是在创建数据库时需 ...
- MySQL的用户的创建以及远程登录配置
最近工作中使用HIve工具,因此搭建了一个Hive的测试环境.通常我们都将Hive的元数据信息存储在外界的MySQL中,因此需要安装并配置MySQL数据库.接下来将讲解MySQL的安装以及配置过程. ...
- Lock和Condition在JDK中LinkedBlockingQueue的应用
Lock和Condition在JDK中LinkedBlockingQueue的应用,核心源码注释解析如下: import java.util.concurrent.LinkedBlockingQueu ...
- day14 Python集合的补充
python_1 = ['charon','pluto','ran','charon'] linux_1 = ['ran','xuexue','ting'] p_s = set(python_1) l ...
- 各个版本的 Oracle 11.2.0.4下载地址
Oracle 11.2.0.4下载地址 Linux x86: https://updates.oracle.com/Orion/Services/download/p13390677_112040_L ...
- 在centos7上修改docker加速镜像为阿里云
使用docker pull,命令下载镜像太慢了,默认是从国外的,本文记录下如何配置国内阿里云竞相加速方式. 登录https://cr.console.aliyun.com,如下, 阿里云会为每个用户提 ...
- <数据结构与算法分析>读书笔记--要分析的问题
通常,要分析的最重要的资源就是运行时间.有几个因素影响着程序的运行时间.有些因素(如使用编译器和计算机)显然超出了任何理论模型的范畴,因此,虽然它们是重要的,但是我们在这里还是不能考虑它们.剩下的主要 ...
- Objective-C ARC下IBOutlet属性是用weak还是strong来修饰
1.苹果官方说明: From a practical perspective, in iOS and OS X outlets should be defined as declared proper ...
- Android学习之基础知识四-Activity活动2讲
一.在活动(activity)中添加Toast显示: 1.Toast作用:Android系统提供的一种非常好的提醒方式,将一些短小的信息提供给用户,这些信息会在一段时间后自动消失,不会占用任何屏幕空间 ...