lua的性能优化
Roberto Ierusalimschy写过经典的Lua 性能提示的文章,链接地址>>
我通过实际的代码来验证,发现一个问题。当我使用 LuaStudio 运行时,发现结果反而与提示相反,甚是奇怪,而使用luac进行运行,与作者给予的提示相符,在某些地方性能可能有优化,比如读取35kb的文件时,时间还是比较快的(可能5.1版本做过优化了)。
日常的Lua编码中,需要注意以下几点:
1)多使用local
print(_VERSION) local startTime, endTime startTime = os.clock() for i = 1, 100 * 10000 do
local x = math.sin(i)
end endTime = os.clock() print("[local] used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock() local sin = math.sin
for i = 1, 100 * 10000 do
local x = sin(i)
end endTime = os.clock() print("[local] used time " .. (endTime - startTime) * 1000 .. " ms")

上面二段代码,唯一的区别就是使用 local sin 将 math.sin缓存起来。性能提升约 (107 - 74) / 107 ~= 30.8%,基本符合作者所说的30%的效率提升。
startTime = os.clock()
function foo(x)
for i = 1, 100 * 10000 do
x = x + math.sin(i)
end
return x
end foo(10) endTime = os.clock() print("[foo] used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock()
function foo2(x)
local sin = math.sin
for i = 1, 100 * 10000 do
x = x + sin(i)
end
return x
end foo2(10) endTime = os.clock() print("[foo2] used time " .. (endTime - startTime) * 1000 .. " ms")
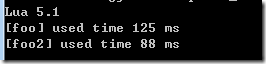
提升的时间是 (125 – 88) /125 = 29.6%,也约为30%(需要多次测试取平均值)
使用闭包,避免动态编译。
startTime = os.clock()
local lim = 10 * 10000
local a = {}
for i = 1, lim do
a[i] = loadstring(string.format("return %d", i))
end print(a[10]()) endTime = os.clock() print("used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock()
function fk(k)
return function() return k end
end local lim = 10 * 10000
local a = {}
for i = 1, lim do
a[i] = fk(i)
end
endTime = os.clock() print("used time " .. (endTime - startTime) * 1000 .. " ms")
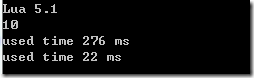
节省了约92%的时间,差异距大。
2) 字符串拼接,尽可能使用 table 替代
startTime = os.clock() local buff = ""
for line in io.lines("C:/Users/zhangyi/Desktop/xxx.txt") do
buff = buff .. line .. "\n"
end endTime = os.clock() print(collectgarbage("count") * 1024) print("used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock() local buff = ""
local tbl = {}
for line in io.lines("C:/Users/zhangyi/Desktop/xxx.txt") do
table.insert(tbl, line)
end buff = table.concat(table, "\n") endTime = os.clock() print(collectgarbage("count") * 1024) print("used time " .. (endTime - startTime) * 1000 .. " ms")
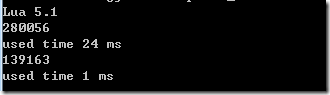
差异非常大,无论是内存还是时间,主要原因是:Lua中字符串的拼接都是新创建一个新的字符串,有一个新创建一块内存、copy字符串的动作,时间、空间上消耗都比较大。
3) table使用的优化
startTime = os.clock()
for i = 1, 100 * 10000 do
local a = {}
a[1] = 1
a[2] = 2
a[3] = 3
end
endTime = os.clock() print("used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock()
for i = 1, 100 * 10000 do
local a = {true, true, true}
a[1] = 1
a[2] = 2
a[3] = 3
end
endTime = os.clock() print("used time " .. (endTime - startTime) * 1000 .. " ms")
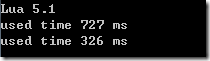
时间相差一倍,也就是说如果不给{}给定初时化大小,当赋值的时候,它会申请空间来存放相应的值。
local polyline= {}
for i = 0, 100 * 10000 do
table.insert(polyline, {x = i, y = 1})
end
print(collectgarbage("count") / 1024)
107.57151889801MB
local polyline= {}
for i = 0, 100 * 10000 do
table.insert(polyline, {i, 1})
end
print(collectgarbage("count") / 1024)
77.053853034973MB
local polyline= {
x = {},
y = {}
}
for i = 0, 100 * 10000 do
table.insert(polyline.x, i)
table.insert(polyline.y, i)
end
print(collectgarbage("count") / 1024)
32.019150733948MB
空间占用差距也非常大,从上面似乎可以得到这样的结论:尽可能减少table的长度,尽可能使用array 而不是 hash。
综上所述,尽可能多使用local,减少查询的性能损耗。json数据表如果需要转化为table时,改变数据的存储结构可能减少很大的内存使用。
lua的性能优化的更多相关文章
- Lua脚本性能优化指南
https://github.com/flily/lua-performance/blob/master/Guide.zh.md https://springrts.com/wiki/Lua_Perf ...
- Lua性能优化
原文:Lua Performance Tips 偶然找到<Lua Performance Tips>这篇关于Lua的优化文章,个人认为相较于多数泛泛而谈要好不少.尽管Lua已经到5.2版本 ...
- iOS app性能优化的那些事
iPhone上面的应用一直都是以流畅的操作体验而著称,但是由于之前开发人员把注意力更多的放在开发功能上面,比较少去考虑性能的问题,可能这其中涉及到objective-c,c++跟lua,优化起来相对 ...
- app 性能优化的那些事
来源:树下的老男孩 链接:http://www.jianshu.com/p/5cf9ac335aec iPhone上面的应用一直都是以流畅的操作体验而著称,但是由于之前开发人员把注意力更多的放在开发功 ...
- [转]Lua和Lua JIT及优化指南
一.什么是lua&luaJit lua(www.lua.org)其实就是为了嵌入其它应用程序而开发的一个脚本语言, luajit(www.luajit.org)是lua的一个Just-In-T ...
- luajit官方性能优化指南和注解
luajit是目前最快的脚本语言之一,不过深入使用就很快会发现,要把这个语言用到像宣称那样高性能,并不是那么容易.实际使用的时候往往会发现,刚开始写的一些小test case性能非常好,经常毫秒级就算 ...
- 用好lua+unity,让性能飞起来——关于《Unity项目常见Lua解决方案性能比较》的一些补充
<Unity项目常见Lua解决方案性能比较>,这篇文章对比了现在主流几个lua+unity的方案 http://blog.uwa4d.com/archives/lua_perf.html ...
- Nginx 服务器性能Bug和性能优化方案(真实经历)
一.遇到的问题 1.问题:本应该是3个ffmpeg ,但是怎么会有5个ffmpeg出现? 2.Lua脚本问题,一直写入日志,导致有大量的日志,这里的错误日志是直接写进nginx的error.log 日 ...
- "个性化空间"性能优化方案设计初步
一.问题的提出 在九月中开始,我们要打造个性化空间,领导要求的是只进行原型的设计,逻辑的设计,不进行技术开发.其实是严重不正确的,因为个性化空间其特点与现有的技术模型完全不同,现有的技术方案未必能适应 ...
随机推荐
- IISExpress运行网站时,Service Fabric报Could not load file or assembly 'Microsoft.ServiceFabric.Data' or one of its dependencies. An attempt was made to load a program with an incorrect format.
打开VS TOOLS > OPTIONS > Projects and Solutions > WEB PROJECTS,选中 "Use the 64 bit vers ...
- CentOS 7.2配置Apache服务httpd小伙伴们可以参考一下
这篇文章主要为大家详细介绍了CentOS 7.2配置Apache服务 httpd上篇,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 一.Perl + mod_perl 安装mod_perl使Per ...
- Python交互图表可视化Bokeh:5 柱状图| 堆叠图| 直方图
柱状图/堆叠图/直方图 ① 单系列柱状图② 多系列柱状图③ 堆叠图④ 直方图 1.单系列柱状图 import numpy as np import pandas as pd import matplo ...
- excel表格导入数据库数据存在则更新不存在添加
public void excelToDB() throws ParseException { String datapath = this.getParameter("datapath&q ...
- 2017-2018-2 20165220『Java程序设计』课程 结对编程练习_四则运算
需求分析 题目要求 一个命令行程序实现: 自动生成小学四则运算题目(加.减.乘.除) 支持整数 支持多运算符(比如生成包含100个运算符的题目) 支持真分数 统计正确率 需求理解 输入:需要计算的式子 ...
- TF之RNN:基于顺序的RNN分类案例对手写数字图片mnist数据集实现高精度预测—Jason niu
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input_dat ...
- Mysql漂流系列(一):MySQL的执行流程
MySQL的执行流程 MySQL的执行流程: MySQL的执行流程分析: 1.当我们请求mysql服务器的时候,MySQL前端会有一个监听,请求到了之后,服务器得到相关的SQL语句,执行之前(虚线部分 ...
- mysql数据库操作语句整合
查看版本:select version();显示当前时间:select now(); 注意:在语句结尾要使用分号; 远程连接 一般在公司开发中,可能会将数据库统一搭建在一台服务器上,所有开发人员共用一 ...
- SpringMVC(十四) RequestMapping ModelAndView
ModelAndView返回模型数据和视图.参考以下Demo代码,了解其实现方法.关注通过视图名称创建ModelAndView的构造方法,以及通过${requestScope.attribute}的方 ...
- XamarinAndroid组件教程设置自定义子元素动画(一)
XamarinAndroid组件教程设置自定义子元素动画(一) 如果在RecyclerViewAnimators.Animators中没有所需要的动画效果,就可以自定义一个.此时,需要让自定义的动画继 ...