Redis+TwemProxy(nutcracker)集群方案部署记录
Twemproxy 又称nutcracker ,是一个memcache、Redis协议的轻量级代理,一个用于sharding 的中间件。有了Twemproxy,客户端不直接访问Redis服务器,而是通过twemproxy 代理中间件间接访问。 Twemproxy 为 Twitter 开源产品,简单来说,Twemproxy是Twitter开发的一个redis代理proxy,类似于nginx的反向代理或者mysql的代理工具,如amoeba。Twemproxy通过引入一个代理层,可以将其后端的多台Redis或Memcached实例进行统一管理与分配,使应用程序只需要在Twemproxy上进行操作,而不用关心后面具体有多少个真实的Redis或Memcached存储。
一般来说,只要服务器上运行了Redis,那么就有可能造成一种非常可怕局面:服务器的内存将立刻被占满,而且一台Redis数据库的性能终归是有限制的,那么现在如果要求保证用户的执行速度快,就需要使用集群的设计。而对于集群的设计主要的问题就是解决单实例Redis的性能瓶颈。
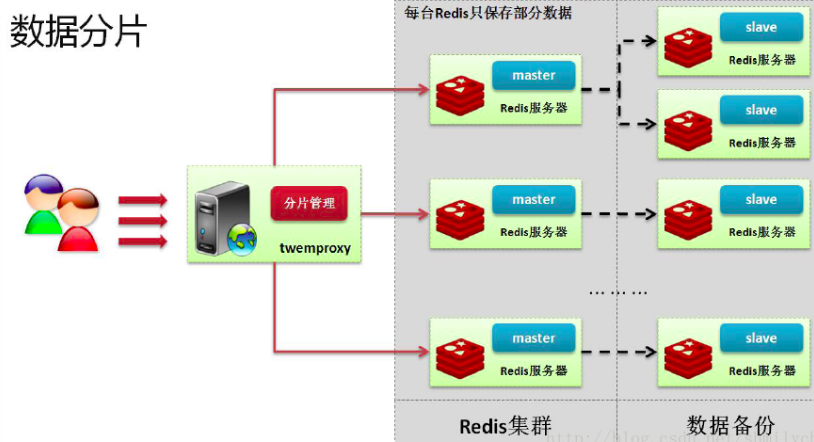
Twemproxy是一个专门为了这种nosql数据库设计的一款代理工具软件,这个工具软件最大的特征是可以实现数据的分片处理。所谓的分片指的是根据一定的算法将要保存的数据保存到不同的节点之中。 有了分片之后数据的保存节点就可能有无限多个,但是理论上如果要真进行集群的搭建,往往要求三台节点起步。Twemproxy代理机制具有如下特点:
1)支持失败节点自动删除
可以设置重新连接该节点的时间
可以设置连接多少次之后删除该节点
2)支持设置HashTag
通过HashTag可以自己设定将两个key哈希到同一个实例上去
3)减少与redis的直接连接数
保持与redis的长连接
减少了客户端直接与服务器连接的连接数量
4)自动分片到后端多个redis实例上
多种hash算法:md5、crc16、crc32 、crc32a、fnv1_64、fnv1a_64、fnv1_32、fnv1a_32、hsieh、murmur、jenkins
多种分片算法:ketama(一致性hash算法的一种实现)、modula、random
可以设置后端实例的权重
5)避免单点问题
可以平行部署多个代理层,通过HAProxy做负载均衡,将redis的读写分散到多个twemproxy上。
6)支持状态监控
可设置状态监控ip和端口,访问ip和端口可以得到一个json格式的状态信息串
可设置监控信息刷新间隔时间
7)使用 pipelining 处理请求和响应
连接复用,内存复用
将多个连接请求,组成reids pipelining统一向redis请求
8)并不是支持所有redis命令
不支持redis的事务操作
使用SIDFF, SDIFFSTORE, SINTER, SINTERSTORE, SMOVE, SUNION and SUNIONSTORE命令需要保证key都在同一个分片上。
举个小例子:比如可以把公司前台的MM看作一个proxy,你是个送快递的,你可以通过这个妹子替你代理把你要送达的包裹给公司内部的人,而你不用知道公司每个人座位在哪里。Twemproxy可以把多台redis server当作一台使用,开发人员通过twemproxy访问这些redis servers 的时候不用关心到底去哪一台redis server读取k-v数据或者把k-v数据更新到数据集中。
通过Twemproxy可以使用多台服务器来水平扩张redis服务,可以有效的避免单点故障问题。虽然使用Twemproxy需要更多的硬件资源和在redis性能有一定的损失(twitter测试约20%),但是能够提高整个系统的HA也是相当划算的。比如我所在的公司,只使用一台redis server进行读写,但是还有一台slave server一直在同步这台生产服务器的数据。这样做就是为了防止这台单一的生产服务器出现故障时能够有一个"备胎",可以把前端的redis数据读写请求切换到从服务器上,web程序因而不需要直接去访问mysql数据库。再借助于haproxy(又是proxy)或者VIP技术可以实现一个简单的HA方案,可以避免单点故障。但是这种简单的Master-Slave"备胎"方案不能扩张整个redis的容量(如果用系统内存大小衡量,且不考虑内存不足时把数据swap到磁盘上),最大容量由所有的redis servers中最小内存决定的【木桶的短板】。
Twemproxy可以把数据sharding(碎片,这里是分散的意思)到多台服务器的上,每台服务器存储着整个数据集的一部分。因而,当某一台redis服务器宕机了,那么也就失去了一部分数据。如果借助于redis的master-slave replication,能保证在任何一台redis不能工作情况下,仍然能够保证能够存在一个整个数据集的完全覆盖,那么整个redis group(或者称作cluster)仍然能够正常工作。
需要注意的是:
Twemproxy不会增加Redis的性能指标数据,据业界测算,使用twemproxy相比直接使用Redis会带来大约10%的性能下降。但是单个Redis进程的内存管理能力有限。据测算,单个Redis进程内存超过20G之后,效率会急剧下降。目前,建议单个Redis最好配置在8G以内;8G以上的Redis缓存需求,通过Twemproxy来提供支持。
Twemproxy是一种代理分片机制,由Twitter开源,主要用于减少后端缓存服务器的连接数量。Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis或memcached服务器,再原路返回。该方案很好的解决了单个Redis或memcached实例承载能力的问题。Twemproxy本身也是单点,需要用Keepalived做高可用方案,可以使用多台服务器来水平扩张redis或memcached服务,可以有效的避免单点故障问题。
-----------------------------------------------------------------------------------------------------------------------------------------------------
下面记录下Redis+Twemproxy(nutcracker)集群部署过程:
先简单看下集群架构

Twemproxy可以把多台redis server当作一台使用,扩大整个redis的容量,开发人员通过twemproxy访问这些redis servers 的时候不用关心到底去哪一台redis server读取k-v数据或者把k-v数据更新到数据集中。
1)集群环境
182.48.115.236 twemproxy-server 安装nutcracker
182.48.115.237 redis-server1 安装redis
182.48.115.238 redis-server2 安装redis 如果在线上使用的话:
中间代理层twemproxy需要2台,并且需要结合keepalived(心跳测试)实现高可用,客户端通过vip资源访问twemproxy。
另外,后面的redis节点也都要做主从复制环境。因为twemproxy会将数据碎片到每个redis节点上,如果节点挂了,那部分数据就没了。所以最好对每个redis节点机做主从,防止数据丢失。 这里做测试,我只使用一台twemproxy+2个redis节点(不做主从)。 关闭三台机器的iptables防火墙和selinux 2)在两台redis机器上安装并启动redis
可以参考:http://www.cnblogs.com/kevingrace/p/6265722.html 3)在twemproxy-server机器上安装nutcracker 编译安装autoconf
[root@twemproxy-server ~]# wget http://ftp.gnu.org/gnu/autoconf/autoconf-2.69.tar.gz
[root@twemproxy-server ~]# tar -zvxf autoconf-2.69.tar.gz
[root@twemproxy-server ~]# cd autoconf-2.69
[root@twemproxy-server autoconf-2.69]# ./configure && make && make install 编译安装automake
[root@twemproxy-server ~]# wget http://ftp.gnu.org/gnu/automake/automake-1.15.tar.gz
[root@twemproxy-server ~]# tar -zvxf automake-1.15.tar.gz
[root@twemproxy-server ~]# cd automake-1.15
[root@twemproxy-server automake-1.15]# ./configure && make && make install 编译安装libtool
[root@twemproxy-server ~]# wget https://ftp.gnu.org/gnu/libtool/libtool-2.4.6.tar.gz
[root@twemproxy-server ~]# tar -zvxf libtool-2.4.6.tar.gz
[root@twemproxy-server ~]# cd libtool-2.4.6
[root@twemproxy-server libtool-2.4.6]# ./configure && make && make install 编译安装twemproxy
[root@twemproxy-server ~]# wget https://github.com/twitter/twemproxy/archive/master.zip
[root@twemproxy-server ~]# unzip master.zip
[root@twemproxy-server ~]# cd twemproxy-master
[root@twemproxy-server twemproxy-master]# aclocal
[root@twemproxy-server twemproxy-master]# autoreconf -f -i -Wall,no-obsolete //执行autoreconf 生成 configure文件等
[root@twemproxy-server twemproxy-master]# ./configure --prefix=/usr/local/twemproxy/
[root@twemproxy-server twemproxy-master]# make && make install .................................................................................
注意:如果没有安装libtool 的话,autoreconf 的时候会报错,如下:
configure.ac:133: the top level
configure.ac:36: error: possibly undefined macro: AC_PROG_LIBTOOL
If this token and others are legitimate, please use m4_pattern_allow.
See the Autoconf documentation.
autoreconf: /usr/local/bin/autoconf failed with exit status: 1
................................................................................. twemproxy配置:
[root@twemproxy-server ~]# cd /usr/local/twemproxy/
[root@twemproxy-server twemproxy]# ls
sbin share
[root@twemproxy-server twemproxy]# cp -r /root/twemproxy-master/conf /usr/local/twemproxy/
[root@twemproxy-server twemproxy]# cd conf/
[root@twemproxy-server conf]# ls
nutcracker.leaf.yml nutcracker.root.yml nutcracker.yml
[root@twemproxy-server conf]# cp nutcracker.yml nutcracker.yml.bak
[root@twemproxy-server conf]# vim nutcracker.yml
alpha: //这个名称可以自己随意定义
listen: 182.48.115.236:22121
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
server_retry_timeout: 2000
server_failure_limit: 1
servers: //这里配置了两个分片
- 182.48.115.237:6379:1
- 182.48.115.238:6379:1 [root@twemproxy-server conf]# nohup /usr/local/twemproxy/sbin/nutcracker -c /usr/local/twemproxy/conf/nutcracker.yml & [root@twemproxy-server conf]# ps -ef|grep nutcracker
root 6407 24314 0 23:26 pts/0 00:00:00 /usr/local/twemproxy/sbin/nutcracker -c /usr/local/twemproxy/conf/nutcracker.yml
root 6410 24314 0 23:26 pts/0 00:00:00 grep nutcracker
[root@twemproxy-server conf]# lsof -i:22121
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nutcracke 6407 root 5u IPv4 155109 0t0 TCP localhost:22121 (LISTEN) 4)测试 twemproxy set/get ,后端分片查看 [root@twemproxy-server ~]# redis-cli -h 182.48.115.236 -p 22121
182.48.115.236:22121> 测试短key - value
[root@twemproxy-server ~]# redis-cli -h 182.48.115.236 -p 22121
182.48.115.236:22121> set wangshibo 666666
OK
182.48.115.236:22121> get wangshibo
"666666" 测试长key - value
182.48.115.236:22121> set huihuihuihuihuihui "hahahahahahahahhahahahahahahahhahahahahahah"
OK
182.48.115.236:22121> get huihuihuihuihuihui
"hahahahahahahahhahahahahahahahhahahahahahah" 登录两台redis节点上查看,发现已经有分片了
[root@redis-server1 ~]# redis-cli -h 182.48.115.237 -p 6379
182.48.115.237:6379> get wangshibo
"666666"
182.48.115.237:6379> get huihuihuihuihuihui
"hahahahahahahahhahahahahahahahhahahahahahah" [root@redis-server2 ~]# redis-cli -h 182.48.115.238 -p 6379
182.48.115.238:6379> get wangshibo
"666666"
182.48.115.238:6379> get huihuihuihuihuihui
"hahahahahahahahhahahahahahahahhahahahahahah"
Redis+TwemProxy(nutcracker)集群方案部署记录的更多相关文章
- ProxySQL Cluster 高可用集群环境部署记录
ProxySQL在早期版本若需要做高可用,需要搭建两个实例,进行冗余.但两个ProxySQL实例之间的数据并不能共通,在主实例上配置后,仍需要在备用节点上进行配置,对管理来说非常不方便.但是Proxy ...
- Redis+Twemproxy+HAProxy集群(转) 干货
原文地址:Redis+Twemproxy+HAProxy集群 干货 Redis主从模式 Redis数据库与传统数据库属于并行关系,也就是说传统的关系型数据库保存的是结构化数据,而Redis保存的是一 ...
- kafka 基础知识梳理及集群环境部署记录
一.kafka基础介绍 Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特 ...
- Centos7下ELK+Redis日志分析平台的集群环境部署记录
之前的文档介绍了ELK架构的基础知识,日志集中分析系统的实施方案:- ELK+Redis- ELK+Filebeat - ELK+Filebeat+Redis- ELK+Filebeat+Kafka+ ...
- LVS+Heartbeat 高可用集群方案操作记录
之前分别介绍了LVS基础知识和Heartbeat基础知识, 今天这里简单说下LVS+Heartbeat实现高可用web集群方案的操作说明. Heartbeat 项目是 Linux-HA 工程的一个组成 ...
- Redis高可用集群方案——哨兵
本篇文章版权归博客园和作者吴双本人共同所有,转载和爬虫请注明原文系列地址http://www.cnblogs.com/tdws/tag/NoSql/ 本人之前有篇文章,讲到了redis主从复制,读写分 ...
- Haproxy+Heartbeat 高可用集群方案操作记录
之前详细介绍了haproxy的基础知识点, 下面记录下Haproxy+Heartbeat高可用web集群方案实现过程, 以加深理解. 架构草图如下: 1) 基本环境准备 (centos6.9系统) 1 ...
- Mongodb副本集+分片集群环境部署记录
前面详细介绍了mongodb的副本集和分片的原理,这里就不赘述了.下面记录Mongodb副本集+分片集群环境部署过程: MongoDB Sharding Cluster,需要三种角色: Shard S ...
- kubeadm安装kubernetes 1.13.1集群完整部署记录
k8s是什么 Kubernetes简称为k8s,它是 Google 开源的容器集群管理系统.在 Docker 技术的基础上,为容器化的应用提供部署运行.资源调度.服务发现和动态伸缩等一系列完整功能,提 ...
随机推荐
- 转:更改SQLServer实例默认字符集
需求 安装数据库时,将字符集安装成了“SQL_Latin1_General_CP1_CI_AS”,现在需要将其更改为“Chinese_PRC_CI_AS”. 方法 重新生成系统数据库 ,然后还原配 ...
- Scrapy爬取遇到的一点点问题
学了大概一个月Scrapy,自己写了些东东,遇到很多问题,这几天心情也不大好,小媳妇人也不舒服,休假了,自己研究了很久,有些眉目了 利用scrapy 框架爬取慕课网的一些信息 步骤一:新建项目 scr ...
- 启动OpenVPN失败
启动OpenVPN失败 文:铁乐与猫 [root@yunwei_OpenVPN openvpn]# systemctl status openvpn ● openvpn.service - LSB: ...
- 4.7 Sublime Text3 中配置 Python环境 --之上安装Sublime 3
返回总目录 目录: 1.展示效果: 2.缺优分析: 3.下载Sublime Text3 (一)展示效果: 1.能够交互式编写Python代码: 2.可以编写文件式Python代码: 3.能够自动补齐代 ...
- 第3章 Git使用人门
[初识Github] 首先让我们大家一起喊一句“Hello Github”.YEAH!就是这样. Git是一个分布式的版本控制系统,最初由Linus Torvalds编写,用作Linux内核代码的管理 ...
- Git学习记录 力做全网最强入门教程
目录 Git学习记录 力做全网最强入门教程 什么是GitHub? 什么是Git? Git的配置 Git的安装(只介绍windos操作系统下) Git的配置 至此我们的入门教程到此结束,更新中级教程要等 ...
- 4、爬虫之mongodb
mongodb 简介 MongoDB是一个基于分布式文件存储的数据库.由C++语言编写.旨在为WEB应用提供可扩展的高性能数据存储解决方案. MongoDB是一个介于关系数据库和非关系数据库之间的产品 ...
- android:layout_margin真实含义 及 自己定义复合控件 layout()运行无效的问题解决
一.关于layout_margin 搞Android时间也不短了.对layout_margin也不陌生了,可近期遇到一个问题让我发现,对它的认识还不够深入全面.大量网络资料上都说,layout_mar ...
- MyCat不适用场景(使用时避免)
1.非分片字段查询 Mycat中的路由结果是通过分片字段和分片方法来确定的.例如下图中的一个Mycat分库方案: · 根据 tt_waybill 表的 id 字段来进行分片 · ...
- 【转】windows 控制台cmd乱码的解决办法
windows 控制台cmd乱码的解决办法 我本机的系统环境: OS Name: Microsoft Windows 10 企业版 OS Version: 10.0.14393 N/A Build 1 ...