算法入门及其C++实现
https://github.com/yuwei67/Play-with-Algorithms
(nlogn)为最优排序算法
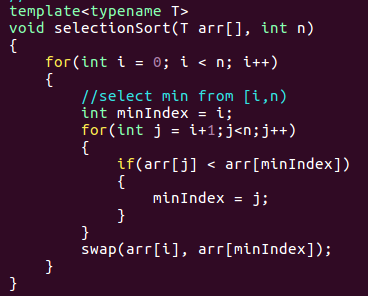
选择排序
整个数组中,先选出最小元素的位置,将该位置与当前的第一位交换;然后选出剩下数组中,最小元素的位置,将此元素与第二位元素交换;以此类推






srand和rand函数使用前,需要包含 stdlib.h和time.h;
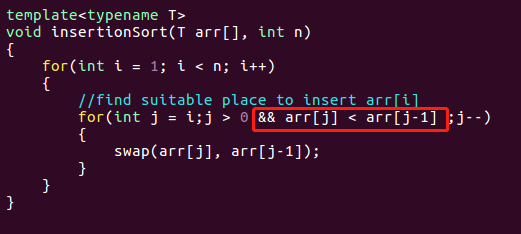
插入排序
类似于玩扑克牌时的思想,看后面牌中的每一张牌,然后插入到前方合适的位置

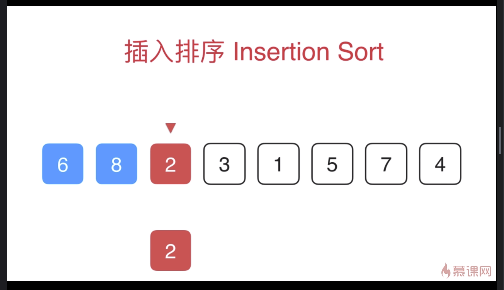
单独看8,不需要排序

6与前面的8比,6小于8,于是6和8互换位置



2先和8比,2小于8,于是互换位置

接下来2和6比,2小于6,于是互换位置,至此前三个数排序结束,后面的排序同理。


相较于选择排序,不需要每次遍历所有内容,有提前终止机会,当数组近乎有序时,插入排序效率远高于选择排序,甚至比很多O(nlogn)级别排序算法效率高;
优化插入排序:不贸然交换位置,思路如下






当考察 “2” 时,先把2这个元素复制一个副本,看是否应该放在这个位置,发现2比前面的8小,所以不应该放在这儿,那么将此位置的值赋值为8,然后考察2是不是应该放在原来8的位置;2比这个位置的前一个位置的6要小,所以6放到这个位置;之后看2是不是应该放在原来6的位置,由于是第0个位置,所以2应该放在此处,至此,对2的排序结束。
一次swap是3次赋值,优化后变为多次比较后1次赋值
插入排序,对近乎有序的数组,可以降到O(N)的复杂度
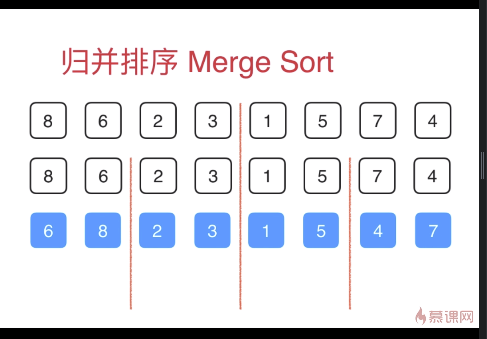
归并排序(自顶向下,使用递归)
将数组对半分成2份,左右分别单独排序,本质是递归排序的过程。


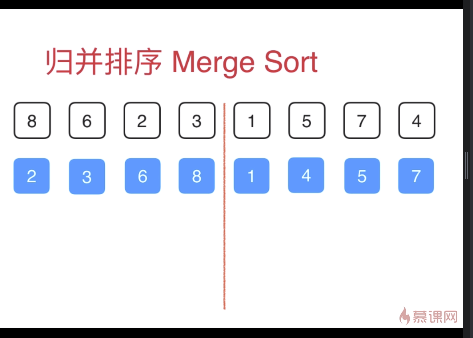

时间复杂度比O(N^2)小,但是需要开辟辅助空间
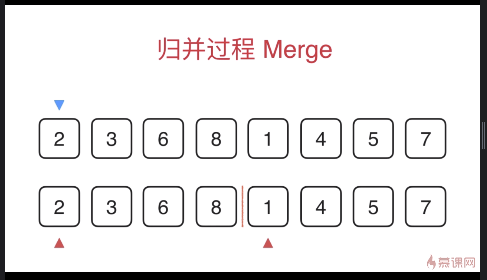

1比2小,所以1放在蓝色指针当前位置,蓝色指针后移,辅助空间中1对应的红色指针后移

之后比较2和4,具体过程同前一步,以此类推。
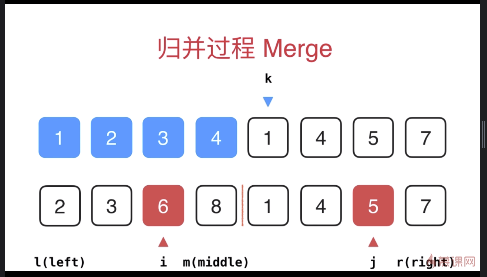
具体实现:i 和 j 表示当前正在考虑的元素,k 指向这两个元素相比较之后,最终应该放到归并数组中的位置(是下一个需要放置的位置,不是已经排好序的最后一位)
代码示例(未优化,对近乎有序数组性能较差):
// 将arr[l...mid]和arr[mid+1...r]两部分进行归并
template<typename T>
void __merge(T arr[], int l, int mid, int r){ // 经测试,传递aux数组的性能效果并不好
T aux[r-l+];
for( int i = l ; i <= r; i ++ )
aux[i-l] = arr[i]; int i = l, j = mid+;
for( int k = l ; k <= r; k ++ ){ if( i > mid ) { arr[k] = aux[j-l]; j ++;}
else if( j > r ){ arr[k] = aux[i-l]; i ++;}
else if( aux[i-l] < aux[j-l] ){ arr[k] = aux[i-l]; i ++;}
else { arr[k] = aux[j-l]; j ++;}
}
} // 递归使用归并排序,对arr[l...r]的范围进行排序
template<typename T>
void __mergeSort(T arr[], int l, int r){ if( l >= r )
return; int mid = (l+r)/;
__mergeSort(arr, l, mid);
__mergeSort(arr, mid+, r);
__merge(arr, l, mid, r);
} template<typename T>
void mergeSort(T arr[], int n){ __mergeSort( arr , , n- );
}
代码优化(第一次)
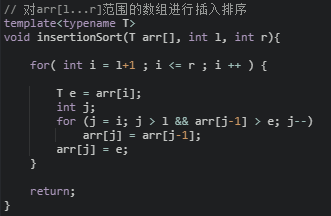
20 // 递归使用归并排序,对arr[l...r]的范围进行排序
21 template<typename T>
22 void __mergeSort(T arr[], int l, int r){
23
//对所有条件的优化(小数组使用插入排序,一是因为此时数组近乎有序的概率会比较大,
//二是因为 N^2 和 NlogN 前是有常数的系数的,对于这个系数,插入排序比归并排序小,所以当N小到一定程度时,插入排序会比归并排序快一些)
//15这个数是最优的么?
24 //if( l >= r )
25 // return;
if( r - l <= 15)
{
insertionSort(arr,l,r);
}
26
27 int mid = (l+r)/2;
28 __mergeSort(arr, l, mid);
29 __mergeSort(arr, mid+1, r);
//对近乎有序数组的优化
if(arr[mid] > arr[mid+1])
30 __merge(arr, l, mid, r);
31 }
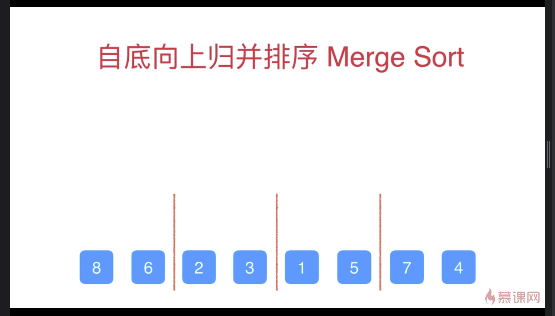
归并排序(自底向上,使用迭代,统计意义上效率稍弱于递归方式实现)
由于没有使用索引直接获取元素,可以非常好的使用NlogN的时间对链表这样的数据结构进行排序






快速排序
思路:每次从当前数组中选择一个元素,将这个元素想办法挪到排好序的数组中应该在的位置,那么以这个元素为基点,前面的数比他小,后面的数比他大。
之后对前后两个数组分别继续使用快速排序。

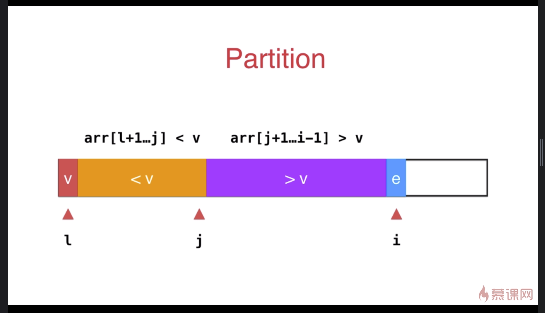
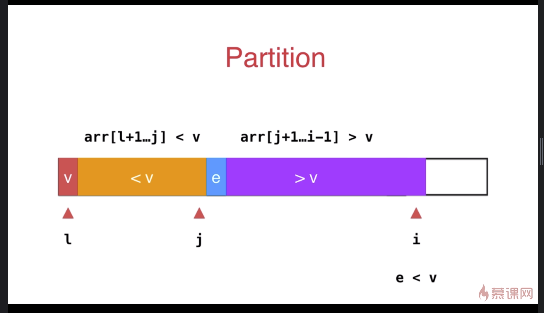
子过程如下:如果当前访问的元素 e 比 v 大,i 指针直接后移;否则调换 i 和 j 后面元素的位置,j 指针后移, i 指针后移;遍历完成后,交换 l 和 j 元素的位置。

// 对arr[l...r]部分进行partition操作
// 返回p,使得arr[l...p-1] < arr[p] ; arr[p+1...r] > arr[p]
template <typename T>
int __partition(T arr[], int l, int r){ T v = arr[l]; int j = l; // arr[l+1...j] < v ; arr[j+1...i) > v
for( int i = l + ; i <= r ; i ++ )
if( arr[i] < v ){
j ++;
swap( arr[j] , arr[i] );
} swap( arr[l] , arr[j]); return j;
} // 对arr[l...r]部分进行快速排序
template <typename T>
void __quickSort(T arr[], int l, int r){ if( l >= r )
return; int p = __partition(arr, l, r);
__quickSort(arr, l, p- );
__quickSort(arr, p+, r);
} template <typename T>
void quickSort(T arr[], int n){ __quickSort(arr, , n-);
}
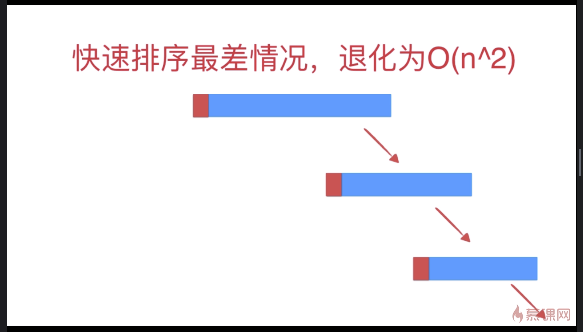
快速排序优化(针对近乎有序数组)
template <typename T>
int _partition(T arr[], int l, int r){ swap( arr[l] , arr[rand()%(r-l+)+l] ); T v = arr[l];
int j = l;
for( int i = l + ; i <= r ; i ++ )
if( arr[i] < v ){
j ++;
swap( arr[j] , arr[i] );
} swap( arr[l] , arr[j]); return j;
} template <typename T>
void _quickSort(T arr[], int l, int r){ // if( l >= r )
// return;
if( r - l <= ){
insertionSort(arr,l,r);
return;
} int p = _partition(arr, l, r);
_quickSort(arr, l, p- );
_quickSort(arr, p+, r);
} template <typename T>
void quickSort(T arr[], int n){ srand(time(NULL));
_quickSort(arr, , n-);
}
快速排序优化(双路快速排序法,针对大量重复元素的数组)
之前小于 v 和大于 v 的数组放于数组的一段,优化后放于数组的两端
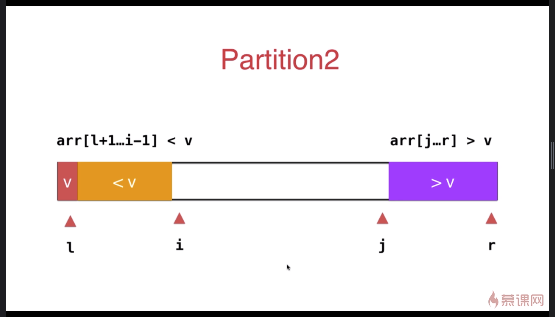
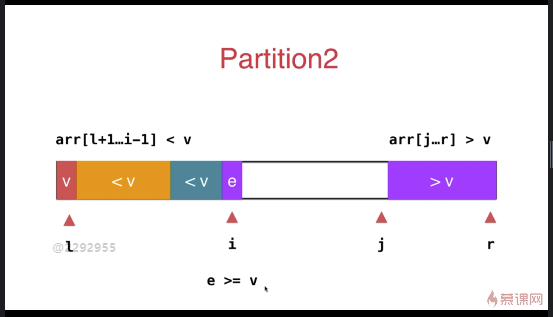
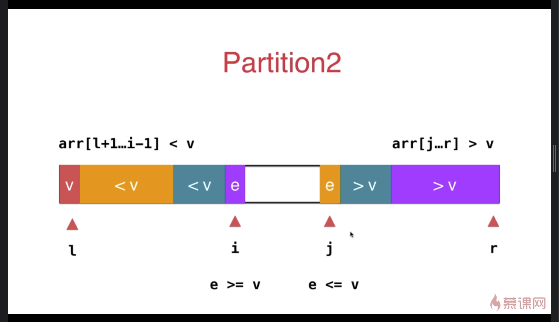
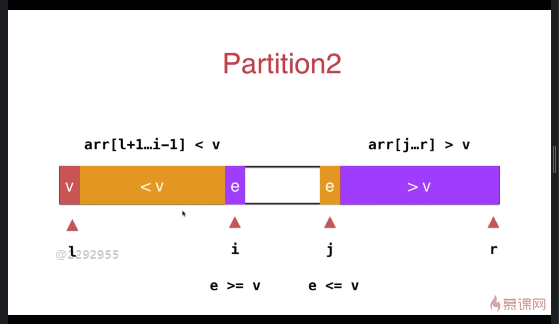
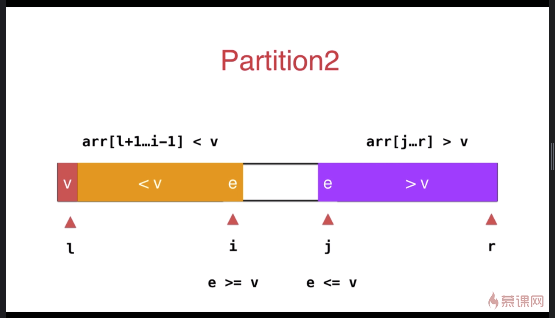
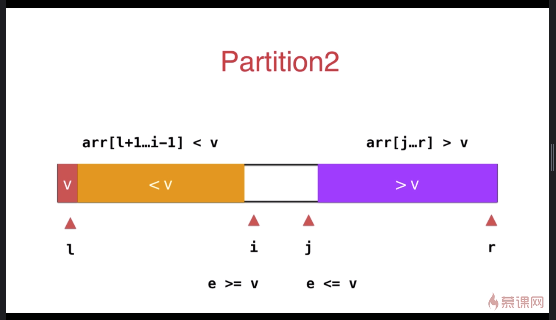
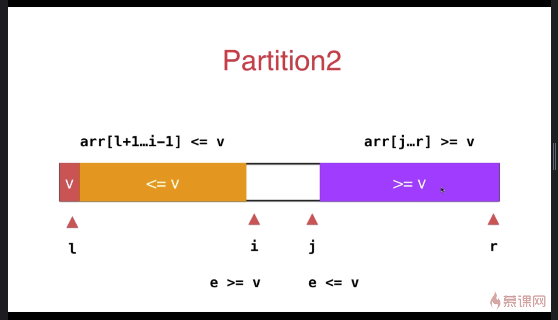
与之前的partition相比较,此方式的最大特点是将等于 v 的元素分散到两侧,不会出现大量相同元素集中在一侧的情况
template <typename T>
int _partition2(T arr[], int l, int r){ swap( arr[l] , arr[rand()%(r-l+)+l] );
T v = arr[l]; // arr[l+1...i) <= v; arr(j...r] >= v
int i = l+, j = r;
while( true ){
while( i <= r && arr[i] < v )
i ++; while( j >= l+ && arr[j] > v )
j --; if( i > j )
break; swap( arr[i] , arr[j] );
i ++;
j --;
} swap( arr[l] , arr[j]); return j;
} template <typename T>
void _quickSort(T arr[], int l, int r){ // if( l >= r )
// return;
if( r - l <= ){
insertionSort(arr,l,r);
return;
} int p = _partition2(arr, l, r);
_quickSort(arr, l, p- );
_quickSort(arr, p+, r);
}
三路快速排序
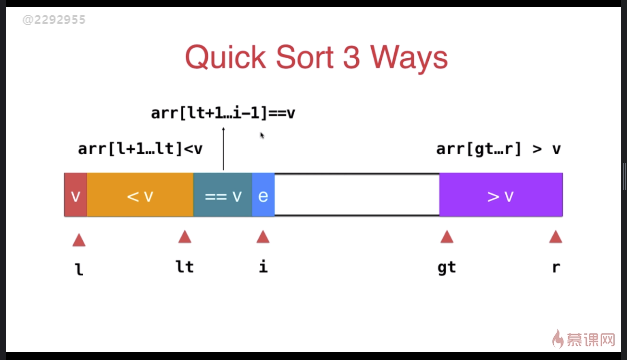
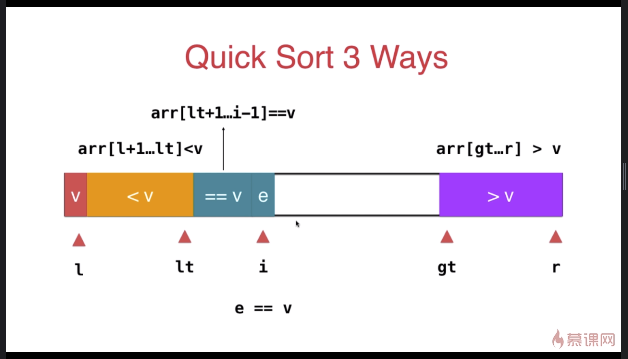
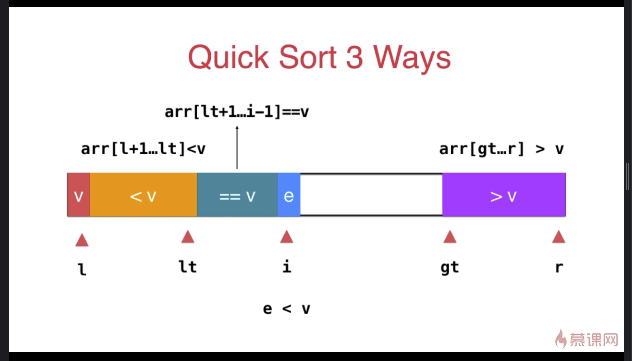
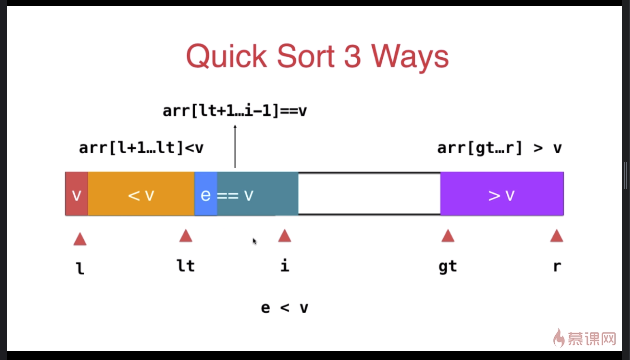
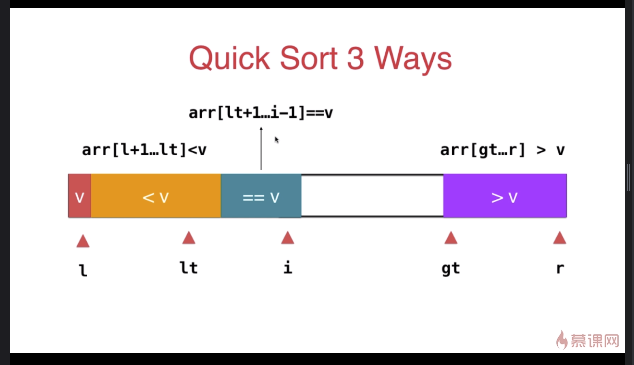
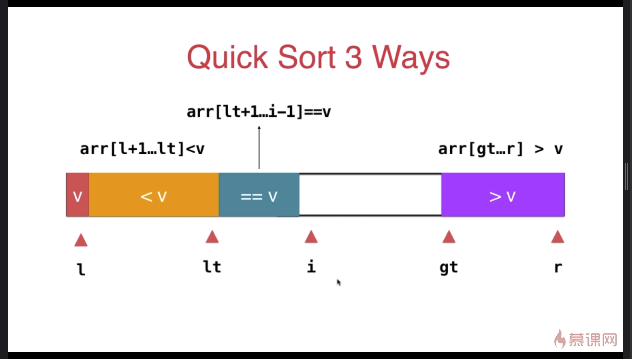
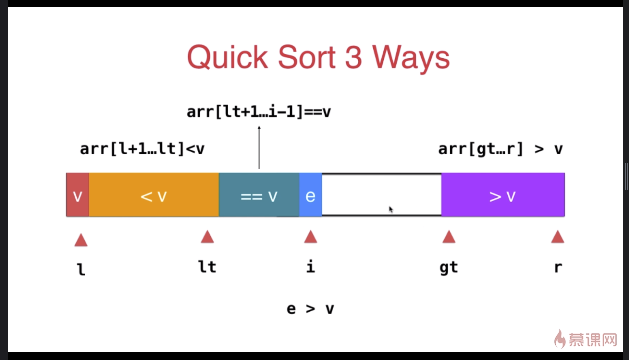
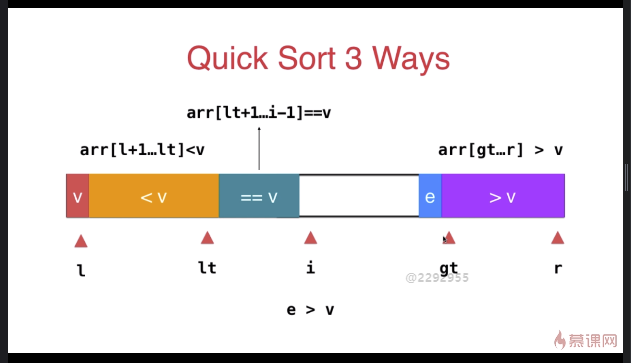
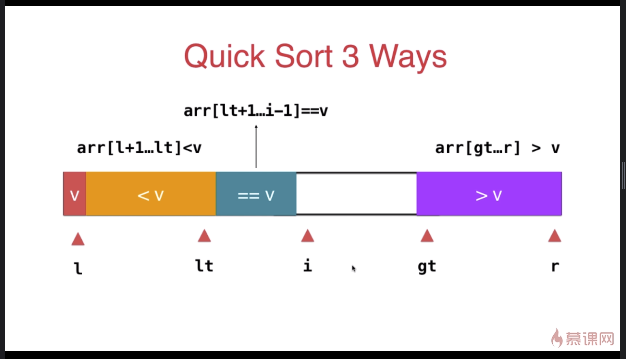
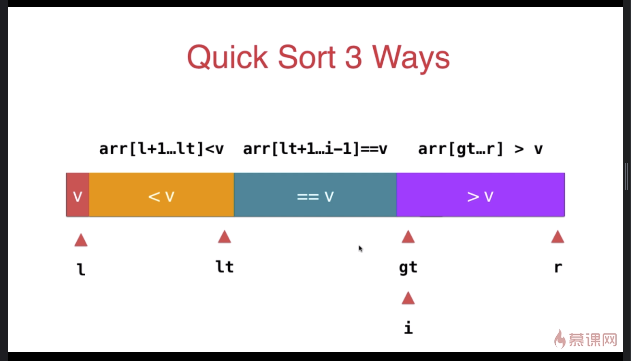
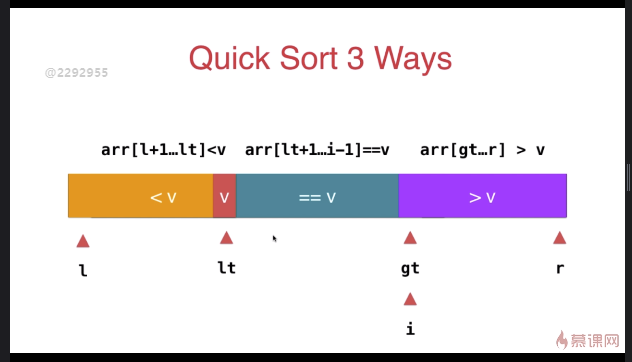
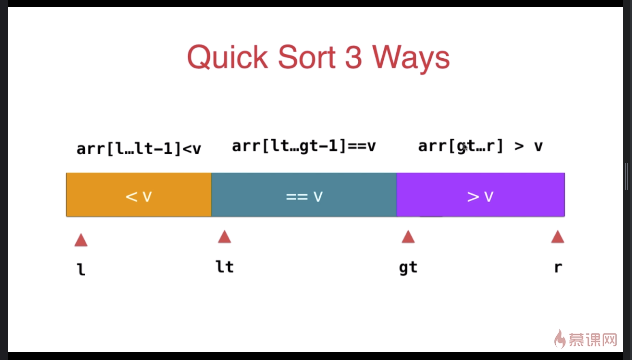
template <typename T>
void __quickSort3Ways(T arr[], int l, int r){ if( r - l <= ){
insertionSort(arr,l,r);
return;
} swap( arr[l], arr[rand()%(r-l+)+l ] ); T v = arr[l]; int lt = l; // arr[l+1...lt] < v
int gt = r + ; // arr[gt...r] > v
int i = l+; // arr[lt+1...i) == v
while( i < gt ){
if( arr[i] < v ){
swap( arr[i], arr[lt+]);
i ++;
lt ++;
}
else if( arr[i] > v ){
swap( arr[i], arr[gt-]);
gt --;
}
else{ // arr[i] == v
i ++;
}
} swap( arr[l] , arr[lt] ); __quickSort3Ways(arr, l, lt-);
__quickSort3Ways(arr, gt, r);
} template <typename T>
void quickSort3Ways(T arr[], int n){ srand(time(NULL));
__quickSort3Ways( arr, , n-);
}



算法入门及其C++实现的更多相关文章
- 【转】 SVM算法入门
课程文本分类project SVM算法入门 转自:http://www.blogjava.net/zhenandaci/category/31868.html (一)SVM的简介 支持向量机(Supp ...
- 三角函数计算,Cordic 算法入门
[-] 三角函数计算Cordic 算法入门 从二分查找法说起 减少乘法运算 消除乘法运算 三角函数计算,Cordic 算法入门 三角函数的计算是个复杂的主题,有计算机之前,人们通常通过查找三角函数表来 ...
- 循环冗余校验(CRC)算法入门引导
目录 写给嵌入式程序员的循环冗余校验CRC算法入门引导 前言 从奇偶校验说起 累加和校验 初识 CRC 算法 CRC算法的编程实现 前言 CRC校验(循环冗余校验)是数据通讯中最常采用的校验方式.在嵌 ...
- 【算法入门】广度/宽度优先搜索(BFS)
广度/宽度优先搜索(BFS) [算法入门] 1.前言 广度优先搜索(也称宽度优先搜索,缩写BFS,以下采用广度来描述)是连通图的一种遍历策略.因为它的思想是从一个顶点V0开始,辐射状地优先遍历其周围较 ...
- (转)三角函数计算,Cordic 算法入门
由于最近要使用atan2函数,但是时间上消耗比较多,因而网上搜了一下简化的算法. 原帖地址:http://blog.csdn.net/liyuanbhu/article/details/8458769 ...
- 【转】循环冗余校验(CRC)算法入门引导
原文地址:循环冗余校验(CRC)算法入门引导 参考地址:https://en.wikipedia.org/wiki/Computation_of_cyclic_redundancy_checks#Re ...
- LDA算法入门
http://blog.csdn.net/warmyellow/article/details/5454943 LDA算法入门 一. LDA算法概述: 线性判别式分析(Linear Discrimin ...
- 贝叶斯公式由浅入深大讲解—AI基础算法入门
1 贝叶斯方法 长久以来,人们对一件事情发生或不发生的概率,只有固定的0和1,即要么发生,要么不发生,从来不会去考虑某件事情发生的概率有多大,不发生的概率又是多大.而且概率虽然未知,但最起码是一个确定 ...
- 贝叶斯公式由浅入深大讲解—AI基础算法入门【转】
本文转载自:https://www.cnblogs.com/zhoulujun/p/8893393.html 1 贝叶斯方法 长久以来,人们对一件事情发生或不发生的概率,只有固定的0和1,即要么发生, ...
- 模式识别之Earley算法入门详讲
引言:刚学习模式识别时,读Earley算法有些晦涩,可能是自己太笨.看了网上各种资料,还是似懂非懂,后来明白了,是网上的前辈们境界太高,写的最基本的东西还是非常抽象,我都领悟不了,所以决定写个白痴版的 ...
随机推荐
- <a>标签中href="javascript:;"** 为什么 style不用src**
&src/href <!--href 用于标示资源和文档关系,src 用于替换标签内容--> <img src="xxx.jpg"/> <sc ...
- Vue命令(一)
Vue Command Summary 1.v-bind:元素节点的title属性和message保持一致. <div id="app-1"> <span v-b ...
- Github介绍
Git是一个分布式的版本控制系统,最初由LinusTorvalds编写,用作Linux内核代码的管理.在推出后,Git在其它项目中也取得了很大成功,尤其是在Ruby社区中.包括Rubinius和Mer ...
- Java web错误总结~
1.java程序中没有错,但是项目上面显示一个红叉的解决办法 错误信息: 报Description Resource Path Location Type Java compiler level d ...
- PAT L2-021 点赞狂魔
https://pintia.cn/problem-sets/994805046380707840/problems/994805058485469184 微博上有个“点赞”功能,你可以为你喜欢的博文 ...
- JHipster - Generate your Spring Boot + Angular/React applications!
JHipster - Generate your Spring Boot + Angular/React applications!https://www.jhipster.tech/
- 工资薪金VS劳务报酬
工资薪金所得与劳务报酬所得两个征税项目在个人所得税应纳税所得额的计算.征收标准等方面都有所不同,因而在实际操作中不可相互混淆. 工资薪金所得属于非独立个人劳务活动,即在机关.团体.学校.部队.企事业单 ...
- sort和uniq的应用实例
sort 排序 uniq 1.语法:sort [option]... [file]... 2.选项:-k key,关键子,指定以那个列来排序.如果不指定,默认将正行作为关键字排序-n 对数值排序.默认 ...
- [代码]--c#实现屏幕取词源码下载
最近公司有一个 项目需要实现类似于金山词霸,有道词典等的屏幕取词功能,准确来说是划词功能,网上搜了各种屏幕取词无外乎就两种: A.金山词霸组件法 B.Nhw32.dll法 百度搜到的重复内容真的太多了 ...
- jenkins--svn+Email自动触发1(作业设置)
项目名称设置: svn设置: 触发构建设置: 构建加入sonar-scanner代码扫描: 邮件设置: 邮件触发器配置: