机器学习 之LightGBM算法

1、基本知识点简介
- 在集成学习的Boosting提升算法中,有两大家族:第一是AdaBoost提升学习方法,另一种是GBDT梯度提升树。
- 传统的AdaBoost算法:利用前一轮迭代弱学习器的误差来更新训练集的权重,一轮轮迭代下去。
梯度提升树GBDT:也是通过迭代的算法,使用前向分布算法,但是其弱分类器限定了只能使用CART回归树模型。
- GBDT算法原理:指通过在残差减小的梯度方向建立boosting tree(提升树),即gradient boosting tree(梯度提升树)。每次建立新模型都是为了使之前模型的残差往梯度方向下降。
- XGBoost原理:XGBoost属于集成学习Boosting,是在GBDT的基础上对Boosting算法进行的改进,并加入了模型复杂度的正则项。GBDT是用模型在数据上的负梯度作为残差的近似值,从而拟合残差。XGBoost也是拟合数据残差,并用泰勒展开式(二阶泰勒展开式)对模型损失残差的近似,同时在损失函数上添加了正则化项。
lightGBM,它是微软出的新的boosting框架,基本原理与XGBoost一样,使用基于学习算法的决策树,只是在框架上做了一优化(重点在模型的训练速度的优化)。最主要的是LightGBM使用了基于直方图的决策树算法,基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
2、LightGBM轻量级提升学习方法
- LightGBM原理和XGBoost类似,通过损失函数的泰勒展开式近似表达残差(包含了一阶和二阶导数信息),另外利用正则化项控制模型的复杂度。但是LightGBM最大的特点是,
- 通过使用leaf-wise分裂策略代替XGBoost的level-wise分裂策略,通过只选择分裂增益最大的结点进行分裂,避免了某些结点增益较小带来的开销。
- 另外LightGBM通过使用基于直方图的决策树算法,只保存特征离散化之后的值,代替XGBoost使用exact算法中使用的预排序算法(预排序算法既要保存原始特征的值,也要保存这个值所处的顺序索引),减少了内存的使用,并加速的模型的训练速度。
2.1 leaf-wise分裂策略
(1)XGBoost的level-wise分类策略
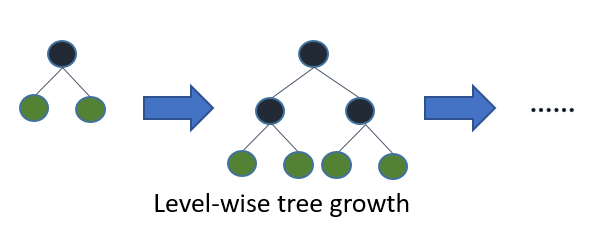
level-wise是指对每一层所有结点做无差别分裂,尽管部分结点的增益比较小,依然会进行分裂,带来了没必要的开销。
(2)LightGBM的leaf-wise分裂策略
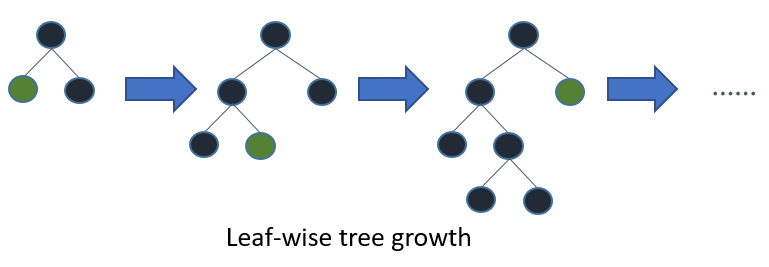
leaf-wise是指在当前所有叶子结点中选择分类增益最大的结点进行分裂,并进行最大深度限制,避免过拟合。
二叉树的分裂增益公式为:
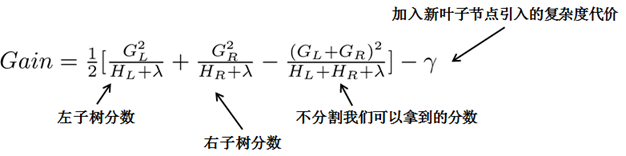
其中\(\frac{1}{2} [\frac{G_{L}^{2}}{H_{L} + \lambda} + \frac{G_{R}^{2}}{H_{R} + \lambda} - \frac{(G_{L}+G_{R})^{2}}{H_{L} + H_{R} + \lambda}]\)是指不考虑其他因素,通过分裂得到的增益,但实际上每次引入新叶子结点,都会带来复杂度的代价,即\(\gamma\)。
\(G_{j} = \sum_{i \in I_{j}} g_{i}, i=1,2,...,n; j=1,2,..,T\),\(H_{j} = \sum_{i \in I_{j}} h_{i}, i=1,2,...,n; j=1,2,..,T\)
这里\(G_{j}\)为该叶子结点上面样本集合中数据点在误差函数上的一阶导数和二阶导数。
2.2 基于直方图的排序算法
直方图算法基本实现:是指先把连续的浮点特征值离散化成 k 个整数,同时构造一个宽度为 k 的直方图。在遍历数据的时候,根据离散化后的值作为是索引,在直方图中累积统计量,然后根据直方图的离散值,遍历寻找最优的分割点。在XGBoost中需要遍历所有离散化的值,而LightGBM通过建立直方图只需要遍历 k 个直方图的值。
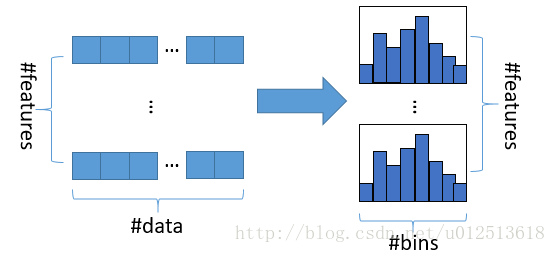
- 使用直方图的优点:
- 明显减少内存的使用,因为直方图不需要额外存储预排序的结果,而且可以只保存特征离散化后的值。
- 遍历特征值时,不需要像XGBoost一样需要计算每次分裂的增益,而是对每个特征只需要计算建立直方图的个数,即k次,时间复杂度由O(#data * #feature)优化到O(k * #feature)。(由于决策树本身是弱分类器,分割点是否精确并不是太重要,因此直方图算法离散化的分割点对最终的精度影响并不大。另外直方图由于取的是较粗略的分割点,因此不至于过度拟合,起到了正则化的效果)
- LightGBM的直方图能做差加速。一个叶子的直方图可以由它的父亲结点的直方图与它兄弟的直方图做差得到。构造的直方图本来需要遍历该叶子结点上所有数据,但是直方图做差仅需遍历直方图的k个桶即可(即直方图区间),速度上可以提升一倍。如下图:

2.3 支持类别特征和高效并行处理
- 直接支持类别特征,不需要做one-hot编码。大多数机器学习都无法直接支持类别特征,一般需要把类别进行特征编码,这样就降低了空间和时间的效率。但是LightGBM可以在对离散特征分裂时,每个取值都当作一个桶,分裂时的增益为“是否属于某个类别category”的gain。
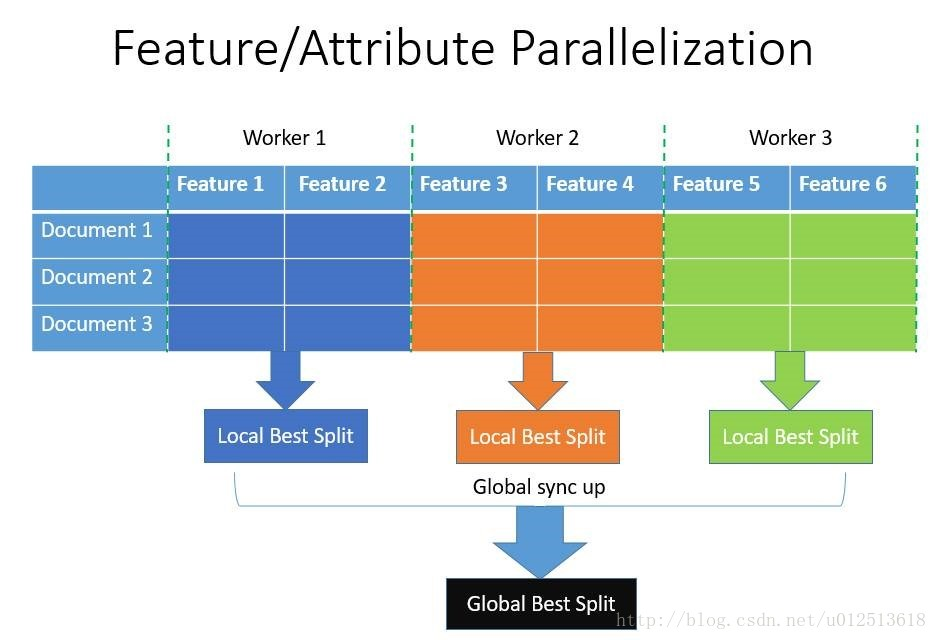
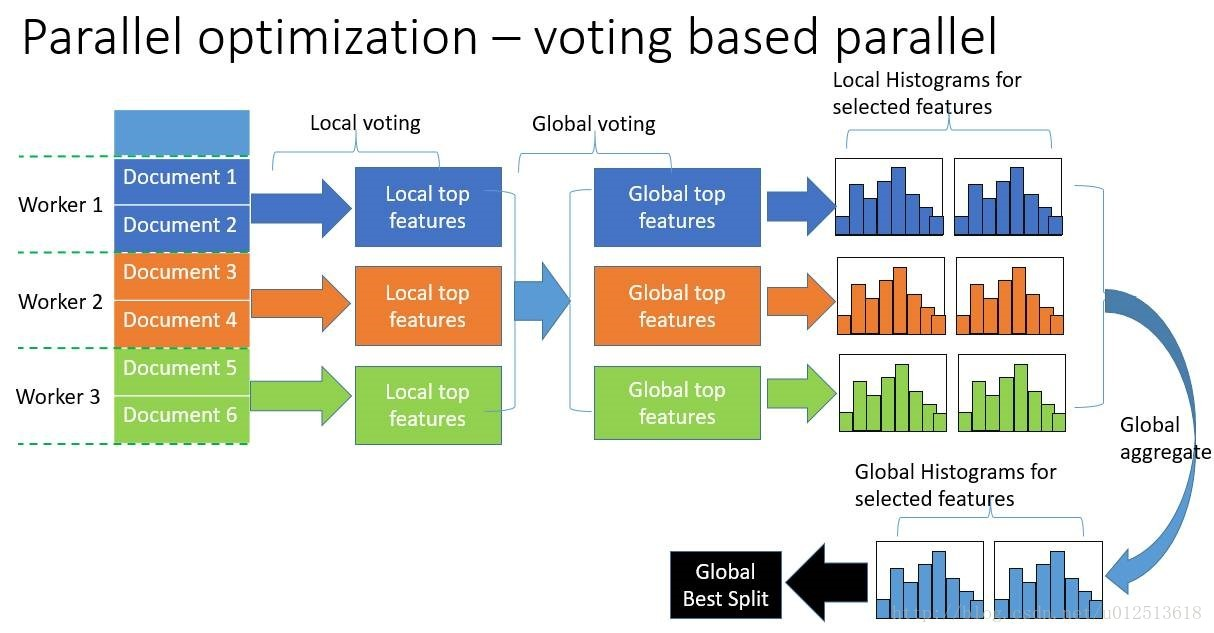
- 支持高效并行:包括特征并行和数据并行。(减少的是分割数据的时间,而不是模型训练的时间)
- 特征并行:即在不同机器上在不同的特征集上分别寻找最优的分割点,然后在机器间同步最优的分割点。其通过本地保存全部数据避免对数据切分结果的通信。
- 数据并行:即让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。其使用分散规约(Reduce scatter)把直方图合并的任务分摊到不同的机器上,降低了通信量,并利用直方图做差,减少了通信量,即减少了通信时间。
参考:
1、LightGBM官方文档:https://lightgbm.readthedocs.io/en/latest/Features.html
2、LightGBM图形理解:https://www.cnblogs.com/jiangxinyang/p/9337094.html
机器学习 之LightGBM算法的更多相关文章
- 【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码
在上一篇文章:机器学习之PageRank算法应用与C#实现(1)算法介绍 中,对PageRank算法的原理和过程进行了详细的介绍,并通过一个很简单的例子对过程进行了讲解.从上一篇文章可以很快的了解Pa ...
- 【原创】机器学习之PageRank算法应用与C#实现(1)算法介绍
考虑到知识的复杂性,连续性,将本算法及应用分为3篇文章,请关注,将在本月逐步发表. 1.机器学习之PageRank算法应用与C#实现(1)算法介绍 2.机器学习之PageRank算法应用与C#实现(2 ...
- 机器学习十大算法之KNN(K最近邻,k-NearestNeighbor)算法
机器学习十大算法之KNN算法 前段时间一直在搞tkinter,机器学习荒废了一阵子.如今想重新写一个,发现遇到不少问题,不过最终还是解决了.希望与大家共同进步. 闲话少说,进入正题. KNN算法也称最 ...
- 机器学习中的算法-决策树模型组合之随机森林与GBDT
机器学习中的算法(1)-决策树模型组合之随机森林与GBDT 版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使 ...
- 机器学习十大算法 之 kNN(一)
机器学习十大算法 之 kNN(一) 最近在学习机器学习领域的十大经典算法,先从kNN开始吧. 简介 kNN是一种有监督学习方法,它的思想很简单,对于一个未分类的样本来说,通过距离它最近的k个" ...
- 【转载】NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩、机器学习及最优化算法
原文:NeurIPS 2018 | 腾讯AI Lab详解3大热点:模型压缩.机器学习及最优化算法 导读 AI领域顶会NeurIPS正在加拿大蒙特利尔举办.本文针对实验室关注的几个研究热点,模型压缩.自 ...
- 机器学习&深度学习基础(机器学习基础的算法概述及代码)
参考:机器学习&深度学习算法及代码实现 Python3机器学习 传统机器学习算法 决策树.K邻近算法.支持向量机.朴素贝叶斯.神经网络.Logistic回归算法,聚类等. 一.机器学习算法及代 ...
- 机器学习中的算法(2)-支持向量机(SVM)基础
版权声明:本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gma ...
- 【机器学习】EM算法详细推导和讲解
今天不太想学习,炒个冷饭,讲讲机器学习十大算法里有名的EM算法,文章里面有些个人理解,如有错漏,还请读者不吝赐教. 众所周知,极大似然估计是一种应用很广泛的参数估计方法.例如我手头有一些东北人的身高的 ...
随机推荐
- axios库的使用
axios是基于Promise 用于浏览器和 nodejs 的 HTTP 客户端:可以用在webpack + vuejs 的项目中 原文 https://github.com/axios/axios ...
- P5280 [ZJOI2019]线段树
题目链接:洛谷 题目描述:[比较复杂,建议看原题] 这道题太神仙了,线段树上做树形dp. 根据树形dp的套路,都是按照转移的不同情况给节点分类.这里每次modify的时候对于节点的影响也不同,所以我们 ...
- python之wtforms组件
作用 生成 HTML 表单. form 表单验证. 基本使用 安装 pip3 install wtforms 示例 登录 from flask import Flask, render_templat ...
- Vue.js使用Leaflet地图
参考:https://blog.csdn.net/Joshua_HIT/article/details/72860171 vue2leaflet的demo:https://github.com/KoR ...
- js阻止表单默认提交、刷新页面
一.阻止刷新页面 在表单中的提交按钮<button></button>标签改为<input type="button">或者在<butto ...
- div “下沉”
最近在做一个计算器,按键整体布局如下: Div2,div3 display属性设置为inline-block.三个div “容器”没添加任何元素时,布局是符合预想的.添加上按键后,布局变成下面这样了: ...
- winfrom进程、线程、用户控件
一.进程 一个进程就是一个程序,利用进程可以在一个程序中打开另一个程序. 1.开启某个进程Process.Start("文件缩写名"); 注意:Process要解析命名空间. 2. ...
- 记录:工作中用到的Js日期时间方法
/** * 获取当前时间 */ function getDate() { return new Date(); } /** * 格式化当前时间 * @param {*} value */ functi ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- iOS项目之获取WebView的高度
获取高度值的方法: - (void)webViewDidFinishLoad:(UIWebView *)webView { // 获取webView的高度 CGFloat webViewHeight ...