Lucene全文检索入门使用
一、 什么是全文检索
全文检索是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置。当用户查询时根据建立的索引查找,类似于通过字典的检索字表查字的过程
全文检索(Full-Text Retrieval)以文本作为检索对象,找出含有指定词汇的文本。全面、准确和快速是衡量全文检索系统的关键指标。
关于全文检索,我们要知道:
1、只处理文本。
2,不处理语义。
3,搜索时英文不区分大小写。
4,结果列表有相关度排序。
二、 全文检索与数据库检索的区别
全文检索不同于数据库的SQL查询。(他们所解决的问题不一样,解决的方案也不一样,所以不应进行对比)。在数据库中的搜索就是使用SQL,如:SELECT * FROM t WHERE content like ‘%ant%’。这样会有如下问题:
1、匹配效果:如搜索ant会搜索出planting。这样就会搜出很多无关的信息。
2、相关度排序:查出的结果没有相关度排序,不知道我想要的结果在哪一页。我们在使用百度搜索时,一般不需要翻页,为什么?因为百度做了相关度排序:为每一条结果打一个分数,这条结果越符合搜索条件,得分就越高,叫做相关度得分,结果列表会按照这个分数由高到低排列,所以第1页的结果就是我们最想要的结果。
3、全文检索的速度大大快于SQL的like搜索的速度。这是因为查询方式不同造成的,以查字典举例:数据库的like就是一页一页的翻,一行一行的找,而全文检索是先查目录,得到结果所在的页码,再直接翻到这一页。
三、 全文检索的使用场景
我们使用Lucene,主要是做站内搜索,即对一个系统内的资源进行搜索。如BBS论坛、BLOG(博客)中的文章搜索,网上商店中的商品搜索等。使用Lucene的项目有Eclipse,智联招聘,天猫,京东等。一般不做互联网中资源的搜索,因为不易获取与管理海量资源(专业搜索方向的公司除外)
入门使用
Java环境下
导入Lucene核心jar包
<!--lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>4.4.0</version>
</dependency>
<!--lucene-analyzers-common分词器相关 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.4.0</version>
</dependency>
<!-- ikanalyzer分词器 -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
<!-- lucene-queryparser使用MultiFieldQueryParser必须导入 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>4.4.0</version>
</dependency>
<!-- lucene-highlighter 高亮依赖-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>4.4.0</version>
</dependency>
创建索引库
public class TestCreateIndex {
public static void main(String[] args) throws IOException {
//构建索引库
Directory dir = FSDirectory.open(new File("F:/index"));
//索引写入相关配置 args:version,分词器
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_44);
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_44,analyzer);
//索引写入器
IndexWriter indexWriter = new IndexWriter(dir,config);
//为文本创建document
Document document = new Document();
//StringField---DoubleField....
document.add(new StringField("id","1",Field.Store.YES));
document.add(new StringField("title","带秀TV",Field.Store.YES)); //YES,数据在元数据区也存在
document.add(new StringField("author","张肖",Field.Store.YES));
document.add(new TextField("content","今晚,是我最开心,也最难过的晚上。开心是因为小梅,难过也是!",Field.Store.YES));
document.add(new StringField("date","2019-1-2",Field.Store.YES));
indexWriter.addDocument(document);
indexWriter.commit();
indexWriter.close();
}
}
此时,就在对象目录下建立了这一篇文章的索引库。
创建搜索索引
public class TestCreateSearch {
public static void main(String[] args) throws IOException {
//索引读入流
Directory directory = FSDirectory.open(new File("D:/index"));
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(reader);
//参数1:搜索条件 Query抽象类,参数2:查询的条数
Query query = new TermQuery(new Term("author", "张")); //词查询,BooleanQuery、 Term参数:field指定索引属性,keyword
TopDocs topDocs = indexSearcher.search(query, 100); //相关度排序
/* TopDocs属性
public int totalHits;
public ScoreDoc[] scoreDocs;
private float maxScore;
*/
ScoreDoc[] scoreDocs = topDocs.scoreDocs; //scoreDocs属性返回数组,相关度排序doc数组
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc; //其中一个拿到的doc的索引编号,该编号由文档进入索引库时生成
Document document = indexSearcher.doc(doc);
System.out.println(scoreDoc.score);
System.out.println(document.get("id"));
System.out.println(document.get("title"));
System.out.println(document.get("content"));
System.out.println(document.get("date"));
}
}
}
注意:8中基本类型+String不分词,text类型分词,当使用StandardAnalyzer分词器,默认每一个词分词,如,你,我,这,....全部被拆分称为单个词建立索引,所以测试搜索时只能以单个字查询,后面会解决这个问题。
四、Lucene的创建索引以及搜索的原理
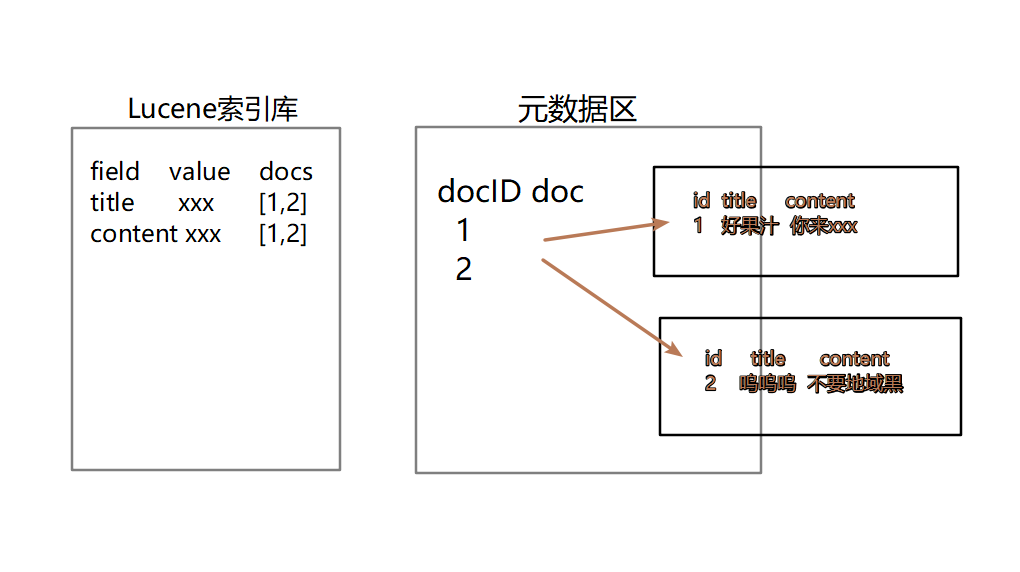
五、 Lucene的增删改查
封装工具类
public class LuceneUtil {
private static Directory directory;
private static final Version version = Version.LUCENE_44;
private static Analyzer analyzer;
private static IndexWriterConfig indexWriterConfig;
static {
try {
//version = Version.LUCENE_44;
analyzer = new IKAnalyzer();
directory = FSDirectory.open(new File("F:/index"));
indexWriterConfig = new IndexWriterConfig(version, analyzer);
} catch (IOException e) {
e.printStackTrace();
}
}
public static IndexWriter getIndexWriter() {
IndexWriter indexWriter = null;
try {
indexWriter = new IndexWriter(directory, indexWriterConfig);
} catch (IOException e) {
e.printStackTrace();
}
return indexWriter;
}
public static IndexSearcher getIndexSearcher() {
IndexSearcher indexSearcher = null;
try {
IndexReader reader = DirectoryReader.open(directory);
indexSearcher = new IndexSearcher(reader);
} catch (IOException e) {
e.printStackTrace();
}
return indexSearcher;
}
public static void commit(IndexWriter indexWriter) {
try {
indexWriter.commit();
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void rollback(IndexWriter indexWriter) {
try {
indexWriter.rollback();
indexWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
增删改查测试
public class TestIndexCreateAndSearch {
@Test
public void testCreateIndex() {
IndexWriter indexWriter = LuceneUtil.getIndexWriter();
try {
for (int i = 0; i < 10; i++) {
Document document = new Document();
document.add(new IntField("id",i, Field.Store.YES));
document.add(new StringField("title", "带秀TV四大门派围攻光明顶", Field.Store.YES));
document.add(new TextField("content", "今晚,是我最开心,也最难过的晚上。开心是因为小梅,难过也是", Field.Store.YES));
document.add(new StringField("date", "2019-1-2", Field.Store.YES));
indexWriter.addDocument(document);
}
} catch (IOException e) {
e.printStackTrace();
LuceneUtil.rollback(indexWriter);
}
LuceneUtil.commit(indexWriter);
}
@Test
public void testSearchIndex() {
IndexSearcher indexSearcher = LuceneUtil.getIndexSearcher();
try {
TopDocs topDocs = indexSearcher.search(new TermQuery(new Term("content", "我")), 100);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (int i = 0; i < scoreDocs.length; i++) {
ScoreDoc scoreDoc = scoreDocs[i];
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
System.out.println("this is 分数======>" + scoreDoc.score);
System.out.println("this is 编号======>" + document.get("id"));
System.out.println("this is 标题======>" + document.get("title"));
System.out.println("this is 内容======>" + document.get("content"));
System.out.println("this is 日期======>" + document.get("date"));
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~");
}
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testDelete() {
IndexWriter indexWriter = LuceneUtil.getIndexWriter();
//indexWriter.deleteAll(); //删除所有
try {
indexWriter.deleteDocuments(new Term("id", "0"));
LuceneUtil.commit(indexWriter);
} catch (IOException e) {
e.printStackTrace();
LuceneUtil.rollback(indexWriter);
}
}
//修改 是先删除再添加
@Test
public void testUpdate() {
IndexWriter indexWriter = LuceneUtil.getIndexWriter();
Document document = new Document();
document.add(new StringField("id", String.valueOf(0), Field.Store.YES));
document.add(new StringField("title", "瘸子", Field.Store.YES));
document.add(new TextField("content", "与队长的博弈第二季", Field.Store.YES));
document.add(new StringField("date", "2019-1-2", Field.Store.YES));
try {
indexWriter.updateDocument(new Term("id", "1"), document);
LuceneUtil.commit(indexWriter);
} catch (IOException e) {
e.printStackTrace();
LuceneUtil.rollback(indexWriter);
}
}
}
六、Lucene的分词器
a) 分词器作用
Analyzer分词器的作用是把一段文本中的词按照一定的规则取出所包含的所有词,对应的类为 “Analyzer”,这是一个抽象类,切分词的具体规则由子类实现,因此不同的语言,需要使用不同的分词器
b) 切分词原理
我是中国人---切分后:中国,中国人
切分关键词
去除停用词
对于英文要把所用字母转化为大/小写搜索,不区分大小写
有的分词器还对英文进行了形态还原,就是去除单词词尾的形态变化,将其还原为词的原型,这样可以搜索出更有意义的结果 如: 搜索student时,出现students,也是很有意义的.
注意:
**如果是同一种语言数据,在创建索引,以及搜索时,一定要使用同一个分词器,否则可能会搜索不到结果**
测试分词器
分词器有很多,StandardAnalyzer,ChineseAnalyzer都不适用,直接测试IKAnalyzer分词器,引入停词词典与扩展词典;
停词词典:那些词不建立索引,在词典内写出
扩展词典:那些特殊的话需要保留
配置文件引入:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
测试程序
public class TestAnalyzer {
String text = "今晚,是我最开心,也最难过的晚上。开心是因为小梅,难过也是";
@Test
public void testIKanalyzer() { //IK可以自定义停词,关键词
test(new IKAnalyzer(), text);
//ChineseAnalyzer,StandardAnalyzer SmartCn 不再使用
}
public void test(Analyzer analyzer, String text) {
System.out.println("当前分词器:--->" + analyzer.getClass().getName());
try {
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(text));
tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while (tokenStream.incrementToken()) {
CharTermAttribute attribute = tokenStream.getAttribute(CharTermAttribute.class);
System.out.println(attribute.toString());
}
tokenStream.end();
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果:
当前分词器:--->org.wltea.analyzer.lucene.IKAnalyzer
加载扩展词典:ext.dic
加载扩展停止词典:stopword.dic
今晚
是
我
最
开心
也
最难
难过
的
晚上
开心
是因为
因为
小
梅
难过
也是
七、Lucene的全文检索的得分/热度
相关度得分是在查询时根据查询条件实进计算出来的,如果索引库据不变,查询条件不变,查出的文档得分也不变
这个相关度的得分我们是可以手动的干预的:
TextField field = new TextField("content","xxxxxx",Store.YES);
field.setBootst(10f); //参数类型float
八、索引库优化
一、Lucene4.0后自动优化
二、排除停用词,被分词器过滤掉,建立索引时,就不会创建停用词,减少索引的大小
三、索引分区存放
四、索引放在内容中
psvm{
FSDirectory dir = FSDirectory.open(new File("D:/index"));
IOContext context = new IOContext();
Directory dir2 = new RAMDirectory(dir,context);
}
九、查询扩展
使用不同的查询器得到的结果就不同,常用的查询器有TermQuery,MultiFieldQueryParser,MatchAllDocsQuery,NumericRangeQuery....
测试程序对查询结果分页,查询关键词高亮显示
public class TestQuery {
@Test
public void termQuery(){
testQuery(new TermQuery(new Term("content","要饭")));
}
//多属性查询 使用MultiFieldQueryParser:1.分词器一致 2.导入jar包
@Test
public void testMultiParser() throws ParseException {
String[] field = {"title","brief"};
IKAnalyzer analyzer = new IKAnalyzer();
MultiFieldQueryParser multiFieldQueryParser = new MultiFieldQueryParser(Version.LUCENE_44,field,analyzer);
testQuery(multiFieldQueryParser.parse("今"));
}
//查询所有文档 --使用场景少
@Test
public void testMacthAll(){
MatchAllDocsQuery matchAllDocsQuery = new MatchAllDocsQuery();
testQuery(matchAllDocsQuery);
}
// 区间查找
@Test
public void testNumericRangeQuery(){
NumericRangeQuery<Integer> query = NumericRangeQuery.newIntRange("id", 5, 7, true, true);
testQuery(query);
}
//匹配查找
@Test
public void testWildQuery(){
WildcardQuery query = new WildcardQuery(new Term("content", "北?"));
testQuery(query);
}
//模糊查询
@Test
public void testFuzzQuery(){
FuzzyQuery fuzzyQuery = new FuzzyQuery(new Term("content", "白京"));
testQuery(fuzzyQuery);
}
//布尔查询
@Test
public void testBooleanQuery(){
BooleanQuery booleanClauses = new BooleanQuery();
NumericRangeQuery<Integer> query = NumericRangeQuery.newIntRange("id", 1, 7, true, true);
NumericRangeQuery<Integer> query2 = NumericRangeQuery.newIntRange("id", 3, 5, true, true);
booleanClauses.add(query,BooleanClause.Occur.MUST);
booleanClauses.add(query2,BooleanClause.Occur.SHOULD);
testQuery(booleanClauses);
}
public void testQuery(Query query){
//查询结果分页
int pageNum = 1;
int pageSize = 3;
Formatter formatter = new SimpleHTMLFormatter("<font color='red'>","</font>");
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter, scorer);
//索引读入流
IndexSearcher indexSearcher = LuceneUtil.getIndexSearcher();
try {
TopDocs topDocs = indexSearcher.search(query, pageNum*pageSize); //相关度排序
ScoreDoc[] scoreDocs = topDocs.scoreDocs; //scoreDocs属性返回数组,相关度排序doc数组
for (int i = (pageNum-1)*pageSize; i < scoreDocs.length; i++) {
ScoreDoc scoreDoc = scoreDocs[i];
int doc = scoreDoc.doc; //其中一个拿到的doc的索引编号,该编号由文档进入索引库时生成
Document document = indexSearcher.doc(doc);
System.out.println("this is 分数======>" + scoreDoc.score);
System.out.println("this is 编号======>" + document.get("id"));
System.out.println("this is 标题======>" + document.get("title"));
System.out.println("this is 内容======>" + document.get("brief"));
System.out.println("this is 日期======>" + document.get("date"));
System.out.println("~~~~~~~~~~~~~~~~after highlight~~~~~~~~~~~~~~~~~~~~~~~~~~");
try {//高亮区域
//当前查询的关键词 id属性中不存在导致空
String bestFragment = highlighter.getBestFragment(new IKAnalyzer(), "id", document.get("id"));
if(bestFragment == null){
System.out.println("this is 编号======>" + document.get("id"));
}else{
System.out.println("this is 编号======>" + bestFragment);
}
System.out.println("this is 内容======>" + highlighter.getBestFragment(new IKAnalyzer(),"content",document.get("content")));
} catch (InvalidTokenOffsetsException e) {
e.printStackTrace();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
高亮原理:对查找的关键词使用font标签包围
Formatter formatter = new SimpleHTMLFormatter("<font color='red'>","</font>");
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter, scorer);
Lucene全文检索入门使用的更多相关文章
- Lucene 全文检索入门
博客地址:http://www.moonxy.com 一.前言 Lucene 是 apache 软件基金会的一个子项目,由 Doug Cutting 开发,是一个开放源代码的全文检索引擎工具包,但它不 ...
- Lucene.net入门学习
Lucene.net入门学习(结合盘古分词) Lucene简介 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全 ...
- Lucene.net入门学习系列(2)
Lucene.net入门学习系列(2) Lucene.net入门学习系列(1)-分词 Lucene.net入门学习系列(2)-创建索引 Lucene.net入门学习系列(3)-全文检索 在使用Luce ...
- Lucene.net入门学习系列(1)
Lucene.net入门学习系列(1) Lucene.net入门学习系列(1)-分词 Lucene.net入门学习系列(2)-创建索引 Lucene.net入门学习系列(3)-全文检索 这几天在公 ...
- 1.搜索引擎的历史,搜索引擎起步,发展,繁荣,搜索引擎的原理,搜索技术用途,信息检索过程,倒排索引,什么是Lucene,Lucene快速入门
一: 1 搜索引擎的历史 萌芽:Archie.Gopher Archie:搜索FTP服务器上的文件 Gopher:索引网页 2 起步:Robot(网络机器人)的出现与spider(网络爬虫) ...
- Lucene 02 - Lucene的入门程序(Java API的简单使用)
目录 1 准备环境 2 准备数据 3 创建工程 3.1 创建Maven Project(打包方式选jar即可) 3.2 配置pom.xml, 导入依赖 4 编写基础代码 4.1 编写图书POJO 4. ...
- Lucene全文检索_分词_复杂搜索_中文分词器
1 Lucene简介 Lucene是apache下的一个开源的全文检索引擎工具包. 1.1 全文检索(Full-text Search) 1.1.1 定义 全文检索就是先分词创建索引,再执行搜索的过 ...
- Lucene 全文检索
基于 lucene 8 1 Lucene简介 Lucene是apache下的一个开源的全文检索引擎工具包. 1.1 全文检索(Full-text Search) 全文检索就是先分词创建索引,再执行搜索 ...
- Lucene搜索引擎入门
一.什么是全文检索? 就是在检索数据,数据的分类: 在计算机当中,比如说存在磁盘的文本文档,HTML页面,Word文档等等...... ...
随机推荐
- UIScrollView上面的UIButton点击始终在中间
-(void)btnClick:(IdleTopChoseBtn *)btn{ btn.selected = YES; _choseBtn.selected = NO; _choseBtn = btn ...
- MySQL的分区、分表、集群
1.分区 mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表结构的,一 ...
- cocos2d-x JS 定时器暂停方法
this.scheduleOnce(function(){ this.addChild(Menugobtn);//要暂停执行的代码 }, 10);
- reactjs中使用高德地图计算两个经纬度之间的距离
第一步下载依赖 npm install --save react-amap 第二步,在组件中使用 import React, { Component } from 'react' import { L ...
- 《linux就该这么学》第七节课:文件的各种权限以及linux分区命名规则
笔记 (借鉴请改动) 5.3:文件特殊权限 SUID 临时拥有文件所有者的权限(基本上只是执行权限) SGID 临时拥有文件所有组的权限,在目录中创建文件自动继承该目录的用户组. SBIT 粘滞 ...
- manjaro使用国内软件源
虽然manjaro是基于arch修改的,但毕竟还是有些改动,如果可以用manjaro仓库里的,尽量不要用arch的源.如果嫌官方的软件源慢,可以直接一条命令修改成国内的软件源 sudo pacman- ...
- DX9 DirectX 索引缓存(IndexBuffer) 代码
// @time: 2012.3.22 // @author: jadeshu // des: 索引缓存 //包含头文件 #include <Windows.h> #include < ...
- redis解决高并发下脏读问题
//解决并发情况下卡脏读的问题 protected function BingFa($mobile, $ent_id){ $obj = EnterpriseMembers::getNewMemberC ...
- 【Spark-core学习之六】 Spark资源调度和任务调度
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- Java代码走查具体考察点
代码走查具体考察点 一.参数检验 公共方法都要做参数的校验,参数校验不通过,需要明确抛出异常或对应响应码. 在接口中也明确使用验证注解修饰参数和返回值,作为一种协议要求调用方按注解约束传参,返回值验证 ...