Python爬虫——你们要的王者荣耀高清图
曾经144区的王者
学了计算机后
头发逐渐从李白变成了达摩
秀发有何用,变秃亦变强
(emmm徒弟说李白比达摩强,变秃不一定变强)
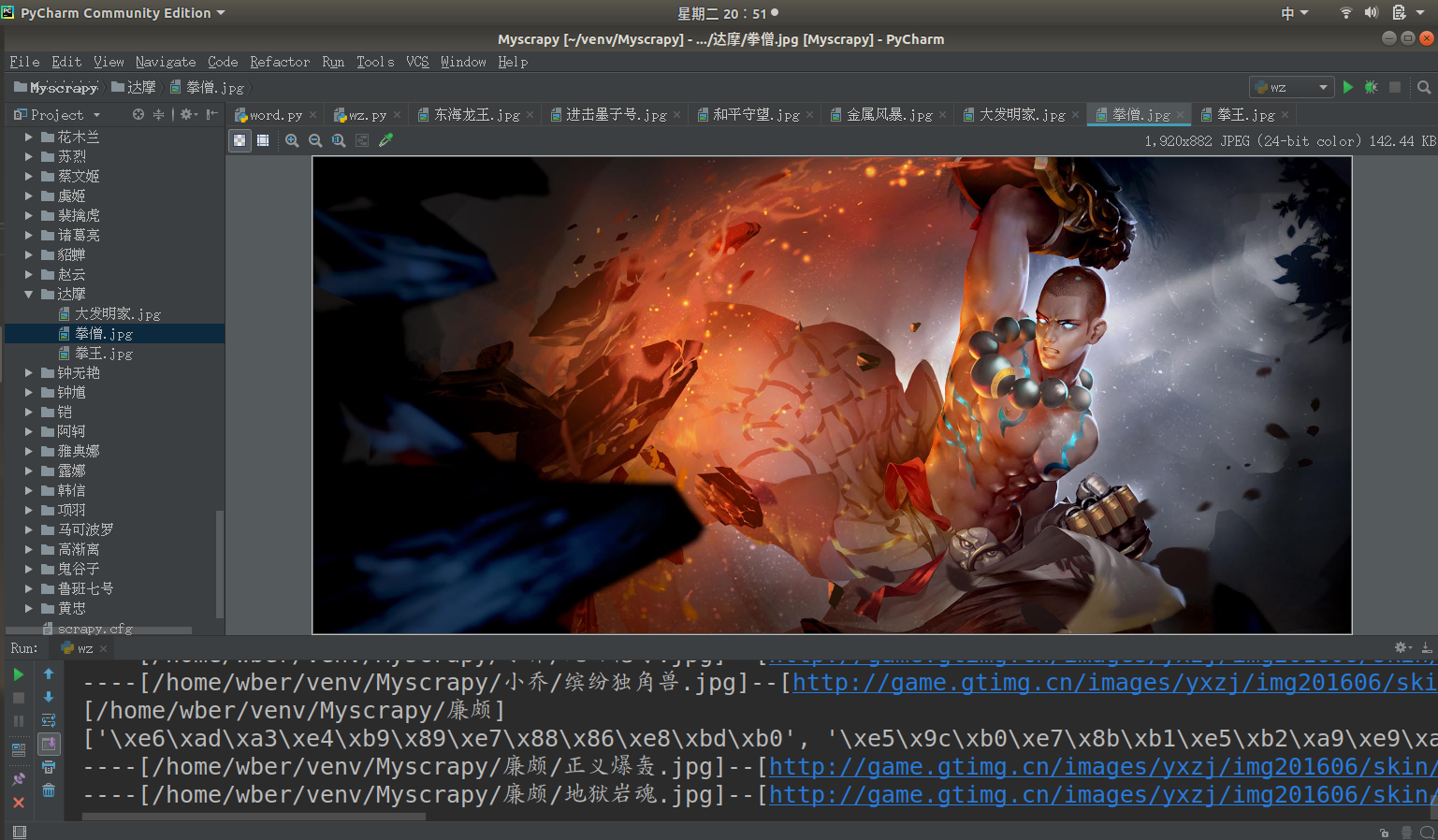
前言
前几天开了农药的安装包,发现农药是.Net实现的游戏
虽然游戏用的语言和排位一样让人恼火
但感觉图片美工还是可以的
比如:
不知...不知道你们是不是和我一样喜欢
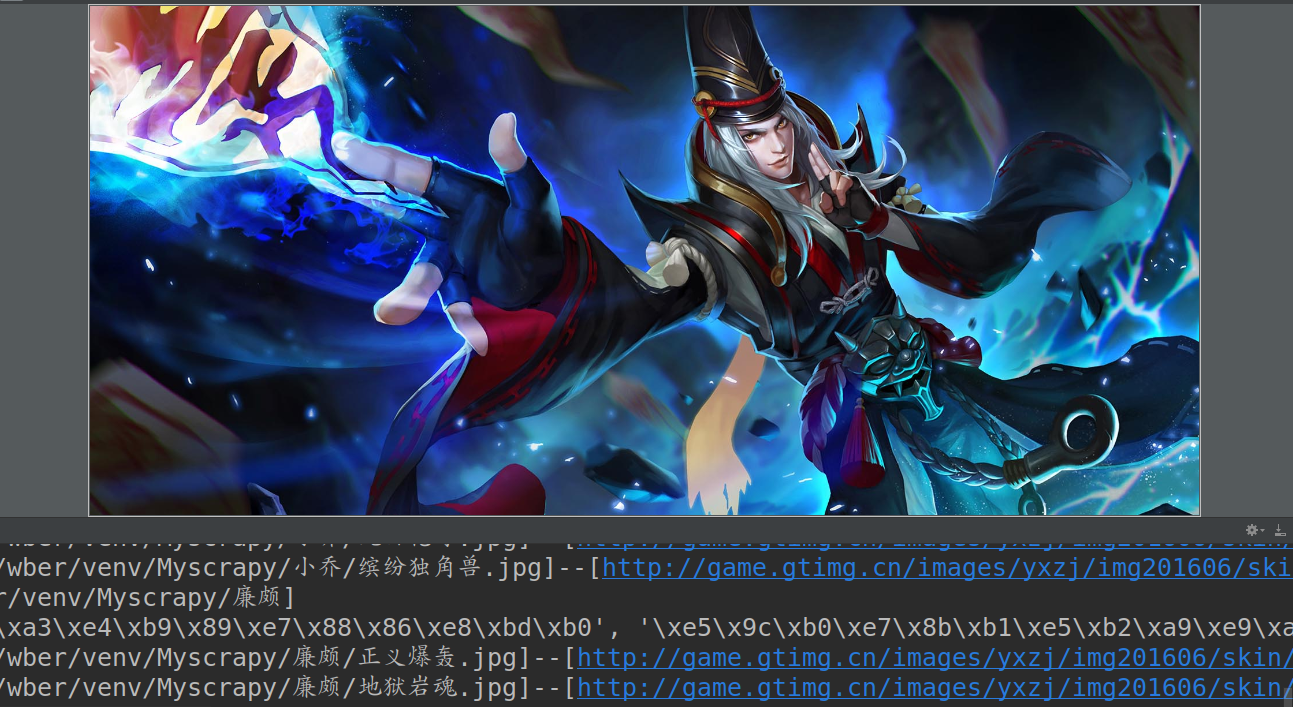
玩阴阳师呢,我可是Ssr只有两只狗子的非酋呢

正文
在 http://pvp.qq.com/web201605/herolist.shtml 可以看到全英雄列表。
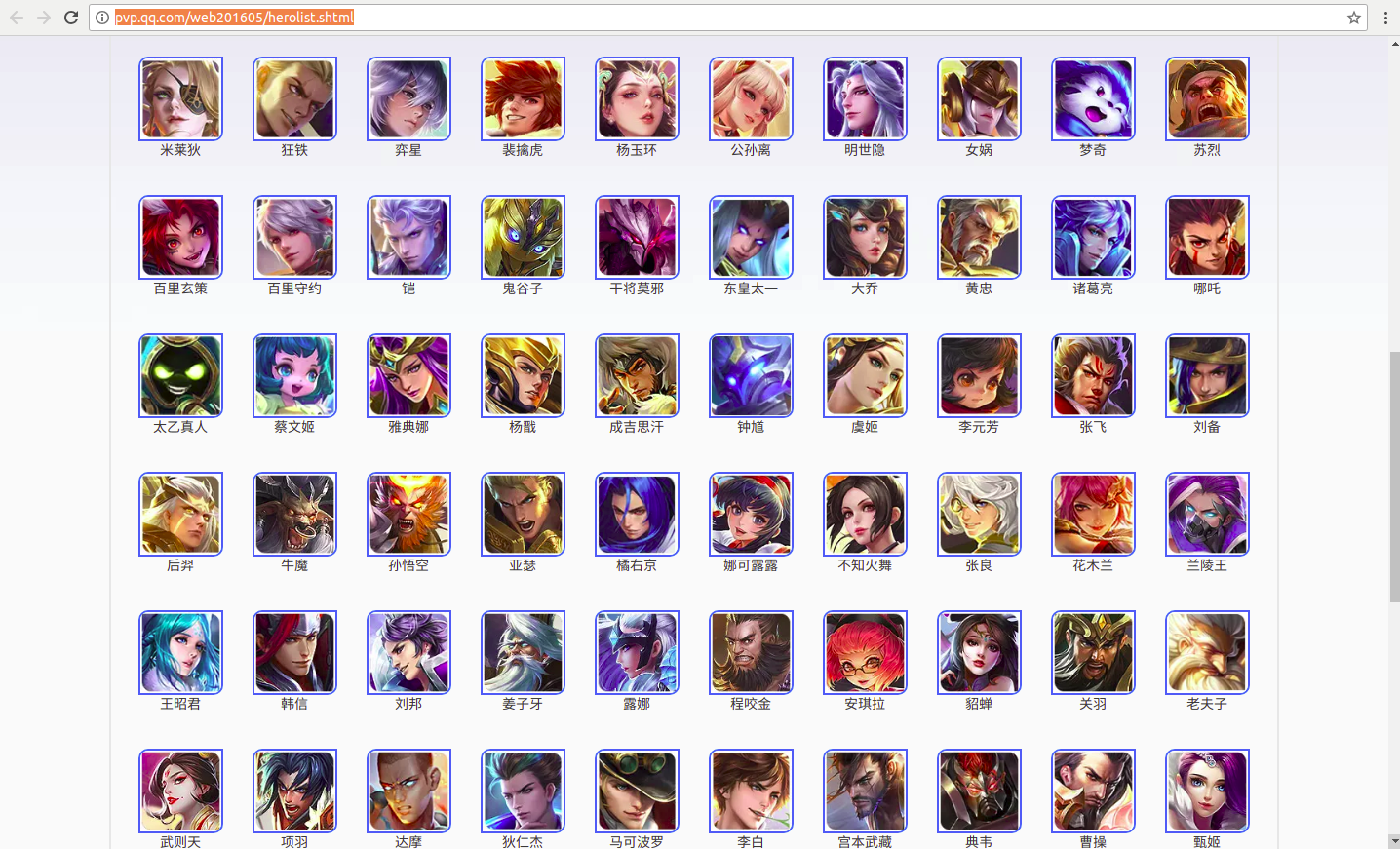
按F12查看元素
看到下面这一堆<li></li>标签了吗
里面的href就是每个英雄的详情地址
图片就在这个链接中
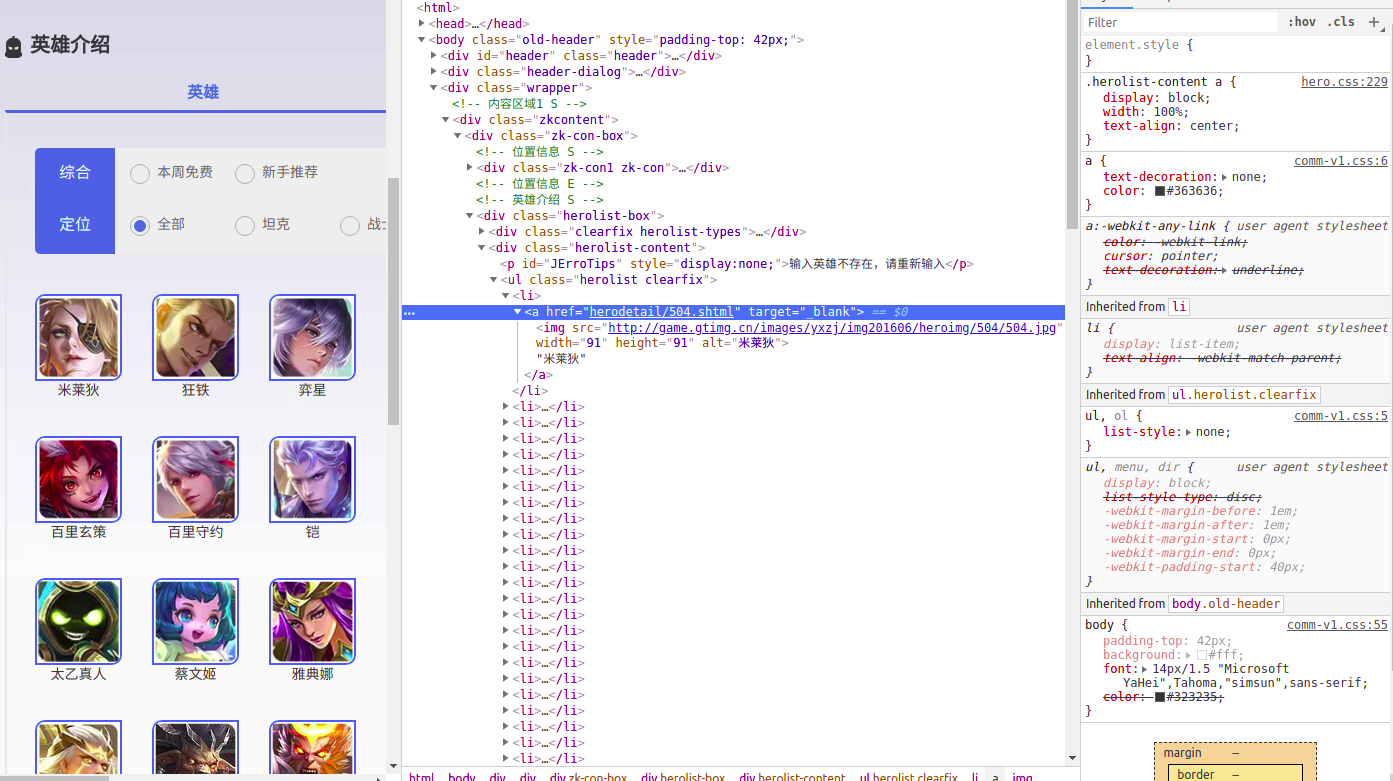
拿到selector
body > div.wrapper > div > div > div.herolist-box > div.herolist-content > ul > li > a
英雄列表获取源码:
def getHeroList():
'''取所以英雄存入list中'''
hero = {}
res = requests.get(mainurl)
sp = BeautifulSoup(res.content, "html.parser")
lists = sp.select('body > div.wrapper > div > div > div.herolist-box > div.herolist-content > ul > li')
for li in lists:
oj = li.select('a')[0];
hero['url'] = oj['href']
hero['name'] = oj.text
# 正则表达式取ename编号
ename = re.findall('herodetail/(\d+)\.shtml', oj['href'])[0]
hero['ename'] = ename
herolist.append(hero)
hero = {}
return herolist
进入英雄详情之后
可以发现,要保存图片的地址也在<li></li>中
他的selector是:
body > div.wrapper > div.zk-con1.zk-con > div > div > div.pic-pf > ul > li > i > img
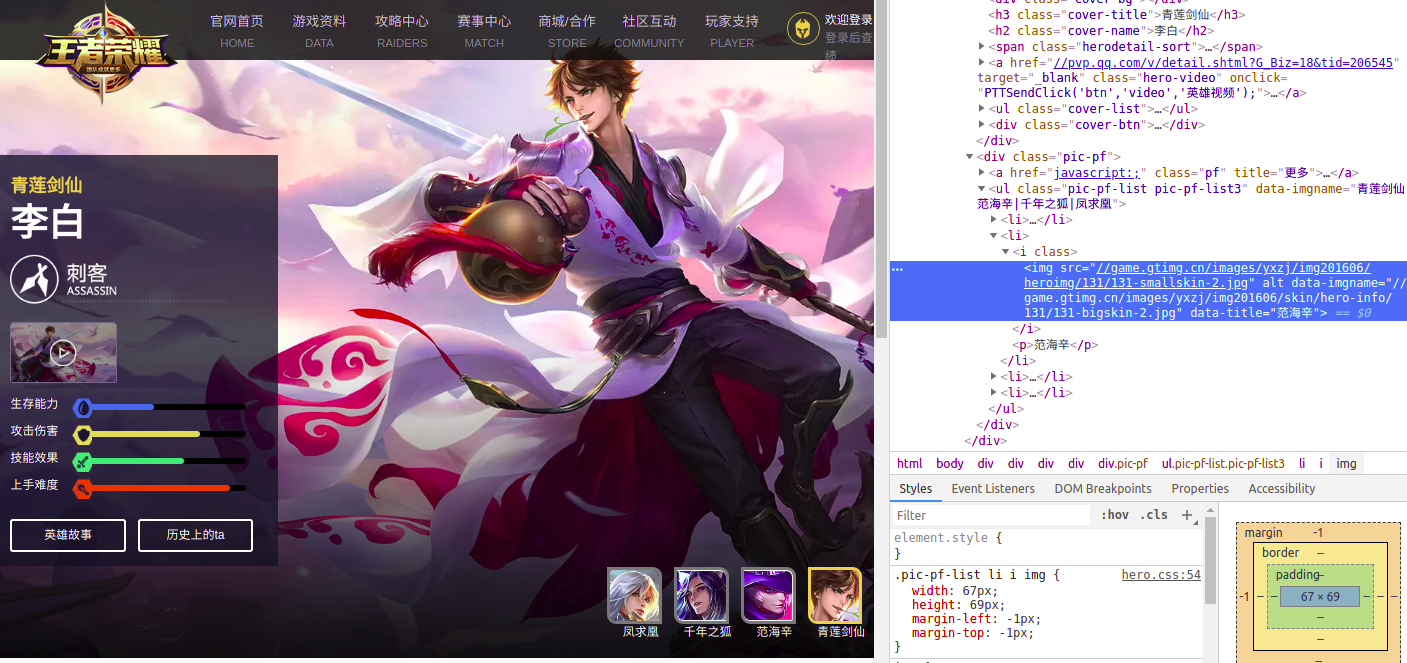
只需要将这个图片保存下来就可以了
代码:
def saveImg(filepath, imgUrl):
'''下载图片并保存'''
r = requests.get(imgUrl, stream=True)
with open(filepath, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
f.close()
全部代码:
# -*- coding: utf-8 -*- import os
import re
import requests
from bs4 import BeautifulSoup import sys
reload(sys)
sys.setdefaultencoding('utf-8') baseurl = 'http://pvp.qq.com/web201605'
mainurl = 'http://pvp.qq.com/web201605/herolist.shtml'
herolist = [] def getHeroList():
'''取所以英雄存入list中'''
hero = {}
res = requests.get(mainurl)
sp = BeautifulSoup(res.content, "html.parser")
lists = sp.select('body > div.wrapper > div > div > div.herolist-box > div.herolist-content > ul > li')
for li in lists:
oj = li.select('a')[0];
hero['url'] = oj['href']
hero['name'] = oj.text
# 正则表达式取ename编号
ename = re.findall('herodetail/(\d+)\.shtml', oj['href'])[0]
hero['ename'] = ename
herolist.append(hero)
hero = {}
return herolist def saveImg(filepath, imgUrl):
'''下载图片并保存'''
r = requests.get(imgUrl, stream=True)
with open(filepath, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
f.close() if __name__ == '__main__':
hlist = getHeroList()
for hero in herolist:
herodir = os.path.join(os.getcwd(), hero['name'])
heropage = baseurl + '/' + hero['url']
print('[%s]' % (herodir))
res = requests.get(heropage)
sop = BeautifulSoup(res.content, "html.parser")
li = sop.select('body > div.wrapper > div.zk-con1.zk-con > div > div > div.pic-pf > ul ')[0]['data-imgname']
li = str(li).split('|')
print(li)
# 遍历所有皮肤
for i in range(len(li)):
imgurl = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' \
+ hero['ename'] + '/' + hero['ename'] + '-bigskin-' + str(i + 1) + '.jpg'
imgname = os.path.join(herodir, li[i] + ".jpg")
print('----[%s]--[%s]---' % (imgname, imgurl))
# 创建英雄目录
if os.path.exists(herodir) == False:
os.mkdir(herodir)
saveImg(imgname, imgurl)
图片生成在同级目录
Python爬虫——你们要的王者荣耀高清图的更多相关文章
- python 爬取王者荣耀高清壁纸
代码地址如下:http://www.demodashi.com/demo/13104.html 一.前言 打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面 ...
- python爬虫王者荣耀高清皮肤大图背景故事通用爬虫
wzry-spider python通用爬虫-通用爬虫爬取静态网页,面向小白 基本上纯python语法切片索引,少用到第三方爬虫网络库 这是一只小巧方便,强大的爬虫,由python编写 主要实现了: ...
- Node JS爬虫:爬取瀑布流网页高清图
原文链接:Node JS爬虫:爬取瀑布流网页高清图 静态为主的网页往往用get方法就能获取页面所有内容.动态网页即异步请求数据的网页则需要用浏览器加载完成后再进行抓取.本文介绍了如何连续爬取瀑布流网页 ...
- 参考学习《Python学习手册(第4版)》高清中文PDF+高清英文PDF+源代码
看到第38章了,整体感觉解释详细,例子丰富:关于Python语言本身的讲解全面详尽而又循序渐进不断重复,同时详述语言现象背后的机制和原理:除语言本身,还包含编程实践和设计以及高级主题.边看边写代码.不 ...
- 《Python编程第4版 下》高清PDF|百度网盘免费下载|Python基础编程
<Python编程第4版 下>高清PDF|百度网盘免费下载|Python基础编程 提取码:tz5v 当掌握Python的基础知识后,你要如何使用Python?Python编程(第四版)为这 ...
- 《Python编程第4版 上》高清PDF|百度网盘免费下载|Python基础编程
<Python编程第4版 上>高清PDF|百度网盘免费下载|Python基础编程 提取码:8qbi 当掌握Python的基础知识后,你要如何使用Python?Python编程(第四版)为 ...
- 《笨办法学 Python(第四版)》高清PDF|百度网盘免费下载|Python编程
<笨办法学 Python(第四版)>高清PDF|百度网盘免费下载|Python编程 提取码:jcl8 笨办法学 Python是Zed Shaw 编写的一本Python入门书籍.适合对计算机 ...
- 第二十八篇、自定义的UITableViewCell上有图片需要显示,要求网络网络状态为WiFi时,显示图片高清图;网络状态为蜂窝移动网络时,显示图片缩略图
1)SDWebImage会自动帮助开发者缓存图片(包括内存缓存,沙盒缓存),所以我们需要设置用户在WiFi环境下下载的高清图,下次在蜂窝网络状态下打开应用也应显示高清图,而不是去下载缩略图. 2)许多 ...
- SDWebImage -- 封装 (网络状态检测,是否打开手机网络下下载高清图设置)
对SDWebImage 进行封装,为了更好的节省用户手机流量,并保证在移动网络下也展示高清图,对使用SDWebImage 下载图片之前进行逻辑处理,根据本地缓存中是否有缓存原始的图片,用户是否打开移动 ...
随机推荐
- java学习之路--面试之多线程基础
Java多线程面试问题1. 进程和线程之间有什么不同?一个进程是一个独立(self contained)的运行环境,它可以被看作一个程序或者一个应用.而线程是在进程中执行的一个任务.Java运行环境是 ...
- curl HTTP Header
对于"User-Agent", "Cookie", "Host"这类标准的HTTP头部字段,通常会有另外一种设置方法.curl命令提供了 ...
- 【node】node连接mongodb操作数据库
1.下载第三方模块mongodb cnpm install mongodb --save 2.检测是否连接成功 1.引入第三方模块mongodb并创建一个客户端 const MongoClient = ...
- HTML经典模板总结(地址)
HTML经典模板总结 地址:http://download.csdn.net/tag/html%E6%A8%A1%E6%9D%BF?from=singlemessage
- ASP.NET Core 中读取 Request.Body 的正确姿势
ASP.NET Core 中的 Request.Body 虽然是一个 Stream ,但它是一个与众不同的 Stream —— 不允许 Request.Body.Position=0 ,这就意味着只能 ...
- jQuery相关用法
#jquery中extend的用法 [1] [2] jQuery.extend( target [, object1 ] [, objectN ] ) Description: Merge the c ...
- JDBC事务(一)
package cn.sasa.tran01; import java.sql.Connection; import java.sql.DriverManager; import java.sql.P ...
- MAC OS X&Vmware
推出共享文件恢复解决办法: 将/Volumes/VMware shared Folders 文件删除(此时这个文件中的内容为乱码) ,生成一个 VMware shared Folders文件夹,重新设 ...
- Java学习之路-Hessian学习
Hessian是基于HTTP的轻量级远程服务解决方案,Hessian像Rmi一样,使用二进制消息进行客户端和服务器端交互.但与其他二进制远程调用技术(例如Rmi)不同的是,它的二进制消息可以移植其他非 ...
- Oracle数据库基础入门《一》Oracle服务器的构成
Oracle数据库基础入门<一>Oracle服务器的构成 Oracle 服务器是一个具有高性能和高可靠性面向对象关系型数据库管理系统,也是一 个高效的 SQL 语句执行环境. Oracle ...