Python+Selenium学习--自动化测试模型
前言
一个自动化测试框架就是一个集成体系,在这一体系中包含测试功能的函数库、测试数据源、测试对象识别标准,以及种可重用的模块。自动化测试框架在发展的过程中经历了几个阶段,模块驱动测试、数据驱动测试、对象驱动测试。本章就带领读者了解这几种测试模型
1. 自动化测试模型介绍
自动化测试模型是自动化测试架构的基础,自动化测试的发展也经历的不同的阶段,不断有新的模型(概念)被提出,了解和使用这些自动化模型将帮助我们构建一个灵活可维护性的自动化架构
1.1 线性测试
通过录制或编写脚本,一个脚本完成一个场景(一组完整功能操作),通过对脚本的回放来进行自动化测试。这是早期进行自动化测试的一种形式;我们之前练习使用webdriver API 所编写的脚本也是
测试脚本一:
#!/usr/bin/env python
# -*- codinfg:utf-8 -*-
'''
@author: Jeff LEE
@file: cnblog登录.py
@time: 2018-09-27 9:55
@desc:
'''
import time
from selenium import webdriver driver = webdriver.Firefox()
#添加智能等待
driver.implicitly_wait(10) driver.get(r'https://passport.cnblogs.com/user/signin?ReturnUrl=https%3A%2F%2Fwww.cnblogs.com%2F') #登录用户
driver.find_element_by_id('input1').clear()
driver.find_element_by_id('input1').send_keys('abcdd')
driver.find_element_by_id('input2').clear()
driver.find_element_by_id('input2').send_keys('abcdd')
driver.find_element_by_id('signin').click()
time.sleep(5) #执行具体测试用例操作1 driver.quit()
测试脚本二:
#!/usr/bin/env python
# -*- codinfg:utf-8 -*-
'''
@author: Jeff LEE
@file: cnblog登录.py
@time: 2018-09-27 9:55
@desc:
'''
import time
from selenium import webdriver driver = webdriver.Firefox()
#添加智能等待
driver.implicitly_wait(10) driver.get(r'https://passport.cnblogs.com/user/signin?ReturnUrl=https%3A%2F%2Fwww.cnblogs.com%2F') #登录用户
driver.find_element_by_id('input1').clear()
driver.find_element_by_id('input1').send_keys('abcdd')
driver.find_element_by_id('input2').clear()
driver.find_element_by_id('input2').send_keys('abcdd')
driver.find_element_by_id('signin').click()
time.sleep(5) #执行具体测试用例操作1 driver.quit()
通过上面的两个脚本,我们发现它优势就是每一个脚本都是独立的,任何一个脚本文件拿出来就能单独运行;当然,缺点也很明显,用例的开发与维护成本很高:
一个用例对应一个脚本,假如登陆发生变化,用户名的属性发生改变,不得不需要对每一个脚本进行修改,测试用例形成一种规模,我们可能将大量的工作用于脚本的维护,从而失去自动化的意义。
这种模式下数据和脚本是混在一起的,如果数据发生变也需要对脚本进行修改。这种模式下脚本的没有可重复使用的概念
1.2 模块化与类库
我们会清晰的发现在上面的脚本中,其实有不少内容是重复的;于是我们就考虑能不能把重复的部分写成一个公共的模块,需要的时候进行调用,这样就大大提高了我们编写脚本的效率
login.py
#!/usr/bin/env python
# -*- codinfg:utf-8 -*-
'''
@author: Jeff LEE
@file: login.py
@time: 2018-09-27 10:06
@desc:
'''
def login(driver):
driver.find_element_by_id('input1').clear()
driver.find_element_by_id('input1').send_keys('abcdd')
driver.find_element_by_id('input2').clear()
driver.find_element_by_id('input2').send_keys('abcdd')
driver.find_element_by_id('signin').click()
测试用例:
#!/usr/bin/env python
# -*- codinfg:utf-8 -*-
'''
@author: Jeff LEE
@file: cnblog登录.py
@time: 2018-09-27 9:55
@desc:
'''
import time
from selenium import webdriver
import login driver = webdriver.Firefox()
#添加智能等待
driver.implicitly_wait(10) driver.get(r'https://passport.cnblogs.com/user/signin?ReturnUrl=https%3A%2F%2Fwww.cnblogs.com%2F') #登录用户
login.login(driver) #用例个性化操作 time.sleep(5)
driver.quit()
通过阅读上面的代码发现,我们可以把脚本中相同的部分代码独立出来,形成模块或库;这样做有两方面的优点:
- 一方面提高了开发效率,不用重复的编写相同的脚本;假如,我已经写好一个登录模块,我后续需要做的就是在需要的地方调用,不同重复造轮子
- 另一方面方便了代码的维护,假如登录模块发生了变化,我只用修改login.py 文件中登录模块的代码即可,那么所有调用登录模块的脚本不用做任何修改
1.3 数据驱动
数据驱动应该是自动化的一个进步;从它的本意来讲,数据的改变(更新)驱动自动化的执行,从而引起测试结果的改变。这显然是一个非常高级的概念和想法。其实,我们可直白的理解成参数化,输入数据的不同从而引起输出结果的变化,下面介绍几种读取参数化的几个例子:
1.3.1 读取文件参数法
test1
abc,123
efg,456
file_reader.py
!/usr/bin/env python
# -*- codinfg:utf-8 -*-
'''
@author: Jeff LEE
@file: file_reader.py
@time: 2018-09-27 17:00
@desc:
'''
import os class fileReader(object): def __init__(self, filepath):
if os.path.exists(filepath):
self.file = filepath
else:
raise FileNotFoundError('文件不存在!')
self._data = None @property
def data(self):
# 如果是第一次调用data,读取test文档,否则直接返回之前保存的数据
if not self._data:
with open(self.file, 'rb') as f:
self._data = f.readlines()
return self._data if __name__ =='__main__':
file_data = fileReader('test1').data
print(file_data)
执行结果:
['abc,123\n', 'efg,456']
对于像获取那个参数,可以对列表进行操作。
1.3.2 yaml参数法
此方法作者比较喜欢
test.yaml
testinfo:
- id: test001
title: 进入通讯录页面
info: 打开APP
testcase:
- element_info: //*[@text="通讯录" and @resource-id="com.camtalk.start:id/title"]
find_type: xpath
operate_type: click
info: 点击通讯录 check:
- element_info: //*[@text="全部" and @resource-id="com.camtalk.start:id/friend_rb_all"]
find_type: xpath
check: default_check
info: 打开通讯录页面成功
file_reader.py
#!/usr/bin/env python
# -*- codinfg:utf-8 -*-
'''
@author: Jeff LEE
@file: file_reader.py
@time: 2018-09-27 17:00
@desc:
'''
import os
import yaml class yamlReader(object):
def __init__(self, yamlf):
if os.path.exists(yamlf):
self.yamlf = yamlf
else:
raise FileNotFoundError('文件不存在!')
self._data = None @property
def data(self):
# 如果是第一次调用data,读取yaml文档,否则直接返回之前保存的数据
if not self._data:
with open(self.yamlf, 'rb') as f:
self._data = list(yaml.safe_load_all(f)) # load后是个generator,用list组织成列表
return self._data if __name__ == '__main__':
yaml_data=yamlReader('test.yaml').data
print(yaml_data)
运行结果:
[{'testcase': [{'info': '点击通讯录', 'find_type': 'xpath', 'operate_type': 'click', 'element_info': '//*[@text="通讯录" and @resource-id="com.camtalk.start:id/title"]'}], 'testinfo': [{'info': '打开APP', 'title': '进入通讯录页面', 'id': 'test001'}], 'check': [{'info': '打开通讯录页面成功', 'find_type': 'xpath', 'check': 'default_check', 'element_info': '//*[@text="全部" and @resource-id="com.camtalk.start:id/friend_rb_all"]'}]}]
1.3.3 excel参数法
baidu.xlxs

file_reader.py
#!/usr/bin/env python
# -*- codinfg:utf-8 -*-
'''
@author: Jeff LEE
@file: file_reader.py
@time: 2018-09-27 17:00
@desc:
'''
import os
from xlrd import open_workbook class excelReader(object):
"""
读取excel文件中的内容。返回list。 如:
excel中内容为:
| A | B | C |
| A1 | B1 | C1 |
| A2 | B2 | C2 | 如果 print(ExcelReader(excel, title_line=True).data),输出结果:
[{A: A1, B: B1, C:C1}, {A:A2, B:B2, C:C2}] 如果 print(ExcelReader(excel, title_line=False).data),输出结果:
[[A,B,C], [A1,B1,C1], [A2,B2,C2]] 可以指定sheet,通过index或者name:
ExcelReader(excel, sheet=2)
ExcelReader(excel, sheet='BaiDuTest')
"""
def __init__(self, excel, sheet=0, title_line=True):
if os.path.exists(excel):
self.excel = excel
else:
raise FileNotFoundError('文件不存在!')
self.sheet = sheet
self.title_line = title_line
self._data = list() @property
def data(self):
if not self._data:
workbook = open_workbook(self.excel)
if type(self.sheet) not in [int, str]:
raise ('Please pass in <type int> or <type str>, not {0}'.format(type(self.sheet)))
elif type(self.sheet) == int:
s = workbook.sheet_by_index(self.sheet)
else:
s = workbook.sheet_by_name(self.sheet) if self.title_line:
title = s.row_values(0) # 首行为title
for col in range(1, s.nrows):
# 依次遍历其余行,与首行组成dict,拼到self._data中
self._data.append(dict(zip(title, s.row_values(col))))
else:
for col in range(0, s.nrows):
# 遍历所有行,拼到self._data中
self._data.append(s.row_values(col))
return self._data if __name__ == '__main__':
excel_data =excelReader('baidu.xlsx').data
print(excel_data)
运行结果:
[{'search': 'selenium 灰蓝', 'name': 'lizf'}, {'search': 'Python selenium', 'name': 'abby'}]
1.3.4 csv参数法
test.csv
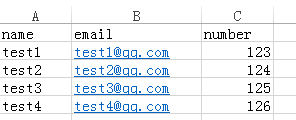
file_reader.py
#!/usr/bin/env python
# -*- codinfg:utf-8 -*-
'''
@author: Jeff LEE
@file: file_reader.py
@time: 2018-09-27 17:00
@desc:
'''
import os
import csv class csvReader(object):
def __init__(self, filepath):
if os.path.exists(filepath):
self.file = filepath
else:
raise FileNotFoundError('文件不存在!')
self._data = None @property
def data(self):
# 如果是第一次调用data,读取csv文档,否则直接返回之前保存的数据
if not self._data:
with open(self.file, 'rb') as f:
self._data = csv.reader(f)
return self._data if __name__ == '__main__':
csv_data =excelReader('test.csv').data
print(csv_data)
运行结果(类似excel):
[{'number': 123.0, 'name': 'test1', 'email': 'test1@qq.com'}, {'number': 124.0, 'name': 'test2', 'email': 'test2@qq.com'}, {'number': 125.0, 'name': 'test3', 'email': 'test3@qq.com'}, {'number': 126.0, 'name': 'test4', 'email': 'test4@qq.com'}]
1.3.5 总结
不管我们读取的是数组,还是字典、函数,又或者是csv、txt 、excel、yaml文件。我们实现了数据与脚本的分离,换句话说,我们实现了参数化。我们传一千条数据,通过脚本的执行,可以返回一千条结果出来。
同样的脚本执行不同的数据从而得到了不同的结果,是不是增强的脚本的复用性呢!?
其实,模块化与参数化这对开发来说是完全没有什么技术含量的;对于当初QTP 自动化工具来说地确是一个卖点,因为它面对的大多是不懂开发的测试,当然,随着时代的发展,懂开发的测试人员越来越多
1.4 关键字驱动
理解了数据驱动,无非是把“数据”换成“关键字”,通过关键字的改变引起测试结果的改变。
关键字驱动用编程方式就不太容易表现了。QTP、robot framework 等都是以关键字驱动为主的自动化工具,因为这类工具主打的易用性,“填表格”式的关键字驱动帮我们封装了很多底层的东西,我们只要考虑三个问题就可以了:我要做什么? 对谁做?怎么做?。
我们可以把selenium IDE 看做是一种关键字驱动的自动化工具,详细可以去找网上其他资料
1.5 小结
这里简单介绍了自动化测试的几种不同的模型,虽然简单阐述了他们的优缺点,但他们并非后者淘汰前者的关系,在实施自动化更多的是以需求为出发点,混合的来使用以上模型去解决问题;使我们的脚本更易于开发与维护。
Python+Selenium学习--自动化测试模型的更多相关文章
- 【python+selenium学习】Python常见错误之:IndentationError: unexpected indent
初入python+selenium学习之路,总会遇到这样那样的问题.IndentationError: unexpected indent,这个坑我已经踏进数次了,索性记录下来.都知道Python对代 ...
- Python+Selenium学习笔记15 - 读取txt和csv文件
读取txt的内容并用百度查找搜索 1 # coding = utf-8 2 3 from selenium import webdriver 4 import time 5 6 # 打开浏览器 7 d ...
- web自动化测试python+selenium学习总结----selenium安装、浏览器驱动下载
一.安装selenium 命令安装selenium库 :pip install -U selenium 查看selenium是否安装成功:pip list PS:有时会有异常,安装失败,可以尝试去s ...
- web自动化测试python+selenium学习总结----python环境安装
一.python下载地址:https://www.python.org/downloads/ 二.双击python的.exe文件安装: 后面直接点击“next” 步骤二:选择安装在D:\python3 ...
- web自动化测试python+selenium学习总结----python编辑器pycharm环境安装
下载安装文件 下载最新文件路径:https://www.jetbrains.com/pycharm/ 安装: 一直点击下一步即可 破解: 配置hosts文件.C:\Windows\System32\d ...
- Python+Selenium UI自动化测试环境搭建及使用
一什么是Selenium ? Selenium 是一个浏览器自动化测试框架,它主要用于web应用程序的自动化测试,其主要特点如下:开源.免费:多平台.浏览器.多语言支持:对web页面有良好的支持:AP ...
- Python&selenium&tesseract自动化测试随机码、验证码(Captcha)的OCR识别解决方案参考
在自动化测试或者安全渗透测试中,Captcha验证码的问题经常困扰我们,还好现在OCR和AI逐渐发展起来,在这块解决上越来越支撑到位. 我推荐的几种方式,一种是对于简单的验证码,用开源的一些OCR图片 ...
- Python+Selenium学习--启动及关闭浏览器
场景 页面上弹出的对话框是自动化测试经常会遇到的一个问题:很多情况下对话框是一个iframe,如之前iframe介绍的例子,处理起来稍微有点麻烦:但现在很多前端框架的对话框是div 形式的,这就让我们 ...
- Python+Selenium - Web自动化测试(二):元素定位
前言 前面已经把环境搭建好了,现在开始使用 Selenium 中的 Webdriver 框架编写自动化代码脚本,我们常见的在浏览器中的操作都会有相对应的类方法,这些方法需要定位才能操作元素,不同网页的 ...
随机推荐
- MySQL Error--Error Code
mysql error code(备忘) 1005:创建表失败 1006:创建数据库失败 1007:数据库已存在,创建数据库失败 1008:数据库不存在,删除数据库失败 1009:不能删除数据库文件导 ...
- 第2章 Java基本语法(下): 流程控制--项目(记账本)
2-5 程序流程控制 2-5-1 顺序结构 2-5-2 分支语句1:if-else结构 案例 class IfTest1{ public static void main(String[] args) ...
- 十九、springcloud(五)配置中心本地示例和refresh
1.创建spring-cloud-houge-config子项目,测试需要的项目入下 2.添加依赖 <dependency> <groupId>org.springframew ...
- 关于Xilinx AXI Lite 源代码分析---自建带AXI接口的IP
关于Xilinx AXI Lite 源代码分析---自建带AXI接口的IP 首先需要注意此处寄存器数量的配置,它决定了slv_reg的个数. 读写数据,即是对寄存器slv_reg进行操作: 关于AXI ...
- 彻底卸载Windows 10中OneDrive
批处理来源网上. @rem OneDrive Complete uninstaller batch process for Windows 10. @rem Run as administrator ...
- Docker容器常用命令
容器是镜像的一个运行实例.两者不同的是,镜像是静态的只读文件,而容器带有运行时需要的可写文件层. 一.创建容器 1.新建容器 docker create:新建一个容器 create命令命令支持的选项十 ...
- 创建一个HTTP接口测试
jmeter Apache JMeter是Apache组织开发的基于Java的压力测试工具. Apache jmeter 可以用于对静态的和动态的资源(文件,Servlet,Perl脚本,java 对 ...
- kafka命令大全
kafka命令大全 http://orchome.com/454
- mass create DN
RUN VL10 in the background. http://paperstreetenterprises.com/running-vl10-background/ VL10*开头的TCODE ...
- 涂抹mysql笔记-InnoDB/MyISAM及其它各种存储引擎
存储引擎:一种设计的存取和处理方式.为不同访问特点的表对象指定不同的存储引擎,可以获取更高的性能和处理数据的灵活性.通常是.so文件,可以用mysql命令加载它. 查看当前mysql数据库支持的存储引 ...