Kafka实战-数据持久化
1.概述
经过前面Kafka实战系列的学习,我们通过学习《Kafka实战-入门》了解Kafka的应用场景和基本原理,《Kafka实战-Kafka Cluster》一文给大家分享了Kafka集群的搭建部署,让大家掌握了集群的搭建步骤,《Kafka实战-实时日志统计流程》一文给大家讲解一个项目(或者说是系统)的整体流程,《Kafka实战-Flume到Kafka》一文给大家介绍了Kafka的数据生产过程,《Kafka实战-Kafka到Storm》一文给大家介绍了Kafka的数据消费,通过Storm来实时计算处理。今天进入Kafka实战的最后一个环节,那就是Kafka实战的结果的数据持久化。下面是今天要分享的内容目录:
- 结果持久化
- 实现过程
- 结果预览
下面开始今天的分享内容。
2.结果持久化
一般,我们在进行实时计算,将结果统计处理后,需要将结果进行输出,供前端工程师去展示我们统计的结果(所说的报表)。结果的存储,这里我们选择的是Redis+MySQL进行存储,下面用一张图来展示这个持久化的流程,如下图所示:
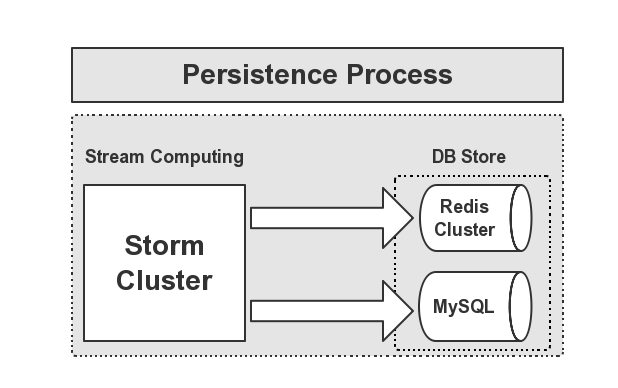
从途中可以看出,实时计算的部分由Storm集群去完成,然后将计算的结果输出到Redis和MySQL库中进行持久化,给前端展示提供数据源。接下来,我给大家介绍如何实现这部分流程。
3.实现过程
首先,我们去实现Storm的计算结果输出到Redis库中,代码如下所示:
package cn.hadoop.hdfs.storm; import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry; import redis.clients.jedis.Jedis;
import cn.hadoop.hdfs.util.JedisFactory;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple; /**
* @Date Jun 10, 2015
*
* @Author dengjie
*
* @Note Calc WordsCount eg.
*/
public class WordsCounterBlots implements IRichBolt { /**
*
*/
private static final long serialVersionUID = -619395076356762569L; OutputCollector collector;
Map<String, Integer> counter; @SuppressWarnings("rawtypes")
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.counter = new HashMap<String, Integer>();
} public void execute(Tuple input) {
String word = input.getString(0);
Integer integer = this.counter.get(word);
if (integer != null) {
integer += 1;
this.counter.put(word, integer);
} else {
this.counter.put(word, 1);
}
for (Entry<String, Integer> entry : this.counter.entrySet()) {
// write result to redis
Jedis jedis = JedisFactory.getJedisInstance("real-time");
jedis.set(entry.getKey(), entry.getValue().toString()); // write result to mysql
// ...
}
this.collector.ack(input);
} public void cleanup() {
// TODO Auto-generated method stub } public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub } public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
} }
注:这里关于输出到MySQL就不赘述了,大家可以按需处理即可。
4.结果预览
在实现持久化到Redis的代码实现后,接下来,我们通过提交Storm作业,来观察是否将计算后的结果持久化到了Redis集群中。结果如下图所示:

通过Redis的Client来浏览存储的Key值,可以观察统计的结果持久化到来Redis中。
5.总结
我们在提交作业到Storm集群的时候需要观察作业运行状况,有可能会出现异常,我们可以通过Storm UI界面来观察,会有提示异常信息的详细描述。若是出错,大家可以通过Storm UI的错误信息和Log日志打印的错误信息来定位出原因,从而找到对应的解决办法。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
Kafka实战-数据持久化的更多相关文章
- 漫游Kafka设计篇之数据持久化
Kafka大量依赖文件系统去存储和缓存消息.对于硬盘有个传统的观念是硬盘总是很慢,这使很多人怀疑基于文件系统的架构能否提供优异的性能.实际上硬盘的快慢完全取决于使用它的方式.设计良好的硬盘架构可以和内 ...
- Docker数据持久化及实战(Nginx+Spring Boot项目+MySQL)
Docker数据持久化: Volume: (1)创建mysql数据库的container docker run -d --name mysql01 -e MYSQL_ROOT_PASSWORD= my ...
- .Net Redis实战——事务和数据持久化
Redis事务 Redis事务可以让一个客户端在不被其他客户端打断的情况下执行多个命令,和关系数据库那种可以在执行的过程中进行回滚(rollback)的事务不同,在Redis里面,被MULTI命令和E ...
- iOS开发——项目实战总结&数据持久化分析
数据持久化分析 plist文件(属性列表) preference(偏好设置) NSKeyedArchiver(归档) SQLite 3 CoreData 当存储大块数据时你会怎么做? 你有很多选择,比 ...
- DataPipeline |《Apache Kafka实战》作者胡夕:Apache Kafka监控与调优
胡夕 <Apache Kafka实战>作者,北航计算机硕士毕业,现任某互金公司计算平台总监,曾就职于IBM.搜狗.微博等公司.国内活跃的Kafka代码贡献者. 前言 虽然目前Apache ...
- Kafka实战分析(一)- 设计、部署规划及其调优
1. Kafka概要设计 kafka在设计之初就需要考虑以下4个方面的问题: 吞吐量/延时 消息持久化 负载均衡和故障转移 伸缩性 1.1 吞吐量/延时 对于任何一个消息引擎而言,吞吐量都是至关重要的 ...
- 《Apache Kafka实战》读书笔记-调优Kafka集群
<Apache Kafka实战>读书笔记-调优Kafka集群 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.确定调优目标 1>.常见的非功能性要求 一.性能( ...
- 《Apache kafka实战》读书笔记-管理Kafka集群安全之ACL篇
<Apache kafka实战>读书笔记-管理Kafka集群安全之ACL篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家能看到这篇博客的小伙伴,估计你对kaf ...
- 《Apache Kafka 实战》读书笔记-认识Apache Kafka
<Apache Kafka 实战>读书笔记-认识Apache Kafka 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.kafka概要设计 kafka在设计初衷就是 ...
随机推荐
- Eclipse常用快捷键(用到想到随时更新)
原始链接:https://jingyan.baidu.com/article/fedf073771323235ac8977f1.html Shift+Enter在当前行的下一行插入空行(这时鼠标可以在 ...
- Git-git push -u为何第二次不用指定-u?
1,如果当前分支只有一个追踪分支,那么主机名都可以省略,如:git push origin 将当前分支推送到origin主机的对应分支 2,$ git push 如果当前分支与多个主机存在追踪关系,那 ...
- Quartz.Net进阶之四:CronTrigger 详述
以前都是将所有的内容放在一篇文章里,就会导致文章很长,对于学习的人来说,有时候这也是一个障碍.所以,以后我的写作习惯,我就会把我写的文章缩短,但是内容不会少,内容更集中.这样,学习起来也不会很累,很容 ...
- PHP开发——数据类型
概述 l 变量就是一个容器,变量本身并没有类型,变量的类型解决值的类型. l PHP和JS都属于弱类型语言,变量在运行过程中,类型是可以变的.但是,Java不可以. l 标量(基本)数据类型:字 ...
- BZOJ5017 [SNOI2017]炸弹 - 线段树优化建图+Tarjan
Solution 一个点向一个区间内的所有点连边, 可以用线段树优化建图来优化 : 前置技能传送门 然后就得到一个有向图, 一个联通块内的炸弹可以互相引爆, 所以进行缩点变成$DAG$ 然后拓扑排序. ...
- 20172325 2018-2019-2 《Java程序设计》第七周学习总结
20172325 2018-2019-2 <Java程序设计>第七周学习总结 教材学习内容总结 二叉查找树 二叉查找树:是含附加属性的二叉树,即其左孩子小于父节点,而父节点又小于或等于右孩 ...
- Apache beam中的便携式有状态大数据处理
Apache beam中的便携式有状态大数据处理 目标: 什么是 apache beam? 状态 计时器 例子&小demo 一.什么是 apache beam? 上面两个图片一个是正面切图,一 ...
- windows内核对象管理学习笔记
目前正在阅读毛老师的<windows内核情景分析>一书对象管理章节,作此笔记. Win内核中是使用对象概念来描述管理内核中使用到的数据结构.此对象(Object)均是由对象头(Object ...
- SQL 不常用的一些命令sp_OACreate,xp_cmdshell,sp_makewebtask
开启和关毕xp_cmdshell EXEC sp_configure 'show advanced options', 1;RECONFIGURE;EXEC sp_configure 'xp_cm ...
- squid常用操作
如何查看squid的缓存命中率 使用命令: squidclient -h host -p port mgr:info比如: /usr/local/squid/bin/squidclient -h 12 ...