Elasticsearch学习之图解Elasticsearch中的_source、_all、store和index属性
转自 : https://blog.csdn.net/napoay/article/details/62233031
1. 概述
Elasticsearch中有几个关键属性容易混淆,很多人搞不清楚_source字段里存储的是什么?store属性的true或false和_source字段有什么关系?store属性设置为true和_all有什么关系?index属性又起到什么作用?什么时候设置store属性为true?什么时候应该开启_all字段?本文通过图解的方式,深入理解Elasticsearch中的_source、_all、store和index属性。
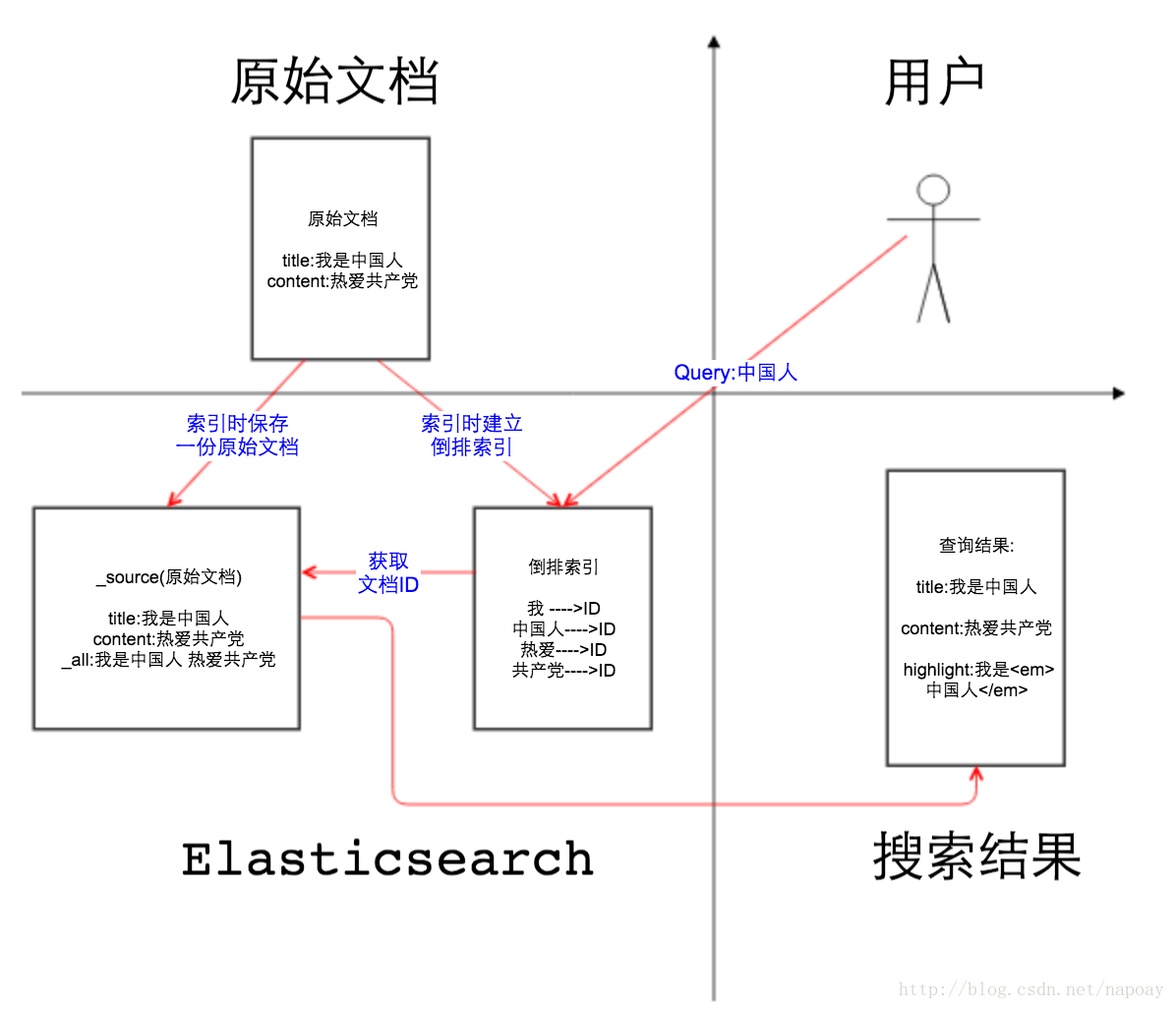
如图1所示, 第二象限是一份原始文档,有title和content2个字段,字段取值分别为”我是中国人”和” 热爱”,这一点没什么可解释的。我们把原始文档写入Elasticsearch,默认情况下,Elasticsearch里面有2份内容,一份是原始文档,也就是_source字段里的内容,我们在Elasticsearch中搜索文档,查看的文档内容就是_source中的内容,如图2,相信大家一定非常熟悉这个界面。

另一份是倒排索引,倒排索引中的数据结构是倒排记录表,记录了词项和文档之间的对应关系,比如关键词”中国人”包含在文档ID为1的文档中,倒排记录表中存储的就是这种对应关系,当然也包括词频等更多信息。Elasticsearch底层用的是Lucene的API,Elasticsearch之所以能完成全文搜索的功能就是因为存储的有倒排索引。如果把倒排索引拿掉,Elasticsearch是不是和mongoDB很像?
那么文档索引到Elasticsearch的时候,默认情况下是对所有字段创建倒排索引的(动态mapping解析出来为数字类型、布尔类型的字段除外),某个字段是否生成倒排索引是由字段的index属性控制的,在Elasticsearch 5之前,index属性的取值有三个:
analyzed:字段被索引,会做分词,可搜索。反过来,如果需要根据某个字段进搜索,index属性就应该设置为analyzed。
not_analyzed:字段值不分词,会被原样写入索引。反过来,如果某些字段需要完全匹配,比如人名、地名,index属性设置为not_analyzed为佳。
no:字段不写入索引,当然也就不能搜索。反过来,有些业务要求某些字段不能被搜索,那么index属性设置为no即可。
再说_all字段,顾名思义,_all字段里面包含了一个文档里面的所有信息,是一个超级字段。以图中的文档为例,如果开启_all字段,那么title+content会组成一个超级字段,这个字段包含了其他字段的所有内容,当然也可以设置只存储某几个字段到_all属性里面或者排除某些字段。回到图一的第一象限,用户输入关键词" 中国人",分词以后,Elasticsearch从倒排记录表中查找哪些文档包含词项"中国人 ",注意变化,分词之前" 中国人"是用户查询(query),分词之后在倒排索引中" 中国人"是词项(term)。Elasticsearch根据文档ID(通常是文档ID的集合)返回文档内容给用户,如图一第四象限所示。通常情况下,对于用户查询的关键字要做高亮处理,如图3所示:
关键字高亮实质上是根据倒排记录中的词项偏移位置,找到关键词,加上前端的高亮代码。这里就要说到store属性,store属性用于指定是否将原始字段写入索引,默认取值为no。如果在Lucene中,高亮功能和store属性是否存储息息相关,因为需要根据偏移位置到原始文档中找到关键字才能加上高亮的片段。在Elasticsearch,因为_source中已经存储了一份原始文档,可以根据_source中的原始文档实现高亮,在索引中再存储原始文档就多余了,所以Elasticsearch默认是把store属性设置为no。注意:如果想要对某个字段实现高亮功能,_source和store至少保留一个。下面会给出测试代码。至此,文章开头提出的几个问题都给出了答案。下面给出这几个字段常用配置的代码。
2. _source
_source字段默认是存储的, 什么情况下不用保留_source字段?如果某个字段内容非常多,业务里面只需要能对该字段进行搜索,最后返回文档id,查看文档内容会再次到mysql或者hbase中取数据,把大字段的内容存在Elasticsearch中只会增大索引,这一点文档数量越大结果越明显,如果一条文档节省几KB,放大到亿万级的量结果也是非常可观的。 如果想要关闭_source字段,在mapping中的设置如下:
{
"yourtype":{
"_source":{
"enabled":false
},
"properties": {
...
}
}
}
如果只想存储某几个字段的原始值到Elasticsearch,可以通过incudes参数来设置,在mapping中的设置如下:
{
"yourtype":{
"_source":{
"includes":["field1","field2"]
},
"properties": {
...
}
}
}
同样,可以通过excludes参数排除某些字段:
{
"yourtype":{
"_source":{
"excludes":["field1","field2"]
},
"properties": {
...
}
}
}
测试,首先创建一个索引,设置mapping,禁用_source:
PUT test/test/_mapping
{
"test": {
"_source": {
"enabled": false
}
}
}
POST test/test/1 { "title":"我是中国人", "content":"热爱" }
搜索关键词”中国人”:
GET test/_search
{
"query": {
"match": {
"title": "中国人"
}
}
}
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"failed":
},
"hits": {
"total": ,
"max_score": 0.30685282,
"hits": [
{
"_index": "test",
"_type": "test",
"_id": "",
"_score": 0.30685282
}
]
}
}
从返回结果中可以看到,搜到了一条文档,但是禁用_source以后查询结果中不会再返回文档原始内容。(注,测试基于ELasticsearch 2.3.3,配置文件中已默认指定ik分词。
3. _all
_all字段默认是关闭的,如果要开启_all字段,索引增大是不言而喻的。_all字段开启适用于不指定搜索某一个字段,根据关键词,搜索整个文档内容。
开启_all字段的方法和_source类似,mapping中的配置如下:
"yourtype": {
"_all": {
"enabled": true
},
"properties": {
...
}
}
}
也可以通过在字段中指定某个字段是否包含在_all中:
{
"yourtype": {
"properties": {
"field1": {
"type": "string",
"include_in_all": false
},
"field2": {
"type": "string",
"include_in_all": true
}
}
}
}
如果要把字段原始值保存,要设置store属性为true,这样索引会更大,需要根据需求使用。设置mapping,这里设置所有字段都保存在_all中并且存储原始值:
PUT test/test/_mapping
{
"test": {
"_all": {
"enabled": true,
"store": true
}
}
}
POST test/test/1 { "title":"我是中国人", "content":"热爱" }
对_all字段进行搜索并高亮:
POST test/_search
{
"fields": ["_all"],
"query": {
"match": {
"_all": "中国人"
}
},
"highlight": {
"fields": {
"_all": {}
}
}
}
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"failed":
},
"hits": {
"total": ,
"max_score": 0.15342641,
"hits": [
{
"_index": "test",
"_type": "test",
"_id": "",
"_score": 0.15342641,
"_all": "我是中国人 热爱 ",
"highlight": {
"_all": [
"我是<em>中国人</em> 热爱 "
]
}
}
]
}
}
Elasticsearch中的query_string和simple_query_string默认就是查询_all字段,示例如下:
GET test/_search
{
"query": {
"query_string": {
"query": "公公公"
}
}
}
4. index和score配置
index和store属性是在字段内进行设置的,下面给出一个例子,设置test索引不保存_source,title字段索引但不分析,字段原始值写入索引,content字段为默认属性,代码如下:
DELETE test
PUT test
PUT test/test/_mapping
{
"test": {
"_source": {
"enabled": false
},
"properties": {
"title": {
"type": "string",
"index": "not_analyzed",
"store": "true"
},
"content": {
"type": "string"
}
}
}
}
Elasticsearch学习之图解Elasticsearch中的_source、_all、store和index属性的更多相关文章
- 图解Elasticsearch中的_source、_all、store和index属性
https://blog.csdn.net/napoay/article/details/62233031
- 【Elasticsearch学习之三】Elasticsearch 搜索引擎案例
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 elasticsearch-2.2.0 第一步:获取数据主流 ...
- 【Elasticsearch学习之一】Elasticsearch
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 一.概念ElasticSearch: 基于Lucene全文搜 ...
- PyQt(Python+Qt)学习随笔:Designer中的QDialogButtonBox的orientation和centerButtons属性
orientation属性 orientation属性表示QDialogButtonBox的方向,缺省情况下,方向为水平方向(值为Qt.Horizontal),表示QDialogButtonBox中的 ...
- 图解elasticsearch的_source、_all、store和index
Elasticsearch中有几个关键属性容易混淆,很多人搞不清楚_source字段里存储的是什么?store属性的true或false和_source字段有什么关系?store属性设置为true和_ ...
- elasticsearch学习网站
elasticsearch学习网站 https://elasticsearch.cn/
- 浅析ES的_source、_all、store、index
Elasticsearch中有大量关键概念容易混淆,对于初学者来说是噩梦: _source字段里存储了什么? index属性的作用是什么? 何时应该开启_all字段? store属性和_source字 ...
- ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
分布式文档存储 ES分布式特性 屏蔽了分布式系统的复杂性 集群内的原理 垂直扩容和水平扩容 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中 ES集群特点 ...
- elasticsearch中mapping的_source和store的笔记
0.故事引入 无意中看到了ES的mapping中有store字段,作为一个ES菜鸡,有必要对这个字段进行下笔记. 1._source _source字段我在们进行检索时相当重要, ES默认检索只会返回 ...
随机推荐
- flask内容学习之蓝图以及单元测试
蓝图的概念: 简单来说,蓝图是一个存储操作方法的容器.这些操作在这个蓝图被注册到一个应用之后就可以被调用.Flask可以通过蓝图来制止URL以及处理请求.Flask使用蓝图来让应用实现模块化,在Fla ...
- jQuery 学习02——效果:隐藏/显示、淡入淡出、滑动、动画、停止动画、Callback、链
jQuery 效果- 隐藏hide()和显示show() 语法: $(selector).hide(speed,callback);$(selector).show(speed,callback); ...
- sqoop导出到hdfs
./sqoop export --connect jdbc:mysql://192.168.58.180/db --username root --password 123456 --export- ...
- delphi button 实现下拉列表
unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms ...
- Spark2.3(四十):如何使用java通过yarn api调度spark app,并根据appId监控任务,关闭任务,获取任务日志
背景: 调研过OOZIE和AZKABA,这种都是只是使用spark-submit.sh来提交任务,任务提交上去之后获取不到ApplicationId,更无法跟踪spark application的任务 ...
- Android application捕获崩溃异常
Java代码 .收集所有 avtivity 用于彻底退出应用 .捕获崩溃异常,保存错误日志,并重启应用 , intent, , restartIntent); // 关闭当前应用 finishAllA ...
- 利用StringEscapeUtils来转义和反转义html/xml/javascript中的特殊字符
我们经常遇到html或者xml在Java程序中被某些库转义成了特殊字符. 例如: 各种逻辑运算符: > >= < <= == 被转义成了 == ...
- Couldn't find log associated with operation handle: OperationHandle [opType=EXECUTE_STATEMENT, getHandleIdentifier ()=5687ff62-aa71-4b47-af6c-89f6a3f7a1fe]
这个异常的出现是因为hive-site-xml中的hive.server2.logging.operation.log.location属性未配置正确: 修改为: <property> & ...
- 【PHP】解析PHP中的数组
目录结构: contents structure [-] 创建数组 删除数组 栈结构 常用的数组处理函数 在这篇文章中,笔者将会介绍PHP中数组的使用,以及一些注意事项.之前笔者已经说过PHP是一门弱 ...
- OpenLayers Node环境安装运行构建-支持Vue集成OpenLayers
NodeJS 环境安装包下载:https://nodejs.org/zh-cn/download/ 安装vue-cli3.0.1: https://cli.vuejs.org/guide/instal ...