Hadoop之MapReduce(一)简介及简单案例
简介
Hadoop MapReduce是一个分布式运算编程框架,基于该框架能够容易地编写应用程序,进而处理海量数据的计算。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想;Map 负责"分",即把复杂的任务分解为若干个"简单的任务"来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。Reduce 负责"合",即对 map 阶段的结果进行全局汇总。
MapReduce的执行流程
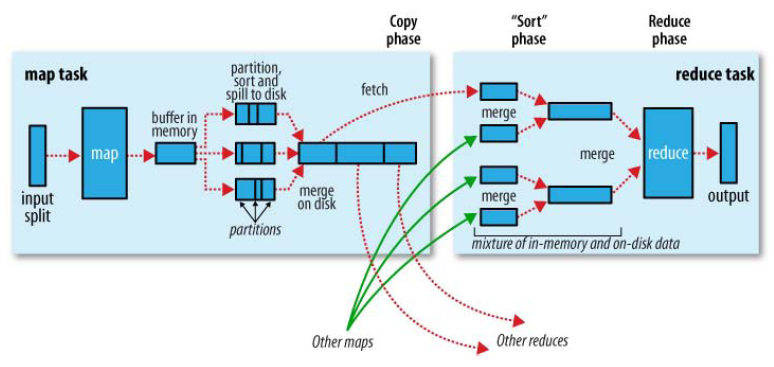
1,由默认读取数据组件TextInputFormat一行一行的读(input)
2,然后做相应的处理(由我们自己编写的Mapper程序做处理),最终context.write出<key,value>到内存缓冲区(图中的buffer in memory)
3,memory缓冲区默认100M,如果满了(或者到了末尾)则spill to disk(溢出到磁盘,最后merge(合并)),如果有分区或者排序的话,这里会分区且排序
4,由我们自己的程序控制一共有几个reduce,每个reduce会去磁盘上拉去属于自己的分区,进而执行我们自己编写的Reducer程序进行处理数据,最终context.write出<key,value>
5,由输出数据组件TextOutPutFomat输出到我们制定的位置(output)
简单示例
需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
首先,编写Mapper程序(需要继承org.apache.hadoop.mapreduce.Mapper并重写map方法):
package com.zy.hadoop.mr.wordcount; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* TODO 本类就是mr程序map阶段调用的类 也是就maptask
* KEYIN :map输入kv中key
* 在默认读取数据的组件下TextInputFormat(一行一行读)
* key:表示是改行的起始偏移量(光标所在的偏移值)
* value:表示的改行内容
* 用long来表示
* <p>
* VALUEIN:map输入kv中的value
* 在默认读取数据的组件下TextInputFormat(一行一行读)
* 表明的是一行内容 所有是String
* <p>
* KEYOUT:map输出的kv中的key
* 在我们的需求中 把单词做为输出的key 所以String
* <p>
* VALUEOUT:map输出kv中的value
* 在我们的需求中 把单词的次数1做为输出的value 所以int
* <p>
* Long String是jdk自带的数据类型
* 在网络传输序列化中 hadoop认为其及其垃圾 效率不高 所以自己封装了一套 数据类型 包括自己的序列化机制(Writable)
* Long----->LongWritable
* String--->Text
* int------>IntWritable
* null----->nullWritable
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* @param key
* @param value
* @param context TODO 该方法就是map阶段具体业务逻辑实现的所在地方
* map方法调用次数 取决于TextInputFormat如何读数据
* TextInputFormat读取一行数据--->封装成<k,v>--->调用一次map方法
* <p>
* hello tom hello alex hello--> <0,hello tom hello alex hello>
* alex tom mac apple --> <24,alex tom mac apple>
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿其中一行内容转成String
String line = value.toString();
//按照分隔符分隔
String[] words = line.split(" ");
//遍历数组 单词出现就标记1
for (String word : words) {
//使用哦context把map处理完的结果写出去
context.write(new Text(word), new IntWritable(1)); //<hello,1>
}
}
}
然后,编写Reducer类(需要继承org.apache.hadoop.mapreduce.Reducer并重写reduce方法):
package com.zy.hadoop.mr.wordcount; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /**
* TODO 该类就是mr程序reduce阶段运行的类 也就是reducetask
* KEYIN: reduce输入的kv中k 也就是map输出kv中的k 是单词 Text
* <p>
* VALUEIN:reduce输入的kv中v 也就是map输出kv中的v 是次数1 IntWritable
* <p>
* KEYOUT:reduce输出的kv中k 在本需求中 还是单词 Text
* <p>
* VALUEOUT:reduce输出的kv中v 在本需求中 是单词的总次数 IntWritable
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//定义一个变量
int count = 0;
//遍历values 累计里面的值
for (IntWritable value : values) {
count += value.get();
}
//输出结果
context.write(key, new IntWritable(count));
}
}
最后,编写执行类:
package com.zy.hadoop.mr.wordcount; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* TODO 该类就是mr程序运行的主类 主要用于一些参数的指定拼接 任务的提交
* TODO 比如使用的是哪个mapper 哪个reducer 输入输出的kv是什么 待处理的数据在那 输出结果放哪
*/
public class WordCountRunner {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); //指定mr采用本地模式运行 本地测试用
conf.set("mapreduce.framework.name", "local"); //使用job构建本次mr程序
Job job = Job.getInstance(conf); //指定本次mr程序运行的主类
job.setJarByClass(WordCountRunner.class); //指定本次mr程序的mapper reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class); //指定本次mr程序map阶段的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //指定本次mr程序reduce阶段的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //设置使用几个Reduce执行
job.setNumReduceTasks(2); //指定本次mr程序处理的数据目录 输出结果的目录
// FileInputFormat.setInputPaths(job, new Path("/wordcount/input"));
// FileOutputFormat.setOutputPath(job, new Path("/wordcount/output")); //本地测试用
FileInputFormat.setInputPaths(job, new Path("D:\\wordcount\\input"));
FileOutputFormat.setOutputPath(job, new Path("D:\\wordcount\\output"));//输出的文件夹不能提前创建 否则会报错 //提交本次mr的job
//job.submit(); //提交任务 并且追踪打印job的执行情况
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : -1);
}
}
如果需要将程序提交给YARN集群执行:
1,将程序打成jar包,上传到集群的任意一个节点上
2,用hadoop命令启动:hadoop xxxxx.jar
Hadoop之MapReduce(一)简介及简单案例的更多相关文章
- asp.net core 身份认证/权限管理系统简介及简单案例
如今的网站大多数都离不开账号注册及用户管理,而这些功能就是通常说的身份验证.这些常见功能微软都为我们做了封装,我们只要利用.net core提供的一些工具就可以很方便的搭建适用于大部分应用的权限管理系 ...
- Java基础之UDP协议和TCP协议简介及简单案例的实现
写在前面的废话:马上要找工作了,做了一年的.net ,到要找工作了发现没几个大公司招聘.net工程师,真是坑爹呀.哎,java就java吧,咱从头开始学呗,啥也不说了,玩命撸吧,我真可怜啊. 摘要: ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
- Hadoop基础-MapReduce的Partitioner用法案例
Hadoop基础-MapReduce的Partitioner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Partitioner关键代码剖析 1>.返回的分区号 ...
- Hadoop mapreduce框架简介
传统hadoop MapReduce架构(老架构) 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 1.首先用户程序 (JobClient) 提交了一个 job,job ...
- 【Hadoop离线基础总结】MapReduce自定义InputFormat和OutputFormat案例
MapReduce自定义InputFormat和OutputFormat案例 自定义InputFormat 合并小文件 需求 无论hdfs还是mapreduce,存放小文件会占用元数据信息,白白浪费内 ...
- oozie与mapreduce简单案例
准备工作 拷贝原来的模板 mkdir oozie-apps cd oozie-apps/ cp -r ../examples/apps/mar-reduce . mv map-reduce mr-w ...
- Hadoop MapReduceV2(Yarn) 框架简介[转]
对于业界的大数据存储及分布式处理系统来说,Hadoop 是耳熟能详的卓越开源分布式文件存储及处理框架,对于 Hadoop 框架的介绍在此不再累述,读者可参考 Hadoop 官方简介.使用和学习过老 H ...
随机推荐
- Leetcode 867. Transpose Matrix
class Solution: def transpose(self, A: List[List[int]]) -> List[List[int]]: return [list(i) for i ...
- SQL中合并两个表的JOIN语句
SQL里有四种JOIN语句用于根据某条件合并两个表: (INNER) JOIN: 交集 LEFT (OUTER) JOIN: 左表数据全包括,右表对应的如果没有就是NULL RIGHT (OUTER) ...
- 从无到有开发自己的Wordpress博客主题---局部模板的准备
毫无疑问,我们媒体页面都会有header和footer,这些用到的内容几乎是一样的. 从无到有,我们先不考虑后面可能用到的Search和Comment等的模板,后面的我会在文本最后面追加. 开始之前, ...
- bisect模块用于插入
参考链接: chttp://www.cnblogs.com/skydesign/archive/2011/09/02/2163592.html水
- 04:sqlalchemy操作数据库 不错
目录: 1.1 ORM介绍(作用:不用原生SQL语句对数据库操作) 1.2 安装sqlalchemy并创建表 1.3 使用sqlalchemy对表基本操作 1.4 一对多外键关联 1.5 sqlalc ...
- gulp 合格插件评判标准
官方插件列表: https://gulpjs.com/plugins/ 合格插件的判断标准 1. 不修改内容 如果一个插件一个文件都修改(无论是文案内容,文件路径),那么它就不是一个gulp ...
- AppScan 8.0.3安全漏洞扫描总结
本文记录了通过AppScan 8.0.3工具进行扫描的安全漏洞问题以及解决方案, 1.使用SQL注入的认证旁路 问题描述: 解决方案: 一般通过XSSFIlter过滤器进行过滤处理即可,通过XSSFI ...
- 记录一下 C51 里的位运算
记录一下 C51 里的位运算 一篇上个世纪的文章<单片机的C语言中位操作用法>1 今天看到一个这样的运算,这相当于清了 XICFG. #define INT1IS1 0x80 #defin ...
- RAC修改数据库的spfile位置
RAC修改spfile位置 [root@rac1 ~]# su - oracle [oracle@rac1 ~]$ sqlplus / as sysdba SQL*Plus: Release 11. ...
- 为什么中国出不了facebook和Twitter?
我们坐拥全球最大基数的网民,我们拥有让人骄傲的四大发明,我们有有流传全世界的孙子兵法,可是在互联网时代,我们却落后了.互联网可以说是江山人才辈辈出,各领风骚三两年. 让我们来简单地回顾一下近几年的互联 ...