Kafka数据辅助和Failover
数据辅助与Failover
CAP理论(它具有一致性、可用性、分区容忍性)

CAP理论:分布式系统中,一致性、可用性、分区容忍性最多只可同时满足两个。一般分区容忍性都要求有保障,因此很多时候在可用性与一致性之间做权衡。
一致性方案
1.Master-slave
》RDBMS的读写分离即为典型的Master-slave方案
》同步复制可保证强一致性但会影响可用性(等master确保将数据复制给全部的slave,slave才返回结果)
》异步复制可提供高可用性但会降低一致性
2.WNR
》主要用于去中心化(P2P)的分布式系统,DynameDB与Cassandra即采用此方案
》N代表副本数,W代表每次写操作要保证的最少写成功的副本数,R代表每次读至少读取的副本数
》当W+R>N时,可保证每次读取的数据至少有一个副本具有最新的更新
》多个写操作的顺序难以保证,可能导致多副本间的写操作顺序不一致,Dynamo通过向量时钟保证最终一致性
3.Paxos及其变种
》Google的Chubby,Zookeeper的Zab,RAFT等
Kafka是如何权衡CA的呢?
Replica

如:
当一个Patiton副本数超过Broker时,就会报错
Data Replication要解决的问题
1.如何Propagate(扩散)消息
2.何时Commit
3.如何处理Replica恢复
4.如何处理Replica全部宕机
1.如何Propagate(扩散)消息
以写入数据为例,Patiton分为leader和follower,follower周期性的向leader pull数据(和consumer相似)。
在读取数据时,与数据库读写分离不一样,follower并不参与读取操作,读取只和leader有关。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。但考虑到这种场景非常少见,可以认为这种方式在性能和数据持久化上做了一个比较好的平衡。在将来的版本中,Kafka会考虑提供更高的持久性。
2.何时Commit

由上图可知,leader数据发送给follower既不是同步通信也不是异步通信,而是在一致性和可用性做了动态的平衡
3.如何处理Replica恢复
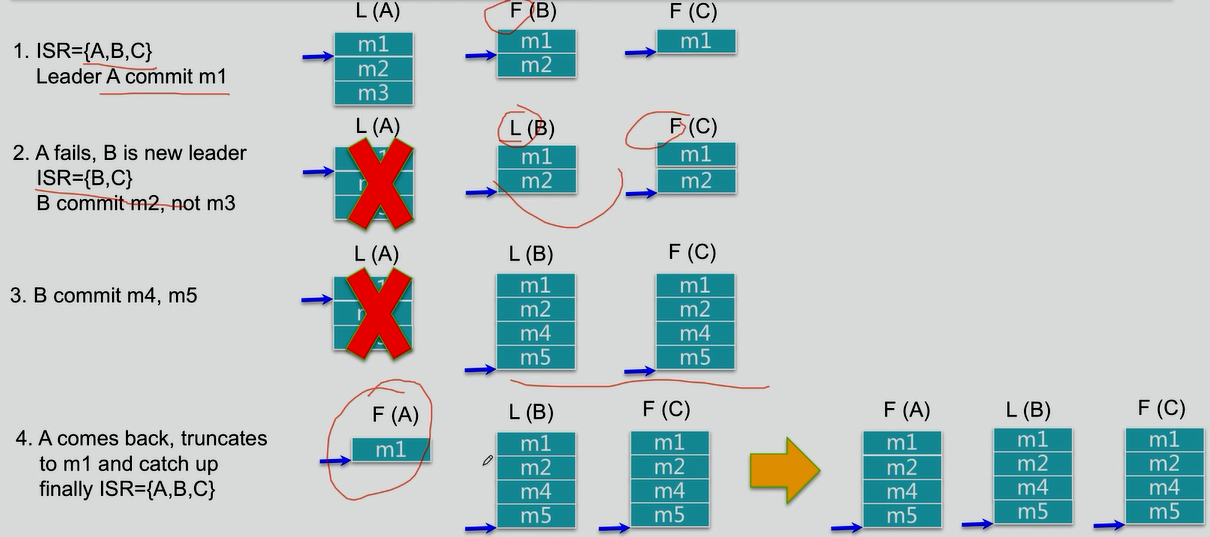
4.如何处理Replica全部宕机
等待ISR中任一Replica恢复,并选它为Leader
》等待时间较长,降低可用性
》或ISR中的所有Replica都无法恢复或者数据丢失,则该Patition将永不可用
选择第一个恢复的Replica为新的Leader,无论它是否在ISR中
》可能会有数据丢失
》可用性较高
Kafka数据辅助和Failover的更多相关文章
- kafka数据祸福和failover
k CAP帽子理论. consistency:一致性 Availability:可用性 partition tolerance:分区容忍型 CA :mysql oracle(抛弃了网络分区) CP:h ...
- Gobblin采集kafka数据
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 找时间记录一下利用Gobblin采集kafka数据的过程,话不多说,进入正题 一.Gobblin ...
- java spark-streaming接收TCP/Kafka数据
本文将展示 1.如何使用spark-streaming接入TCP数据并进行过滤: 2.如何使用spark-streaming接入TCP数据并进行wordcount: 内容如下: 1.使用maven,先 ...
- Flink消费Kafka数据并把实时计算的结果导入到Redis
1. 完成的场景 在很多大数据场景下,要求数据形成数据流的形式进行计算和存储.上篇博客介绍了Flink消费Kafka数据实现Wordcount计算,这篇博客需要完成的是将实时计算的结果写到redis. ...
- 工具篇-Spark-Streaming获取kafka数据的两种方式(转载)
转载自:https://blog.csdn.net/weixin_41615494/article/details/7952173 一.基于Receiver的方式 原理 Receiver从Kafka中 ...
- spark streaming从指定offset处消费Kafka数据
spark streaming从指定offset处消费Kafka数据 -- : 770人阅读 评论() 收藏 举报 分类: spark() 原文地址:http://blog.csdn.net/high ...
- Spark Streaming接收Kafka数据存储到Hbase
Spark Streaming接收Kafka数据存储到Hbase fly spark hbase kafka 主要参考了这篇文章https://yq.aliyun.com/articles/60712 ...
- flume 读取kafka 数据
本文介绍flume读取kafka数据的方法 代码: /************************************************************************* ...
- Kafka数据安全性、运行原理、存储
直接贴面试题: 怎么保证数据 kafka 里的数据安全? 答: 生产者数据的不丢失kafka 的 ack 机制: 在 kafka 发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够 ...
随机推荐
- LeetCode 翻转链表
基本思路 从元首节点之后每次取一个节点,并将节点接到元首节点前面 代码实现 /** * Definition for singly-linked list. * struct ListNode { * ...
- IDEA中使用插件添加更多可选择的主题,使代码高亮,缓解视觉疲劳
1.点击 File-->settings(或Ctrl+Shift+S)打开IDE设置面板 点击plugins-->右侧选择Marketplace-->搜索框中输入Material-- ...
- MySQL必会
SQL语言对大小写不敏感,但一般使用大.1.创建数据库 CREATE DATABASE test; 2.授予权限 CRANT ALL ON test.* to user(s); 3.使用指定数据库 U ...
- thinkphp5 前台模板的引入css,js,images
一:在公共的静态文件夹中建立我们模块的名称用来放置css,js,images 二:在配置文件config中定义需要的路径 三:在视图页面引入
- Mysql错误积累001-load data导入文件数据出现1290错误
错误出现情景 在cmd中使用mysql命令,学生信息表添加数据.使用load data方式简单批量导入数据. 准备好文本数据: xueshengxinxi.txt 文件 数据之间以tab键进行分割 ...
- Hadoop(2)-CentOS下的jdk和hadoop的安装与配置
准备工作 下载jdk8和hadoop2.7.2 使用sftp的方式传到hadoop100上的/opt/software目录中 配置环境 如果安装虚拟机时选择了open java,请先卸载 rpm -q ...
- Python学习 :文件操作
文件基本操作流程: 一. 创建文件对象 二. 调用文件方法进行操作 三. 关闭文件(注意:只有在关闭文件后,才会写入数据) fh = open('李白诗句','w',encoding='utf-8') ...
- rails小技巧之分组查询统计并去重
分组查询并统计 SpecialGroup.group(:special_type).count select special_type,count(*) from special_groups gro ...
- 怎么修复网站漏洞之metinfo远程SQL注入漏洞修补
2018年11月23日SINE网站安全检测平台,检测到MetInfo最新版本爆出高危漏洞,危害性较大,影响目前MetInfo 5.3版本到最新的 MetInfo 6.1.3版本,该网站漏洞产生的主要原 ...
- 652. Find Duplicate Subtrees
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode ...