Presto架构及原理
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎,可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别,据称该引擎的性能是 Hive 的 10 倍以上。Presto 可以查询包括 Hive、Cassandra 甚至是一些商业的数据存储产品,单个 Presto 查询可合并来自多个数据源的数据进行统一分析。Presto 的目标是在可期望的响应时间内返回查询结果,Facebook 在内部多个数据存储中使用 Presto 交互式查询,包括 300PB 的数据仓库,超过 1000 个 Facebook 员工每天在使用 Presto 运行超过 3 万个查询,每天扫描超过 1PB 的数据。
目录:
- presto架构
- presto低延迟原理
- presto存储插件
- presto执行过程
- presto引擎对比
Presto架构

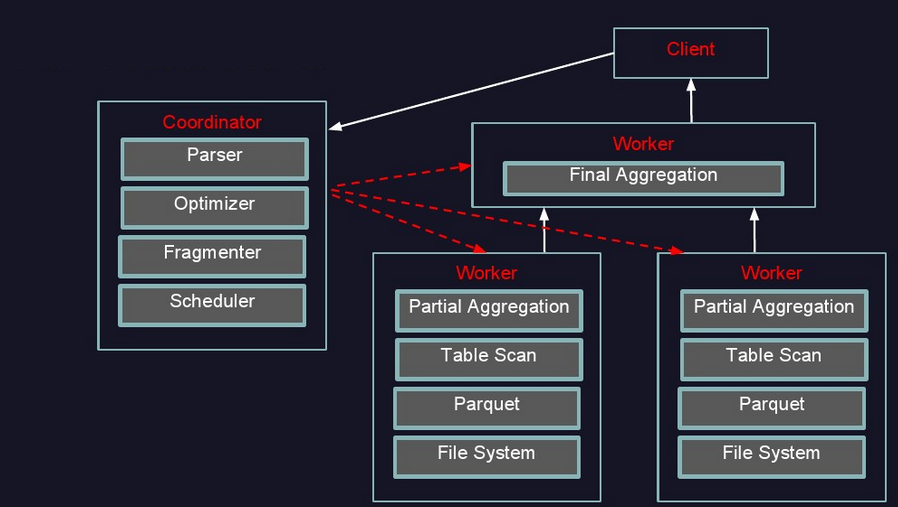
- Presto查询引擎是一个Master-Slave的架构,由下面三部分组成:
- 一个Coordinator节点
- 一个Discovery Server节点
- 多个Worker节点
- Coordinator: 负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行
- Discovery Server: 通常内嵌于Coordinator节点中
- Worker节点: 负责实际执行查询任务,负责与HDFS交互读取数据
- Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息
- 更形象架构图如下:

Presto低延迟原理
- 完全基于内存的并行计算
- 流水线式计算作业
- 本地化计算
- 动态编译执行计划
- GC控制
Presto存储插件
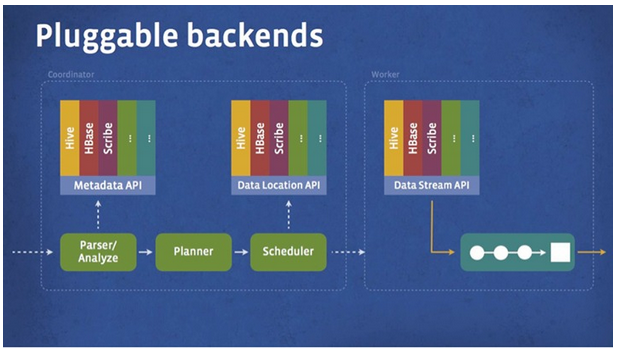
- Presto设计了一个简单的数据存储的抽象层, 来满足在不同数据存储系统之上都可以使用SQL进行查询。
- 存储插件(连接器,connector)只需要提供实现以下操作的接口, 包括对元数据(metadata)的提取,获得数据存储的位置,获取数据本身的操作等。
- 除了我们主要使用的Hive/HDFS后台系统之外, 我们也开发了一些连接其他系统的Presto 连接器,包括HBase,Scribe和定制开发的系统
- 插件结构图如下:
presto执行过程
- 执行过程示意图:
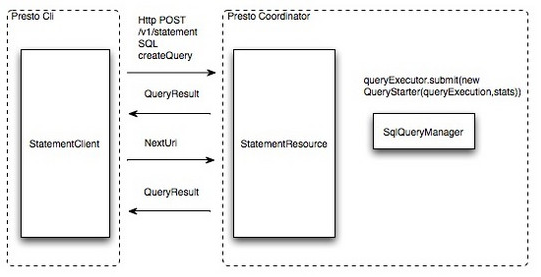
- 提交查询:用户使用Presto Cli提交一个查询语句后,Cli使用HTTP协议与Coordinator通信,Coordinator收到查询请求后调用SqlParser解析SQL语句得到Statement对象,并将Statement封装成一个QueryStarter对象放入线程池中等待执行,如下图:示例SQL如下
select c1.rank, count(*) from dim.city c1 join dim.city c2 on c1.id = c2.id where c1.id > 10 group by c1.rank limit 10;
- 逻辑执行过程示意图如下:
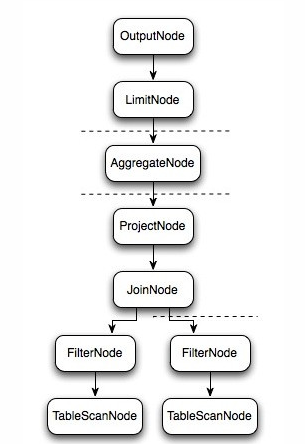
- 上图逻辑执行计划图中的虚线就是Presto对逻辑执行计划的切分点,逻辑计划Plan生成的SubPlan分为四个部分,每一个SubPlan都会提交到一个或者多个Worker节点上执行
- SubPlan有几个重要的属性planDistribution、outputPartitioning、partitionBy属性整个执行过程的流程图如下:
- PlanDistribution:表示一个查询阶段的分发方式,上图中的4个SubPlan共有3种不同的PlanDistribution方式
- Source:表示这个SubPlan是数据源,Source类型的任务会按照数据源大小确定分配多少个节点进行执行
- Fixed: 表示这个SubPlan会分配固定的节点数进行执行(Config配置中的query.initial-hash-partitions参数配置,默认是8)
- None: 表示这个SubPlan只分配到一个节点进行执行
- OutputPartitioning:表示这个SubPlan的输出是否按照partitionBy的key值对数据进行Shuffle(洗牌), 只有两个值HASH和NONE
- PlanDistribution:表示一个查询阶段的分发方式,上图中的4个SubPlan共有3种不同的PlanDistribution方式
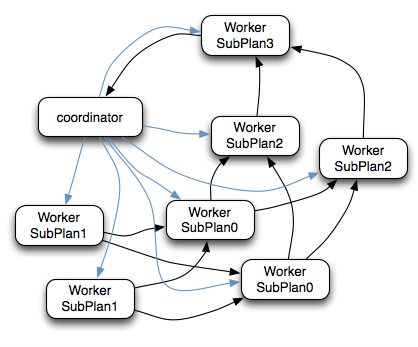
- 在上图的执行计划中,SubPlan1和SubPlan0 PlanDistribution=Source,这两个SubPlan都是提供数据源的节点,SubPlan1所有节点的读取数据都会发向SubPlan0的每一个节点;SubPlan2分配8个节点执行最终的聚合操作;SubPlan3只负责输出最后计算完成的数据,如下图:
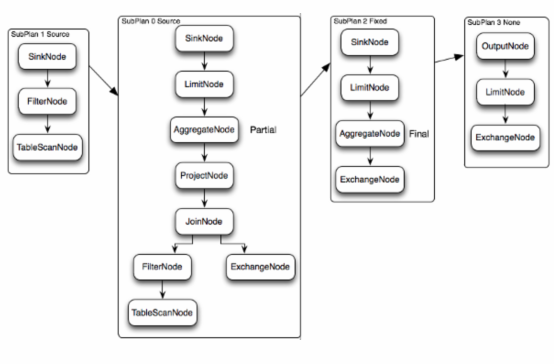
- SubPlan1和SubPlan0 作为Source节点,它们读取HDFS文件数据的方式就是调用的HDFS InputSplit API,然后每个InputSplit分配一个Worker节点去执行,每个Worker节点分配的InputSplit数目上限是参数可配置的,Config中的query.max-pending-splits-per-node参数配置,默认是100
- SubPlan1的每个节点读取一个Split的数据并过滤后将数据分发给每个SubPlan0节点进行Join操作和Partial Aggr操作
- SubPlan0的每个节点计算完成后按GroupBy Key的Hash值将数据分发到不同的SubPlan2节点
- 所有SubPlan2节点计算完成后将数据分发到SubPlan3节点
- SubPlan3节点计算完成后通知Coordinator结束查询,并将数据发送给Coordinator
presto引擎对比
- 与hive、SparkSQL对比结果图

Presto架构及原理的更多相关文章
- Presto 架构和原理简介(转)
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎,可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别,据称该引擎的性能是 ...
- presto架构和原理
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎,可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别,据称该引擎的性能是 ...
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- SQL Server AlwaysOn架构及原理
SQL Server AlwaysOn架构及原理 SQL Server2012所支持的AlwaysOn技术集中了故障转移群集.数据库镜像和日志传送三者的优点,但又不相同.故障转移群集的单位是SQL实例 ...
- 爱莲(iLinkIT)的架构与原理
随着移动互联网时代的到来,手机正在逐步替代其他的设备,手机是电话.手机是即时通讯,手机是相机,手机是导航仪,手机是钱包,手机是音乐播放器……. 除此之外,手机还是一个大大的U盘,曾几何时,我们用一根长 ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- [转帖]万字详解Oracle架构、原理、进程,学会世间再无复杂架构
万字详解Oracle架构.原理.进程,学会世间再无复杂架构 http://www.itpub.net/2019/04/24/1694/ 里面的图特别好 数据和云 2019-04-24 09:11:59 ...
- HDFS架构及原理
原文链接:HDFS架构及原理 引言 进入大数据时代,数据集的大小已经超过一台独立物理计算机的存储能力,我们需要对数据进行分区(partition)并存储到若干台单独的计算机上,也就出现了管理网络中跨多 ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
随机推荐
- LeetCode Pow(x, n) (水题)
题意: 求浮点型x的n次幂结果. 思路: logN直接求,注意n可能为负数!!!当n=-2147483648的时候,千万别直接n=-n,这样的结果是多少?其他求法大同小异. class Solutio ...
- 蓝牙SIG
蓝牙SIG 蓝牙SIG是一个国际性的非营利组织,它的目的是制定蓝牙的技术规范和推广蓝牙技术的应用.该组织由发起会员(Promoter).合作会员(Associate Member)和接受会员(Adop ...
- jquery 平滑滚动页面到某个锚点
$(document).ready(function() { $("a.topLink").click(function() { $ ...
- 学习iOS笔记第一天的C语言学习记录
c语言基础学习 int num1 = 15; int num2 = 5; int temp = 0; //先把num1放到temp里 temp = num1; //先把num2放到num1里 num1 ...
- csu 1604 SunnyPig (bfs)
Description SunnyPig is a pig who is much cleverer than any other pigs in the pigpen. One sunny morn ...
- linux脚本编程技术---8
一.什么是脚本 脚本是一个包含一系列命令序列的可执行(777)文本文件.当运行这个脚本文件时,文件中包含的命令序列将得到自动执行. 二.脚本编程 #!/bin/sh 首行固定格式 #!表明该脚本的的解 ...
- html部分---表单、iframe、frameset及其他字符的用法(以及name、id、value的作用与区别);
<form action="aa.html" method="post/get"> /action的作用是提交到..,methed是提交方法,用po ...
- C#部分---特殊集合:stack栈集合、queue队列集合、哈希表集合。
1.stack栈集合:又名 干草堆集合 栈集合 特点:(1)一个一个赋值 一个一个取值(2)先进后出实例化 初始化 Stack st = new Stack(); //添加元素用push st.Pus ...
- 工作中遇到的问题--缓存配置(使用@Configuration装配 @Bean的方式注入)
@EnableCaching@Configurationpublic class MFGCachingConfiguration { @Autowired private MFGSettings mf ...
- Android——网格布局仿计算器
代码如下: <?xml version="1.0" encoding="utf-8"?> <GridLayout xmlns:android= ...